

Gabrielle02
-
Posts
50 -
Cadastrado em
-
Última visita
-
 Oi pessoal boa tarde, tudo bom? Estou querendo pegar o Galaxy S24 FE, mas vi que alguns usuários tiveram problema com a conexão bluetooth com o fone. Alguém que tenha esse celular pode me confirmar se está acontecendo isso mesmo? Qualquer comentário é válido, obrigada!
Oi pessoal boa tarde, tudo bom? Estou querendo pegar o Galaxy S24 FE, mas vi que alguns usuários tiveram problema com a conexão bluetooth com o fone. Alguém que tenha esse celular pode me confirmar se está acontecendo isso mesmo? Qualquer comentário é válido, obrigada! -
Não consigo mais de 100mbps na internet
Gabrielle02 respondeu ao tópico de Gabrielle02 em Redes e Internet
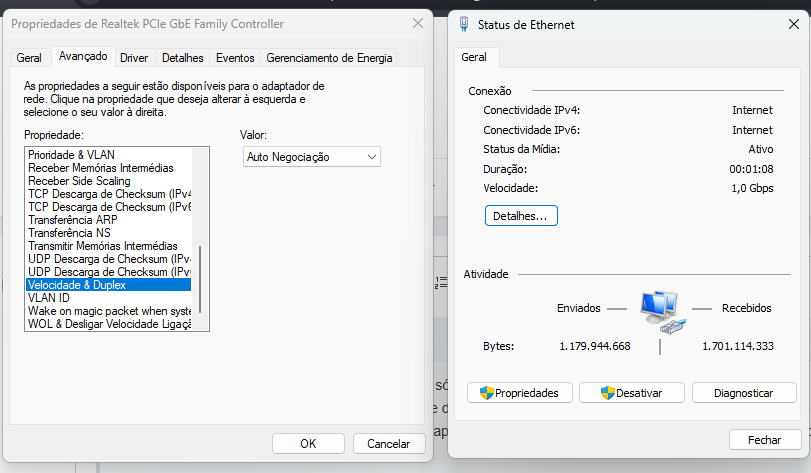
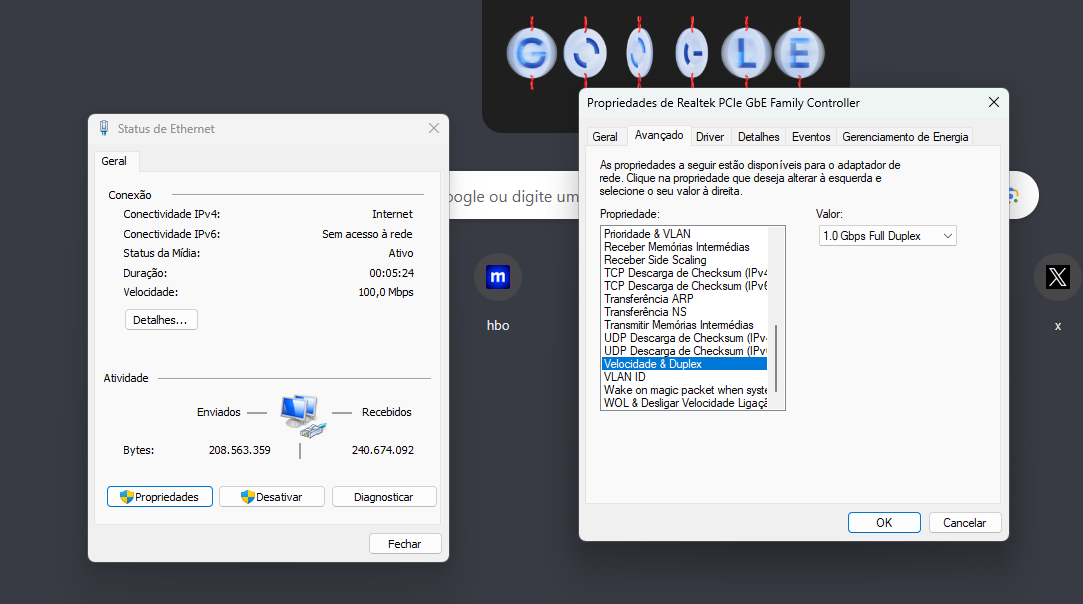
Obrigada a vocês que me responderam, no final eu só mudei a configuração para auto negociação e deu certo. Acho que o problema era o cabo anterior que era muito pequeno, deve que amassou em algum lugar.
-
Não consigo mais de 100mbps na internet
Gabrielle02 respondeu ao tópico de Gabrielle02 em Redes e Internet
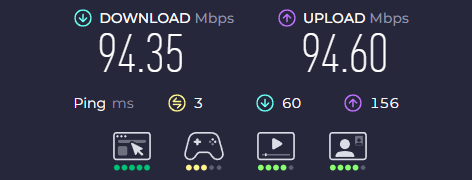
@arfneto fiz o teste dentro da minha rede, e deu só 100 também. Comprei o bendito cabo cat6, instalei ele e não teve diferença. Pelo menos agora sei que definitivamente não é o cabo. Tentei entrar nas configurações do meu roteador e aparentemente mudaram a senha (não é admin, nem mesmo a senha que vem na ***** do roteador), então agora estou contatando novamente a provedora. -
Não consigo mais de 100mbps na internet
Gabrielle02 respondeu ao tópico de Gabrielle02 em Redes e Internet
@Edvaldo J. Frederico Entendi, eu comprei um cat6 de 30 metros agora, para não ter forçamento no cabo. Depois vou retornar com o resultado, obrigada -
Gabrielle02 alterou sua foto pessoal
-
Olá pessoal, tudo bom? Eu pago 800megas de internet, e só utilizo 100mbps. Já contatei a provedora, e disseram que talvez o problema era o cabo, então troquei para um Cat5e, depois eles vieram aqui e trocaram para um modem mais atual. Porém, ainda continuo recebendo somente 100. Os drivers estão atualizados Minha placa-mãe: B450M PRO-VDH MAX. Modelo do modem: Huawei OptiXstar EG8145X6-10 Alguém poderia me ajudar? E já fiz essa configuração, Full duplex
-
Boa noite, tudo joia? Então, sou bem novata na área de programação, e estou tendo dificuldades em uma questão. Objetivo: a partir de uma URL obtenha o trecho de texto contido no nível mais profundo da estrutura HTML de seu conteúdo usando Java JDK17. Não pode usar bibliotecas e frameworks externos ao JDK. Também não é permitido o uso de packages e classes nativos do JDK relacionados à manipulação de HTML, XML ou DOM Estou tento dificuldades para dar inicio, queria algumas dicas de como achar conteúdo sobre html + java, e também queria um norte para começar o meu código. Desde já, obrigada a todos! Por enquanto, consegui ler e imprimir o conteúdo de uma url. Mas ainda preciso fazer a lógica de pegar o o trecho de texto do nivel mais profundo, alguma dica pessoal? Aqui o código: import java.io.BufferedReader; import java.io.IOException; import java.io.InputStreamReader; import java.net.HttpURLConnection; import java.net.URL; public class teste { public static void main(String[] args) { try { URL obj = new URL("https://www.google.com/"); HttpURLConnection con = (HttpURLConnection) obj.openConnection(); con.setRequestMethod("GET"); BufferedReader in = new BufferedReader( new InputStreamReader( obj.openStream())); String inputLine; while ((inputLine = in.readLine()) != null) System.out.println(inputLine); in.close(); } catch (IOException e) { System.out.println("Erro de leitura"); } } }
-
Vish kkkk, mas duvido que seja mais barulhetas que as minhas atuais, porém irei trocá-las mais pra frente do mesmo jeito. Qual é a quantidade ideal de dbA?
-
@1lokos então, acabei de comprar esse XPG Stalker Air que voce tinha recomendado anteriormente. Sobre as fans, peguei só duas para quebrar o galho, já q esse gabinete vem com duas equipadas. fans gabinete o que você acha? obrigada
-
qual o melhor custo beneficio para processador amd?
Gabrielle02 respondeu ao tópico de Gabrielle02 em Processadores
@RS Faria por exemplo, um teto de 800 reais por ai -
qual o melhor custo beneficio para processador amd?
Gabrielle02 respondeu ao tópico de Gabrielle02 em Processadores
@RS Faria você tem alguma indicação de placa de Vídeo com custo beneficio? -
Tirando a limitação de ser rosa, quais outros você me recomenda? Também achei esse aqui da aigo AIGO DARKFLASH DK100, MID-TOWER poderia também, me recomendar as fans com pwm? estou procurando e só achei na amazon para comprar, e só vem 3 delas, não sei se já é o suficiente ou não, tendo em vista que irei optar por comprar um gabinete sem fans. link das fans pwm que achei Outra coisa, eu vi em um post daqui do fórum que gabinete fechado na frente vira uma estufa, então to observando os que são mais abertinhos. Igual esses aqui: AIGO DARKFLASH A290 MESH (com 3 fans) PICHAU KAZAN 2 AZZA CELESTA 340 algum desses é uma boa opção?
-
qual o melhor custo beneficio para processador amd?
Gabrielle02 respondeu ao tópico de Gabrielle02 em Processadores
@J.Augusto F falando nisso, eu estava pensando em incluir uma placa de vídeo também. mas primeiro queria olhar a questão do processador -
qual o melhor custo beneficio para processador amd?
Gabrielle02 respondeu ao tópico de Gabrielle02 em Processadores
@J.Augusto F Basicamente: programar, blender, editar Vídeo, jogar valorant/fortnite. . -
Bom dia fórum,tudo bom? Eu gostaria de dar um up no meu pc, aqui as configurações dele: AMD Ryzen 5 3400G with Radeon Vega Graphics 3.70 GHz memória RAM: 2x hyperx fury 8gb 3200mhz Fonte Corsair CV450, 450W, 80 Plus Bronze - CP-9020209-BR placa-mãe: gigabyte b450m gaming DDR4 Gostaria de saber qual processador seria melhor para substituir esse, tenho preferência em amd.
-
@1lokos Por acaso você sabe de um gabinete que ja venha com essas fans pwm? O gabinete pode ser de qualquer cor.

Sobre o Clube do Hardware
No ar desde 1996, o Clube do Hardware é uma das maiores, mais antigas e mais respeitadas comunidades sobre tecnologia do Brasil. Leia mais
Direitos autorais
Não permitimos a cópia ou reprodução do conteúdo do nosso site, fórum, newsletters e redes sociais, mesmo citando-se a fonte. Leia mais