

Classificação de Computadores Paralelos
É muito difícil a tarefa de classificar computadores paralelos. Já foram feitas diversas sugestões. A classificação definitiva ainda está por vir. Porém, a que trouxe melhores resultados e ainda hoje é usada, é a proposta por Flynn[2]. Essa classificação está baseada em dois conceitos: fluxo de instruções e fluxo de dados. O fluxo de instruções está relacionado com o programa que o processador executa, enquanto que o fluxo de dados está relacionado com os operandos manipulados por essas instruções. O fluxo de instruções e o fluxo de dados são considerados independentes e por isso existem quatro combinações possíveis, como mostrado na Figura 1.

Figura 1: Fluxo de instruções e dados.
Nas Figuras 2 a 5 apresentamos os diagramas de blocos para essas 4 combinações. Nessas figuras, a sigla MM representa o “Módulo de Memória” e a sigla EP representa o “Elemento de Processamento”, ou seja, o processador. Essas quatro arquiteturas serão detalhadas a seguir.

Figura 2: Arquitetura SISD (Single Instruction Single Data).
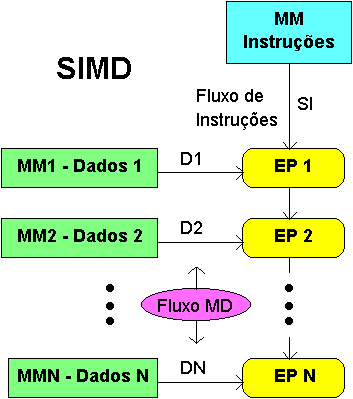
Figura 3: Aquitetura SIMD (Single Instruction Multiple Data).

Figura 4: Arquitetura MISD (Multiple Instruction Single Data).

Figura 5: Arquitetura MIMD (Multiple Instruction Multiple Data).
SISD - Instrução Única, Dado Único (Single Instruction Single Data)
Essa arquitetura é usada nos computadores que temos em casa. Segue o proposto por von Neumann e é por isso denominada de “Arquitetura de von Neumann”, também chamado de computador serial. Temos um único fluxo de instruções (SI), caracterizado pelo contador de programa da CPU, que opera sobre um único dado (SD) por vez. A Figura 2 apresenta um diagrama de blocos ilustrativo deste caso. Apesar de serem representados como módulos separados, a memória de instruções e a memória de dados são, para este caso, a mesma.
SIMD - Única Instrução, Múltiplos Dados (Single Instruction Multiple Data)
De início esta arquitetura paralela pode parecer estranha, mas como será constatado adiante, ela não só é conhecida, como também já foi muito utilizada. Para facilitar o conceito de um computador que utilize uma única instrução operando sobre uma grande quantidade de dados, devemos consultar o diagrama da Figura 3.
A arquitetura mostrada apresenta N processadores (EP), sendo que cada processador trabalha sobre um dado distinto, que vem de cada um dos N módulos de memória (MD). O ponto importante é que todos os processadores (EPi) trabalham sincronizados e executam todos a mesma instrução, ou seja, cada instrução é passada, ao mesmo tempo, para os N EPs. Assim, os processadores executam a mesma instrução, porém sobre um dado diferente. Como é fácil de concluir, um computador com essa arquitetura é capaz de operar um vetor de dados por vez. Vem daí seu nome de Computador Vetorial, ou “Array Processor”.
Um grande exemplo desta arquitetura são os famosos computadores Cray. Outro exemplo é o conjunto de instruções MMX. Eles são muito usados quando um mesmo programa deve ser executado sobre uma grande massa de dados, como é o caso de prospeção de petróleo. Note que essa arquitetura não sofre com problemas de sincronização, pois existe um único programa em execução.
MISD - Múltiplas Instruções, Dado Único (Multiple Instruction Single Data)
Essa arquitetura é um pouco mais difícil de ser explicada. Tentemos imaginar como é que se pode fazer múltiplas operações (MI) sobre um mesmo dado (SD). Os próprios pesquisadores têm opiniões divergentes sobre esse assunto. Entretanto, não vamos entrar nesses debates teóricos. De forma simples, vamos estudar a Figura 4, onde pode ser visto que, apesar de existir um único fluxo de dados, existem vários dados sendo operados ao mesmo tempo. Essa figura é conhecida na literatura especializada com o nome de “pipeline” ou linha de produção.
A figura mostra que N processadores operam sobre K diferentes dados. Façamos uma analogia com uma linha de montagem de carros. Vamos supor que um carro leve 6 horas para ser montado e que a tarefa de montagem possa ser dividida em 12 equipes, numeradas em seqüência de 1 até 12, cada uma gastando meia hora. É fácil de ver que não precisamos esperar que a última equipe termine de montar um carro para a equipe 1 inicie a montagem do carro seguinte. Na verdade, todas elas trabalham simultaneamente, montando vários carros ao mesmo tempo. Por isso, com alguma liberdade, é costume classificá-la de paralelismo temporal. Então, apesar do tempo de montagem consumir 6 horas, a saída da linha de produção entrega um carro a cada meia hora. Agora é fácil voltar aos computadores e ver que temos um único fluxo de dados (SD), porém vários instruções (MI) processam esses dados, ao mesmo tempo.
MIMD - Múltiplas Instruções, Múltiplos Dados (Multiple Instruction Multiple Data)
Essa é a arquitetura que esperaríamos encontrar em um computador paralelo. Temos vários dados (MD) sendo operados por vários instruções (MI), simultaneamente. Essa é a arquitetura mais usada pelos modernos supercomputadores. Nesse caso, é importante que os processadores possam se comunicar entre si para fazer a sincronização e trocar informações. Além disso, é necessário ter uma memória, chamada de global, onde todos processadores possam disponibilizar, para os demais, os resultados intermediários. A Figura 5 apresenta uma solução genérica para essa arquitetura MIMD.
Note que agora temos N processadores e dois tipos de memória: a local e a global. A memória global pode ser acessada por qualquer um dos processadores, por isso existe a chamada “Estrutura de Comunicação”, que disponibiliza a memória global para qualquer um dos processadores. Uma única memória global criaria um grande gargalo, pois só um processador poderia acessá-la por vez. Por isso, a figura apresenta duas memórias globais e, com isso, dois processadores podem ser atendidos ao mesmo tempo.
Para evitar uma quantidade excessiva de acessos a essa memória, os processadores possuem a chamada memória local, onde está a maioria das suas instruções e dos dados que devam ser operados. Essa memória local evita que a estrutura de comunicação se transforme num enorme gargalo. Os processadores precisam trocar informações e, no caso desta figura, a própria estrutura de comunicação se encarrega desta tarefa.
Uma simples análise da arquitetura MIMD da Figura 5 mostra que agora existe um fluxo de múltiplos dados (MD) sendo operado por um fluxo de múltiplas instruções (MI). Agora sim é necessária a genialidade dos programadores, pois como conseguir que uma estrutura deste tipo, imagine 1.024 processadores, trabalhe de forma sincronizada para gerar algum resultado? Se já é difícil escrever e depurar programas seriais, imagine fazer isso em um computador com 1.024 diferentes programas trabalhando sobre 1.024 dados diferentes.


























")
")

")

Respostas recomendadas
Não há comentários para mostrar.
Crie uma conta ou entre para comentar
Você precisa ser um usuário para fazer um comentário
Criar uma conta
Crie uma nova conta em nossa comunidade. É fácil!
Crie uma nova contaEntrar
Já tem uma conta? Faça o login.
Entrar agora