

MZ Editora
-
Posts
28 -
Cadastrado em
-
Última visita
Nunca
Tipo de conteúdo
Artigos
Selos
Fabricantes
Livros
Cursos
Análises
Fórum
Tudo que MZ Editora postou
-
Tópico para a discussão do seguinte conteúdo publicado no Clube do Hardware: PCI Plug and Play "Aprenda sobre o funcionamento do barramento PCI Plug and Play." Comentários são bem-vindos. Atenciosamente, Equipe Clube do Hardware https://www.clubedohardware.com.br
-
Processadores Para o Próximo Milênio - Parte 4
MZ Editora postou um tópico em Comentários de artigos
Tópico para a discussão do seguinte conteúdo publicado no Clube do Hardware: Processadores Para o Próximo Milênio - Parte 4 "Nesta parte final da série "Processadores para o próximo milênio", falamos sobre supercomputadores." Comentários são bem-vindos. Atenciosamente, Equipe Clube do Hardware https://www.clubedohardware.com.br -
Processadores Para o Próximo Milênio - Parte 3
MZ Editora postou um tópico em Comentários de artigos
Tópico para a discussão do seguinte conteúdo publicado no Clube do Hardware: Processadores Para o Próximo Milênio - Parte 3 "Na terceira parte desta série de artigos mostramos alguns exemplos de arquiteturas paralelas propostas pela IBM." Comentários são bem-vindos. Atenciosamente, Equipe Clube do Hardware https://www.clubedohardware.com.br -
Processadores Para o Próximo Milênio - Parte 2
MZ Editora postou um tópico em Comentários de artigos
Tópico para a discussão do seguinte conteúdo publicado no Clube do Hardware: Processadores Para o Próximo Milênio - Parte 2 "Série que discute os avanços na arquitetura de processadores. Nesta parte, discutimos o conceito de paralelismo." Comentários são bem-vindos. Atenciosamente, Equipe Clube do Hardware https://www.clubedohardware.com.br -
Tópico para a discussão do seguinte conteúdo publicado no Clube do Hardware: Arquitetura de 64 bits da AMD (x86-64) "Aprenda tudo sobre o funcionamento da arquitetura de 64bits da AMD." Comentários são bem-vindos. Atenciosamente, Equipe Clube do Hardware https://www.clubedohardware.com.br
-
Tópico para a discussão do seguinte conteúdo publicado no Clube do Hardware: Arquitetura de 64 bits da Intel (IA-64) "Aprenda tudo sobre o funcionamento da arquitetura IA-64 da Intel, utilizada pelos processadores Itanium." Comentários são bem-vindos. Atenciosamente, Equipe Clube do Hardware https://www.clubedohardware.com.br
-
Tópico para a discussão do seguinte conteúdo publicado no Clube do Hardware: ISA Plug and Play "Aprenda sobre o funcionamento do barramento ISA Plug and Play." Comentários são bem-vindos. Atenciosamente, Equipe Clube do Hardware https://www.clubedohardware.com.br
-
Tópico para a discussão do seguinte conteúdo publicado no Clube do Hardware: Arquitetura Plug and Play "Aprenda sobre o funcionamento da Arquitetura Plug and Play." Comentários são bem-vindos. Atenciosamente, Equipe Clube do Hardware https://www.clubedohardware.com.br
-
Tópico para a discussão do seguinte conteúdo publicado no Clube do Hardware: USB - Estrutura de Software "Saiba tudo sobre a estrutura de software do barramento USB." Comentários são bem-vindos. Atenciosamente, Equipe Clube do Hardware https://www.clubedohardware.com.br
-
Tópico para a discussão do seguinte conteúdo publicado no Clube do Hardware: USB - Estrutura Elétrica "Saiba tudo sobre a estrutura elétrica do barramento USB." Comentários são bem-vindos. Atenciosamente, Equipe Clube do Hardware https://www.clubedohardware.com.br
-
Tópico para a discussão do seguinte conteúdo publicado no Clube do Hardware: Merced: O Sucessor do Pentium II "Aprenda sobre o projeto P7 da Intel, codinome Merced, que acabou sendo lançado no mercado com o nome Itanium." Comentários são bem-vindos. Atenciosamente, Equipe Clube do Hardware https://www.clubedohardware.com.br
-
Processadores Para o Próximo Milênio - Parte 1
MZ Editora postou um tópico em Comentários de artigos
Tópico para a discussão do seguinte conteúdo publicado no Clube do Hardware: Processadores Para o Próximo Milênio - Parte 1 "Uma visão dos computadores antigos para entendermos onde vamos chegar." Comentários são bem-vindos. Atenciosamente, Equipe Clube do Hardware https://www.clubedohardware.com.br -
Tópico para a discussão do seguinte conteúdo publicado no Clube do Hardware: DVD - Arquitetura "Veja como funciona os aparelhos de DVD." Comentários são bem-vindos. Atenciosamente, Equipe Clube do Hardware https://www.clubedohardware.com.br
-
Tópico para a discussão do seguinte conteúdo publicado no Clube do Hardware: Processador Athlon "Aprenda sobre o funcionamento do processador Athlon da AMD. " Comentários são bem-vindos. Atenciosamente, Equipe Clube do Hardware https://www.clubedohardware.com.br
-
 Continuando o estudo dos artigos anteriores, neste artigo exporemos a arquitetura de 64 bits da AMD. Ao longo dos últimos quatro meses, vimos o surgimento dos computadores, dos microcomputadores e a consolidação dos seus princípios fundamentais. Em seguida, estudamos como esses princípios evoluíram para o processamento paralelo e os novos problemas que daí surgiram. De posse dessas idéias, pudemos melhor compreender a complexidade das modernas máquinas de alto desempenho. Constatamos também que o processamento paralelo não está limitado às máquinas sofisticadas, mas é empregado em diversos processadores. Mesmo nossos “velhos” PCs-Pentium fazem uso de um paralelismo, mas a nível de instrução, ou seja, executam mais de uma instrução por vez. Agora, neste artigo e no próximo, abordaremos os processadores de 64 bits que irão impulsionar nossos próximos computadores pessoais. Os projetos da Intel e AMD são inovadores e, se as promessas forem cumpridas, em menos de um ano deverão estar nas prateleiras das lojas. Essas novas arquiteturas prometem levar o paralelismo ainda mais longe, fornecendo mecanismos para que os compiladores passem para as CPUs não só as instruções arrumadas de forma eficiente, mas principalmente como e quais podem ser executadas em paralelo. Quando se fala de CPUs de 64 bits, é importante elucidar uma certa confusão que se faz com processadores atuais. Devemos ter claro que todos os atuais processadores, Intel ou AMD, são CPUs de 32 bits. O Pentium 4 ou o Athlon têm barramento de dados de 64 bits, porém a arquitetura da CPU é de 32 bits. Neste artigo, vamos ver o que a AMD está planejando para a sua arquitetura de 64 bits. No mês que vem, será a vez da Intel. Arquitetura x86-64 da AMD Iniciamos com uma pergunta: como fazer a transição das CPUs de 32 bits para 64 bits? A AMD está respondendo a esta pergunta com uma arquitetura que, além do ambiente 64 bits, promete compatibilidade com todos os programas desenvolvidos para 16 e 32 bits. O objetivo é oferecer um caminho de baixo custo para que os usuários façam essa transição de forma bastante suave. Com uma arquitetura compatível com o mundo x86, os fabricantes de placas, de software e os usuários podem gerenciar mais facilmente seus investimentos. A ideia é oferecer uma ponte segura para a transição de 32 para 64 bits. A computação de 64 bits está voltada para aplicações que têm uma grande “fome” por memória, como as grandes bases de dados, as ferramentas CAD e as simulações que, de acordo com os recursos atuais, estão limitadas pelo espaço de endereçamento de 4 GB. Até há pouco tempo, dizia-se que as CPUs RISC ultrapassariam de forma definitiva as arquiteturas CISC. Porém, isso não aconteceu e as atuais máquinas CISC se equiparam às RISC, em termos de operações com inteiros, e já diminuíram bastante desvantagem que tinham em operações com ponto-flutuante. Por isso, afirma a AMD, os próximos ganhos de desempenho terão mais a ver com as técnicas de implementação (ex: paralelismo) do que com o conjunto de instruções: RISC, CISC-64 ou VLIW. Na verdade, há um certo abuso com esses nomes, pois as atuais CPUs x86 só têm uma casca CISC, sendo seu núcleo formado por máquinas RISC. A AMD está denominando sua nova arquitetura de “x86-64” e ela será iniciada com uma família de processadores que tem o nome código “Hammer”. As promessas apontam para a comercialização ainda no final deste ano. A estratégia de 64 bits da AMD é a extensão das atuais CPUs x86 para trabalharem em 64 bits, com a introdução do chamado Modo Longo. Essa solução é segura pois já foi empregada por ocasião da transição de 16 bits (CPUs 8088 e 286) para 32 bits (CPUs 386 e diante). Desde há muito tempo, as CPUs de 32 bits operam em dois modos. Quando em modo real, elas ficam iguais ao antigo 8088, porém, quando em modo protegido, elas oferecem recursos de 32 bits, junto com gerenciadores de tarefas e de memória. A arquitetura x86-64 oferece um novo modo denominado “Modo Longo”, em inglês “long mode”, que serve para colocar a CPU operando a 64 bits. Quando em Modo Longo, além dos recursos de 64 bits, são oferecidos registradores estendidos para 64 bits e, além disso, novos registradores foram adicionados. Passemos ao estudo desse novo modo. O Modo Longo é ativado através de um bit de controle chamado LMA, do inglês “Long Mode Active”. Quando o LMA estiver desativado, o processador operará no modo padrão x86 e será compatível com os sistemas operacionais e aplicativos de 16 e 32 bits, ou seja, será compatível com tudo que existe nos dias de hoje. Quando o LMA for ativado (Modo Longo), a extensão de 64 bits estará habilitada, oferecendo uma nova CPU de 64 bits. O Modo Longo é ainda dividido em dois submodos: o Modo 64-bits e o Modo Compatível. Esses dois submodos são controlados pelos bits D e L, presentes no descritor apontado pelo registrador CS (Segmento de Código). O Modo Compatível é interessante porque permite que, a nível de programa, se rodem aplicativos de 16 ou 32 bits dentro do Modo 64-bits. É algo semelhante ao modo virtual 86 dos processadores 386. A Figura 1 apresenta um quadro explicativo desses modos. Figura 1: Modos de operação da família x86-64. O antigo modo x86 (32 ou 16 bits) é denominado Modo Legal (LMA=0). Quando nesse modo, as CPUs x86-64 podem trabalhar com dados de 16 ou 32 bits. Note que, quando nesse modo, o estado do bit CS.L não tem significado, ou seja, ele é um “don’t care”. Quando colocado em Modo Longo 64-bits (LMA=1, CS.L=1 e CS.D=0), o tamanho padrão do operando é de 32 bits e o tamanho padrão para o endereçamento é de 64 bits. Com o uso de prefixos de instrução, o tamanho do operando pode ser alterado para 64 ou 16 bits e o tamanho do endereço para 32 bits. Se colocado no Modo Longo Compatível (LMA=1 e CS.L=0), passa a existir a compatibilidade binária com as aplicações escritas em 16 e 32 bits x86. Isso é interessante, pois um sistema operacional em Modo Longo pode rodar os atuais programas de 16 e 32 bits apenas colocando em zero o bit CS.L do descritor apontado pelo segmento de código desses aplicativos. No submodo Compatível, o bit CS.D continua a selecionar entre os modos de 16 e 32 bits. Deve ainda ser notado que, quando o processador está no Modo Legal, o estado do bit CS.L não tem significado, ou seja, é um “don’t care”. A Figura 2 apresenta os detalhes de programação dessa nova arquitetura. Figura 2: Características de programação da arquitetura x86-64 da AMD. Vamos agora dar uma olhada mais cuidadosa no Modo Longo. Como já foi visto, o Modo Longo permite o uso dos recursos de 64 bits, ao mesmo tempo que oferece o submodo Compatível para rodar aplicações de 16 ou 32 bits. Esse modo traz uma grande quantidade de recursos, que estão listados a seguir: Endereçamento virtual de 64 bits; Registradores estendidos para 64 bits; Adição de 8 registradores (R8-R15); Adição de 8 registradores para SIMD (XMM8-XMM15); Ponteiro de instruções com 64 bits; Modo de endereçamento absoluto (“flat”). A adição de novos registradores para operações SIMD torna disponível um total de 16 registradores multimídia. Os novos registradores de finalidade geral vêm a diminuir um pouco uma das deficiências da arquitetura x86, que é a pequena quantidade de registradores. Para definir sua lógica de registradores, a AMD simplesmente estendeu o esquema usado para os registradores de 16 e 32 bits. Assim, continua sendo possível acessar de forma fracionada os registradores herdados do antigo 8086. Por exemplo, o registrador RAX pode ser acessado como um único bloco de 64 bits, mas também é possível acessar somente sua metade inferior através do registrador EAX. Além disso, também está acessível uma porção de 16 bits (AX) e duas porções de 8 bits (AH e AL). É claro que AX é formado pela justaposição dos registradores AH com AL. Assim é mantida toda compatibilidade com os antigos ambientes x86. A Figura 3 ilustra esses possíveis fracionamentos. Figura 3: Esquema de fracionamento dos registradores herdados da arquitetura x86-64. Os avanços da tecnologia de integração e o aumento de velocidade do relógio deverão possibilitar um maior desempenho destas CPUs, mesmo quando operando no Modo Legal. Com essa arquitetura, a AMD espera oferecer um caminho tranqüilo para a transição de 32 para 64 bits. No passado, uma transição não tão tranqüila, devido ao novo modelo de memória, permitiu uma evolução dos 16 bits (8086 e 286) para os 32 bits (386 em diante). A AMD aposta que, ao invés de mudar completamente a arquitetura, o sucesso estará com quem mantiver a compatibilidade.
Continuando o estudo dos artigos anteriores, neste artigo exporemos a arquitetura de 64 bits da AMD. Ao longo dos últimos quatro meses, vimos o surgimento dos computadores, dos microcomputadores e a consolidação dos seus princípios fundamentais. Em seguida, estudamos como esses princípios evoluíram para o processamento paralelo e os novos problemas que daí surgiram. De posse dessas idéias, pudemos melhor compreender a complexidade das modernas máquinas de alto desempenho. Constatamos também que o processamento paralelo não está limitado às máquinas sofisticadas, mas é empregado em diversos processadores. Mesmo nossos “velhos” PCs-Pentium fazem uso de um paralelismo, mas a nível de instrução, ou seja, executam mais de uma instrução por vez. Agora, neste artigo e no próximo, abordaremos os processadores de 64 bits que irão impulsionar nossos próximos computadores pessoais. Os projetos da Intel e AMD são inovadores e, se as promessas forem cumpridas, em menos de um ano deverão estar nas prateleiras das lojas. Essas novas arquiteturas prometem levar o paralelismo ainda mais longe, fornecendo mecanismos para que os compiladores passem para as CPUs não só as instruções arrumadas de forma eficiente, mas principalmente como e quais podem ser executadas em paralelo. Quando se fala de CPUs de 64 bits, é importante elucidar uma certa confusão que se faz com processadores atuais. Devemos ter claro que todos os atuais processadores, Intel ou AMD, são CPUs de 32 bits. O Pentium 4 ou o Athlon têm barramento de dados de 64 bits, porém a arquitetura da CPU é de 32 bits. Neste artigo, vamos ver o que a AMD está planejando para a sua arquitetura de 64 bits. No mês que vem, será a vez da Intel. Arquitetura x86-64 da AMD Iniciamos com uma pergunta: como fazer a transição das CPUs de 32 bits para 64 bits? A AMD está respondendo a esta pergunta com uma arquitetura que, além do ambiente 64 bits, promete compatibilidade com todos os programas desenvolvidos para 16 e 32 bits. O objetivo é oferecer um caminho de baixo custo para que os usuários façam essa transição de forma bastante suave. Com uma arquitetura compatível com o mundo x86, os fabricantes de placas, de software e os usuários podem gerenciar mais facilmente seus investimentos. A ideia é oferecer uma ponte segura para a transição de 32 para 64 bits. A computação de 64 bits está voltada para aplicações que têm uma grande “fome” por memória, como as grandes bases de dados, as ferramentas CAD e as simulações que, de acordo com os recursos atuais, estão limitadas pelo espaço de endereçamento de 4 GB. Até há pouco tempo, dizia-se que as CPUs RISC ultrapassariam de forma definitiva as arquiteturas CISC. Porém, isso não aconteceu e as atuais máquinas CISC se equiparam às RISC, em termos de operações com inteiros, e já diminuíram bastante desvantagem que tinham em operações com ponto-flutuante. Por isso, afirma a AMD, os próximos ganhos de desempenho terão mais a ver com as técnicas de implementação (ex: paralelismo) do que com o conjunto de instruções: RISC, CISC-64 ou VLIW. Na verdade, há um certo abuso com esses nomes, pois as atuais CPUs x86 só têm uma casca CISC, sendo seu núcleo formado por máquinas RISC. A AMD está denominando sua nova arquitetura de “x86-64” e ela será iniciada com uma família de processadores que tem o nome código “Hammer”. As promessas apontam para a comercialização ainda no final deste ano. A estratégia de 64 bits da AMD é a extensão das atuais CPUs x86 para trabalharem em 64 bits, com a introdução do chamado Modo Longo. Essa solução é segura pois já foi empregada por ocasião da transição de 16 bits (CPUs 8088 e 286) para 32 bits (CPUs 386 e diante). Desde há muito tempo, as CPUs de 32 bits operam em dois modos. Quando em modo real, elas ficam iguais ao antigo 8088, porém, quando em modo protegido, elas oferecem recursos de 32 bits, junto com gerenciadores de tarefas e de memória. A arquitetura x86-64 oferece um novo modo denominado “Modo Longo”, em inglês “long mode”, que serve para colocar a CPU operando a 64 bits. Quando em Modo Longo, além dos recursos de 64 bits, são oferecidos registradores estendidos para 64 bits e, além disso, novos registradores foram adicionados. Passemos ao estudo desse novo modo. O Modo Longo é ativado através de um bit de controle chamado LMA, do inglês “Long Mode Active”. Quando o LMA estiver desativado, o processador operará no modo padrão x86 e será compatível com os sistemas operacionais e aplicativos de 16 e 32 bits, ou seja, será compatível com tudo que existe nos dias de hoje. Quando o LMA for ativado (Modo Longo), a extensão de 64 bits estará habilitada, oferecendo uma nova CPU de 64 bits. O Modo Longo é ainda dividido em dois submodos: o Modo 64-bits e o Modo Compatível. Esses dois submodos são controlados pelos bits D e L, presentes no descritor apontado pelo registrador CS (Segmento de Código). O Modo Compatível é interessante porque permite que, a nível de programa, se rodem aplicativos de 16 ou 32 bits dentro do Modo 64-bits. É algo semelhante ao modo virtual 86 dos processadores 386. A Figura 1 apresenta um quadro explicativo desses modos. Figura 1: Modos de operação da família x86-64. O antigo modo x86 (32 ou 16 bits) é denominado Modo Legal (LMA=0). Quando nesse modo, as CPUs x86-64 podem trabalhar com dados de 16 ou 32 bits. Note que, quando nesse modo, o estado do bit CS.L não tem significado, ou seja, ele é um “don’t care”. Quando colocado em Modo Longo 64-bits (LMA=1, CS.L=1 e CS.D=0), o tamanho padrão do operando é de 32 bits e o tamanho padrão para o endereçamento é de 64 bits. Com o uso de prefixos de instrução, o tamanho do operando pode ser alterado para 64 ou 16 bits e o tamanho do endereço para 32 bits. Se colocado no Modo Longo Compatível (LMA=1 e CS.L=0), passa a existir a compatibilidade binária com as aplicações escritas em 16 e 32 bits x86. Isso é interessante, pois um sistema operacional em Modo Longo pode rodar os atuais programas de 16 e 32 bits apenas colocando em zero o bit CS.L do descritor apontado pelo segmento de código desses aplicativos. No submodo Compatível, o bit CS.D continua a selecionar entre os modos de 16 e 32 bits. Deve ainda ser notado que, quando o processador está no Modo Legal, o estado do bit CS.L não tem significado, ou seja, é um “don’t care”. A Figura 2 apresenta os detalhes de programação dessa nova arquitetura. Figura 2: Características de programação da arquitetura x86-64 da AMD. Vamos agora dar uma olhada mais cuidadosa no Modo Longo. Como já foi visto, o Modo Longo permite o uso dos recursos de 64 bits, ao mesmo tempo que oferece o submodo Compatível para rodar aplicações de 16 ou 32 bits. Esse modo traz uma grande quantidade de recursos, que estão listados a seguir: Endereçamento virtual de 64 bits; Registradores estendidos para 64 bits; Adição de 8 registradores (R8-R15); Adição de 8 registradores para SIMD (XMM8-XMM15); Ponteiro de instruções com 64 bits; Modo de endereçamento absoluto (“flat”). A adição de novos registradores para operações SIMD torna disponível um total de 16 registradores multimídia. Os novos registradores de finalidade geral vêm a diminuir um pouco uma das deficiências da arquitetura x86, que é a pequena quantidade de registradores. Para definir sua lógica de registradores, a AMD simplesmente estendeu o esquema usado para os registradores de 16 e 32 bits. Assim, continua sendo possível acessar de forma fracionada os registradores herdados do antigo 8086. Por exemplo, o registrador RAX pode ser acessado como um único bloco de 64 bits, mas também é possível acessar somente sua metade inferior através do registrador EAX. Além disso, também está acessível uma porção de 16 bits (AX) e duas porções de 8 bits (AH e AL). É claro que AX é formado pela justaposição dos registradores AH com AL. Assim é mantida toda compatibilidade com os antigos ambientes x86. A Figura 3 ilustra esses possíveis fracionamentos. Figura 3: Esquema de fracionamento dos registradores herdados da arquitetura x86-64. Os avanços da tecnologia de integração e o aumento de velocidade do relógio deverão possibilitar um maior desempenho destas CPUs, mesmo quando operando no Modo Legal. Com essa arquitetura, a AMD espera oferecer um caminho tranqüilo para a transição de 32 para 64 bits. No passado, uma transição não tão tranqüila, devido ao novo modelo de memória, permitiu uma evolução dos 16 bits (8086 e 286) para os 32 bits (386 em diante). A AMD aposta que, ao invés de mudar completamente a arquitetura, o sucesso estará com quem mantiver a compatibilidade. -
 Desde 1994, Intel e HP vêm trabalhando numa proposta de 64 bits. Sua arquitetura deveria possibilitar aos processadores CISC um passo grande o suficiente para ultrapassar os processadores RISC. Usando a técnica denominada VLIW, ainda experimental na época, e criando o modelo EPIC, eles propuseram a arquitetura Merced, que ficou prometida para início do ano 2000. Como a conjuntura mudou, os processadores Pentium III e IV e o Athlon ofereceram desempenho excepcional, ultrapassando 1 GHz, e ainda devido ao preço elevado dessa nova arquitetura e a pouca disponibilidade de programas para 64 bits, o cronograma foi atrasado e o lançamento da arquitetura IA-64 deverá ocorrer somente neste ano. A sigla VLIW significa “Palavra de Instrução Muito Grande”, do inglês “Very Large Instruction Word”. Processadores que usam essa técnica acessam a memória transferindo longas palavras de programa, sendo que, em cada palavra, estão empacotadas várias instruções. No caso da IA-64, são usadas três instruções para cada pacote de 128 bits. Como cada instrução tem 41 bits, sobram 5 bits que são usados para indicar os tipos de instruções que foram empacotadas. A Figura 1 apresenta o esquema de empacotamento das instruções. Esse empacotamento diminui a quantidade de acessos à memória, cabendo ao compilador a tarefa de agrupar as instruções de forma a tirar o melhor proveito da arquitetura. Figura 1: Empacotamento das instruções usada na arquitetura IA-64. Como já foi dito, o campo de 5 bits, rotulado como “Indicador”, serve para indicar os tipos de instruções empacotadas. Esses 5 bits oferecem 32 tipos de empacotamentos possíveis que, na verdade, são reduzidos para 24 tipos, já que 8 não são utilizados Cada instrução usa um dos recursos da CPU, que estão listados a seguir, e que podem ser identificados na Figura 2: Unidade I: números inteiros; Unidade F - operações a ponto-flutuante; Unidade M - acessos à memória; e Unidade B - tratamento de desvios. A arquitetura que a Intel propõe para executar essas instruções, que foi denominada Itanium, é versátil e promete desempenho através da execução simultânea (paralela) de até 6 instruções. A Figura 2 apresenta o diagrama em blocos desta arquitetura que faz uso de um “pipeline” de 10 estágios. Figura 2: Diagrama em blocos da CPU Itanium (arquitetura IA-64). As arquiteturas IA-64 recebem a sigla EPIC, do inglês “Explicit Parallel Instruction Computing”, que é traduzida como “Computação com Paralelismo de Instruções Explícito”. Com essa sigla, a Intel quer dizer que o compilador será o grande responsável por determinar e explicitar o paralelismo presente nas instruções a serem executadas. Isto é uma combinação de conceitos chamados de especulação, predicação e paralelismo explícito. A seguir, estudaremos rapidamente cada um deles. O Paralelismo a Nível de Instrução (IPL - “Instruction Level Parallelism”) é a habilidade de executar múltiplas instruções ao mesmo tempo. Como já vimos, a arquitetura IA-64 permite empacotar instruções independentes para serem executadas em paralelo e, por cada período de relógio, é capaz de tratar múltiplos pacotes. Devido ao grande número de recursos em paralelo, tais como grande quantidade de registradores e múltiplas unidades de execução, é possível ao compilador gerenciar e programar a computação em paralelo. Os compiladores usados para as arquiteturas tradicionais são limitados em sua capacidade especulativa porque nem sempre há como ter certeza se a especulação será corretamente gerenciada pelo processador. A arquitetura IA-64 permite ao compilador explorar a informação especulativa sem sacrificar a correta execução de uma aplicação. A arquitetura IA-64 tem mecanismos denominados indicador de instruções, sugestões para desvios e cache, que permitem ao compilador enviar ao processador informações obtidas durante o tempo de compilação. Essas informações minimizam as penalidades advindas dos desvios e ausências de cache (“cache misses”). Existem dois tipos de especulação: a de dados e a de controle. Com a especulação, o compilador antecipa uma operação de forma que sua latência (tempo gasto) seja retirada do caminho crítico. A especulação é uma forma de permitir ao compilador evitar que operações lentas atrapalhem o paralelismo das instruções. A especulação de controle é a execução de uma operação antes do desvio que a precede. Por sua vez, a especulação de dados é a execução de uma carga da memória (“load”) antes de uma operação de armazenagem (“store”) que a precede e com a qual pode estar relacionada. Com a “predicação”, do inglês “predication”, marca-se com predicados todos os ramos dos desvios condicionais que, em seguida, são despachados para a execução em paralelo, porém, executa-se apenas os que forem necessários. Assim, é possível preparar a execução das instruções antes mesmo de se ter resolvido o desvio condicional. Além da remoção de desvios através do uso de predicados, na arquitetura IA-64, existe ainda uma série de mecanismos que devem diminuir o erro na predição dos desvios e o custo quando este erro acontece. A arquitetura IA-64 traz uma grande quantidade de registradores. São 128 registradores gerais (inteiros), 128 registradores de ponto-flutuante, 64 registradores de 1 bit, para os predicados, e diversos outros registradores para configuração, gerenciamento e monitoração do desempenho da CPU. Para finalizar, vemos que a Intel promete compatibilidade com os aplicativos de 32 bits (IA-32). Eles deverão rodar sem qualquer alteração desde que o sistema operacional e o “firmware” tenham recursos para isso. Deverá ser possível rodar aplicativos no modo real (16 bits), modo protegido (32 bits) e modo virtual 86 (16 bits). Com isso, eles querem dizer que a CPU poderá operar no modo IA-64 ou modo IA-32. Existem instruções especiais para transitar de um modo para outro, como mostrado na Figura 3. Figura 3: Modelo de transição dos conjuntos de instruções. As três instruções que fazem a transição entre os conjunto de instruções são: JMPE (IA-32): salta para um instrução de 64 bits e muda para o modo IA-64; br.ia (IA-64): desvia para uma instrução de 32 bits e muda para o modo IA-32; Interrupções transicionam para o modo IA-64, permitindo assim o atendimento de todas as condições de interrupção e rfi (IA-64): é o retorno de interrupção; o retorno se dá tanto para uma situação IA-32 quanto para uma IA-64, dependendo da situação presente no momento em que a interrupção for invocada. Com este artigo e com o anterior, que abordaram as arquiteturas de 64 bits da Intel e AMD, terminamos de falar sobre os processadores para o início do milênio. É importante citar que já existem máquinas rodando versões 64 bits do Windows e Linux. Por ora, mais que o desempenho, o que mais nos preocupa é a compatibilidade com nossos programas atuais. Realmente, há que se comprovar o quanto essas arquiteturas de 64 bits serão compatíveis com nossos programas de 32 ou 16 bits. Esperamos que, em menos de um ano, já tenhamos resposta para essa inquietude. Para finalizar essa parte de CPUs de 64 bits, é muito bom ver o quanto as duas empresas disputam o mercado dos processadores de alto desempenho. Isso nos garante o acesso a computadores cada vez mais maravilhosos e baratos. Concluindo, gostaríamos de comentar o enorme espaço que ainda existe para a evolução da eletrônica e conseqüentemente para a evolução dos computadores. Mais importante que o surgimento dos supercomputadores, essa nova era será marcada pela permeabilidade dos computadores. Será a era dos computadores invisíveis. Eles estarão presentes em quase todo dispositivo moderno. No momento, eles habitam nossos televisores, fornos de microondas, carros, relógios, aparelhos de som, DVD, etc.. Num futuro próximo, eles invadirão a geladeira, a torradeira, o aparelho de ar condicionado e todos nos aparelhos de uso cotidiano. Já ultrapassamos a era da eletrônica barata e estamos entrando na era da inteligência barata.
Desde 1994, Intel e HP vêm trabalhando numa proposta de 64 bits. Sua arquitetura deveria possibilitar aos processadores CISC um passo grande o suficiente para ultrapassar os processadores RISC. Usando a técnica denominada VLIW, ainda experimental na época, e criando o modelo EPIC, eles propuseram a arquitetura Merced, que ficou prometida para início do ano 2000. Como a conjuntura mudou, os processadores Pentium III e IV e o Athlon ofereceram desempenho excepcional, ultrapassando 1 GHz, e ainda devido ao preço elevado dessa nova arquitetura e a pouca disponibilidade de programas para 64 bits, o cronograma foi atrasado e o lançamento da arquitetura IA-64 deverá ocorrer somente neste ano. A sigla VLIW significa “Palavra de Instrução Muito Grande”, do inglês “Very Large Instruction Word”. Processadores que usam essa técnica acessam a memória transferindo longas palavras de programa, sendo que, em cada palavra, estão empacotadas várias instruções. No caso da IA-64, são usadas três instruções para cada pacote de 128 bits. Como cada instrução tem 41 bits, sobram 5 bits que são usados para indicar os tipos de instruções que foram empacotadas. A Figura 1 apresenta o esquema de empacotamento das instruções. Esse empacotamento diminui a quantidade de acessos à memória, cabendo ao compilador a tarefa de agrupar as instruções de forma a tirar o melhor proveito da arquitetura. Figura 1: Empacotamento das instruções usada na arquitetura IA-64. Como já foi dito, o campo de 5 bits, rotulado como “Indicador”, serve para indicar os tipos de instruções empacotadas. Esses 5 bits oferecem 32 tipos de empacotamentos possíveis que, na verdade, são reduzidos para 24 tipos, já que 8 não são utilizados Cada instrução usa um dos recursos da CPU, que estão listados a seguir, e que podem ser identificados na Figura 2: Unidade I: números inteiros; Unidade F - operações a ponto-flutuante; Unidade M - acessos à memória; e Unidade B - tratamento de desvios. A arquitetura que a Intel propõe para executar essas instruções, que foi denominada Itanium, é versátil e promete desempenho através da execução simultânea (paralela) de até 6 instruções. A Figura 2 apresenta o diagrama em blocos desta arquitetura que faz uso de um “pipeline” de 10 estágios. Figura 2: Diagrama em blocos da CPU Itanium (arquitetura IA-64). As arquiteturas IA-64 recebem a sigla EPIC, do inglês “Explicit Parallel Instruction Computing”, que é traduzida como “Computação com Paralelismo de Instruções Explícito”. Com essa sigla, a Intel quer dizer que o compilador será o grande responsável por determinar e explicitar o paralelismo presente nas instruções a serem executadas. Isto é uma combinação de conceitos chamados de especulação, predicação e paralelismo explícito. A seguir, estudaremos rapidamente cada um deles. O Paralelismo a Nível de Instrução (IPL - “Instruction Level Parallelism”) é a habilidade de executar múltiplas instruções ao mesmo tempo. Como já vimos, a arquitetura IA-64 permite empacotar instruções independentes para serem executadas em paralelo e, por cada período de relógio, é capaz de tratar múltiplos pacotes. Devido ao grande número de recursos em paralelo, tais como grande quantidade de registradores e múltiplas unidades de execução, é possível ao compilador gerenciar e programar a computação em paralelo. Os compiladores usados para as arquiteturas tradicionais são limitados em sua capacidade especulativa porque nem sempre há como ter certeza se a especulação será corretamente gerenciada pelo processador. A arquitetura IA-64 permite ao compilador explorar a informação especulativa sem sacrificar a correta execução de uma aplicação. A arquitetura IA-64 tem mecanismos denominados indicador de instruções, sugestões para desvios e cache, que permitem ao compilador enviar ao processador informações obtidas durante o tempo de compilação. Essas informações minimizam as penalidades advindas dos desvios e ausências de cache (“cache misses”). Existem dois tipos de especulação: a de dados e a de controle. Com a especulação, o compilador antecipa uma operação de forma que sua latência (tempo gasto) seja retirada do caminho crítico. A especulação é uma forma de permitir ao compilador evitar que operações lentas atrapalhem o paralelismo das instruções. A especulação de controle é a execução de uma operação antes do desvio que a precede. Por sua vez, a especulação de dados é a execução de uma carga da memória (“load”) antes de uma operação de armazenagem (“store”) que a precede e com a qual pode estar relacionada. Com a “predicação”, do inglês “predication”, marca-se com predicados todos os ramos dos desvios condicionais que, em seguida, são despachados para a execução em paralelo, porém, executa-se apenas os que forem necessários. Assim, é possível preparar a execução das instruções antes mesmo de se ter resolvido o desvio condicional. Além da remoção de desvios através do uso de predicados, na arquitetura IA-64, existe ainda uma série de mecanismos que devem diminuir o erro na predição dos desvios e o custo quando este erro acontece. A arquitetura IA-64 traz uma grande quantidade de registradores. São 128 registradores gerais (inteiros), 128 registradores de ponto-flutuante, 64 registradores de 1 bit, para os predicados, e diversos outros registradores para configuração, gerenciamento e monitoração do desempenho da CPU. Para finalizar, vemos que a Intel promete compatibilidade com os aplicativos de 32 bits (IA-32). Eles deverão rodar sem qualquer alteração desde que o sistema operacional e o “firmware” tenham recursos para isso. Deverá ser possível rodar aplicativos no modo real (16 bits), modo protegido (32 bits) e modo virtual 86 (16 bits). Com isso, eles querem dizer que a CPU poderá operar no modo IA-64 ou modo IA-32. Existem instruções especiais para transitar de um modo para outro, como mostrado na Figura 3. Figura 3: Modelo de transição dos conjuntos de instruções. As três instruções que fazem a transição entre os conjunto de instruções são: JMPE (IA-32): salta para um instrução de 64 bits e muda para o modo IA-64; br.ia (IA-64): desvia para uma instrução de 32 bits e muda para o modo IA-32; Interrupções transicionam para o modo IA-64, permitindo assim o atendimento de todas as condições de interrupção e rfi (IA-64): é o retorno de interrupção; o retorno se dá tanto para uma situação IA-32 quanto para uma IA-64, dependendo da situação presente no momento em que a interrupção for invocada. Com este artigo e com o anterior, que abordaram as arquiteturas de 64 bits da Intel e AMD, terminamos de falar sobre os processadores para o início do milênio. É importante citar que já existem máquinas rodando versões 64 bits do Windows e Linux. Por ora, mais que o desempenho, o que mais nos preocupa é a compatibilidade com nossos programas atuais. Realmente, há que se comprovar o quanto essas arquiteturas de 64 bits serão compatíveis com nossos programas de 32 ou 16 bits. Esperamos que, em menos de um ano, já tenhamos resposta para essa inquietude. Para finalizar essa parte de CPUs de 64 bits, é muito bom ver o quanto as duas empresas disputam o mercado dos processadores de alto desempenho. Isso nos garante o acesso a computadores cada vez mais maravilhosos e baratos. Concluindo, gostaríamos de comentar o enorme espaço que ainda existe para a evolução da eletrônica e conseqüentemente para a evolução dos computadores. Mais importante que o surgimento dos supercomputadores, essa nova era será marcada pela permeabilidade dos computadores. Será a era dos computadores invisíveis. Eles estarão presentes em quase todo dispositivo moderno. No momento, eles habitam nossos televisores, fornos de microondas, carros, relógios, aparelhos de som, DVD, etc.. Num futuro próximo, eles invadirão a geladeira, a torradeira, o aparelho de ar condicionado e todos nos aparelhos de uso cotidiano. Já ultrapassamos a era da eletrônica barata e estamos entrando na era da inteligência barata. -
 Na parte anterior, vimos algumas das máquinas mais velozes do planeta e também as promessas da computação quântica. Continuando, apreciaremos agora os computadores Cray, máquinas que sempre foram sinônimo de alto desempenho, e também alguns processadores que são interessantes, não pelas suas velocidades estonteantes, mas sim pela forma distinta de suas soluções. Computadores Cray É impossível falar de supercomputadores sem citar o pionerismo das máquinas fabricadas por Seymour Cray, que já usavam o conceito de processamento vetorial. Seu primeiro supercomputador foi o CRAY-1, fabricado em 1976. Era capaz de atingir o pico de 133 Megaflops. Em 1985, lançou o Cray-2, com o desempenho de 1,9 Gigaflops. Na época, esse computador tinha a maior memória do mundo: 2 Gigabytes. Quantidade gigantesca, mesmo para os parâmetros atuais. Após esses marcos, citamos as principais máquinas que a empresa Cray comercializa nos dias de hoje. Começamos com o Cray T-90, que usa até 32 processadores vetoriais em paralelo e chega a 60 Gigaflops. Em seguida, está o Cray T3E, que oferece até 2048 processadores, permitindo alcançar 2,5 Teraflops e que, em breve, será substituído pelo Cray SV2, ainda em fase de projeto. Finalmente, temos o Cray muita, (“MultiThread Architecture”), que pretende diminuir o trabalho de programação paralela ao oferecer vetorização e paralelização automáticas. O atual topo de linha é o Cray SV1, que traz solução para os conflitantes problemas de desempenho, preço e escalabilidade. Os supercomputadores, como é de se esperar, são máquinas caras mas que oferecem um grande desempenho. Essa característica os torna quase inacessíveis para as empresas menores. Fica então o dilema: ou gasta-se muito dinheiro e compra-se um computador de alto desempenho, ou então economiza-se dinheiro e tenta-se satisfazer-se com máquinas de desempenho inferior. Pensando nisso, a Cray projetou uma máquina escalável, cujo desempenho, de acordo com as necessidades e orçamento do cliente pode ir desde 1,2 Gigaflops até 1 Teraflops (1.000 vezes o desempenho inicial). Esse computador pode usar desde um processador (4,8 Gigaflops) até centenas de processadores, quando então atinge a marca de 1 Teraflops. São empregados dois tipos de processadores: um processador de alto desempenho (4,8 Gigaflops), chamado de MSP, e um processador convencional (1,2 Gigaflops). Até 6 MSP e até 8 processadores convencionais formam um nó. O sistema pode chegar até 32 nós, resultando em 1 Teraflops. A Figura 1 ilustra a escalabilidade desse computador. Figura 1: Escalabilidade do CRAY SV1. Em 22 de setembro de 1999, a Cray assinou um contrato com diversas agências americanas, entre elas a conhecida NSA (“National Security Agency”), aquela que trata, dentre outros temas, das limitações na exportação de programas de criptografia, para construir o SV2, que substituirá o Cray T3E. Este novo computador contará com novos processadores vetoriais e pretende atingir algumas dezenas de Teraflops. A tabela a seguir apresenta uma comparação de velocidade entre os principais computadores Cray. Figura 2: Desempenho (em Gigaflops). Abordemos agora alguns processadores que trazem novidades interessantes. A Sun Microsystems, fabricante das conhecidas estações Sun, está inovando o mercado da informática com seu processador MAJC, que em inglês se pronuncia “magic”. A sigla MAJC significa Arquitetura Microprocessada para Computação em Java, do inglês “Microprocessor Architecture for Java Computing”. De acordo com a Sun, os dados que os processadores dos servidores de rede tratam nos dias de hoje estão muito diferentes dos dados das décadas de 70 e 80. Este fato motiva as duas principais arquiteturas atuais: uma com conjunto complexo de instruções (CISC) e a outra com conjunto reduzido de instruções (RISC). Antigamente, por exemplo em uma operação de atualização de saldo, os dados que chegavam ao servidor eram utilizados imediatamente. Os servidores atuais, entretanto, antes da atualização, devem tratar primeiro da compactação e criptografia deles (e talvez até o comando de voz), para só depois realizar a operação de crédito. Isso tudo deve ser feito na taxa do fluxo de dados das redes de alta velocidade. Assim, nos modernos sistemas, os processadores devem estar aptos não só a receber os dados a taxas elevadas, mas também aptos a processá-los nesta mesma taxa. As principais exigências de hardware são velocidade de I/O e capacidade de processamento. O processador deve entrar no fluxo de dados sem gerar atrasos, ou seja, ele recebe os dados a taxas elevadas, os processa e os envia adiante nessa mesma taxa elevada. A primeira implementação da família, o MAJC-5200, tem a interface de I/O operando a 10 GB/s, quando o usual na maioria dos processadores é 1 GB/s, e sua a capacidade de processamento vem de duas CPUs, cada uma com 4 unidades funcionais VLIW (“Very Large Instruction Word”) que, além dos recursos usuais, operam como processadores de sinais digitais (DSP-“Digital Signal Processor”) e como processadores vetoriais SIMD. A CPU, como pode ser vista na Figura 3, possui 4 Unidades Funcionais (FU), numeradas de 0 até 4. Cada Unidade é um processador RISC. A UF0 é um pouco diferente das demais, pois ela é responsável por tratar da leitura e escrita de dados, que acontece através da Unidade de Carga e Armazenamento, e ainda por controlar o fluxo das operações (saltos). Por ser uma CPU tipo VLIW, as instruções de 32 bits vêm agrupadas em pacotes com até 4 instruções, 128 bytes no total, e cada uma é distribuída para uma Unidade Funcional. Se não houver interdependência, são realizadas até 4 operações por vez. O compilador é responsável por preparar o fluxo de instruções de forma a reduzir a interdependência. De acordo com a Figura 3, as instruções vêm do Cache e seguem para o Buffer de Instruções, daí passam pelos Decodificadores, têm seus Registradores acessados e vão para as Unidades Funcionais. Já os resultados são devolvidos aos Registradores graças ao Estágio de Contra-Escrita. O compartilhamento dos resultados entre as Unidades Funcionais é possível graças ao Estágio de Contra-Escrita, mas consome um ciclo. Entre UF0 e UF1, existe uma conexão que permite esse compartilhamento no mesmo ciclo de relógio. A CPU possui 224 registradores lógicos, divididos em 96 globais, que podem ser acessados por qualquer Unidade Funcional, e 32 particulares para cada UF. A Unidade de Carga e Armazenamento é responsável por gerenciar todas as operações entre a memória e os registradores. Está disponível um conjunto completo de instruções para operações inteiras e de ponto-flutuante. As unidades de 1 a 3 podem executar operações do tipo multiplica e acumula em um único ciclo. Tais instruções são fundamentais para a implementação de filtros digitais. As unidades podem operar juntas implementando um ambiente de execução tipo SIMD. Com tais instruções e operando a 500 MHz, essa CPU é capaz de obter um desempenho de 6,16 Gigaflops. Figura 3: A CPU MAJC. A Figura 4 apresenta o diagrama em blocos do processador MAJC-5200, que possui duas CPUs idênticas às mostradas na Figura 3. Deve-se notar que o cache de dados é compartilhado entre as duas CPUs, porém existe um cache de instrução para cada uma. A capacidade para aceitar altas taxas de bits deve-se à quantidade de interfaces, cada uma delas com seu próprio controlador. A memória principal é do tipo Rambus (DRDRAM) e trabalha a 1,6 GB/s. A Ponte PCI oferece recursos para DMA e I/O, a taxas de até 264 MB/s. Existem duas outras interfaces, a UPA Norte e a UPA Sul, que podem operar a até 4 GB/s. A porta UPA, que em inglês significa “Universal Port Architecture”, destina-se a interfacear dados com altas taxas, como por exemplo vídeo. Além disso tudo, existe um Processador Gráfico para, dentre outras coisas, fazer a descompressão de geometria 3D em tempo real. Figura 4: Diagrama em blocos da arquitetura MAJC-5200. Nessa arquitetura, a Sun usou o que seus engenheiros chamam de “processamento espaço-tempo”, mas que também pode ser rotulado como processamento especulativo. Graças a isso, os programadores não precisam de preocupar-se em explicitar o paralelismo de seus programas, por que essa tarefa será especulada pela máquina virtual Java. A máquina virtual examina o programa e especula se dois métodos podem rodar em dois processadores, despachando-os ao mesmo tempo. Assim, ela envia os dois métodos para dois processadores distintos, sendo que um deles (o segundo) rodará em separado, usando o que se chama de espaço de memória especulativa. Ao término do processamento, se tudo correu bem e não houve violação de dependência de dados então a área especulativa é fundida com a memória principal e o programa segue adiante. Entretanto, se tiver havido dependência entre os dados, o segundo processo é inutilizado e sua memória descartada. Esse processador não tem desempenho comparável com os processadores aqui analisados, já que ele chega apenas a 50 MIPS (mega instruções por segundo). Porém, o que o torna notável é o fato de ser totalmente construído em PLD, sigla que significa dispositivos lógicos programáveis, do inglês “Programmable Logic Device". Um dispositivo lógico programável é um circuito digital que o usuário pode configurar de forma a solucionar seu problema. É como se fosse um Lego Digital onde o usuário junta as peças para construir o circuito digital que necessita. O que a Altera fez foi fornecer, junto com seu Lego Digital, um mapa que ensina a construir um processador RISC. Note que o usuário pode alterar esse mapa e construir uma CPU RISC específica para sua necessidade. O que é mais interessante é que sobram peças de Lego dentro da caixa, ou seja, sobram circuitos programáveis dentro do chip e estes podem ser usados para implementar ainda outros circuitos digitais. Essa CPU RISC pode chegar a 50 MIPS, possui um conjunto de instruções de 16 bits, barramento de dados de 16 ou 32 bits, um “pipeline” de 5 estágios e em média executa uma instrução por ciclo. Ela usa, conforme a implementação, de 2% a 25% dos dispositivos programáveis, o que deixa bastante recurso para o usuário expandi-la colocando outros periféricos mapeados em memória, dispositivos de leitura e escrita mapeado nos bancos de registradores, ou ainda, blocos funcionais dentro da CPU. Em suma, o usuário pode modificar essa CPU, talhando-a para sua necessidade específica. A Figura 5 apresenta um diagrama em blocos do núcleo Nios, que consiste da CPU, de uma interface com memória estática ou dinâmica, de um temporizador, de uma UART, de uma PIO e de uma linha de interrupção. Além disso tudo, também são oferecidos compilador C/C++, montador e depurador. Figura 5: Diagrama em blocos da CPU RISC Nios da Altera, ressaltando que boa parte ainda está disponível. Nesta parte do artigo, continuamos a ver que o processamento paralelo infiltra-se nas mais diversas CPUs, oferecendo cada vez mais desempenho e exigindo compiladores sofisticados. O compilador já era importante para as máquinas RISC, mas agora, perante essas novas CPUs, ele assume um papel mais fundamental, pois passa a ser responsável por sugerir a especulação e a execução paralela. A Intel e a AMD também empregam bastante o processamento paralelo nas suas arquiteturas de 64 bits, como poderá ser constatado na continuação deste artigo. Verificamos ainda que os fabricantes de supercomputadores estão preocupados com o cliente intermediário e oferecem para máquinas acessíveis, mas que podem ser expandidas de forma a atingir grande desempenho. Finalmente, vemos chegar a era na qual o usuário pode projetar seu processador. É claro que isso é interessante não tanto para o usuário comum, mas sim para aqueles que fabricam equipamentos com processadores incorporados, como é o caso dos fabricantes de celulares, máquinas fax, impressoras e até mesmo aparelhos de televisão. No passado, era necessário ajustar o projeto aos processadores disponíveis no mercado. Agora, já é possível comprar a descrição do processador e modificá-lo de forma a atender, de forma minuciosa, a todas suas necessidades do projeto. Na próxima parte deste artigo veremos as soluções que Intel traz em sua arquitetura de 64 bits (IA-64). Sites Seymour Cray: http://americanhistory.si.edu/csr/comphist/cray.htm Seymour Cray: http://www.cgl.ucsf.edu/home/tef/cray/tribute.html MAJC: http://www.sun.com/microelectronics/MAJC/5200.html Altera-Nios: http://altera.com/html/products/nios.html
Na parte anterior, vimos algumas das máquinas mais velozes do planeta e também as promessas da computação quântica. Continuando, apreciaremos agora os computadores Cray, máquinas que sempre foram sinônimo de alto desempenho, e também alguns processadores que são interessantes, não pelas suas velocidades estonteantes, mas sim pela forma distinta de suas soluções. Computadores Cray É impossível falar de supercomputadores sem citar o pionerismo das máquinas fabricadas por Seymour Cray, que já usavam o conceito de processamento vetorial. Seu primeiro supercomputador foi o CRAY-1, fabricado em 1976. Era capaz de atingir o pico de 133 Megaflops. Em 1985, lançou o Cray-2, com o desempenho de 1,9 Gigaflops. Na época, esse computador tinha a maior memória do mundo: 2 Gigabytes. Quantidade gigantesca, mesmo para os parâmetros atuais. Após esses marcos, citamos as principais máquinas que a empresa Cray comercializa nos dias de hoje. Começamos com o Cray T-90, que usa até 32 processadores vetoriais em paralelo e chega a 60 Gigaflops. Em seguida, está o Cray T3E, que oferece até 2048 processadores, permitindo alcançar 2,5 Teraflops e que, em breve, será substituído pelo Cray SV2, ainda em fase de projeto. Finalmente, temos o Cray muita, (“MultiThread Architecture”), que pretende diminuir o trabalho de programação paralela ao oferecer vetorização e paralelização automáticas. O atual topo de linha é o Cray SV1, que traz solução para os conflitantes problemas de desempenho, preço e escalabilidade. Os supercomputadores, como é de se esperar, são máquinas caras mas que oferecem um grande desempenho. Essa característica os torna quase inacessíveis para as empresas menores. Fica então o dilema: ou gasta-se muito dinheiro e compra-se um computador de alto desempenho, ou então economiza-se dinheiro e tenta-se satisfazer-se com máquinas de desempenho inferior. Pensando nisso, a Cray projetou uma máquina escalável, cujo desempenho, de acordo com as necessidades e orçamento do cliente pode ir desde 1,2 Gigaflops até 1 Teraflops (1.000 vezes o desempenho inicial). Esse computador pode usar desde um processador (4,8 Gigaflops) até centenas de processadores, quando então atinge a marca de 1 Teraflops. São empregados dois tipos de processadores: um processador de alto desempenho (4,8 Gigaflops), chamado de MSP, e um processador convencional (1,2 Gigaflops). Até 6 MSP e até 8 processadores convencionais formam um nó. O sistema pode chegar até 32 nós, resultando em 1 Teraflops. A Figura 1 ilustra a escalabilidade desse computador. Figura 1: Escalabilidade do CRAY SV1. Em 22 de setembro de 1999, a Cray assinou um contrato com diversas agências americanas, entre elas a conhecida NSA (“National Security Agency”), aquela que trata, dentre outros temas, das limitações na exportação de programas de criptografia, para construir o SV2, que substituirá o Cray T3E. Este novo computador contará com novos processadores vetoriais e pretende atingir algumas dezenas de Teraflops. A tabela a seguir apresenta uma comparação de velocidade entre os principais computadores Cray. Figura 2: Desempenho (em Gigaflops). Abordemos agora alguns processadores que trazem novidades interessantes. A Sun Microsystems, fabricante das conhecidas estações Sun, está inovando o mercado da informática com seu processador MAJC, que em inglês se pronuncia “magic”. A sigla MAJC significa Arquitetura Microprocessada para Computação em Java, do inglês “Microprocessor Architecture for Java Computing”. De acordo com a Sun, os dados que os processadores dos servidores de rede tratam nos dias de hoje estão muito diferentes dos dados das décadas de 70 e 80. Este fato motiva as duas principais arquiteturas atuais: uma com conjunto complexo de instruções (CISC) e a outra com conjunto reduzido de instruções (RISC). Antigamente, por exemplo em uma operação de atualização de saldo, os dados que chegavam ao servidor eram utilizados imediatamente. Os servidores atuais, entretanto, antes da atualização, devem tratar primeiro da compactação e criptografia deles (e talvez até o comando de voz), para só depois realizar a operação de crédito. Isso tudo deve ser feito na taxa do fluxo de dados das redes de alta velocidade. Assim, nos modernos sistemas, os processadores devem estar aptos não só a receber os dados a taxas elevadas, mas também aptos a processá-los nesta mesma taxa. As principais exigências de hardware são velocidade de I/O e capacidade de processamento. O processador deve entrar no fluxo de dados sem gerar atrasos, ou seja, ele recebe os dados a taxas elevadas, os processa e os envia adiante nessa mesma taxa elevada. A primeira implementação da família, o MAJC-5200, tem a interface de I/O operando a 10 GB/s, quando o usual na maioria dos processadores é 1 GB/s, e sua a capacidade de processamento vem de duas CPUs, cada uma com 4 unidades funcionais VLIW (“Very Large Instruction Word”) que, além dos recursos usuais, operam como processadores de sinais digitais (DSP-“Digital Signal Processor”) e como processadores vetoriais SIMD. A CPU, como pode ser vista na Figura 3, possui 4 Unidades Funcionais (FU), numeradas de 0 até 4. Cada Unidade é um processador RISC. A UF0 é um pouco diferente das demais, pois ela é responsável por tratar da leitura e escrita de dados, que acontece através da Unidade de Carga e Armazenamento, e ainda por controlar o fluxo das operações (saltos). Por ser uma CPU tipo VLIW, as instruções de 32 bits vêm agrupadas em pacotes com até 4 instruções, 128 bytes no total, e cada uma é distribuída para uma Unidade Funcional. Se não houver interdependência, são realizadas até 4 operações por vez. O compilador é responsável por preparar o fluxo de instruções de forma a reduzir a interdependência. De acordo com a Figura 3, as instruções vêm do Cache e seguem para o Buffer de Instruções, daí passam pelos Decodificadores, têm seus Registradores acessados e vão para as Unidades Funcionais. Já os resultados são devolvidos aos Registradores graças ao Estágio de Contra-Escrita. O compartilhamento dos resultados entre as Unidades Funcionais é possível graças ao Estágio de Contra-Escrita, mas consome um ciclo. Entre UF0 e UF1, existe uma conexão que permite esse compartilhamento no mesmo ciclo de relógio. A CPU possui 224 registradores lógicos, divididos em 96 globais, que podem ser acessados por qualquer Unidade Funcional, e 32 particulares para cada UF. A Unidade de Carga e Armazenamento é responsável por gerenciar todas as operações entre a memória e os registradores. Está disponível um conjunto completo de instruções para operações inteiras e de ponto-flutuante. As unidades de 1 a 3 podem executar operações do tipo multiplica e acumula em um único ciclo. Tais instruções são fundamentais para a implementação de filtros digitais. As unidades podem operar juntas implementando um ambiente de execução tipo SIMD. Com tais instruções e operando a 500 MHz, essa CPU é capaz de obter um desempenho de 6,16 Gigaflops. Figura 3: A CPU MAJC. A Figura 4 apresenta o diagrama em blocos do processador MAJC-5200, que possui duas CPUs idênticas às mostradas na Figura 3. Deve-se notar que o cache de dados é compartilhado entre as duas CPUs, porém existe um cache de instrução para cada uma. A capacidade para aceitar altas taxas de bits deve-se à quantidade de interfaces, cada uma delas com seu próprio controlador. A memória principal é do tipo Rambus (DRDRAM) e trabalha a 1,6 GB/s. A Ponte PCI oferece recursos para DMA e I/O, a taxas de até 264 MB/s. Existem duas outras interfaces, a UPA Norte e a UPA Sul, que podem operar a até 4 GB/s. A porta UPA, que em inglês significa “Universal Port Architecture”, destina-se a interfacear dados com altas taxas, como por exemplo vídeo. Além disso tudo, existe um Processador Gráfico para, dentre outras coisas, fazer a descompressão de geometria 3D em tempo real. Figura 4: Diagrama em blocos da arquitetura MAJC-5200. Nessa arquitetura, a Sun usou o que seus engenheiros chamam de “processamento espaço-tempo”, mas que também pode ser rotulado como processamento especulativo. Graças a isso, os programadores não precisam de preocupar-se em explicitar o paralelismo de seus programas, por que essa tarefa será especulada pela máquina virtual Java. A máquina virtual examina o programa e especula se dois métodos podem rodar em dois processadores, despachando-os ao mesmo tempo. Assim, ela envia os dois métodos para dois processadores distintos, sendo que um deles (o segundo) rodará em separado, usando o que se chama de espaço de memória especulativa. Ao término do processamento, se tudo correu bem e não houve violação de dependência de dados então a área especulativa é fundida com a memória principal e o programa segue adiante. Entretanto, se tiver havido dependência entre os dados, o segundo processo é inutilizado e sua memória descartada. Esse processador não tem desempenho comparável com os processadores aqui analisados, já que ele chega apenas a 50 MIPS (mega instruções por segundo). Porém, o que o torna notável é o fato de ser totalmente construído em PLD, sigla que significa dispositivos lógicos programáveis, do inglês “Programmable Logic Device". Um dispositivo lógico programável é um circuito digital que o usuário pode configurar de forma a solucionar seu problema. É como se fosse um Lego Digital onde o usuário junta as peças para construir o circuito digital que necessita. O que a Altera fez foi fornecer, junto com seu Lego Digital, um mapa que ensina a construir um processador RISC. Note que o usuário pode alterar esse mapa e construir uma CPU RISC específica para sua necessidade. O que é mais interessante é que sobram peças de Lego dentro da caixa, ou seja, sobram circuitos programáveis dentro do chip e estes podem ser usados para implementar ainda outros circuitos digitais. Essa CPU RISC pode chegar a 50 MIPS, possui um conjunto de instruções de 16 bits, barramento de dados de 16 ou 32 bits, um “pipeline” de 5 estágios e em média executa uma instrução por ciclo. Ela usa, conforme a implementação, de 2% a 25% dos dispositivos programáveis, o que deixa bastante recurso para o usuário expandi-la colocando outros periféricos mapeados em memória, dispositivos de leitura e escrita mapeado nos bancos de registradores, ou ainda, blocos funcionais dentro da CPU. Em suma, o usuário pode modificar essa CPU, talhando-a para sua necessidade específica. A Figura 5 apresenta um diagrama em blocos do núcleo Nios, que consiste da CPU, de uma interface com memória estática ou dinâmica, de um temporizador, de uma UART, de uma PIO e de uma linha de interrupção. Além disso tudo, também são oferecidos compilador C/C++, montador e depurador. Figura 5: Diagrama em blocos da CPU RISC Nios da Altera, ressaltando que boa parte ainda está disponível. Nesta parte do artigo, continuamos a ver que o processamento paralelo infiltra-se nas mais diversas CPUs, oferecendo cada vez mais desempenho e exigindo compiladores sofisticados. O compilador já era importante para as máquinas RISC, mas agora, perante essas novas CPUs, ele assume um papel mais fundamental, pois passa a ser responsável por sugerir a especulação e a execução paralela. A Intel e a AMD também empregam bastante o processamento paralelo nas suas arquiteturas de 64 bits, como poderá ser constatado na continuação deste artigo. Verificamos ainda que os fabricantes de supercomputadores estão preocupados com o cliente intermediário e oferecem para máquinas acessíveis, mas que podem ser expandidas de forma a atingir grande desempenho. Finalmente, vemos chegar a era na qual o usuário pode projetar seu processador. É claro que isso é interessante não tanto para o usuário comum, mas sim para aqueles que fabricam equipamentos com processadores incorporados, como é o caso dos fabricantes de celulares, máquinas fax, impressoras e até mesmo aparelhos de televisão. No passado, era necessário ajustar o projeto aos processadores disponíveis no mercado. Agora, já é possível comprar a descrição do processador e modificá-lo de forma a atender, de forma minuciosa, a todas suas necessidades do projeto. Na próxima parte deste artigo veremos as soluções que Intel traz em sua arquitetura de 64 bits (IA-64). Sites Seymour Cray: http://americanhistory.si.edu/csr/comphist/cray.htm Seymour Cray: http://www.cgl.ucsf.edu/home/tef/cray/tribute.html MAJC: http://www.sun.com/microelectronics/MAJC/5200.html Altera-Nios: http://altera.com/html/products/nios.html -
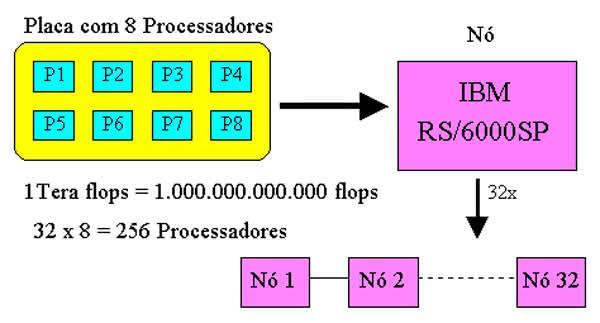 Na primeira parte deste artigo vimos uma pequena e rápida resenha histórica sobre os computadores. A parte anterior foi dedicada ao estudo da evolução da arquitetura serial para a arquitetura paralela. Agora, nesta terceira parte, vamos analisar algumas arquiteturas paralelas que foram propostas pela IBM. Veremos, não só o mais poderoso computador da atualidade, como também o projeto mais ambicioso do momento. Faremos ainda uma breve exposição sobre os computadores quânticos. Como vamos comparar velocidade de máquinas de alto desempenho, necessitaremos de uma unidade de medida. Em tais casos, a velocidade é medida pela quantidade de operações de ponto-flutuante por segundo, abreviado por flops (do inglês “float operations per second”). Como os valores são elevados, utilizam-se os multiplicadores listados na tabela ao final deste artigo. Assim preparados, iniciamos nosso estudo com um computador enxadrista. A máquina chamada “Deep Blue”[1] ainda é o mais poderoso computador voltado para o jogo de xadrez. Mas, o que será que tem de interessante uma máquina que joga xadrez? Muita coisa quando esta máquina possui uma arquitetura paralela capaz de realizar 1.000.000.000.000 operações de ponto-flutuante por segundo (1Teraflops). A arquitetura é bem simples: o “Deep Blue” está montado sobre estações de trabalho IBM RS/6000SP (P2SC). Cada estação é um nó e cada nó usa um placa microcanal contendo 8 processadores VLSI. Como são empregados 32 nós, chega-se a um total de 256 processadores trabalhando em paralelo, como mostrado na Figura 1, onde uma letra “P” é usada para representar cada processador. Figura 1: Arquitetura do Computador “Deep Blue” com seus 256 processadores. Tal arquitetura, capaz de analisar 200 milhões de posições de xadrez por segundo, duelou com o mestre Garry Kasparov, cuja capacidade de análise é de aproximadamente 3 posições por segundo. Realmente, foi uma batalha desigual. No dia 11 de maio, foi iniciada a disputa de 6 partidas, que terminou em 3,5 x 2,5 a favor do “Deep Blue”. Deve-se notar que Kasparov ainda foi capaz de ganhar a primeira e empatar três, perdendo apenas duas partidas. Kasparov, pelo segundo lugar ganhou US$ 400.000,00, enquanto que o “Deep Blue”, o vencedor, levou US$ 700.000,00 (mas infelizmente ele não teve onde gastar). Figura 2: Kasparov versus “Deep Blue”. A habilidade do “Deep Blue” em jogar xadrez vem da chamada “função de avaliação”. Esta função é um algoritmo que mede a qualidade de uma dada posição de xadrez. Posições com valores positivos são boas para as brancas, enquanto que aquelas com valores negativos são boas para as pretas. Se o cômputo total é positivo, as brancas estão em vantagem. A função de avaliação leva em conta 4 valores que são básicos para o xadrez: material, posição, segurança do Rei e tempo. O material é calculado segundo o valor das peças, o peão vale 1 e assim por diante até a Rainha que vale 9. O Rei, é claro, está além desses valores pois sua perda implica em derrota. A posição é calculada ao olhar suas peças e contar o número de posições seguras que eles podem atacar. A segurança do Rei é medida em função de sua capacidade defensiva. O tempo está relacionado com o desenvolvimento do jogo sobre o tabuleiro. Além disso tudo, o “Deep Blue” não usa força bruta ao avaliar as posições, mas sim seleciona alguns caminhos com bom potencial e elimina as buscas irrelevantes. Aproveitamos ainda para elucidar alguns pontos sobre este embate. O “Deep Blue” não usa inteligência artificial (IA) e tampouco aprende enquanto joga com seu oponente. Ao invés disso, ele trabalha como um sistema especialista que analisa seu vasto sistema de informações. Por exemplo, ele consulta sua base de dados com todas as aberturas dos últimos 100 anos e então calcula qual a melhor resposta ao movimento do oponente. Ele não pensa, mas sim, apenas reage e foi aí onde Kasparov tinha sua vantagem. Mas é claro que, com todos esses recursos, o “Deep Blue” é de certa forma “força bruta” contra a inteligência de Kasparov, que teve que jogar contra os fantasmas de todos os grandes mestres do passado. Além disso, a máquina nunca esquece ou se distrai. Para terminar este tópico, perguntamo-nos por que tanto dinheiro para jogar xadrez? O principal objetivo não está no jogo, mas sim na busca de uma arquitetura rápida o suficiente para apresentar resultados práticos. Para isso, o xadrez é um excelente desafio, pois, com suas 64 células, oferece um problema matemático extremamente complexo. Ao provar sua eficiência nessa área, a IBM demonstrou ser capaz de oferecer computadores para os problemas que ainda desafiam as atuais máquinas. E, no dia seguinte à vitória, suas ações subiram. O mais rápido computador da atualidade chama-se “Blue Pacific” e foi entregue em 28 de outubro de 1998. O termo ASCI vem de “Accelerate Strategic Computing Iniciative”, traduzido como “Iniciativa para Aceleração da Computação Estratégica”, que é o nome do programa do Departamento de Energia Norte-Americano para acelerar os avanços nas tecnologias necessárias para simular numericamente dispositivos nucleares, eliminando assim a necessidade do teste físico. Ele emprega 5.856 processadores que, operando cada um a cerca de 333 MHz, entregam uma potência de aproximadamente 4 Teraflops, ou, em outros termos, é 15.000 vezes mais rápido que um PC convencional, consumindo o equivalente a 324 secadores de cabelo. Uma pessoa com um calculadora de mão levaria 63 mil anos para realizar as operações que esse computador faz em 1 segundo. A tabela a seguir resume suas principais características. Processadores 5.856 Nós 1.464 Memória 2,6 Terabytes Armazenagem 75 Terabytes Desempenho 3,88 Teraflops Potência 486 kW Preço US$ 94 milhões Em 6 de dezembro de 1999, a IBM anunciou uma pesquisa de US$ 100 milhões com o objetivo de construir um computador que será 500 vezes mais poderoso que o mais rápido computador da atualidade. Esse novo computador, apelidado de “Blue Gene” será capaz de ultrapassar a marca de 1 quadrilhão de operações por segundo, ou seja, 1 Petaflops (10^15 flops). Essa marca o torna 1.000 vezes mais poderoso que o “Deep Blue” e cerca de 2 milhões de vezes mais rápido que um PC topo de linha. Essa maciça capacidade de processamento será usada inicialmente para modelar o “dobramento” das proteínas humanas. As proteínas controlam todos os processos celulares do corpo humano. Formadas por cadeias de aminoácidos, são unidas como anéis em uma corrente e dobram-se de formas altamente complexas. Sua forma tridimensional determina sua função. Qualquer mudança na forma altera dramaticamente a função da proteína. Mesmo uma pequena alteração no processo de dobragem pode transformar uma proteína desejável em uma doença. Assim, aprender mais sobre como as proteínas são dobradas deverá possibilitar aos pesquisadores médicos uma melhor compreensão das doenças e, em conseqüência, de suas curas. A comunidade científica considera o problema de dobragem das proteínas como um dos grandes desafios científicos da atualidade e sua solução somente pode ser alcançada com a tecnologia de computação de alto desempenho que, com certeza, terá grande impacto científico e econômico. A expectativa da IBM é atingir os Petaflops em 5 anos, um terço do que seria esperado segundo a Lei de Moore. A IBM denomina sua abordagem para este computador de SMASH, “Simple, Many and Self-Hearing”, que seria traduzido como “Simples, Muitos e Auto-Curativo”. Três tópicos distinguem essa arquitetura SMASH: Redução dramática do número de instruções, permitindo que os processadores sejam rápidos, de baixo consumo e ocupem pouca área do CI; Facilidade no processamento maciçamente paralelo, permitindo mais de 8 milhões de “threads”; Garantia de um computador auto-estável e auto-curativo, sobrepujando falhas de processadores e de “threads”. O “Blue Gene” consistirá de mais de 1 milhão de processadores, cada um capaz de oferecer 1 bilhão de operações por segundo, ou seja, 1 Gigaflops, como está mostrado na Figura 3. Trinta e dois desses processadores serão integrados em um único CI, resultando em 32 Gigaflops. Uma placa de 2 pés por 2 pés receberá 64 CIs, levando a 2 Teraflops. Somente essa placa já é capaz de igualar o desempenho do “Blue Pacific”, que tem 8.000 pés quadrados. Oito dessas placas (16 Teraflops) serão colocadas em “racks” de 6 pés. Finalmente 64 “racks” constituirão o estado final do computador, ocupando uma área menor que 2.000 pés quadrados. Figura 3: Arquitetura do “Blue Gene”, com seu 1 milhão de processadores. Agora teremos a sensação de que entramos no campo da ficção científica. Os computadores tradicionais trabalham com elementos básicos que podem assumir dois estados (ou dois bits): 0 ou 1. Normalmente, usam-se transistores ou “flip-flops” para representá-los. Olhando para o lado da física atômica, uma partícula quântica, como o elétron ou núcleos atômicos, pode existir em dois estados: com o “spin” para cima ou para baixo. Ora, isto constitui um bit quântico ou “qubit”. Quando o spin está para cima, o átomo pode ser lido como 1 e, quando o spin está para baixo, é lido como 0. Os qubits diferem dos bits tradicionais porque um núcleo atômico pode estar num estado de superposição, representando simultaneamente 0 e 1 e tudo o mais que existe entre esses valores. Mais ainda, sem a interferência do ambiente externo, os spins podem se “relacionar” de tal forma que efetivamente conectam os qubits de um computador quântico. Dois átomos “relacionados” atuam em conjunto: quando um está na posição para cima e o outro é garantido estar na posição para baixo. A combinação de superposição e “relacionamento” é o que permite a um computador quântico ter um enorme poder de processamento, possibilitando-o a realizar cálculos de forma maciçamente paralela e de forma não linear. Para certos tipos de cálculos, como por exemplo os complexos algoritmos para criptografia, um computador quântico pode realizar bilhões de cálculos em um único passo. Ao invés de resolver o problema pela adição ordenada de todos os números, um computador quântico poderia adicionar todos os números ao mesmo tempo. Assim, pela interação de um com o outro, quando isoladas do ambiente externo, os qubits podem realizar certos cálculos de forma exponencialmente mais rápida que os computadores convencionais. Diz-se que o computador quântico começa onde a Lei de Moore termina. Em 15 de agosto de 2000, um time da IBM demonstrou um novo computador quântico com 5 qubits, composto portanto por 5 átomos (de flúor) fixados em uma molécula especialmente projetada de forma a permitir que os qubits (spin dos núcleos) “relacionem” entre si. Esses qubits são programados por pulsos de rádio-freqüência e detectados por meio de ressonância nuclear magnética, semelhante ao usado em hospitais. Esse computador de 5 qubits foi capaz de resolver um problema de determinação de ordem de um sistema, ou seja, a determinação do período de uma função. Os computadores convencionais calculam a solução usando iterações passo-a-passo com os valores da função até que eles comecem a repetir. O computador quântico faz isso com um novo enfoque. Por natureza, eles representam simultaneamente todos os possíveis valores da variável de entrada e, portanto, com um único passo pode analisar todos os possíveis valores da função. Apesar do potencial dos computadores quânticos ser gigantesco e encorajador, os desafios ainda são enormes. O atual computador de 5 bits é um mero instrumento de pesquisa. Ainda faltam muitos anos de trabalho para que os computadores quânticos se tornem comerciais. Os prognósticos indicam que eles deverão ter pelo menos 12 bits para poderem resolver problemas do mundo real. Espera-se que, no futuro, tais computadores venham a trabalhar como processador auxiliar para problemas matemáticos de difícil solução. Com certeza processamento de texto e Internet não são aplicações talhadas para um computador quântico. A ideia do computador quântico não é recente, ela foi proposta na década de 1970. Observa-se claramente que os grandes computadores caminham para o processamento paralelo. Basicamente, o poder está vindo, não dos megahertz do processador, mas da quantidade de processadores que em conjunto resolvem um determinado problema. Isto significa que o tamanho do grão de processamento será cada vez menor e os processos cada vez mais acoplados. Vê-se também o uso intenso da arquitetura que Flynn (página anterior) classificada como MIMD. Como substituição para o atual modelo de processamento e esperança para os novos computadores, surge o processador quântico. No próximo número veremos alguns computadores Cray e estudaremos dois processadores simples, porém inovadores. Continue lendo: Processadores para o próximo milênio - parte 4 [1] “HAL’s Legacy”, David G. Stork (Editor). Sites Deep Blue: http://www.research.ibm.com/deepblue/meet/html/d.3.2.html Todas partidas Deep Blue vs Kasparov: http://www.ishipress.com/deepblue.pgn Blue Gene: http://www.research.ibm.com/news/detail/bluegene.html Blue Pacific: http://www.rs6000.ibm.com/hardware/largescale/SP/index.html Quântico: http://www.research.ibm.com/resources/news/20000815_quantum.html
Na primeira parte deste artigo vimos uma pequena e rápida resenha histórica sobre os computadores. A parte anterior foi dedicada ao estudo da evolução da arquitetura serial para a arquitetura paralela. Agora, nesta terceira parte, vamos analisar algumas arquiteturas paralelas que foram propostas pela IBM. Veremos, não só o mais poderoso computador da atualidade, como também o projeto mais ambicioso do momento. Faremos ainda uma breve exposição sobre os computadores quânticos. Como vamos comparar velocidade de máquinas de alto desempenho, necessitaremos de uma unidade de medida. Em tais casos, a velocidade é medida pela quantidade de operações de ponto-flutuante por segundo, abreviado por flops (do inglês “float operations per second”). Como os valores são elevados, utilizam-se os multiplicadores listados na tabela ao final deste artigo. Assim preparados, iniciamos nosso estudo com um computador enxadrista. A máquina chamada “Deep Blue”[1] ainda é o mais poderoso computador voltado para o jogo de xadrez. Mas, o que será que tem de interessante uma máquina que joga xadrez? Muita coisa quando esta máquina possui uma arquitetura paralela capaz de realizar 1.000.000.000.000 operações de ponto-flutuante por segundo (1Teraflops). A arquitetura é bem simples: o “Deep Blue” está montado sobre estações de trabalho IBM RS/6000SP (P2SC). Cada estação é um nó e cada nó usa um placa microcanal contendo 8 processadores VLSI. Como são empregados 32 nós, chega-se a um total de 256 processadores trabalhando em paralelo, como mostrado na Figura 1, onde uma letra “P” é usada para representar cada processador. Figura 1: Arquitetura do Computador “Deep Blue” com seus 256 processadores. Tal arquitetura, capaz de analisar 200 milhões de posições de xadrez por segundo, duelou com o mestre Garry Kasparov, cuja capacidade de análise é de aproximadamente 3 posições por segundo. Realmente, foi uma batalha desigual. No dia 11 de maio, foi iniciada a disputa de 6 partidas, que terminou em 3,5 x 2,5 a favor do “Deep Blue”. Deve-se notar que Kasparov ainda foi capaz de ganhar a primeira e empatar três, perdendo apenas duas partidas. Kasparov, pelo segundo lugar ganhou US$ 400.000,00, enquanto que o “Deep Blue”, o vencedor, levou US$ 700.000,00 (mas infelizmente ele não teve onde gastar). Figura 2: Kasparov versus “Deep Blue”. A habilidade do “Deep Blue” em jogar xadrez vem da chamada “função de avaliação”. Esta função é um algoritmo que mede a qualidade de uma dada posição de xadrez. Posições com valores positivos são boas para as brancas, enquanto que aquelas com valores negativos são boas para as pretas. Se o cômputo total é positivo, as brancas estão em vantagem. A função de avaliação leva em conta 4 valores que são básicos para o xadrez: material, posição, segurança do Rei e tempo. O material é calculado segundo o valor das peças, o peão vale 1 e assim por diante até a Rainha que vale 9. O Rei, é claro, está além desses valores pois sua perda implica em derrota. A posição é calculada ao olhar suas peças e contar o número de posições seguras que eles podem atacar. A segurança do Rei é medida em função de sua capacidade defensiva. O tempo está relacionado com o desenvolvimento do jogo sobre o tabuleiro. Além disso tudo, o “Deep Blue” não usa força bruta ao avaliar as posições, mas sim seleciona alguns caminhos com bom potencial e elimina as buscas irrelevantes. Aproveitamos ainda para elucidar alguns pontos sobre este embate. O “Deep Blue” não usa inteligência artificial (IA) e tampouco aprende enquanto joga com seu oponente. Ao invés disso, ele trabalha como um sistema especialista que analisa seu vasto sistema de informações. Por exemplo, ele consulta sua base de dados com todas as aberturas dos últimos 100 anos e então calcula qual a melhor resposta ao movimento do oponente. Ele não pensa, mas sim, apenas reage e foi aí onde Kasparov tinha sua vantagem. Mas é claro que, com todos esses recursos, o “Deep Blue” é de certa forma “força bruta” contra a inteligência de Kasparov, que teve que jogar contra os fantasmas de todos os grandes mestres do passado. Além disso, a máquina nunca esquece ou se distrai. Para terminar este tópico, perguntamo-nos por que tanto dinheiro para jogar xadrez? O principal objetivo não está no jogo, mas sim na busca de uma arquitetura rápida o suficiente para apresentar resultados práticos. Para isso, o xadrez é um excelente desafio, pois, com suas 64 células, oferece um problema matemático extremamente complexo. Ao provar sua eficiência nessa área, a IBM demonstrou ser capaz de oferecer computadores para os problemas que ainda desafiam as atuais máquinas. E, no dia seguinte à vitória, suas ações subiram. O mais rápido computador da atualidade chama-se “Blue Pacific” e foi entregue em 28 de outubro de 1998. O termo ASCI vem de “Accelerate Strategic Computing Iniciative”, traduzido como “Iniciativa para Aceleração da Computação Estratégica”, que é o nome do programa do Departamento de Energia Norte-Americano para acelerar os avanços nas tecnologias necessárias para simular numericamente dispositivos nucleares, eliminando assim a necessidade do teste físico. Ele emprega 5.856 processadores que, operando cada um a cerca de 333 MHz, entregam uma potência de aproximadamente 4 Teraflops, ou, em outros termos, é 15.000 vezes mais rápido que um PC convencional, consumindo o equivalente a 324 secadores de cabelo. Uma pessoa com um calculadora de mão levaria 63 mil anos para realizar as operações que esse computador faz em 1 segundo. A tabela a seguir resume suas principais características. Processadores 5.856 Nós 1.464 Memória 2,6 Terabytes Armazenagem 75 Terabytes Desempenho 3,88 Teraflops Potência 486 kW Preço US$ 94 milhões Em 6 de dezembro de 1999, a IBM anunciou uma pesquisa de US$ 100 milhões com o objetivo de construir um computador que será 500 vezes mais poderoso que o mais rápido computador da atualidade. Esse novo computador, apelidado de “Blue Gene” será capaz de ultrapassar a marca de 1 quadrilhão de operações por segundo, ou seja, 1 Petaflops (10^15 flops). Essa marca o torna 1.000 vezes mais poderoso que o “Deep Blue” e cerca de 2 milhões de vezes mais rápido que um PC topo de linha. Essa maciça capacidade de processamento será usada inicialmente para modelar o “dobramento” das proteínas humanas. As proteínas controlam todos os processos celulares do corpo humano. Formadas por cadeias de aminoácidos, são unidas como anéis em uma corrente e dobram-se de formas altamente complexas. Sua forma tridimensional determina sua função. Qualquer mudança na forma altera dramaticamente a função da proteína. Mesmo uma pequena alteração no processo de dobragem pode transformar uma proteína desejável em uma doença. Assim, aprender mais sobre como as proteínas são dobradas deverá possibilitar aos pesquisadores médicos uma melhor compreensão das doenças e, em conseqüência, de suas curas. A comunidade científica considera o problema de dobragem das proteínas como um dos grandes desafios científicos da atualidade e sua solução somente pode ser alcançada com a tecnologia de computação de alto desempenho que, com certeza, terá grande impacto científico e econômico. A expectativa da IBM é atingir os Petaflops em 5 anos, um terço do que seria esperado segundo a Lei de Moore. A IBM denomina sua abordagem para este computador de SMASH, “Simple, Many and Self-Hearing”, que seria traduzido como “Simples, Muitos e Auto-Curativo”. Três tópicos distinguem essa arquitetura SMASH: Redução dramática do número de instruções, permitindo que os processadores sejam rápidos, de baixo consumo e ocupem pouca área do CI; Facilidade no processamento maciçamente paralelo, permitindo mais de 8 milhões de “threads”; Garantia de um computador auto-estável e auto-curativo, sobrepujando falhas de processadores e de “threads”. O “Blue Gene” consistirá de mais de 1 milhão de processadores, cada um capaz de oferecer 1 bilhão de operações por segundo, ou seja, 1 Gigaflops, como está mostrado na Figura 3. Trinta e dois desses processadores serão integrados em um único CI, resultando em 32 Gigaflops. Uma placa de 2 pés por 2 pés receberá 64 CIs, levando a 2 Teraflops. Somente essa placa já é capaz de igualar o desempenho do “Blue Pacific”, que tem 8.000 pés quadrados. Oito dessas placas (16 Teraflops) serão colocadas em “racks” de 6 pés. Finalmente 64 “racks” constituirão o estado final do computador, ocupando uma área menor que 2.000 pés quadrados. Figura 3: Arquitetura do “Blue Gene”, com seu 1 milhão de processadores. Agora teremos a sensação de que entramos no campo da ficção científica. Os computadores tradicionais trabalham com elementos básicos que podem assumir dois estados (ou dois bits): 0 ou 1. Normalmente, usam-se transistores ou “flip-flops” para representá-los. Olhando para o lado da física atômica, uma partícula quântica, como o elétron ou núcleos atômicos, pode existir em dois estados: com o “spin” para cima ou para baixo. Ora, isto constitui um bit quântico ou “qubit”. Quando o spin está para cima, o átomo pode ser lido como 1 e, quando o spin está para baixo, é lido como 0. Os qubits diferem dos bits tradicionais porque um núcleo atômico pode estar num estado de superposição, representando simultaneamente 0 e 1 e tudo o mais que existe entre esses valores. Mais ainda, sem a interferência do ambiente externo, os spins podem se “relacionar” de tal forma que efetivamente conectam os qubits de um computador quântico. Dois átomos “relacionados” atuam em conjunto: quando um está na posição para cima e o outro é garantido estar na posição para baixo. A combinação de superposição e “relacionamento” é o que permite a um computador quântico ter um enorme poder de processamento, possibilitando-o a realizar cálculos de forma maciçamente paralela e de forma não linear. Para certos tipos de cálculos, como por exemplo os complexos algoritmos para criptografia, um computador quântico pode realizar bilhões de cálculos em um único passo. Ao invés de resolver o problema pela adição ordenada de todos os números, um computador quântico poderia adicionar todos os números ao mesmo tempo. Assim, pela interação de um com o outro, quando isoladas do ambiente externo, os qubits podem realizar certos cálculos de forma exponencialmente mais rápida que os computadores convencionais. Diz-se que o computador quântico começa onde a Lei de Moore termina. Em 15 de agosto de 2000, um time da IBM demonstrou um novo computador quântico com 5 qubits, composto portanto por 5 átomos (de flúor) fixados em uma molécula especialmente projetada de forma a permitir que os qubits (spin dos núcleos) “relacionem” entre si. Esses qubits são programados por pulsos de rádio-freqüência e detectados por meio de ressonância nuclear magnética, semelhante ao usado em hospitais. Esse computador de 5 qubits foi capaz de resolver um problema de determinação de ordem de um sistema, ou seja, a determinação do período de uma função. Os computadores convencionais calculam a solução usando iterações passo-a-passo com os valores da função até que eles comecem a repetir. O computador quântico faz isso com um novo enfoque. Por natureza, eles representam simultaneamente todos os possíveis valores da variável de entrada e, portanto, com um único passo pode analisar todos os possíveis valores da função. Apesar do potencial dos computadores quânticos ser gigantesco e encorajador, os desafios ainda são enormes. O atual computador de 5 bits é um mero instrumento de pesquisa. Ainda faltam muitos anos de trabalho para que os computadores quânticos se tornem comerciais. Os prognósticos indicam que eles deverão ter pelo menos 12 bits para poderem resolver problemas do mundo real. Espera-se que, no futuro, tais computadores venham a trabalhar como processador auxiliar para problemas matemáticos de difícil solução. Com certeza processamento de texto e Internet não são aplicações talhadas para um computador quântico. A ideia do computador quântico não é recente, ela foi proposta na década de 1970. Observa-se claramente que os grandes computadores caminham para o processamento paralelo. Basicamente, o poder está vindo, não dos megahertz do processador, mas da quantidade de processadores que em conjunto resolvem um determinado problema. Isto significa que o tamanho do grão de processamento será cada vez menor e os processos cada vez mais acoplados. Vê-se também o uso intenso da arquitetura que Flynn (página anterior) classificada como MIMD. Como substituição para o atual modelo de processamento e esperança para os novos computadores, surge o processador quântico. No próximo número veremos alguns computadores Cray e estudaremos dois processadores simples, porém inovadores. Continue lendo: Processadores para o próximo milênio - parte 4 [1] “HAL’s Legacy”, David G. Stork (Editor). Sites Deep Blue: http://www.research.ibm.com/deepblue/meet/html/d.3.2.html Todas partidas Deep Blue vs Kasparov: http://www.ishipress.com/deepblue.pgn Blue Gene: http://www.research.ibm.com/news/detail/bluegene.html Blue Pacific: http://www.rs6000.ibm.com/hardware/largescale/SP/index.html Quântico: http://www.research.ibm.com/resources/news/20000815_quantum.html -
 Na primeira parte deste artigo abordamos alguns tópicos da história dos computadores. Continuando, vamos estudar os conceitos propostos por um dos nomes que apareceu neste histórico e, em seguida, abordaremos os principais tópicos sobre processamento paralelo. Postulados de von Neumann Von Neumann[1], que trabalhou no desenvolvimento do ENIAC e posteriormente empregou sua experiência no projeto do IAS (1952), elaborou as idéias e os conceitos que nortearam a arquitetura dos computadores até os dias de hoje. Seu entendimento é essencial para apreciarmos a atual evolução dos computadores. Iniciemos constatando, de forma óbvia, que as máquinas que usamos nas nossas casas possuem quatro elementos básicos: a CPU, a memória, os dados e as instruções (ou programas). A partir daí, apresentamos os três postulados básicos de von Neumann, que no momento podem parecer triviais, mas que não o eram na década de 50: 1. Um único controle centralizado (uma só CPU); 2. Uma única memória para dados e instruções; e 3. As instruções devem fazer operações elementares sobre os dados. Cerca de 90% dos computadores atuais usam esses postulados e por isso são chamados de “Arquitetura de von Neumann”, ou “Arquitetura Serial”, pois empregam um único processador. Essa arquitetura, aliada aos avanços da microeletrônica, ofertou-nos o atual mercado de computadores, rápidos e baratos. Porém, tal arquitetura enfrenta um limite de velocidade que é ditado pelas leis da física. O tempo que um sinal elétrico gasta para trafegar entre dois pontos de um circuito eletrônico é muito pequeno, porém não é igual a zero. Em outras palavras, isto corresponde a dizer que existe um limite para a velocidade de relógio das CPUs e, infelizmente, ele não está muito distante. Como então continuar com a evolução dos computadores? Essa é a pergunta que tem ocupado a cabeça de muitos pesquisadores e desde a segunda metade desta década, várias soluções foram propostas. A principal resposta vem da comparação entre nosso cérebro e um processador. É sabido que o sinal elétrico trafegando por dentro de um CI é muito mais veloz que o trânsito de impulsos nervosos entre nossos neurônios. É claro que, para fazer operações numéricas, comparar e classificar, o computador é mais rápido. Mas, por outro lado, ele é inferior, pois não pensa, não inova e não aprende, apenas segue passos programados. Por exemplo, com um único olhar em uma sala identificamos imediatamente centenas de objetos. Já um computador, mesmo o mais sofisticado, apenas consegue identificar os objetos mais simples. Somos capazes de dirigir um carro e enquanto andamos por nossas (terríveis) estradas, temos habilidade para escolher o melhor caminho. Será que um computador pode dirigir um carro? Uma das experiências no MIT com um piloto computadorizado, que identificava a rua através das linhas paralelas do meio fio, revelou um grande escalador de árvores, pois ele confundia o contorno do meio fio com o contorno do caule das árvores. Como será que o cérebro consegue ser superior aos processadores, se o nosso neurônio é muito mais lento que um circuito eletrônico? A resposta é óbvia: porque temos vários bilhões de neurônios operando em paralelo. Ora, por que, ao invés de construirmos CPUs velozes e gigantescas, não usamos várias CPUs, simples e confiáveis, operando em paralelo? Chegamos assim à ideia básica do processamento paralelo, que é a esperança para o próximo milênio Sabemos então que devemos usar uma grande quantidade de processadores, mas como controlá-los de forma a que façam alguma coisa de útil? Existem grandes problemas! Para iniciar, vamos trabalhar o conceito de processamento paralelo através de um exemplo bem simples. Se um pedreiro constrói uma casa em um ano, então dois pedreiros constróem a mesma casa em meio ano. Este é conceito básico do processamento paralelo: a divisão das tarefas. Podemos seguir adiante e concluir que cem pedreiros gastam apenas 3,6 dias. Será isto um absurdo? É claro que há um limite, pois o trabalho dos pedreiros só será eficiente se estiverem perfeitamente sincronizados e equilibrados. Este ponto é importante: todos os pedreiros devem ter a mesma carga de trabalho. Em termos técnicos, usa-se a expressão “Balanceamento da Carga de Trabalho”. Esse balanceamento pode ser feito de dois modos. No primeiro modo, o trabalho de cada pedreiro é idêntico, ou seja, cada um faz 1/100 da casa. No outro modo é usado a especialização, ou seja, alguns pedreiros “viram” cimento enquanto outros assentam tijolos e outros tratam do encanamento, e assim por diante. Ao imaginarmos todas as tarefas que devam ser executadas para a construção da casa, fica claro que algumas delas não poderão ser paralelizadas. Imagine 100 pedreiros para assentar um porta, ou 100 pedreiros em cima da casa tentando montar o telhado. A casa acabaria por cair! Além disso, deve haver um limite para a quantidade de pedreiros que podem trabalhar em paralelo. A partir deste limite, quanto mais pedreiros colocamos, pioramos o desempenho e em conseqüência, aumentamos o tempo de construção. Temos então dois grandes problemas: até quanto podemos paralelizar uma tarefa e até quantos processadores devem ser alocados? A partir daí, surgem outras questões: como sincronizar esses processadores de forma a que um não repita o trabalho do outro e como garantir o balanceamento da carga de trabalho? Agora temos condições de entender porque se diz que as dificuldades presentes no projeto do hardware de máquinas paralelas não são tão complexas quando comparados com os problemas de sua programação. Diz-se que os computadores estão sempre uma geração atrasada em relação às nossas necessidades e os programas, duas gerações atrasadas. Em suma, um desafio maior que o projeto de supercomputadores é a sua programação. É muito difícil a tarefa de classificar computadores paralelos. Já foram feitas diversas sugestões. A classificação definitiva ainda está por vir. Porém, a que trouxe melhores resultados e ainda hoje é usada, é a proposta por Flynn[2]. Essa classificação está baseada em dois conceitos: fluxo de instruções e fluxo de dados. O fluxo de instruções está relacionado com o programa que o processador executa, enquanto que o fluxo de dados está relacionado com os operandos manipulados por essas instruções. O fluxo de instruções e o fluxo de dados são considerados independentes e por isso existem quatro combinações possíveis, como mostrado na Figura 1. Figura 1: Fluxo de instruções e dados. Nas Figuras 2 a 5 apresentamos os diagramas de blocos para essas 4 combinações. Nessas figuras, a sigla MM representa o “Módulo de Memória” e a sigla EP representa o “Elemento de Processamento”, ou seja, o processador. Essas quatro arquiteturas serão detalhadas a seguir. Figura 2: Arquitetura SISD (Single Instruction Single Data). Figura 3: Aquitetura SIMD (Single Instruction Multiple Data). Figura 4: Arquitetura MISD (Multiple Instruction Single Data). Figura 5: Arquitetura MIMD (Multiple Instruction Multiple Data). SISD - Instrução Única, Dado Único (Single Instruction Single Data) Essa arquitetura é usada nos computadores que temos em casa. Segue o proposto por von Neumann e é por isso denominada de “Arquitetura de von Neumann”, também chamado de computador serial. Temos um único fluxo de instruções (SI), caracterizado pelo contador de programa da CPU, que opera sobre um único dado (SD) por vez. A Figura 2 apresenta um diagrama de blocos ilustrativo deste caso. Apesar de serem representados como módulos separados, a memória de instruções e a memória de dados são, para este caso, a mesma. SIMD - Única Instrução, Múltiplos Dados (Single Instruction Multiple Data) De início esta arquitetura paralela pode parecer estranha, mas como será constatado adiante, ela não só é conhecida, como também já foi muito utilizada. Para facilitar o conceito de um computador que utilize uma única instrução operando sobre uma grande quantidade de dados, devemos consultar o diagrama da Figura 3. A arquitetura mostrada apresenta N processadores (EP), sendo que cada processador trabalha sobre um dado distinto, que vem de cada um dos N módulos de memória (MD). O ponto importante é que todos os processadores (EPi) trabalham sincronizados e executam todos a mesma instrução, ou seja, cada instrução é passada, ao mesmo tempo, para os N EPs. Assim, os processadores executam a mesma instrução, porém sobre um dado diferente. Como é fácil de concluir, um computador com essa arquitetura é capaz de operar um vetor de dados por vez. Vem daí seu nome de Computador Vetorial, ou “Array Processor”. Um grande exemplo desta arquitetura são os famosos computadores Cray. Outro exemplo é o conjunto de instruções MMX. Eles são muito usados quando um mesmo programa deve ser executado sobre uma grande massa de dados, como é o caso de prospeção de petróleo. Note que essa arquitetura não sofre com problemas de sincronização, pois existe um único programa em execução. MISD - Múltiplas Instruções, Dado Único (Multiple Instruction Single Data) Essa arquitetura é um pouco mais difícil de ser explicada. Tentemos imaginar como é que se pode fazer múltiplas operações (MI) sobre um mesmo dado (SD). Os próprios pesquisadores têm opiniões divergentes sobre esse assunto. Entretanto, não vamos entrar nesses debates teóricos. De forma simples, vamos estudar a Figura 4, onde pode ser visto que, apesar de existir um único fluxo de dados, existem vários dados sendo operados ao mesmo tempo. Essa figura é conhecida na literatura especializada com o nome de “pipeline” ou linha de produção. A figura mostra que N processadores operam sobre K diferentes dados. Façamos uma analogia com uma linha de montagem de carros. Vamos supor que um carro leve 6 horas para ser montado e que a tarefa de montagem possa ser dividida em 12 equipes, numeradas em seqüência de 1 até 12, cada uma gastando meia hora. É fácil de ver que não precisamos esperar que a última equipe termine de montar um carro para a equipe 1 inicie a montagem do carro seguinte. Na verdade, todas elas trabalham simultaneamente, montando vários carros ao mesmo tempo. Por isso, com alguma liberdade, é costume classificá-la de paralelismo temporal. Então, apesar do tempo de montagem consumir 6 horas, a saída da linha de produção entrega um carro a cada meia hora. Agora é fácil voltar aos computadores e ver que temos um único fluxo de dados (SD), porém vários instruções (MI) processam esses dados, ao mesmo tempo. MIMD - Múltiplas Instruções, Múltiplos Dados (Multiple Instruction Multiple Data) Essa é a arquitetura que esperaríamos encontrar em um computador paralelo. Temos vários dados (MD) sendo operados por vários instruções (MI), simultaneamente. Essa é a arquitetura mais usada pelos modernos supercomputadores. Nesse caso, é importante que os processadores possam se comunicar entre si para fazer a sincronização e trocar informações. Além disso, é necessário ter uma memória, chamada de global, onde todos processadores possam disponibilizar, para os demais, os resultados intermediários. A Figura 5 apresenta uma solução genérica para essa arquitetura MIMD. Note que agora temos N processadores e dois tipos de memória: a local e a global. A memória global pode ser acessada por qualquer um dos processadores, por isso existe a chamada “Estrutura de Comunicação”, que disponibiliza a memória global para qualquer um dos processadores. Uma única memória global criaria um grande gargalo, pois só um processador poderia acessá-la por vez. Por isso, a figura apresenta duas memórias globais e, com isso, dois processadores podem ser atendidos ao mesmo tempo. Para evitar uma quantidade excessiva de acessos a essa memória, os processadores possuem a chamada memória local, onde está a maioria das suas instruções e dos dados que devam ser operados. Essa memória local evita que a estrutura de comunicação se transforme num enorme gargalo. Os processadores precisam trocar informações e, no caso desta figura, a própria estrutura de comunicação se encarrega desta tarefa. Uma simples análise da arquitetura MIMD da Figura 5 mostra que agora existe um fluxo de múltiplos dados (MD) sendo operado por um fluxo de múltiplas instruções (MI). Agora sim é necessária a genialidade dos programadores, pois como conseguir que uma estrutura deste tipo, imagine 1.024 processadores, trabalhe de forma sincronizada para gerar algum resultado? Se já é difícil escrever e depurar programas seriais, imagine fazer isso em um computador com 1.024 diferentes programas trabalhando sobre 1.024 dados diferentes. Como medir o quanto se ganhou com a execução de uma tarefa em um computador paralelo? É intuitivo que devemos usar o tempo de execução para medir esse desempenho, já que nosso principal objetivo é aumentar a velocidade de processamento. Uma solução boa é verificarmos a relação entre os tempos gastos para executar essa tarefa em um computador serial e em um computador paralelo. A expressão a seguir é usada para o cálculo do Ganho de Velocidade, que é abreviado pela sigla GV. Por exemplo, uma determinada tarefa, quando executada em um computador convencional consome 200 s e quando executada em uma máquina paralela (24 processadores) consome 10 s, então o ganho de velocidade é GV = 200/10 = 20. Gostaríamos que o Ganho de Velocidade fosse igual à quantidade de Elementos de Processamento (EP) empregados, mas isso é raro de acontecer pois quando se escreve um programa para rodar em máquinas paralelas, invariavelmente se necessita colocar trechos extras (de programa) para sincronização dos diversos EP e troca de informações. Esses trechos extras recebem o nome de custo de paralelização. Dependendo da tarefa a ser executada, pode haver uma necessidade de sincronização e troca informações tão grande que venha a inviabilizar o processamento paralelo. O ideal é que um aumento no número de processadores traga um igual aumento de desempenho (GV). A Figura 6 apresenta 4 casos, onde se calcula o Ganho de Processamento em função do número de processadores. A curva em vermelho mostra o caso ideal, onde há um ganho linear em função do número de processadores. A curva em verde traz um caso mais real onde o ganho não acompanha a quantidade de processadores, ou seja, ao dobramos a quantidade de processadores, não dobramos o ganho de velocidade. A curva em azul traz um caso de saturação em 85 processadores, ou seja, é inútil utilizar mais do que 85 processadores. A curva em negro apresenta um caso ainda pior, pois nota-se que há um limite em 25 processadores, qualquer processador que se adicione além desse valor, só atrasará o processamento. Figura 6: Influência do custo de paralelização. Assim, um tópico interessante é determinar qual a quantidade ótima de processadores para uma determinada tarefa. É claro que esse valor é fortemente influenciado pelo algoritmo e pela técnica de programação empregada. A arquitetura paralela também influencia muito. Por exemplo, algumas arquiteturas têm gargalos para a comunicação entre os processadores e outras penalizam muito os acessos à memória global. É claro que nem toda tarefa é indicada para ser executada em máquinas paralelas, como veremos no próximo tópico. Apesar do quanto promissor a computação paralela possa parecer, ela não é uma solução para todo o problema de processamento. Existem tarefas que são eminentemente seqüenciais e que não tiram proveito de um computador paralelo. Voltando ao nosso exemplo da construção de uma casa, apesar dela ser executada em paralelo, existe por detrás uma seqüência que deve ser obedecida. Nessa construção, não podemos fazer o telhado antes de termos as paredes prontas e também não podemos construir as paredes antes do alicerce. Assim, é comum que as tarefas a serem executadas possuam porções paralelizáveis e porções que precisam ser executadas de forma seqüencial. Note que um computador paralelo operando de forma seqüencial é um grande desperdício, pois enquanto um processador trabalha no trecho serial, todos os demais ficam ociosos. Abordando esse tema, Amdahl propôs uma expressão para esse problema, que ficou conhecida como Lei de Amdahl[3] e que está representada a seguir. A explicação é muito simples. Imaginemos uma tarefa que executada em uma máquina seqüencial gaste "T" segundos. Porém, quando preparada para execução em uma máquina paralela, ela tem uma porção que obrigatoriamente deve ser executada de forma serial. Digamos que "p" represente a porção serial, em conseqüência "(1-p)" representa a porção paralelizável. Quando executado em uma máquina paralela com N processadores, o tempo gasto será igual a "". Somente o trecho paralelizável tira partido dos "N" processadores. Assim o Ganho de Processamento é dado por: ou que é a forma consagrada da Lei de Amdahl. Deve-se notar que estamos ignorando os custos de sincronização e de troca de parâmetros entre os processadores. Vejamos em um gráfico o desempenho de alguns programas, segundo essa lei. A Figura 7 apresenta 4 casos. A curva em vermelho é a de uma tarefa 100% paralelizável, ou seja, p = 0. Nesse caso o aumento do número de processadores reflete linearmente no desempenho. A curva em verde ilustra o caso de p = 0,001 ou 0,1%, ou seja, apenas 0,1 % das tarefas não puderam ser paralelizadas. A curva em azul é para o caso onde 1% (p = 0,01) da tarefa precisa ser executada de forma serial. Nota-se uma grande queda de desempenho para grande quantidade de processadores. A última curva representa o caso de uma tarefa onde 10% (p = 0,1) precisam ser executadas de forma serial. Nota-se que há uma saturação, e que o aumento de processadores, por exemplo, de 50 para 100 processadores, pouca diferença traz para o desempenho. Devem ser ressaltados dois pontos importantes. O primeiro é que, exceto para o caso de p = 0, todos os demais casos irão apresentar saturação em algum ponto. Se p é pequeno, a saturação só ocorre com um elevado número de processadores. O segundo ponto é que, contrastando com a Figura 7, a Lei de Amdahl não prevê queda no desempenho, no pior caso, ele fica fixo em algum valor. Figura 7: Exemplos da Lei da Amdahl. Assim terminamos o este rápido estudo de processamento paralelo. Esperamos ter elucidado diversos conceitos básicos. Nas próximas partes dessa série de artigos ilustraremos nosso estudo abordando diversas arquiteturas paralelas propostas pelos gigantes de mercado para o próximo milênio. Continue lendo: Processadores para o próximo milênio - parte 3 [1] IEEE "Annals of the History of Computing" magazine, Volume 15, Number 4, 1993, page 28. [2] “Some Computer Organizations and their Effectiveness”, M. J. Flynn, IEEE Transactions on Computers, vol C-21, pp. 948-960, Setembro, 1972. [3] “Validity of the Single Processor Approach to Achieving Large Scale Computing Capabilities”, G. Amdahl, AFIPS Conference Proceeding, vol. 30, Abril, 1967, Thompson Books, Washington DC. [4] “Structured Computer Organization”, Andrew S. Tanenbaum, 4a Edição.
Na primeira parte deste artigo abordamos alguns tópicos da história dos computadores. Continuando, vamos estudar os conceitos propostos por um dos nomes que apareceu neste histórico e, em seguida, abordaremos os principais tópicos sobre processamento paralelo. Postulados de von Neumann Von Neumann[1], que trabalhou no desenvolvimento do ENIAC e posteriormente empregou sua experiência no projeto do IAS (1952), elaborou as idéias e os conceitos que nortearam a arquitetura dos computadores até os dias de hoje. Seu entendimento é essencial para apreciarmos a atual evolução dos computadores. Iniciemos constatando, de forma óbvia, que as máquinas que usamos nas nossas casas possuem quatro elementos básicos: a CPU, a memória, os dados e as instruções (ou programas). A partir daí, apresentamos os três postulados básicos de von Neumann, que no momento podem parecer triviais, mas que não o eram na década de 50: 1. Um único controle centralizado (uma só CPU); 2. Uma única memória para dados e instruções; e 3. As instruções devem fazer operações elementares sobre os dados. Cerca de 90% dos computadores atuais usam esses postulados e por isso são chamados de “Arquitetura de von Neumann”, ou “Arquitetura Serial”, pois empregam um único processador. Essa arquitetura, aliada aos avanços da microeletrônica, ofertou-nos o atual mercado de computadores, rápidos e baratos. Porém, tal arquitetura enfrenta um limite de velocidade que é ditado pelas leis da física. O tempo que um sinal elétrico gasta para trafegar entre dois pontos de um circuito eletrônico é muito pequeno, porém não é igual a zero. Em outras palavras, isto corresponde a dizer que existe um limite para a velocidade de relógio das CPUs e, infelizmente, ele não está muito distante. Como então continuar com a evolução dos computadores? Essa é a pergunta que tem ocupado a cabeça de muitos pesquisadores e desde a segunda metade desta década, várias soluções foram propostas. A principal resposta vem da comparação entre nosso cérebro e um processador. É sabido que o sinal elétrico trafegando por dentro de um CI é muito mais veloz que o trânsito de impulsos nervosos entre nossos neurônios. É claro que, para fazer operações numéricas, comparar e classificar, o computador é mais rápido. Mas, por outro lado, ele é inferior, pois não pensa, não inova e não aprende, apenas segue passos programados. Por exemplo, com um único olhar em uma sala identificamos imediatamente centenas de objetos. Já um computador, mesmo o mais sofisticado, apenas consegue identificar os objetos mais simples. Somos capazes de dirigir um carro e enquanto andamos por nossas (terríveis) estradas, temos habilidade para escolher o melhor caminho. Será que um computador pode dirigir um carro? Uma das experiências no MIT com um piloto computadorizado, que identificava a rua através das linhas paralelas do meio fio, revelou um grande escalador de árvores, pois ele confundia o contorno do meio fio com o contorno do caule das árvores. Como será que o cérebro consegue ser superior aos processadores, se o nosso neurônio é muito mais lento que um circuito eletrônico? A resposta é óbvia: porque temos vários bilhões de neurônios operando em paralelo. Ora, por que, ao invés de construirmos CPUs velozes e gigantescas, não usamos várias CPUs, simples e confiáveis, operando em paralelo? Chegamos assim à ideia básica do processamento paralelo, que é a esperança para o próximo milênio Sabemos então que devemos usar uma grande quantidade de processadores, mas como controlá-los de forma a que façam alguma coisa de útil? Existem grandes problemas! Para iniciar, vamos trabalhar o conceito de processamento paralelo através de um exemplo bem simples. Se um pedreiro constrói uma casa em um ano, então dois pedreiros constróem a mesma casa em meio ano. Este é conceito básico do processamento paralelo: a divisão das tarefas. Podemos seguir adiante e concluir que cem pedreiros gastam apenas 3,6 dias. Será isto um absurdo? É claro que há um limite, pois o trabalho dos pedreiros só será eficiente se estiverem perfeitamente sincronizados e equilibrados. Este ponto é importante: todos os pedreiros devem ter a mesma carga de trabalho. Em termos técnicos, usa-se a expressão “Balanceamento da Carga de Trabalho”. Esse balanceamento pode ser feito de dois modos. No primeiro modo, o trabalho de cada pedreiro é idêntico, ou seja, cada um faz 1/100 da casa. No outro modo é usado a especialização, ou seja, alguns pedreiros “viram” cimento enquanto outros assentam tijolos e outros tratam do encanamento, e assim por diante. Ao imaginarmos todas as tarefas que devam ser executadas para a construção da casa, fica claro que algumas delas não poderão ser paralelizadas. Imagine 100 pedreiros para assentar um porta, ou 100 pedreiros em cima da casa tentando montar o telhado. A casa acabaria por cair! Além disso, deve haver um limite para a quantidade de pedreiros que podem trabalhar em paralelo. A partir deste limite, quanto mais pedreiros colocamos, pioramos o desempenho e em conseqüência, aumentamos o tempo de construção. Temos então dois grandes problemas: até quanto podemos paralelizar uma tarefa e até quantos processadores devem ser alocados? A partir daí, surgem outras questões: como sincronizar esses processadores de forma a que um não repita o trabalho do outro e como garantir o balanceamento da carga de trabalho? Agora temos condições de entender porque se diz que as dificuldades presentes no projeto do hardware de máquinas paralelas não são tão complexas quando comparados com os problemas de sua programação. Diz-se que os computadores estão sempre uma geração atrasada em relação às nossas necessidades e os programas, duas gerações atrasadas. Em suma, um desafio maior que o projeto de supercomputadores é a sua programação. É muito difícil a tarefa de classificar computadores paralelos. Já foram feitas diversas sugestões. A classificação definitiva ainda está por vir. Porém, a que trouxe melhores resultados e ainda hoje é usada, é a proposta por Flynn[2]. Essa classificação está baseada em dois conceitos: fluxo de instruções e fluxo de dados. O fluxo de instruções está relacionado com o programa que o processador executa, enquanto que o fluxo de dados está relacionado com os operandos manipulados por essas instruções. O fluxo de instruções e o fluxo de dados são considerados independentes e por isso existem quatro combinações possíveis, como mostrado na Figura 1. Figura 1: Fluxo de instruções e dados. Nas Figuras 2 a 5 apresentamos os diagramas de blocos para essas 4 combinações. Nessas figuras, a sigla MM representa o “Módulo de Memória” e a sigla EP representa o “Elemento de Processamento”, ou seja, o processador. Essas quatro arquiteturas serão detalhadas a seguir. Figura 2: Arquitetura SISD (Single Instruction Single Data). Figura 3: Aquitetura SIMD (Single Instruction Multiple Data). Figura 4: Arquitetura MISD (Multiple Instruction Single Data). Figura 5: Arquitetura MIMD (Multiple Instruction Multiple Data). SISD - Instrução Única, Dado Único (Single Instruction Single Data) Essa arquitetura é usada nos computadores que temos em casa. Segue o proposto por von Neumann e é por isso denominada de “Arquitetura de von Neumann”, também chamado de computador serial. Temos um único fluxo de instruções (SI), caracterizado pelo contador de programa da CPU, que opera sobre um único dado (SD) por vez. A Figura 2 apresenta um diagrama de blocos ilustrativo deste caso. Apesar de serem representados como módulos separados, a memória de instruções e a memória de dados são, para este caso, a mesma. SIMD - Única Instrução, Múltiplos Dados (Single Instruction Multiple Data) De início esta arquitetura paralela pode parecer estranha, mas como será constatado adiante, ela não só é conhecida, como também já foi muito utilizada. Para facilitar o conceito de um computador que utilize uma única instrução operando sobre uma grande quantidade de dados, devemos consultar o diagrama da Figura 3. A arquitetura mostrada apresenta N processadores (EP), sendo que cada processador trabalha sobre um dado distinto, que vem de cada um dos N módulos de memória (MD). O ponto importante é que todos os processadores (EPi) trabalham sincronizados e executam todos a mesma instrução, ou seja, cada instrução é passada, ao mesmo tempo, para os N EPs. Assim, os processadores executam a mesma instrução, porém sobre um dado diferente. Como é fácil de concluir, um computador com essa arquitetura é capaz de operar um vetor de dados por vez. Vem daí seu nome de Computador Vetorial, ou “Array Processor”. Um grande exemplo desta arquitetura são os famosos computadores Cray. Outro exemplo é o conjunto de instruções MMX. Eles são muito usados quando um mesmo programa deve ser executado sobre uma grande massa de dados, como é o caso de prospeção de petróleo. Note que essa arquitetura não sofre com problemas de sincronização, pois existe um único programa em execução. MISD - Múltiplas Instruções, Dado Único (Multiple Instruction Single Data) Essa arquitetura é um pouco mais difícil de ser explicada. Tentemos imaginar como é que se pode fazer múltiplas operações (MI) sobre um mesmo dado (SD). Os próprios pesquisadores têm opiniões divergentes sobre esse assunto. Entretanto, não vamos entrar nesses debates teóricos. De forma simples, vamos estudar a Figura 4, onde pode ser visto que, apesar de existir um único fluxo de dados, existem vários dados sendo operados ao mesmo tempo. Essa figura é conhecida na literatura especializada com o nome de “pipeline” ou linha de produção. A figura mostra que N processadores operam sobre K diferentes dados. Façamos uma analogia com uma linha de montagem de carros. Vamos supor que um carro leve 6 horas para ser montado e que a tarefa de montagem possa ser dividida em 12 equipes, numeradas em seqüência de 1 até 12, cada uma gastando meia hora. É fácil de ver que não precisamos esperar que a última equipe termine de montar um carro para a equipe 1 inicie a montagem do carro seguinte. Na verdade, todas elas trabalham simultaneamente, montando vários carros ao mesmo tempo. Por isso, com alguma liberdade, é costume classificá-la de paralelismo temporal. Então, apesar do tempo de montagem consumir 6 horas, a saída da linha de produção entrega um carro a cada meia hora. Agora é fácil voltar aos computadores e ver que temos um único fluxo de dados (SD), porém vários instruções (MI) processam esses dados, ao mesmo tempo. MIMD - Múltiplas Instruções, Múltiplos Dados (Multiple Instruction Multiple Data) Essa é a arquitetura que esperaríamos encontrar em um computador paralelo. Temos vários dados (MD) sendo operados por vários instruções (MI), simultaneamente. Essa é a arquitetura mais usada pelos modernos supercomputadores. Nesse caso, é importante que os processadores possam se comunicar entre si para fazer a sincronização e trocar informações. Além disso, é necessário ter uma memória, chamada de global, onde todos processadores possam disponibilizar, para os demais, os resultados intermediários. A Figura 5 apresenta uma solução genérica para essa arquitetura MIMD. Note que agora temos N processadores e dois tipos de memória: a local e a global. A memória global pode ser acessada por qualquer um dos processadores, por isso existe a chamada “Estrutura de Comunicação”, que disponibiliza a memória global para qualquer um dos processadores. Uma única memória global criaria um grande gargalo, pois só um processador poderia acessá-la por vez. Por isso, a figura apresenta duas memórias globais e, com isso, dois processadores podem ser atendidos ao mesmo tempo. Para evitar uma quantidade excessiva de acessos a essa memória, os processadores possuem a chamada memória local, onde está a maioria das suas instruções e dos dados que devam ser operados. Essa memória local evita que a estrutura de comunicação se transforme num enorme gargalo. Os processadores precisam trocar informações e, no caso desta figura, a própria estrutura de comunicação se encarrega desta tarefa. Uma simples análise da arquitetura MIMD da Figura 5 mostra que agora existe um fluxo de múltiplos dados (MD) sendo operado por um fluxo de múltiplas instruções (MI). Agora sim é necessária a genialidade dos programadores, pois como conseguir que uma estrutura deste tipo, imagine 1.024 processadores, trabalhe de forma sincronizada para gerar algum resultado? Se já é difícil escrever e depurar programas seriais, imagine fazer isso em um computador com 1.024 diferentes programas trabalhando sobre 1.024 dados diferentes. Como medir o quanto se ganhou com a execução de uma tarefa em um computador paralelo? É intuitivo que devemos usar o tempo de execução para medir esse desempenho, já que nosso principal objetivo é aumentar a velocidade de processamento. Uma solução boa é verificarmos a relação entre os tempos gastos para executar essa tarefa em um computador serial e em um computador paralelo. A expressão a seguir é usada para o cálculo do Ganho de Velocidade, que é abreviado pela sigla GV. Por exemplo, uma determinada tarefa, quando executada em um computador convencional consome 200 s e quando executada em uma máquina paralela (24 processadores) consome 10 s, então o ganho de velocidade é GV = 200/10 = 20. Gostaríamos que o Ganho de Velocidade fosse igual à quantidade de Elementos de Processamento (EP) empregados, mas isso é raro de acontecer pois quando se escreve um programa para rodar em máquinas paralelas, invariavelmente se necessita colocar trechos extras (de programa) para sincronização dos diversos EP e troca de informações. Esses trechos extras recebem o nome de custo de paralelização. Dependendo da tarefa a ser executada, pode haver uma necessidade de sincronização e troca informações tão grande que venha a inviabilizar o processamento paralelo. O ideal é que um aumento no número de processadores traga um igual aumento de desempenho (GV). A Figura 6 apresenta 4 casos, onde se calcula o Ganho de Processamento em função do número de processadores. A curva em vermelho mostra o caso ideal, onde há um ganho linear em função do número de processadores. A curva em verde traz um caso mais real onde o ganho não acompanha a quantidade de processadores, ou seja, ao dobramos a quantidade de processadores, não dobramos o ganho de velocidade. A curva em azul traz um caso de saturação em 85 processadores, ou seja, é inútil utilizar mais do que 85 processadores. A curva em negro apresenta um caso ainda pior, pois nota-se que há um limite em 25 processadores, qualquer processador que se adicione além desse valor, só atrasará o processamento. Figura 6: Influência do custo de paralelização. Assim, um tópico interessante é determinar qual a quantidade ótima de processadores para uma determinada tarefa. É claro que esse valor é fortemente influenciado pelo algoritmo e pela técnica de programação empregada. A arquitetura paralela também influencia muito. Por exemplo, algumas arquiteturas têm gargalos para a comunicação entre os processadores e outras penalizam muito os acessos à memória global. É claro que nem toda tarefa é indicada para ser executada em máquinas paralelas, como veremos no próximo tópico. Apesar do quanto promissor a computação paralela possa parecer, ela não é uma solução para todo o problema de processamento. Existem tarefas que são eminentemente seqüenciais e que não tiram proveito de um computador paralelo. Voltando ao nosso exemplo da construção de uma casa, apesar dela ser executada em paralelo, existe por detrás uma seqüência que deve ser obedecida. Nessa construção, não podemos fazer o telhado antes de termos as paredes prontas e também não podemos construir as paredes antes do alicerce. Assim, é comum que as tarefas a serem executadas possuam porções paralelizáveis e porções que precisam ser executadas de forma seqüencial. Note que um computador paralelo operando de forma seqüencial é um grande desperdício, pois enquanto um processador trabalha no trecho serial, todos os demais ficam ociosos. Abordando esse tema, Amdahl propôs uma expressão para esse problema, que ficou conhecida como Lei de Amdahl[3] e que está representada a seguir. A explicação é muito simples. Imaginemos uma tarefa que executada em uma máquina seqüencial gaste "T" segundos. Porém, quando preparada para execução em uma máquina paralela, ela tem uma porção que obrigatoriamente deve ser executada de forma serial. Digamos que "p" represente a porção serial, em conseqüência "(1-p)" representa a porção paralelizável. Quando executado em uma máquina paralela com N processadores, o tempo gasto será igual a "". Somente o trecho paralelizável tira partido dos "N" processadores. Assim o Ganho de Processamento é dado por: ou que é a forma consagrada da Lei de Amdahl. Deve-se notar que estamos ignorando os custos de sincronização e de troca de parâmetros entre os processadores. Vejamos em um gráfico o desempenho de alguns programas, segundo essa lei. A Figura 7 apresenta 4 casos. A curva em vermelho é a de uma tarefa 100% paralelizável, ou seja, p = 0. Nesse caso o aumento do número de processadores reflete linearmente no desempenho. A curva em verde ilustra o caso de p = 0,001 ou 0,1%, ou seja, apenas 0,1 % das tarefas não puderam ser paralelizadas. A curva em azul é para o caso onde 1% (p = 0,01) da tarefa precisa ser executada de forma serial. Nota-se uma grande queda de desempenho para grande quantidade de processadores. A última curva representa o caso de uma tarefa onde 10% (p = 0,1) precisam ser executadas de forma serial. Nota-se que há uma saturação, e que o aumento de processadores, por exemplo, de 50 para 100 processadores, pouca diferença traz para o desempenho. Devem ser ressaltados dois pontos importantes. O primeiro é que, exceto para o caso de p = 0, todos os demais casos irão apresentar saturação em algum ponto. Se p é pequeno, a saturação só ocorre com um elevado número de processadores. O segundo ponto é que, contrastando com a Figura 7, a Lei de Amdahl não prevê queda no desempenho, no pior caso, ele fica fixo em algum valor. Figura 7: Exemplos da Lei da Amdahl. Assim terminamos o este rápido estudo de processamento paralelo. Esperamos ter elucidado diversos conceitos básicos. Nas próximas partes dessa série de artigos ilustraremos nosso estudo abordando diversas arquiteturas paralelas propostas pelos gigantes de mercado para o próximo milênio. Continue lendo: Processadores para o próximo milênio - parte 3 [1] IEEE "Annals of the History of Computing" magazine, Volume 15, Number 4, 1993, page 28. [2] “Some Computer Organizations and their Effectiveness”, M. J. Flynn, IEEE Transactions on Computers, vol C-21, pp. 948-960, Setembro, 1972. [3] “Validity of the Single Processor Approach to Achieving Large Scale Computing Capabilities”, G. Amdahl, AFIPS Conference Proceeding, vol. 30, Abril, 1967, Thompson Books, Washington DC. [4] “Structured Computer Organization”, Andrew S. Tanenbaum, 4a Edição. -
 Finalmente, após o grande alarde do “Bug Y2K”, vamos ultrapassar a barreira do segundo milênio. Mas será que somos muito diferentes do homem de 2000 anos atrás? Não muito, o homem moderno, apesar de toda onda de informação, ainda lembra bastante seu antepassado, especialmente na adoração por datas, acontecimentos e cerimônias. Ao olharmos para trás, vimos que 2.000 anos formaram uma era. Quantas coisas nos separam daquele homem que não sabia medir o tempo, que acreditava que as estrelas eram candelabros de luzes e que a Terra era plana. O homem atual quebra os núcleos e transmuta os elementos, cria anti-matéria, manipula átomos, constrói máquinas inteligentes, envia naves além do Sistema Solar. Esta mesma sensação dual de mudança e não-mudança envolve-nos quando olhamos para trás em busca do nascimento da computação e, para a frente, querendo saber o que nos promete o próximo milênio. O presente artigo é o primeiro de uma série que irá explorar as realizações atuais e as especulações para o início do próximo milênio. Tentaremos apresentar um panorama diversificado, abordando não só as arquiteturas clássicas, mas também as evoluções que estão surgindo. Para tanto, não nos basta a experiência que temos com a família 80x86 para entendermos as novas arquiteturas, vamos precisar de alguns conceitos que serão abordados ao longo dos próximos artigos. Assim, vamos iniciar este artigo olhando para trás para apreciarmos o que aconteceu no passado e, em seguida, observaremos o mundo ao nosso redor e analisaremos o momento atual, para então abordamos as arquiteturas que serão as inovações para o próximo milênio. Finalmente, estudaremos em especial as arquiteturas de 64 bits da Intel (IA-64) e da AMD (x86-64). Qual foi o primeiro computador ? A resposta mais freqüente é o ábaco chinês, embora contestável por ele tratar-se de um instrumento auxiliar de cálculo. Acreditamos que o rótulo “computador no 1" deva ir para a calculadora mecânica de Blaise Pascal (homenageado com a linguagem Pascal), desenvolvida em 1642, que podia operar com números até 999.999.999. Em 1822, Charles Babbage desenvolveu a Máquina Diferencial (“Difference Engine”), que tinha uma arquitetura muito semelhante aos modernos processadores, apresentando CPU, memória e até linguagem de programação. A filha de Lord Byron, uma garota chamada Ada Byron[1], teve contato com esta máquina e acabou por se tornar a primeira programadora (em sua homenagem, temos hoje a linguagem ADA). Em 1833, Babbage projetou a Máquina Analítica (“Analytical Engine”), com capacidade de processamento muito superior, porém ela ficou limitada pela tecnologia mecânica daquela época. William Gibson, escritor, aproveita esse fato e nos conta uma interessante estória alternativa[2] de como seria o mundo se Babbage conseguisse construir sua máquina e o computador surgisse em pleno século XIX. Os século XX é marcado pelos grandes avanços. Gostaríamos de começar citando o romance “R.U.R.”[3], do tcheco Karel Capek, onde, em 1921, ele cria o termo “robot”, que na sua língua natal significa trabalhador. Sempre que falamos de robot, precisamos citar Isaac Asimov[4] e suas maravilhosas visões. Um marco importante neste século foi o ENIAC (do inglês “Electronic Numerical Integrator And Calculator”), ver Figura 1, projetado durante a Segunda Grande Guerra com a finalidade de calcular tiros de artilharia. Quando ele ficou pronto, em 1946, a guerra já havia acabado. Seu peso era de 30 t e consumia 140 kW. Um dos gênios que teve contato com esse projeto foi von Neumann, de quem falaremos mais adiante. Figura 1: ENIAC, sua programação era feita com fios ("hard wired"). Figura 2: Colossus, da Inglaterra. Sua programação também era feita com fios. Um outro grande projeto da época, anterior ao ENIAC e por isso pioneiro, foi o Colossus (Figura 2), desenvolvido na Inglaterra no período de 1939 a 1943 com a intenção de quebrar o código da máquina de criptografia alemã denominada Enigma, que gerava seqüências aleatórias com período de 1019 caracteres. Deste projeto, tomou parte Alan Turing, certamente um nome conhecido hoje em dia. Após a guerra, esse projeto foi descontinuado, mas permaneceu secreto até 1973. Dizem que, se esse projeto fosse publicado logo após a término da guerra, teríamos hoje uma grande indústria inglesa de computadores. Entramos em seguida na era da computação eletrônica, quando surgem os grandes computadores e, por detrás deles, as grandes empresas: IBM, Bourroughs, NCR, etc.. É a era de máquinas grandes, acessadas por uma multidão de terminais burros. Chegou-se a prever que no mundo haveria cinco grandes computadores, um para cada continente. Era a visão de homens simples perante máquinas maravilhosas e as vezes fatais, como conta Arthur Clark em "2001"[5]. Nas figuras a seguir vemos quatro marcos interessantes sobre esse passado. Para iniciar, falamos do termo “bug”, que sempre foi usado pelos engenheiros para indicar pequenas falhas em suas máquinas. Já em 1870, Thomas Edison falava de “bugs” em seus circuitos elétricos. Em 1947, os engenheiros que trabalhavam com o Harvard Mark I encontraram uma traça entre seus circuitos, prenderam-na no livro de registro e rotularam-na como o “primeiro bug” encontrado, como vemos na Figura 3. E como eles se tornariam comum! Na Figura 4 está o computador IAS, de 1952, que foi construído segundo orientação de von Newmann e muito influenciou o projeto do IBM 701, o primeiro computador eletrônico comercializado pela IBM. Temos ainda, na Figura 5, o UNIVAC, projetado pelos idealizadores do ENIAC. Finalmente, a Figura 6 mostra o PDP-8, primeiro computador com preço acessível, tendo sido uma máquina da série PDP onde Ken Thompson e Dennis Ritchie desenvolveram o UNIX. Figura 3: O primeiro "bug", 1947. Figura 4: Computador IAS, 1952. Figura 5: Modelo do UNIVAC, 1954. Figura 6: Minicomputador PDP-8, 1965. Essa visão de grandes máquinas, inalcançáveis para os pobres mortais, domina até 1971, quando surge o primeiro microprocessador, o Intel 4004. No início, não chamou muita atenção, mas paulatinamente foram surgindo outros processadores e, na esteira desses processadores, companhias que fabricavam pequenos computadores. O computador começava a aproximar-se do homem comum. Surgia assim o mercado dos microcomputadores. Nele, destacaram-se empresas que tropeçaram com o sucesso, que se tornaram gigantes e que passaram a ameaçar a posição de companhias do porte da HP e IBM. Essa história é contada de forma divertida por Robert Cringely em seu livro “Accidental Empires”[6]. Já mais voltada para o projeto de CPUs é a abordagem de Tracy Kidder em seu livro “The Soul of a New Machine”[7]. Já na área dos microcomputadores, perguntamo-nos: qual foi o primeiro ? Em 1975 a Revista “Popular Electronics” apresentou o projeto e anunciou a venda do “kit” do primeiro microcomputador. Era o Altair 8800, baseado no microprocessador 8008 da Intel, cuja foto está na Figura 7. O nome Altair é uma homenagem ao planeta onde se passa o filme “O Planeta Proibido” (1956) , onde aparece um robot (“Robbie”) cuja imagem ficaria famosa (Figura 8). Foi também para esse microcomputador que a dupla Paul Allen e Bill Gates vendeu um de seus primeiros produtos: um interpretador Basic. Figura 7: Altair 8008, o primeiro microcomputador. Figura 8: Cartaz do filme O Planeta Proibido, que inspirou o nome Altair. Outro fato marcante dessa época é o projeto da Xerox, no centro de pesquisas em Palo Alto, onde se desenvolveram vários conceitos de informática, inovadores para a época. Desse projeto surgiram o mouse, os ícones, as janelas e ainda computadores ligados em redes e as mensagens eletrônicas. Eram conceitos tão revolucionários que a alta direção da Xerox não soube aproveitá-los, mas Steve Jobs soube e colocou-os todos no Macintosh. Há quase vinte anos, em 1981, a IBM lançava seu microcomputador provocando um verdadeiro terremoto no mercado e terminando por polarizá-lo entre o IBM PC e o Macintosh da Apple. Na verdade, o primeiro microcomputador da IBM, o IBM 5100, lançado em 1975, foi um fracasso[8]. Nesses últimos vinte anos, experimentamos uma evolução de tirar o fôlego. Um PC equipado com um Pentium III é mais barato e duas mil vezes mais rápido que o PC XT original, isto sem falarmos dos recursos de vídeo 3D, som, DVD e Internet. A resposta é: não vamos parar. É claro que a evolução vai continuar, mas a atual arquitetura dos microcomputadores deverá mudar bastante, pois a concorrência está cada dia mai acirrada. Vejamos, por exemplo, o caso das estações de trabalho, antigamente tão superiores aos microcomputadores e que hoje disputam um mesmo mercado. Ao mesmo tempo que os microprocessadores caminham em direção às arquiteturas de 64 bits, surgem outros como processadores como os dedicados à Internet, os processadores para os roteadores e chaveadores das redes de alta velocidade e até processadores RISC com arquitetura passível de ser alterada pelo usuário. Com essa rápida resenha da história, particularizada no final para os microcomputadores, terminamos a primeira parte deste artigo. Vemos que muita coisa mudou, mas nem tanto, pois os computadores que usamos em casa seguem a mesma arquitetura proposta por von Newmann, ainda na década de 50. Assim, na continuação, abordaremos os postulados de von Newmann e estudaremos alguns conceitos de processamento paralelo, pois eles são fundamentais para entendermos os supercomputadores atuais e os que estão sendo projetados para o próximo milênio. Continue lendo: Processadores para o próximo milênio - parte 2 Livros [1] "Ada, the Enchantress of Numbers", Betty A. Toole (Editor). [2] "The Difference Engine", William Gibson. [3] "De Júlio Verne aos Astronautas", Coleção Argonauta, Número 100. [4] "Eu, Robô", Issac Asimov. [5] "HAL’s Legacy", David G. Stork (Editor). [6] "Accidental Empires", Robert X. Cringely. [7] "The Soul of a New Machine", Tracy Kidder. [8] "History of Computing", Mark Greenia. Sites Ada: http://www.agnesscott.edu/lriddle/women/love.htm Altair IV: http://neptune.spaceports.com/~slacker/altair4/ ENIAC: http://americanhistory.si.edu/csr/comphist/pr1.pdf e http://americanhistory.si.edu/csr/comphist/pr4.pdf. Colossus: http://www.cranfield.ac.uk/ccc/bpark/colossus.htm Diversos: http://www.cs.yale.edu/homes/tap/photo_gallery.html Histórico: http://americanhistory.si.edu/csr/comphist/
Finalmente, após o grande alarde do “Bug Y2K”, vamos ultrapassar a barreira do segundo milênio. Mas será que somos muito diferentes do homem de 2000 anos atrás? Não muito, o homem moderno, apesar de toda onda de informação, ainda lembra bastante seu antepassado, especialmente na adoração por datas, acontecimentos e cerimônias. Ao olharmos para trás, vimos que 2.000 anos formaram uma era. Quantas coisas nos separam daquele homem que não sabia medir o tempo, que acreditava que as estrelas eram candelabros de luzes e que a Terra era plana. O homem atual quebra os núcleos e transmuta os elementos, cria anti-matéria, manipula átomos, constrói máquinas inteligentes, envia naves além do Sistema Solar. Esta mesma sensação dual de mudança e não-mudança envolve-nos quando olhamos para trás em busca do nascimento da computação e, para a frente, querendo saber o que nos promete o próximo milênio. O presente artigo é o primeiro de uma série que irá explorar as realizações atuais e as especulações para o início do próximo milênio. Tentaremos apresentar um panorama diversificado, abordando não só as arquiteturas clássicas, mas também as evoluções que estão surgindo. Para tanto, não nos basta a experiência que temos com a família 80x86 para entendermos as novas arquiteturas, vamos precisar de alguns conceitos que serão abordados ao longo dos próximos artigos. Assim, vamos iniciar este artigo olhando para trás para apreciarmos o que aconteceu no passado e, em seguida, observaremos o mundo ao nosso redor e analisaremos o momento atual, para então abordamos as arquiteturas que serão as inovações para o próximo milênio. Finalmente, estudaremos em especial as arquiteturas de 64 bits da Intel (IA-64) e da AMD (x86-64). Qual foi o primeiro computador ? A resposta mais freqüente é o ábaco chinês, embora contestável por ele tratar-se de um instrumento auxiliar de cálculo. Acreditamos que o rótulo “computador no 1" deva ir para a calculadora mecânica de Blaise Pascal (homenageado com a linguagem Pascal), desenvolvida em 1642, que podia operar com números até 999.999.999. Em 1822, Charles Babbage desenvolveu a Máquina Diferencial (“Difference Engine”), que tinha uma arquitetura muito semelhante aos modernos processadores, apresentando CPU, memória e até linguagem de programação. A filha de Lord Byron, uma garota chamada Ada Byron[1], teve contato com esta máquina e acabou por se tornar a primeira programadora (em sua homenagem, temos hoje a linguagem ADA). Em 1833, Babbage projetou a Máquina Analítica (“Analytical Engine”), com capacidade de processamento muito superior, porém ela ficou limitada pela tecnologia mecânica daquela época. William Gibson, escritor, aproveita esse fato e nos conta uma interessante estória alternativa[2] de como seria o mundo se Babbage conseguisse construir sua máquina e o computador surgisse em pleno século XIX. Os século XX é marcado pelos grandes avanços. Gostaríamos de começar citando o romance “R.U.R.”[3], do tcheco Karel Capek, onde, em 1921, ele cria o termo “robot”, que na sua língua natal significa trabalhador. Sempre que falamos de robot, precisamos citar Isaac Asimov[4] e suas maravilhosas visões. Um marco importante neste século foi o ENIAC (do inglês “Electronic Numerical Integrator And Calculator”), ver Figura 1, projetado durante a Segunda Grande Guerra com a finalidade de calcular tiros de artilharia. Quando ele ficou pronto, em 1946, a guerra já havia acabado. Seu peso era de 30 t e consumia 140 kW. Um dos gênios que teve contato com esse projeto foi von Neumann, de quem falaremos mais adiante. Figura 1: ENIAC, sua programação era feita com fios ("hard wired"). Figura 2: Colossus, da Inglaterra. Sua programação também era feita com fios. Um outro grande projeto da época, anterior ao ENIAC e por isso pioneiro, foi o Colossus (Figura 2), desenvolvido na Inglaterra no período de 1939 a 1943 com a intenção de quebrar o código da máquina de criptografia alemã denominada Enigma, que gerava seqüências aleatórias com período de 1019 caracteres. Deste projeto, tomou parte Alan Turing, certamente um nome conhecido hoje em dia. Após a guerra, esse projeto foi descontinuado, mas permaneceu secreto até 1973. Dizem que, se esse projeto fosse publicado logo após a término da guerra, teríamos hoje uma grande indústria inglesa de computadores. Entramos em seguida na era da computação eletrônica, quando surgem os grandes computadores e, por detrás deles, as grandes empresas: IBM, Bourroughs, NCR, etc.. É a era de máquinas grandes, acessadas por uma multidão de terminais burros. Chegou-se a prever que no mundo haveria cinco grandes computadores, um para cada continente. Era a visão de homens simples perante máquinas maravilhosas e as vezes fatais, como conta Arthur Clark em "2001"[5]. Nas figuras a seguir vemos quatro marcos interessantes sobre esse passado. Para iniciar, falamos do termo “bug”, que sempre foi usado pelos engenheiros para indicar pequenas falhas em suas máquinas. Já em 1870, Thomas Edison falava de “bugs” em seus circuitos elétricos. Em 1947, os engenheiros que trabalhavam com o Harvard Mark I encontraram uma traça entre seus circuitos, prenderam-na no livro de registro e rotularam-na como o “primeiro bug” encontrado, como vemos na Figura 3. E como eles se tornariam comum! Na Figura 4 está o computador IAS, de 1952, que foi construído segundo orientação de von Newmann e muito influenciou o projeto do IBM 701, o primeiro computador eletrônico comercializado pela IBM. Temos ainda, na Figura 5, o UNIVAC, projetado pelos idealizadores do ENIAC. Finalmente, a Figura 6 mostra o PDP-8, primeiro computador com preço acessível, tendo sido uma máquina da série PDP onde Ken Thompson e Dennis Ritchie desenvolveram o UNIX. Figura 3: O primeiro "bug", 1947. Figura 4: Computador IAS, 1952. Figura 5: Modelo do UNIVAC, 1954. Figura 6: Minicomputador PDP-8, 1965. Essa visão de grandes máquinas, inalcançáveis para os pobres mortais, domina até 1971, quando surge o primeiro microprocessador, o Intel 4004. No início, não chamou muita atenção, mas paulatinamente foram surgindo outros processadores e, na esteira desses processadores, companhias que fabricavam pequenos computadores. O computador começava a aproximar-se do homem comum. Surgia assim o mercado dos microcomputadores. Nele, destacaram-se empresas que tropeçaram com o sucesso, que se tornaram gigantes e que passaram a ameaçar a posição de companhias do porte da HP e IBM. Essa história é contada de forma divertida por Robert Cringely em seu livro “Accidental Empires”[6]. Já mais voltada para o projeto de CPUs é a abordagem de Tracy Kidder em seu livro “The Soul of a New Machine”[7]. Já na área dos microcomputadores, perguntamo-nos: qual foi o primeiro ? Em 1975 a Revista “Popular Electronics” apresentou o projeto e anunciou a venda do “kit” do primeiro microcomputador. Era o Altair 8800, baseado no microprocessador 8008 da Intel, cuja foto está na Figura 7. O nome Altair é uma homenagem ao planeta onde se passa o filme “O Planeta Proibido” (1956) , onde aparece um robot (“Robbie”) cuja imagem ficaria famosa (Figura 8). Foi também para esse microcomputador que a dupla Paul Allen e Bill Gates vendeu um de seus primeiros produtos: um interpretador Basic. Figura 7: Altair 8008, o primeiro microcomputador. Figura 8: Cartaz do filme O Planeta Proibido, que inspirou o nome Altair. Outro fato marcante dessa época é o projeto da Xerox, no centro de pesquisas em Palo Alto, onde se desenvolveram vários conceitos de informática, inovadores para a época. Desse projeto surgiram o mouse, os ícones, as janelas e ainda computadores ligados em redes e as mensagens eletrônicas. Eram conceitos tão revolucionários que a alta direção da Xerox não soube aproveitá-los, mas Steve Jobs soube e colocou-os todos no Macintosh. Há quase vinte anos, em 1981, a IBM lançava seu microcomputador provocando um verdadeiro terremoto no mercado e terminando por polarizá-lo entre o IBM PC e o Macintosh da Apple. Na verdade, o primeiro microcomputador da IBM, o IBM 5100, lançado em 1975, foi um fracasso[8]. Nesses últimos vinte anos, experimentamos uma evolução de tirar o fôlego. Um PC equipado com um Pentium III é mais barato e duas mil vezes mais rápido que o PC XT original, isto sem falarmos dos recursos de vídeo 3D, som, DVD e Internet. A resposta é: não vamos parar. É claro que a evolução vai continuar, mas a atual arquitetura dos microcomputadores deverá mudar bastante, pois a concorrência está cada dia mai acirrada. Vejamos, por exemplo, o caso das estações de trabalho, antigamente tão superiores aos microcomputadores e que hoje disputam um mesmo mercado. Ao mesmo tempo que os microprocessadores caminham em direção às arquiteturas de 64 bits, surgem outros como processadores como os dedicados à Internet, os processadores para os roteadores e chaveadores das redes de alta velocidade e até processadores RISC com arquitetura passível de ser alterada pelo usuário. Com essa rápida resenha da história, particularizada no final para os microcomputadores, terminamos a primeira parte deste artigo. Vemos que muita coisa mudou, mas nem tanto, pois os computadores que usamos em casa seguem a mesma arquitetura proposta por von Newmann, ainda na década de 50. Assim, na continuação, abordaremos os postulados de von Newmann e estudaremos alguns conceitos de processamento paralelo, pois eles são fundamentais para entendermos os supercomputadores atuais e os que estão sendo projetados para o próximo milênio. Continue lendo: Processadores para o próximo milênio - parte 2 Livros [1] "Ada, the Enchantress of Numbers", Betty A. Toole (Editor). [2] "The Difference Engine", William Gibson. [3] "De Júlio Verne aos Astronautas", Coleção Argonauta, Número 100. [4] "Eu, Robô", Issac Asimov. [5] "HAL’s Legacy", David G. Stork (Editor). [6] "Accidental Empires", Robert X. Cringely. [7] "The Soul of a New Machine", Tracy Kidder. [8] "History of Computing", Mark Greenia. Sites Ada: http://www.agnesscott.edu/lriddle/women/love.htm Altair IV: http://neptune.spaceports.com/~slacker/altair4/ ENIAC: http://americanhistory.si.edu/csr/comphist/pr1.pdf e http://americanhistory.si.edu/csr/comphist/pr4.pdf. Colossus: http://www.cranfield.ac.uk/ccc/bpark/colossus.htm Diversos: http://www.cs.yale.edu/homes/tap/photo_gallery.html Histórico: http://americanhistory.si.edu/csr/comphist/ -
 Desde seu lançamento, em junho de 1999, a CPU Athlon está cumprindo as promessas feitas pela AMD e, ao mesmo tempo, realizando um sonho, pelo menos para nós que valorizamos a concorrência: no momento, a CPU mais veloz do mercado não é fabricada pela Intel! Nada temos contra a Intel, aliás, ela tem o mérito de ter inventado o mercado de microprocessadores, porém só conseguiremos comprar bons computadores a preços razoáveis enquanto houver concorrência. Quanto mais concorrência, computadores melhores e mais baratos. O principal objetivo de um fabricante de CPU não é o de entregar CPUs rápidas e baratas, mas sim o de gerar lucro para seus acionistas. No começo dos anos 90, havia vários fabricantes de CPU disputando o mercado e surgiram outros ao longo da década. Mas agora, ao iniciarmos o ano 2000, devemos nos preocupar um pouco com a concorrência, pois restaram apenas dois fabricantes de CPUs de alto desempenho: Intel e AMD. A AMD iniciou o ano 2000 rompendo, pela primeira vez no mundo dos microcomputadores, a significativa barreira dos 1.000 MHz. No dia 6 de janeiro, a equipe formada por AMD, Compaq e Kryo Tech apresentou uma máquina Presario, "motorizada" com um processador Athlon trabalhando a 1 GHz. é claro que esse computador é um mero protótipo de laboratório e tal velocidade só foi alcançada graças às técnicas de refrigeração fornecidas pela Kryo Tech. Mas não deixa de ser um grande feito e, por isso, vamos analisá-lo um pouco. O principal problema para uma CPU rodar com um relógio elevado é o seu aquecimento. Quanto maior a velocidade, maior a quantidade de calor gerado no interior do semicondutor. Se for providenciado um mecanismo eficiente para remoção deste calor, então é possível atingir altas velocidades. E é exatamente isso que foi feito com esse computador onde, é claro, só a CPU roda em 1 GHz, todo o resto trabalha nas velocidades usuais. Uma das maneiras de minimizar o calor gerado no interior da CPU é a diminuição do seu tamanho e o emprego de condutores mais eficientes, como, por exemplo, o cobre. Todo condutor se aquece na presença de corrente elétrica; porém, quanto melhor o condutor, menos calor ele gera. Nas CPUs atuais, todas as conexões metálicas são feitas com alumínio. O cobre era um sério candidato a fazer essas conexões pois ele tem melhores propriedades condutoras que o alumínio; todavia, problemas tecnológicos impediam seu emprego dentro de CI. Com a solução desses problemas, o cobre está passando a ser usado de forma intensa, possibilitando o uso de relógios mais rápidos. A atual versão do Athlon é fabricada em Austin, Texas, no que a AMD chama de Fab 25. Ela usa tecnologia de 0,18 micron para integrar 22 milhões de transistores num "die" de 102 mm2 de área. Por volta da metade deste ano, usando a Fab 30, que fica em Dresden - Alemanha, a AMD deverá começar a entregar o Athlon com tecnologia de interconexão usando cobre. O Athlon, nome comercial para o K7, na época do seu lançamento, operava na velocidade de 500 MHz. Logo em seguida, observou-se uma escalada de velocidade (MHz) a preços ainda razoáveis: 500 MHZ ($209), 550 ($279), 600 ($419), 650 ($519), 700 ($699), 750 ($799) e atualmente 800 MHz ($849). é interessante olhar a relação desses preços com a velocidade, como mostrado na Figura 1. Pode ser notado que a variação de preço entre 750 e 800 MHz é muito pequena, quando comparado com o que se paga para subir de 650 MHz para 700 MHz. Há, notoriamente, a preferência para se venderem CPUs com determinadas velocidades. Isso fica muito claro na Figura 2, que mostra o quanto se paga para aumentar 50 MHz na velocidade do Athlon. Figura 1: Relação entre MHz e US$ usado pela AMD para vender a CPU Athlon, em lotes de 1.000 unidades. Figura 2: Quanto custa aumentar 50 MHz numa CPU Athlon. Por exemplo, para passar de uma CPU de 500 MHz para uma de 550 MHz, é necessário pagar mais US$ 70,00. A AMD está realmente oferecendo processadores que ultrapassam o desempenho dos Pentium III. Quando se trata de desempenho, não basta comparar os relógios, também é necessário verificar como está a velocidade da unidade de inteiros e a da unidade de ponto-flutuante. Além disso, é importante ver o desempenho global do processador, por exemplo, em aplicações Windows e, por curiosidade, em alguns jogos. A seguir, são exibidos quatro quadros comparativos que mostram o desempenho do Athlon em um ambiente Windows (Figura 3), em jogos (Figura 4), no processamento de inteiros (Figura 5) e, finalmente, no processamento de números representados em ponto-flutuante (Figura 6). Todas essas informações foram obtidas junto à "Home-Page" da AMD e, por isso, não devem ser aceitas como verdades absolutas. Quem nunca caiu em um "papo de vendedor"? É prudente desconfiar um pouco do que eles nos afirmam. Chamamos ainda a atenção para o fato de que, em todas as comparações, o relógio usado com o Athlon foi superior ao usado com o Pentium III. Figura 3: Desempenho comparativo do Athlon em processamento Windows (Ziff Davis Winstone 99 - Windows NT). Figura 4: Desempenho comparativo do Athlon em jogos (Quake3 Demo2 640x480 Normal). Figura 5: Desempenho comparativo do Athlon em processamento de números inteiros (SPECint_base95). Figura 6: Desempenho comparativo do Athlon em processamento de números representados em ponto-flutuante (SPECfp_base95). Para o ano 2000, a AMD planeja introduzir diferentes versões do processador Athlon. Essas versões estão baseadas em três novos núcleos ("cores") de processamento: Thunderbird, Spitfire e Mustang. O núcleo Thunderbird está sendo projetado para ser uma versão de alto desempenho do processador Athlon, com um cache L2 integrado dentro do chip e trabalhando na mesma velocidade da CPU. Serão oferecidas implementações tanto para Soquete como para Slot. O Thunderbird terá por alvo o mercado de computadores de mesa e estações de trabalho. O núcleo Spitfire está sendo projetado para ser uma versão evoluída do processador Athlon, também com um cache L2 integrado dentro do chip e trabalhando na mesma velocidade de CPU. Com esse processador, pretende-se premiar a relação custo-benefício. Ele virá apenas na implementação com Slot A e terá como alvo o mercado de computadores de mesa. O núcleo Mustand será um aperfeiçoamento do Thunderbird, oferecendo um tamanho de CI reduzido, baixo consumo de energia e até 2 MB de cache L2, integrado dentro do mesmo chip e trabalhando na mesma velocidade da CPU. Serão oferecidas versões em Slot e em Soquete. Serão implementadas muitas versões deste núcleo, visando aos mercados das estações de trabalho, computadores de mesa, computadores com boa relação custo-desempenho e computadores portáteis. Com essa descrição, percebe-se que o próximo passo, na disputa do mercado de CPUs, será a integração do cache L2 junto com a pastilha da CPU. Isso porque a velocidade do cache L2 está ficando pequena quando comparada com a da CPU. Na verdade, a velocidade das memórias (externas), usadas nos caches L2, já está no limite permitido pelo custo. Segundo afirmações da AMD, a CPU Athlon traz, pela primeira vez em plataforma x86, uma unidade de ponto-flutuante usando pipeline superescalar, o que permite grande desempenho e a torna competitiva com processadores RISC usados em estações de trabalho, pois, com relógio de 800 MHz, oferece 3,2 Gflops (precisão simples). Essa CPU usa o que a AMD chama de superpipeline, com nove elementos simultâneos (superescalar), otimizados para trabalhar em altas freqüências. Em palavras mais simples, são nove pipelines (de execução) em paralelo: Três para cálculo de endereços Três para cálculo de inteiros Três para executar instruções de ponto-flutuante, 3DNow e MMX. Como acontece com todas as CPUs modernas (da família x86), as complexas instruções x86 são traduzidas em instruções RISC que, no caso da AMD, são chamadas de "Micro-Ops". Essas instruções RISC são mais simples e têm tamanho fixo, o que facilita o controle e a execução de várias delas ao mesmo tempo. A Figura 7 apresenta um diagrama em blocos dessa CPU, onde devem ser notadas as nove unidades de execução que trabalham em paralelo e o bloco denominado "decodificadores de instruções", além do cache L1 que está dividido em dois blocos, um para instruções e outro para dados, perfazendo 128 KB. Figura 7: Diagrama em blocos da arquitetura do processador Athlon. O primeiro fabricante a oferecer a tecnologia MMX para ponto-flutuante foi a AMD, sob o nome 3DNow, que era incorporada nas suas CPUs K6-III. Essa tecnologia 3DNow, com suas 21 instruções, oferece SIMD ("Single Instruction Multiple Data") com ponto-flutuante e, para ser incorporada ao o Athlon, sofreu um incremento de 24 novas instruções, assim agrupadas: 12 instruções para melhorar os cálculos com números inteiros usados em operações multimídia, tais como reconhecimento de voz e processamento de vídeo; 7 instruções que aceleram as transferências de dados, permitindo gráficos mais detalhados e novas funcionalidades para os "browsers" Internet; 5 instruções DSP que melhoram as operações envolvidas nos aplicativos de comunicações tais como soft modem, soft ADSL, Dolby Digital e MP3. Essa CPU inclui o maior cache L1 de sua classe, com um total de 128 KB, dividido em 64 KB para dados e 64 KB para dados, como já foi observado na Figura 7. O cache L1 está integrado dentro do chip da CPU e trabalha com barramento de 64 bits. Para o cache L2, que está "fora" do chip, foi construído um barramento traseiro (BSB-"Back Side Bus") de 72 bits, sendo 64 bits de dados e 8 bits para correção de erros, onde é possível conectar um cache que pode variar de 512 KB até 8 MB. Esse barramento BSB é rápido e é capaz de tirar proveito da alta velocidade das modernas memórias. No lançamento de CPUs de alto desempenho, não é raro encontrarmos problemas de atrasos na produção de seus chipsets. O chipset é um item muito importante, pois ele traz consigo todo o resto do computador. Usando uma comparação extremamente simples com um carro, dizemos que a CPU é o motor desse carro, enquanto que todo o "resto" é chamado de chipset. Além do motor potente, um carro precisa de uma excelente suspensão, chassi, sistema de freios, etc.. No momento, a AMD oferece para o Athlon o chipset 750, cujo diagrama está mostrado na Figura 8. Apesar deste conjunto de CIs trazer algumas novidades, como o "super bypass" que reduz em 25% o tempo latência para os acessos à memória principal, sabe-se que ainda há muito espaço para desenvolvimento. Esperam-se, num futuro próximo, o AGP 4X e os recursos para o emprego de várias CPUs (multi-processamento). A AMD está em contato com outras empresas que operam no mercado de chipsets, tais como VIA Technologies, SiS, Acer Laboratories, Inc (ALI) e Triden, para que, através de soluções próprias, se consiga mais flexibilidade e variedade na oferta de chipsets. Figura 8: Diagrama do Athlon conectado ao chipset AMD 750. Graças à adoção da tecnologia de barramento Alpha EV6, desenvolvida pela Digital Equipment Corp., a AMD pode oferecer o primeiro barramento de 200 MHz em plataformas x86 e ainda existem promessas para esse barramento operar até 400 MHz. Trabalhando com 64 bits em 200 MHz, essa CPU oferece uma taxa de comunicação de 1,6 GB/s, que é um valor grande (ganho de 45%) quando comparado com os 1,1 GB/s do Pentium III que opera em 133 MHz. O novo barramento de 200 MHz, que pretende chegar a 266 MHz ainda este ano, e a simplicidade que se obtém ao colocar a memória cache L2 próximo ao chip da CPU, levaram a AMD a abandonar o soquete Super 7 e a criar o denominado Slot A. Esse slot A é mecanicamente igual ao Slot 1 da Intel, mas eletricamente distinto. Por isso, a CPU Athlon é entregue em um cartucho parecido com o do Pentium II ou III, mas esse cartucho só pode ser usado nos Slots A. Com a evolução dos mercados, a AMD pretende oferecer CPUs Athlon para soquetes, mas essas versões sempre serão destinadas a computadores de baixo custo e desempenho inferior, enquanto que o Slot A será sempre usado para o computadores de alto desempenho. Ao terminar este artigo é interessante fazermos uma análise síntese dos principais recursos do Athlon em comparação com os do Pentium III. Isso é visto na tabela a seguir. Características Athlon (Slot A) Pentium III (Slot 1) Operações por ciclo de relógio 9 5 Pipeline de Inteiros 3 2 Pipeline de Ponto-Flutuante 3 1 Decodificadores x86 (completos) 3 1 Tamanho do cache L1 128 KB 32 KB Tamanho do cache L2 512BK - 8MB 256 KB (interno) 512KB-2MB (externo) Velocidade do barramento 200 MHz 66 ou 133 MHz Banda passante do barramento 1,6 GB/s 533 MB/s ou 1,1 GB/s Número de transistores 22 milhões 9,5 - 28 milhões O mercado está aquecido e a disputa pela fatia das CPUs de alto desempenho continua acirrada e certamente a Intel tem vários recursos para lançar mão. Enquanto isso, nós os consumidores continuamos a desfrutar desses processadores que nos chegam com preços cada vez mais interessantes.
Desde seu lançamento, em junho de 1999, a CPU Athlon está cumprindo as promessas feitas pela AMD e, ao mesmo tempo, realizando um sonho, pelo menos para nós que valorizamos a concorrência: no momento, a CPU mais veloz do mercado não é fabricada pela Intel! Nada temos contra a Intel, aliás, ela tem o mérito de ter inventado o mercado de microprocessadores, porém só conseguiremos comprar bons computadores a preços razoáveis enquanto houver concorrência. Quanto mais concorrência, computadores melhores e mais baratos. O principal objetivo de um fabricante de CPU não é o de entregar CPUs rápidas e baratas, mas sim o de gerar lucro para seus acionistas. No começo dos anos 90, havia vários fabricantes de CPU disputando o mercado e surgiram outros ao longo da década. Mas agora, ao iniciarmos o ano 2000, devemos nos preocupar um pouco com a concorrência, pois restaram apenas dois fabricantes de CPUs de alto desempenho: Intel e AMD. A AMD iniciou o ano 2000 rompendo, pela primeira vez no mundo dos microcomputadores, a significativa barreira dos 1.000 MHz. No dia 6 de janeiro, a equipe formada por AMD, Compaq e Kryo Tech apresentou uma máquina Presario, "motorizada" com um processador Athlon trabalhando a 1 GHz. é claro que esse computador é um mero protótipo de laboratório e tal velocidade só foi alcançada graças às técnicas de refrigeração fornecidas pela Kryo Tech. Mas não deixa de ser um grande feito e, por isso, vamos analisá-lo um pouco. O principal problema para uma CPU rodar com um relógio elevado é o seu aquecimento. Quanto maior a velocidade, maior a quantidade de calor gerado no interior do semicondutor. Se for providenciado um mecanismo eficiente para remoção deste calor, então é possível atingir altas velocidades. E é exatamente isso que foi feito com esse computador onde, é claro, só a CPU roda em 1 GHz, todo o resto trabalha nas velocidades usuais. Uma das maneiras de minimizar o calor gerado no interior da CPU é a diminuição do seu tamanho e o emprego de condutores mais eficientes, como, por exemplo, o cobre. Todo condutor se aquece na presença de corrente elétrica; porém, quanto melhor o condutor, menos calor ele gera. Nas CPUs atuais, todas as conexões metálicas são feitas com alumínio. O cobre era um sério candidato a fazer essas conexões pois ele tem melhores propriedades condutoras que o alumínio; todavia, problemas tecnológicos impediam seu emprego dentro de CI. Com a solução desses problemas, o cobre está passando a ser usado de forma intensa, possibilitando o uso de relógios mais rápidos. A atual versão do Athlon é fabricada em Austin, Texas, no que a AMD chama de Fab 25. Ela usa tecnologia de 0,18 micron para integrar 22 milhões de transistores num "die" de 102 mm2 de área. Por volta da metade deste ano, usando a Fab 30, que fica em Dresden - Alemanha, a AMD deverá começar a entregar o Athlon com tecnologia de interconexão usando cobre. O Athlon, nome comercial para o K7, na época do seu lançamento, operava na velocidade de 500 MHz. Logo em seguida, observou-se uma escalada de velocidade (MHz) a preços ainda razoáveis: 500 MHZ ($209), 550 ($279), 600 ($419), 650 ($519), 700 ($699), 750 ($799) e atualmente 800 MHz ($849). é interessante olhar a relação desses preços com a velocidade, como mostrado na Figura 1. Pode ser notado que a variação de preço entre 750 e 800 MHz é muito pequena, quando comparado com o que se paga para subir de 650 MHz para 700 MHz. Há, notoriamente, a preferência para se venderem CPUs com determinadas velocidades. Isso fica muito claro na Figura 2, que mostra o quanto se paga para aumentar 50 MHz na velocidade do Athlon. Figura 1: Relação entre MHz e US$ usado pela AMD para vender a CPU Athlon, em lotes de 1.000 unidades. Figura 2: Quanto custa aumentar 50 MHz numa CPU Athlon. Por exemplo, para passar de uma CPU de 500 MHz para uma de 550 MHz, é necessário pagar mais US$ 70,00. A AMD está realmente oferecendo processadores que ultrapassam o desempenho dos Pentium III. Quando se trata de desempenho, não basta comparar os relógios, também é necessário verificar como está a velocidade da unidade de inteiros e a da unidade de ponto-flutuante. Além disso, é importante ver o desempenho global do processador, por exemplo, em aplicações Windows e, por curiosidade, em alguns jogos. A seguir, são exibidos quatro quadros comparativos que mostram o desempenho do Athlon em um ambiente Windows (Figura 3), em jogos (Figura 4), no processamento de inteiros (Figura 5) e, finalmente, no processamento de números representados em ponto-flutuante (Figura 6). Todas essas informações foram obtidas junto à "Home-Page" da AMD e, por isso, não devem ser aceitas como verdades absolutas. Quem nunca caiu em um "papo de vendedor"? É prudente desconfiar um pouco do que eles nos afirmam. Chamamos ainda a atenção para o fato de que, em todas as comparações, o relógio usado com o Athlon foi superior ao usado com o Pentium III. Figura 3: Desempenho comparativo do Athlon em processamento Windows (Ziff Davis Winstone 99 - Windows NT). Figura 4: Desempenho comparativo do Athlon em jogos (Quake3 Demo2 640x480 Normal). Figura 5: Desempenho comparativo do Athlon em processamento de números inteiros (SPECint_base95). Figura 6: Desempenho comparativo do Athlon em processamento de números representados em ponto-flutuante (SPECfp_base95). Para o ano 2000, a AMD planeja introduzir diferentes versões do processador Athlon. Essas versões estão baseadas em três novos núcleos ("cores") de processamento: Thunderbird, Spitfire e Mustang. O núcleo Thunderbird está sendo projetado para ser uma versão de alto desempenho do processador Athlon, com um cache L2 integrado dentro do chip e trabalhando na mesma velocidade da CPU. Serão oferecidas implementações tanto para Soquete como para Slot. O Thunderbird terá por alvo o mercado de computadores de mesa e estações de trabalho. O núcleo Spitfire está sendo projetado para ser uma versão evoluída do processador Athlon, também com um cache L2 integrado dentro do chip e trabalhando na mesma velocidade de CPU. Com esse processador, pretende-se premiar a relação custo-benefício. Ele virá apenas na implementação com Slot A e terá como alvo o mercado de computadores de mesa. O núcleo Mustand será um aperfeiçoamento do Thunderbird, oferecendo um tamanho de CI reduzido, baixo consumo de energia e até 2 MB de cache L2, integrado dentro do mesmo chip e trabalhando na mesma velocidade da CPU. Serão oferecidas versões em Slot e em Soquete. Serão implementadas muitas versões deste núcleo, visando aos mercados das estações de trabalho, computadores de mesa, computadores com boa relação custo-desempenho e computadores portáteis. Com essa descrição, percebe-se que o próximo passo, na disputa do mercado de CPUs, será a integração do cache L2 junto com a pastilha da CPU. Isso porque a velocidade do cache L2 está ficando pequena quando comparada com a da CPU. Na verdade, a velocidade das memórias (externas), usadas nos caches L2, já está no limite permitido pelo custo. Segundo afirmações da AMD, a CPU Athlon traz, pela primeira vez em plataforma x86, uma unidade de ponto-flutuante usando pipeline superescalar, o que permite grande desempenho e a torna competitiva com processadores RISC usados em estações de trabalho, pois, com relógio de 800 MHz, oferece 3,2 Gflops (precisão simples). Essa CPU usa o que a AMD chama de superpipeline, com nove elementos simultâneos (superescalar), otimizados para trabalhar em altas freqüências. Em palavras mais simples, são nove pipelines (de execução) em paralelo: Três para cálculo de endereços Três para cálculo de inteiros Três para executar instruções de ponto-flutuante, 3DNow e MMX. Como acontece com todas as CPUs modernas (da família x86), as complexas instruções x86 são traduzidas em instruções RISC que, no caso da AMD, são chamadas de "Micro-Ops". Essas instruções RISC são mais simples e têm tamanho fixo, o que facilita o controle e a execução de várias delas ao mesmo tempo. A Figura 7 apresenta um diagrama em blocos dessa CPU, onde devem ser notadas as nove unidades de execução que trabalham em paralelo e o bloco denominado "decodificadores de instruções", além do cache L1 que está dividido em dois blocos, um para instruções e outro para dados, perfazendo 128 KB. Figura 7: Diagrama em blocos da arquitetura do processador Athlon. O primeiro fabricante a oferecer a tecnologia MMX para ponto-flutuante foi a AMD, sob o nome 3DNow, que era incorporada nas suas CPUs K6-III. Essa tecnologia 3DNow, com suas 21 instruções, oferece SIMD ("Single Instruction Multiple Data") com ponto-flutuante e, para ser incorporada ao o Athlon, sofreu um incremento de 24 novas instruções, assim agrupadas: 12 instruções para melhorar os cálculos com números inteiros usados em operações multimídia, tais como reconhecimento de voz e processamento de vídeo; 7 instruções que aceleram as transferências de dados, permitindo gráficos mais detalhados e novas funcionalidades para os "browsers" Internet; 5 instruções DSP que melhoram as operações envolvidas nos aplicativos de comunicações tais como soft modem, soft ADSL, Dolby Digital e MP3. Essa CPU inclui o maior cache L1 de sua classe, com um total de 128 KB, dividido em 64 KB para dados e 64 KB para dados, como já foi observado na Figura 7. O cache L1 está integrado dentro do chip da CPU e trabalha com barramento de 64 bits. Para o cache L2, que está "fora" do chip, foi construído um barramento traseiro (BSB-"Back Side Bus") de 72 bits, sendo 64 bits de dados e 8 bits para correção de erros, onde é possível conectar um cache que pode variar de 512 KB até 8 MB. Esse barramento BSB é rápido e é capaz de tirar proveito da alta velocidade das modernas memórias. No lançamento de CPUs de alto desempenho, não é raro encontrarmos problemas de atrasos na produção de seus chipsets. O chipset é um item muito importante, pois ele traz consigo todo o resto do computador. Usando uma comparação extremamente simples com um carro, dizemos que a CPU é o motor desse carro, enquanto que todo o "resto" é chamado de chipset. Além do motor potente, um carro precisa de uma excelente suspensão, chassi, sistema de freios, etc.. No momento, a AMD oferece para o Athlon o chipset 750, cujo diagrama está mostrado na Figura 8. Apesar deste conjunto de CIs trazer algumas novidades, como o "super bypass" que reduz em 25% o tempo latência para os acessos à memória principal, sabe-se que ainda há muito espaço para desenvolvimento. Esperam-se, num futuro próximo, o AGP 4X e os recursos para o emprego de várias CPUs (multi-processamento). A AMD está em contato com outras empresas que operam no mercado de chipsets, tais como VIA Technologies, SiS, Acer Laboratories, Inc (ALI) e Triden, para que, através de soluções próprias, se consiga mais flexibilidade e variedade na oferta de chipsets. Figura 8: Diagrama do Athlon conectado ao chipset AMD 750. Graças à adoção da tecnologia de barramento Alpha EV6, desenvolvida pela Digital Equipment Corp., a AMD pode oferecer o primeiro barramento de 200 MHz em plataformas x86 e ainda existem promessas para esse barramento operar até 400 MHz. Trabalhando com 64 bits em 200 MHz, essa CPU oferece uma taxa de comunicação de 1,6 GB/s, que é um valor grande (ganho de 45%) quando comparado com os 1,1 GB/s do Pentium III que opera em 133 MHz. O novo barramento de 200 MHz, que pretende chegar a 266 MHz ainda este ano, e a simplicidade que se obtém ao colocar a memória cache L2 próximo ao chip da CPU, levaram a AMD a abandonar o soquete Super 7 e a criar o denominado Slot A. Esse slot A é mecanicamente igual ao Slot 1 da Intel, mas eletricamente distinto. Por isso, a CPU Athlon é entregue em um cartucho parecido com o do Pentium II ou III, mas esse cartucho só pode ser usado nos Slots A. Com a evolução dos mercados, a AMD pretende oferecer CPUs Athlon para soquetes, mas essas versões sempre serão destinadas a computadores de baixo custo e desempenho inferior, enquanto que o Slot A será sempre usado para o computadores de alto desempenho. Ao terminar este artigo é interessante fazermos uma análise síntese dos principais recursos do Athlon em comparação com os do Pentium III. Isso é visto na tabela a seguir. Características Athlon (Slot A) Pentium III (Slot 1) Operações por ciclo de relógio 9 5 Pipeline de Inteiros 3 2 Pipeline de Ponto-Flutuante 3 1 Decodificadores x86 (completos) 3 1 Tamanho do cache L1 128 KB 32 KB Tamanho do cache L2 512BK - 8MB 256 KB (interno) 512KB-2MB (externo) Velocidade do barramento 200 MHz 66 ou 133 MHz Banda passante do barramento 1,6 GB/s 533 MB/s ou 1,1 GB/s Número de transistores 22 milhões 9,5 - 28 milhões O mercado está aquecido e a disputa pela fatia das CPUs de alto desempenho continua acirrada e certamente a Intel tem vários recursos para lançar mão. Enquanto isso, nós os consumidores continuamos a desfrutar desses processadores que nos chegam com preços cada vez mais interessantes. -
 O tempo em que se especulava sobre o sucesso do DVD já passou. Tendo provado seu valor como uma mídia de alta qualidade para a distribuição de vídeo e multimídia, o DVD agora avança sobre o mercado de alta capacidade de armazenamento, com técnicas inovadoras na gravação bem como na tecnologia de regravação. No início, o foco de interesse da indústria estava voltado às aplicações de vídeo. O sucesso do lançamento de vídeos em discos com 4.7 GB de capacidade foi prematuramente antecipado, sendo a qualidade do mesmo comparada com os discos laser e com a transmissão de televisão. Entretanto, de forma análoga ao que ocorre com toda nova tecnologia, vários foram os obstáculos pelos quais o DVD teve de passar até amadurecer e ganhar o espaço de mercado que hoje tem. Os primeiros DVD-5 produzidos foram testados em vários modelos de equipamentos, de diferentes fabricantes, e apresentaram alguns problemas relacionados com a qualidade de vídeo bem como com os leitores das mídias. Isto foi decisivo para que o processo de fabricação dos discos fosse melhorado de forma que se obtivesse uma maior qualidade a um menor custo. Ao mesmo tempo, os fabricantes de equipamentos delineavam os padrões de compatibilidade para os equipamentos. à medida que as melhorias eram implementadas, a expectativa de utilizarem-se CDs para armazenamento de informação de vídeo foi perdendo a força e o DVD começou a tornar-se um outro padrão de armazenamento, cujas versões estão mostradas na Figura 2. Com o crescente aumento de demanda, não demorou muito tempo para que os 4,7 GB não fossem suficientes para atender às aplicações multimídia. Mas o DVD Fórum, segmento da indústria responsável pela normatização, já havia previsto uma padronização para a família de produtos DVD: DVD-9 e DVD-10. Com 9,4 GB de capacidade de armazenamento, o DVD-10, que na prática corresponde a nada mais que dois DVD-5 fundidos, tornou-se a solução mais simples. Com a produção do DVD-5 já refinada, o processo de fusão usado para colocar dois discos unidos face à face não necessitou de considerações especiais. Entretanto, sob o ponto de vista da distribuição em massa, o DVD-10 é problemático. O disco não oferece qualquer face para que sejam colocadas identificações ou mesmo estampas decorativas. Além disto, a maioria dos leitores de DVDs dos consumidores contém somente uma cabeça de leitura ótica, o que os obriga a tirarem o disco do leitor e virarem a face de leitura. Esta deficiência compromete seriamente o produto pois nenhum usuário de títulos em DVD, consumidores vorazes de tecnologia, desejam ter preocupação com este tipo de detalhe. Por outro lado, o DVD-9 oferece 8,5 GB em uma única face de disco. Isto é possível ao fundirem-se dois discos cujas faces se encontram voltadas para o mesmo lado. O processo, que é extremamente difícil de ser produzido e requer que uma camada (ou "layer") semi-reflexiva seja fundida à outra camada reflexiva. Desta forma, o laser do leitor ótico realiza primeiro a leitura da camada mais externa do disco e, então, atravessa o material fundido chegando até os dados impressos na camada mais interna. Como observado na figura 1, para que seja lida a informação da camada #1, é necessário interpretar o laser que percorreu o trajeto ("a", "d"), enquanto que a informação da camada #2 vem do feixe laser que atravessou a camada #1, ou seja, que percorreu ("a", "b", "c", "d"). Aparentemente, parece estranho que se possa recuperar as duas informações das duas camadas, que não são correlacionadas, ao mesmo tempo. Contudo, a geometria dos discos é constituída por um processo tal que permita a implementação de detetores em quadratura, graças à diferença de fase estrategicamente calculada introduzida pelo espaçamento entre as camadas. Figura 1: Esquema de camadas nos discos DVD. As vantagens do DVD-9 possuem um preço. Somente alguns replicadores de disco podem produzir discos em tempo adequado e a um custo razoável. O custo de produção de um DVD-9 é cerca de US$1 à US$1,50, maior que o custo de um DVD-5. Além disto, soma-se o valor do elevado custo de edição das duas camadas, que é o fato preponderante para o sincronismo na leitura dos dados. Quando o DVD foi apresentado ao mercado, uma grande família de discos foi definida, abrangendo desde o DVD-5 até o DVD-18, cada um oferecendo um acréscimo significativo na capacidade de armazenamento e no número de camadas no disco. Para uma comparação entre os diversos formatos veja a tabela da Figura 2. A Warner Advanced Media Operations (WAMO) já está testando o processo de produção de DVD-14/18. De fato, a WAMO é o primeiro fabricante a anunciar a produção de DVD-18, o DVD de dupla face e dupla camada, que culminará nos 17GB de capacidade de armazenamento, prometidos para o final de ano. Ela também pretende oferecer o DVD-14, um híbrido entre o DVD-9 e o DVD-5. Tipo face/no. camadas Capacidade (GB) Capacidade (CDs) DVD-5 simples / 1 4,7 7 DVD-9 simples / 2 8,5 13 DVD-10 dupla / 1 9,4 14 DVD-14 dupla / 1 (numa face) e 2 (na outra) 13,2 20 DVD-18 dupla / 2 17 26 Figura 2: Padrões de discos DVD comerciais. O DVD permite que o áudio digital seja gravado a uma taxa de amostragem de até 96 kHz, com resolução de 24 bits, valores estes exageradamente superiores aos 44,1 kHz e aos 16 bits do CD. Essa qualidade antes era somente atingida nos modernos estúdios de gravação digital. Além disso, o áudio pode ser gravado no padrão AC-3 que, em vez de dois canais (direito e esquerdo), reserva seis canais: esquerdo frontal, direito frontal, esquerdo traseiro, direito traseiro, central e um canal exclusivo para "subwoofers" (sons extremamente graves). Este padrão foi desenvolvido para atender a filmes e a transmissões de áudio da HDTV (televisão de alta resolução). Para vídeo, o DVD apresenta diversas opções muito interessantes: oito opções de dublagem, 32 opções de legenda e 5 opções de formato de tela; tudo isto com um detalhe: utilizando áudio AC-3. A resolução do DVD é de 500 linhas, o dobro da resolução do vídeo-cassete tradicional. É importante lembrar que o DVD é um sistema digital de acesso aleatório, ao contrário do vídeo-cassete, que é um sistema analógico de acesso sequencial. Na prática, não é só o fato de a qualidade de áudio e vídeo serem muito superiores, já que a procura por um determinado trecho de filme é quase instantânea, não existindo a necessidade de "rebobinar o filme". Além disso, o DVD não gasta com o tempo e a qualidade da reprodução não é afetada com o uso. O DVD-5 foi originalmente desenvolvido para armazenar filmes de 135 minutos. Utilizando a compressão MPEG-2, uma imagem em movimento requer 3500 Kbps. Já o áudio, gravado no padrão AC-3, requer mais 384 Kbps. Conforme a WAMO, o valor superdimensionado para as faixas adicionais de legenda e para a dublagem em diferentes idiomas é de aproximadamente 807 Kbps. Consolidando estes valores, constatamos que são necessários 4,75 GB. Mas, como é possível que um disco com as mesmas dimensões das de um CD tenha 7 vezes a capacidade de um CD ? Basicamente, tornando os elementos de dados menores. O espaçamento entre as trilhas (em espiral) reduziu de 1,6 mícrons para 0,74 mícrons. Já o menor tamanho do dado que pode ser impresso na superfície do disco reduziu de 0,83 para 0,40 mícrons. O comprimento de onda (780 nanometros) do laser de leitores de CD ainda era grande para ler estas trilhas. Assim, os leitores de DVD utilizam um laser que produz um feixe luminoso com comprimento de onda de 640 nanometros. Esta configuração de comprimento de onda exige que a camada plástica protetora do disco seja mais fina, de tal forma que o laser não precise atravessar um meio tão espesso para chegar ao layer de dados. Por esse motivo, o disco de DVD teria apenas metade dos 1,2 mm de espessura do CD. No caso do DVD-5, um outro disco de 0,6 mm é colado ao DVD para manter a mesma espessura original do CD. Entretanto, apesar dos 4,7 GB fornecerem uma enorme capacidade de armazenamento, por que não aumentar ainda mais este valor ? Por exemplo, ao invés de colar um disco vazio ao DVD, pode-se colar um outro disco de dados ao DVD, mantendo a mesma espessura do CD e dobrando a capacidade de armazenamento do DVD-5. Alguns filmes em DVD já se aproveitam desta vantagem, colocando uma versão de um filme formatado para uma TV normal ou mesmo um monitor de computador, em um lado, e, no outro, uma versão formatada para as telas mais largas como no padrão dos cinemas. A indústria cinematográfica dividiu o mundo em um conjunto de seis regiões geográficas. A razão para esta divisão é permitir o controle do lançamento de filmes e home-vídeos em diferentes partes do mundo em diferentes épocas. Um filme, por exemplo, pode ser lançado na Europa e depois nos Estados Unidos, coincidindo com o lançamento do home-vídeo no Estados Unidos. Nessa situação, teme-se que cópias de discos DVD atinjam o mercado europeu prejudicando a arrecadação das bilheterias. Desta forma, é dado ao leitor de DVD um código de região na qual ele foi vendido. O aparelho não disponibilizará o conteúdo dos discos em regiões nas quais ele não é autorizado. Os discos comprados em uma certa região, como por exemplo o Japão, podem não funcionar em leitores comprados por exemplo no Brasil. Uma outra subdivisão de áreas também ocorre devido aos diferentes padrões de vídeo adotados por cada país. Por exemplo, o Japão está situado na região 2 mas usa o padrão NTSC que é compatível com os Estados Unidos (região 1). A Europa, por sua vez, também está situada na região 2 mas utiliza o padrão PAL, que não é compatível com o NTSC. A opção por incluir ou não um código de região a um disco DVD pertence ao estúdio ou ao distribuidor dos títulos. Entretanto, se seu disco não possuir código, então ele poderá ser reproduzido em qualquer parte do mundo. Alguns discos têm sido lançados sem código, mas, até o momento, nenhum destes lançamentos pertencem aos grandes estúdios. Muitos destes grandes estúdios pretendem laçar cópias sem código, contanto que não haja conflito entre este lançamento e a arrecadação das bilheterias. As 6 regiões citadas são compostas por: 1. Canadá e Estados Unidos 2. Japão, Europa, África do Sul, Oriente Médio (incluindo Egito) 3. Sudeste e Leste da Ásia (incluindo Hong Kong) 4. Austrália, Nova Zelândia, Ilhas do Pacífico, América Central, América do Sul, Caribe 5. Antiga União Soviética, Índia, África, Coreia do Norte e Mongólia 6. China Alguns leitores são fabricados para que possam ser facilmente modificados pelos consumidores para reproduzirem vídeos com quaisquer códigos. Existe também um mercado negro bastante ativo que fornece leitores com modificações nos circuitos eletrônicos que despistam os códigos de regiões. Os sistemas de DVD-ROM aplicam o código de região somente aos discos de vídeo em DVD e não para os discos contendo software. Muitos dos leitores de DVD-ROM de computadores permitem mudar através de software o código da região, até que, após sucessivas trocas, este se torne permanente. Também neste caso, já existe um mercado negro de softwares que manipulam estes códigos. Para encerrar, existem as denominações DVD-R, DVD-RAM, DVD+RW e DIVX, explicadas na Figura 3. DVD-R Disco DVD que pode ser gravado por uma única vez DVD-RAM Primeira especificação para um disco de DVD que pode ser regravável (capacidade de 2,6 GB por lado) DVD+RW Especificação de disco DVD regravável feita pela Sony, HP e Phillips (capacidade de 3 GB por lado) DIVX Disco DVD com o atributo "per-per-view". O drive para este disco inclui um modem que se comunica com uma central de cobrança. Figura 3: Denominações de discos DVD.
O tempo em que se especulava sobre o sucesso do DVD já passou. Tendo provado seu valor como uma mídia de alta qualidade para a distribuição de vídeo e multimídia, o DVD agora avança sobre o mercado de alta capacidade de armazenamento, com técnicas inovadoras na gravação bem como na tecnologia de regravação. No início, o foco de interesse da indústria estava voltado às aplicações de vídeo. O sucesso do lançamento de vídeos em discos com 4.7 GB de capacidade foi prematuramente antecipado, sendo a qualidade do mesmo comparada com os discos laser e com a transmissão de televisão. Entretanto, de forma análoga ao que ocorre com toda nova tecnologia, vários foram os obstáculos pelos quais o DVD teve de passar até amadurecer e ganhar o espaço de mercado que hoje tem. Os primeiros DVD-5 produzidos foram testados em vários modelos de equipamentos, de diferentes fabricantes, e apresentaram alguns problemas relacionados com a qualidade de vídeo bem como com os leitores das mídias. Isto foi decisivo para que o processo de fabricação dos discos fosse melhorado de forma que se obtivesse uma maior qualidade a um menor custo. Ao mesmo tempo, os fabricantes de equipamentos delineavam os padrões de compatibilidade para os equipamentos. à medida que as melhorias eram implementadas, a expectativa de utilizarem-se CDs para armazenamento de informação de vídeo foi perdendo a força e o DVD começou a tornar-se um outro padrão de armazenamento, cujas versões estão mostradas na Figura 2. Com o crescente aumento de demanda, não demorou muito tempo para que os 4,7 GB não fossem suficientes para atender às aplicações multimídia. Mas o DVD Fórum, segmento da indústria responsável pela normatização, já havia previsto uma padronização para a família de produtos DVD: DVD-9 e DVD-10. Com 9,4 GB de capacidade de armazenamento, o DVD-10, que na prática corresponde a nada mais que dois DVD-5 fundidos, tornou-se a solução mais simples. Com a produção do DVD-5 já refinada, o processo de fusão usado para colocar dois discos unidos face à face não necessitou de considerações especiais. Entretanto, sob o ponto de vista da distribuição em massa, o DVD-10 é problemático. O disco não oferece qualquer face para que sejam colocadas identificações ou mesmo estampas decorativas. Além disto, a maioria dos leitores de DVDs dos consumidores contém somente uma cabeça de leitura ótica, o que os obriga a tirarem o disco do leitor e virarem a face de leitura. Esta deficiência compromete seriamente o produto pois nenhum usuário de títulos em DVD, consumidores vorazes de tecnologia, desejam ter preocupação com este tipo de detalhe. Por outro lado, o DVD-9 oferece 8,5 GB em uma única face de disco. Isto é possível ao fundirem-se dois discos cujas faces se encontram voltadas para o mesmo lado. O processo, que é extremamente difícil de ser produzido e requer que uma camada (ou "layer") semi-reflexiva seja fundida à outra camada reflexiva. Desta forma, o laser do leitor ótico realiza primeiro a leitura da camada mais externa do disco e, então, atravessa o material fundido chegando até os dados impressos na camada mais interna. Como observado na figura 1, para que seja lida a informação da camada #1, é necessário interpretar o laser que percorreu o trajeto ("a", "d"), enquanto que a informação da camada #2 vem do feixe laser que atravessou a camada #1, ou seja, que percorreu ("a", "b", "c", "d"). Aparentemente, parece estranho que se possa recuperar as duas informações das duas camadas, que não são correlacionadas, ao mesmo tempo. Contudo, a geometria dos discos é constituída por um processo tal que permita a implementação de detetores em quadratura, graças à diferença de fase estrategicamente calculada introduzida pelo espaçamento entre as camadas. Figura 1: Esquema de camadas nos discos DVD. As vantagens do DVD-9 possuem um preço. Somente alguns replicadores de disco podem produzir discos em tempo adequado e a um custo razoável. O custo de produção de um DVD-9 é cerca de US$1 à US$1,50, maior que o custo de um DVD-5. Além disto, soma-se o valor do elevado custo de edição das duas camadas, que é o fato preponderante para o sincronismo na leitura dos dados. Quando o DVD foi apresentado ao mercado, uma grande família de discos foi definida, abrangendo desde o DVD-5 até o DVD-18, cada um oferecendo um acréscimo significativo na capacidade de armazenamento e no número de camadas no disco. Para uma comparação entre os diversos formatos veja a tabela da Figura 2. A Warner Advanced Media Operations (WAMO) já está testando o processo de produção de DVD-14/18. De fato, a WAMO é o primeiro fabricante a anunciar a produção de DVD-18, o DVD de dupla face e dupla camada, que culminará nos 17GB de capacidade de armazenamento, prometidos para o final de ano. Ela também pretende oferecer o DVD-14, um híbrido entre o DVD-9 e o DVD-5. Tipo face/no. camadas Capacidade (GB) Capacidade (CDs) DVD-5 simples / 1 4,7 7 DVD-9 simples / 2 8,5 13 DVD-10 dupla / 1 9,4 14 DVD-14 dupla / 1 (numa face) e 2 (na outra) 13,2 20 DVD-18 dupla / 2 17 26 Figura 2: Padrões de discos DVD comerciais. O DVD permite que o áudio digital seja gravado a uma taxa de amostragem de até 96 kHz, com resolução de 24 bits, valores estes exageradamente superiores aos 44,1 kHz e aos 16 bits do CD. Essa qualidade antes era somente atingida nos modernos estúdios de gravação digital. Além disso, o áudio pode ser gravado no padrão AC-3 que, em vez de dois canais (direito e esquerdo), reserva seis canais: esquerdo frontal, direito frontal, esquerdo traseiro, direito traseiro, central e um canal exclusivo para "subwoofers" (sons extremamente graves). Este padrão foi desenvolvido para atender a filmes e a transmissões de áudio da HDTV (televisão de alta resolução). Para vídeo, o DVD apresenta diversas opções muito interessantes: oito opções de dublagem, 32 opções de legenda e 5 opções de formato de tela; tudo isto com um detalhe: utilizando áudio AC-3. A resolução do DVD é de 500 linhas, o dobro da resolução do vídeo-cassete tradicional. É importante lembrar que o DVD é um sistema digital de acesso aleatório, ao contrário do vídeo-cassete, que é um sistema analógico de acesso sequencial. Na prática, não é só o fato de a qualidade de áudio e vídeo serem muito superiores, já que a procura por um determinado trecho de filme é quase instantânea, não existindo a necessidade de "rebobinar o filme". Além disso, o DVD não gasta com o tempo e a qualidade da reprodução não é afetada com o uso. O DVD-5 foi originalmente desenvolvido para armazenar filmes de 135 minutos. Utilizando a compressão MPEG-2, uma imagem em movimento requer 3500 Kbps. Já o áudio, gravado no padrão AC-3, requer mais 384 Kbps. Conforme a WAMO, o valor superdimensionado para as faixas adicionais de legenda e para a dublagem em diferentes idiomas é de aproximadamente 807 Kbps. Consolidando estes valores, constatamos que são necessários 4,75 GB. Mas, como é possível que um disco com as mesmas dimensões das de um CD tenha 7 vezes a capacidade de um CD ? Basicamente, tornando os elementos de dados menores. O espaçamento entre as trilhas (em espiral) reduziu de 1,6 mícrons para 0,74 mícrons. Já o menor tamanho do dado que pode ser impresso na superfície do disco reduziu de 0,83 para 0,40 mícrons. O comprimento de onda (780 nanometros) do laser de leitores de CD ainda era grande para ler estas trilhas. Assim, os leitores de DVD utilizam um laser que produz um feixe luminoso com comprimento de onda de 640 nanometros. Esta configuração de comprimento de onda exige que a camada plástica protetora do disco seja mais fina, de tal forma que o laser não precise atravessar um meio tão espesso para chegar ao layer de dados. Por esse motivo, o disco de DVD teria apenas metade dos 1,2 mm de espessura do CD. No caso do DVD-5, um outro disco de 0,6 mm é colado ao DVD para manter a mesma espessura original do CD. Entretanto, apesar dos 4,7 GB fornecerem uma enorme capacidade de armazenamento, por que não aumentar ainda mais este valor ? Por exemplo, ao invés de colar um disco vazio ao DVD, pode-se colar um outro disco de dados ao DVD, mantendo a mesma espessura do CD e dobrando a capacidade de armazenamento do DVD-5. Alguns filmes em DVD já se aproveitam desta vantagem, colocando uma versão de um filme formatado para uma TV normal ou mesmo um monitor de computador, em um lado, e, no outro, uma versão formatada para as telas mais largas como no padrão dos cinemas. A indústria cinematográfica dividiu o mundo em um conjunto de seis regiões geográficas. A razão para esta divisão é permitir o controle do lançamento de filmes e home-vídeos em diferentes partes do mundo em diferentes épocas. Um filme, por exemplo, pode ser lançado na Europa e depois nos Estados Unidos, coincidindo com o lançamento do home-vídeo no Estados Unidos. Nessa situação, teme-se que cópias de discos DVD atinjam o mercado europeu prejudicando a arrecadação das bilheterias. Desta forma, é dado ao leitor de DVD um código de região na qual ele foi vendido. O aparelho não disponibilizará o conteúdo dos discos em regiões nas quais ele não é autorizado. Os discos comprados em uma certa região, como por exemplo o Japão, podem não funcionar em leitores comprados por exemplo no Brasil. Uma outra subdivisão de áreas também ocorre devido aos diferentes padrões de vídeo adotados por cada país. Por exemplo, o Japão está situado na região 2 mas usa o padrão NTSC que é compatível com os Estados Unidos (região 1). A Europa, por sua vez, também está situada na região 2 mas utiliza o padrão PAL, que não é compatível com o NTSC. A opção por incluir ou não um código de região a um disco DVD pertence ao estúdio ou ao distribuidor dos títulos. Entretanto, se seu disco não possuir código, então ele poderá ser reproduzido em qualquer parte do mundo. Alguns discos têm sido lançados sem código, mas, até o momento, nenhum destes lançamentos pertencem aos grandes estúdios. Muitos destes grandes estúdios pretendem laçar cópias sem código, contanto que não haja conflito entre este lançamento e a arrecadação das bilheterias. As 6 regiões citadas são compostas por: 1. Canadá e Estados Unidos 2. Japão, Europa, África do Sul, Oriente Médio (incluindo Egito) 3. Sudeste e Leste da Ásia (incluindo Hong Kong) 4. Austrália, Nova Zelândia, Ilhas do Pacífico, América Central, América do Sul, Caribe 5. Antiga União Soviética, Índia, África, Coreia do Norte e Mongólia 6. China Alguns leitores são fabricados para que possam ser facilmente modificados pelos consumidores para reproduzirem vídeos com quaisquer códigos. Existe também um mercado negro bastante ativo que fornece leitores com modificações nos circuitos eletrônicos que despistam os códigos de regiões. Os sistemas de DVD-ROM aplicam o código de região somente aos discos de vídeo em DVD e não para os discos contendo software. Muitos dos leitores de DVD-ROM de computadores permitem mudar através de software o código da região, até que, após sucessivas trocas, este se torne permanente. Também neste caso, já existe um mercado negro de softwares que manipulam estes códigos. Para encerrar, existem as denominações DVD-R, DVD-RAM, DVD+RW e DIVX, explicadas na Figura 3. DVD-R Disco DVD que pode ser gravado por uma única vez DVD-RAM Primeira especificação para um disco de DVD que pode ser regravável (capacidade de 2,6 GB por lado) DVD+RW Especificação de disco DVD regravável feita pela Sony, HP e Phillips (capacidade de 3 GB por lado) DIVX Disco DVD com o atributo "per-per-view". O drive para este disco inclui um modem que se comunica com uma central de cobrança. Figura 3: Denominações de discos DVD. -
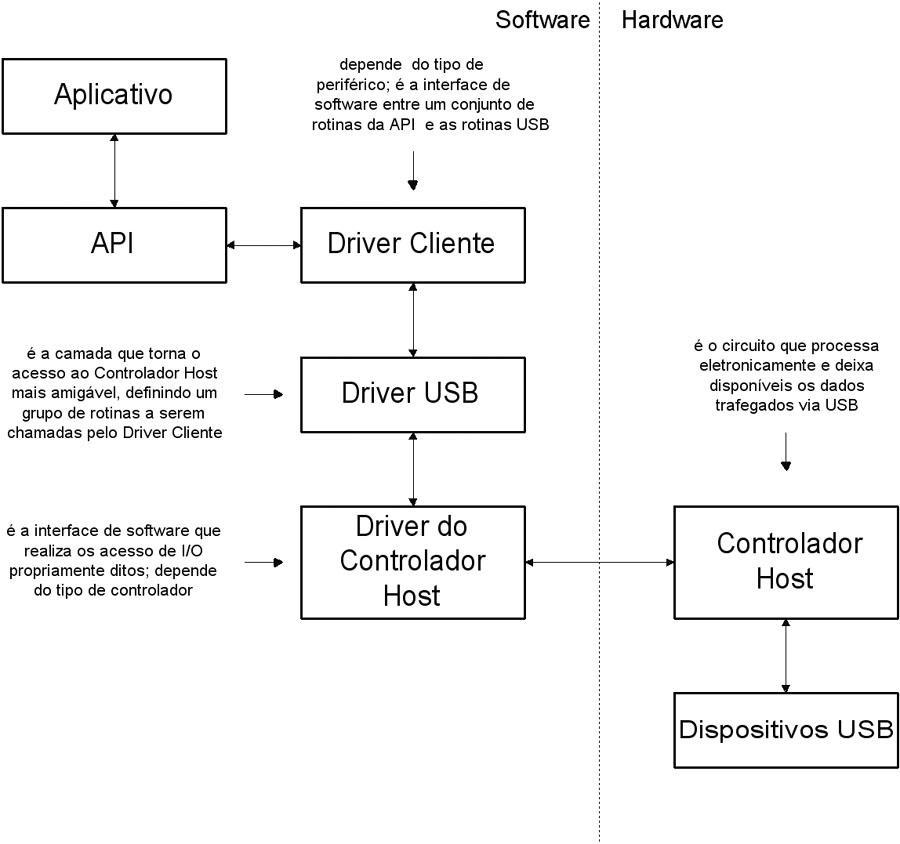 Na primeira parte, faremos uma breve introdução deste barramento, além dos procedimentos de software (a nível de sistema operacional, device-driver e aplicativo) que são realizados durante os processo de instalação e operação de um dispositivo USB. Numa segunda parte, estudar-se-ão as estruturas elétricas associadas ao novo padrão. O barramento serial universal, especificado pelas empresas líderes no mercado de computadores pessoais (Compaq, DEC, IBM, Intel, Microsoft, NEC e outras), permite uma expansão externa do PC praticamente ilimitada. Com o USB, os usuários aproveitam os benefícios da arquitetura plug-and-play, ou seja, não necessitam mais de efetuar configurações de recursos de hardware, como nos quebra-cabeças dos "dip-switches" e "jumpers", para a definição de IRQ’s, canais de DMA ou endereços de I/O. O USB utiliza um conector universal que permite ao usuário instalar e remover periféricos sem sequer abrir o computador. E ainda, com a característica de inserção e remoção automáticas, os periféricos podem ser instalados e removidos a qualquer momento, mesmo com o computador ligado e inicializado. Além da facilidade de utilização de periféricos convencionais, o USB abre caminho para novos aplicações, como a integração PC/telefonia e jogos multiusuários. Dois importantes atributos do USB são também destacados: a compatibilidade universal, pois nada impede que o USB seja aproveitado por outra arquitetura, e a simplicidade no projeto de periféricos, pois são eliminados diversos custos, como o de interfaces auxiliares (ex: alguns scanners e CD ROM precisam de uma interface SCSI). O USB pode ser usado com a maioria dos periféricos de PC’s, tais como: controladoras de vídeo, drives de CD ROM, joysticks, unidades de fita, drives de disco-flexível externos, scanners ou impressoras. A taxa de transmissão especificada de 12 Megabits/s também acomoda uma nova geração de periféricos, incluindo os produtos baseados em vídeo (ex: câmeras digitais). Quanto à organização das camadas de software necessárias para operar-se um dispositivo, o sistema USB HOST é composto por vários níveis de hardware e programas, conforme mostrado na Figura 1. Figura 1: Camadas de software necessárias para operarem-se dados via USB. Conforme a Figura 1 indica, um aplicativo requer o acesso a um periférico USB da forma padrão, como é feita para os periféricos comuns: chama funções da API. Num segundo estágio, a API chama rotinas do driver Cliente do periférico USB instalado. Este driver traduz os comandos da API para comandos USB. O driver Cliente é geralmente parte do sistema operacional ou vem instalável com o dispositivo USB. A terceira camada de software indicada é o driver USB (USBD), que é aquela que dá ao sistema operacional o suporte ao USB. A quarta camada de interesse é o driver do controlador HOST (HCD), que funciona a nível de Kernel do sistema operacional. O HCD provê o nível de software entre o hardware do controlador HOST e o USBD. É esta camada que realiza os acessos de I/O necessários para a operação do dispositivo USB. O HCD interpreta as chamadas do USBD e constrói uma lista de estruturas, um descritor de transferências, uma fila principal e um buffer de dados para o controlador HOST. A Figura 1 apresenta também duas camadas de hardware. A primeira delas é o Controlador HOST (HC), que é o circuito onde serão feitas as conexões de todos os dispositivos USB. Tal circuito executa eletronicamente os comandos programadas pelo HCD, além de registrar o estado das transações do USB. Sua operação é gerenciada pelo HCD. A segunda delas é constituída pelo conjunto de Dispositivos USB conectados, que são os periféricos que usam esse tipo de barramento. Uma característica extremamente inovadora do USB é a possibilidade de conectar-se um novo dispositivo durante a execução do aplicativo. Neste caso, o controlador HOST detecta a conexão e envia uma mensagem ao HCD para avisá-lo do fato. Em seguida, o HCD faz a mesma notificação ao driver USB (USBD). Este, então, inicializa o driver cliente do periférico conectado e, em seguida, torna-o operacional, de forma que o aplicativo já possa dispor de seus recursos. Tal seqüência está ilustrada na Figura 2. Figura 2: Seqüência de eventos desde a conexão da placa até a inicialização dos drivers. O USB é mais do que uma conexão Plug-and-Play. Esta nova tecnologia permite usar o PC em novos e interessantes caminhos. Seguem-se alguns exemplos de benefícios especiais que o USB pode proporcionar. Em Jogos Apesar de já existirem jogos onde é possível, via conexão de rede, que várias pessoas participem, o USB tem a interessante característica de permitir a entrada de novos jogadores sem que se interrompa a partida. Isto porque o USB permite conectar e desconectar joysticks e outros dispositivos de entrada sem que ocorra uma ação de parada. Lembrar que isto ocorre num único computador. Não há o ambiente de rede envolvido. Outro benefício associado a jogos é a possibilidade de sentir-se a massa de objetos virtuais e ter-se noção de aceleração em veículos. No fundo, é também um grande passo para simulações realísticas em robótica, devido à grande capacidade de fluxo de dados nos dois sentidos do cabo USB, que mantém um computador apto a receber as últimas novidades tecnológicas em termos de periféricos. Conexões na Internet O USB fornece a alternativa de utilizarem-se modem's externos de grande velocidade ou mesmo terminais de rede. Com isto, o acesso a Internet pode ser realizado sem a utilização de placas de rede. Fica também bastante flexível a topologia de um projeto de rede local, pois a substituição de nós (troca de computadores conectados) pode ser realizada com a simples troca do cabo, sem que se precise reinicializar qualquer computador. Compartilhamento Um dos mais importantes benefícios trazidos pelo USB é que ele permite o compartilhamento de periféricos entre PC’s, como dispositivos de segurança, telefones, monitores e outros. Telefonia e VIA PC A conexão via USB é imediata e flexível entre telefones e PC’s, especialmente com as novas aplicações que transformaram um simples computador numa sofisticada central de chamadas. Selecionar chamadas, adaptar as mensagens a serem enviadas, salvar e recuperar mensagens em voz ou fax e muitas outras ações podem ser controladas diretamente do PC através de aplicativos. A maioria dos computadores USB compatíveis apresenta pelo menos um um par de portas USB. Deve-se verificar a presença dos conectores. Outra maneira de saber se o sistema é compatível com o USB é analisar a característica do processador Pentium com tecnologia MMX ou Pentium II. Os PC’s vendidos em 1997 com esses processadores têm o hardware necessário instalado. Para trabalhar com o USB, é preciso ter um sistema operacional compatível. A maioria dos computadores vendidos em 1997 já têm essa característica. Caso se esteja utilizando uma versão do Windows incompatível, pode-se carregar um utilitário do USB através do site http://www.teleport.com/~usb Para verificar se o periférico comprado possui interface USB, verificar se o cabo de conexão tem forma semelhante à da Figura 3. Figura 3: Plug USB. A tecnologia USB reúne qualidades que tornam o PC mais flexível e capaz de explorar ainda mais suas potencialidades em termos de aplicação prática . O que antes limitava o PC a uns poucos periféricos, hoje o lança num ambiente de grande multiplicidade sem grandes complicações tecnológicas, facilitando a vida dos usuários. Na segunda parte, serão estudadas de forma bastante técnica as estruturas elétricas da especificação USB. Para saber mais: Ler parte 2 Artigo sobre USB Livro USB System Architecture, de Don Anderson
Na primeira parte, faremos uma breve introdução deste barramento, além dos procedimentos de software (a nível de sistema operacional, device-driver e aplicativo) que são realizados durante os processo de instalação e operação de um dispositivo USB. Numa segunda parte, estudar-se-ão as estruturas elétricas associadas ao novo padrão. O barramento serial universal, especificado pelas empresas líderes no mercado de computadores pessoais (Compaq, DEC, IBM, Intel, Microsoft, NEC e outras), permite uma expansão externa do PC praticamente ilimitada. Com o USB, os usuários aproveitam os benefícios da arquitetura plug-and-play, ou seja, não necessitam mais de efetuar configurações de recursos de hardware, como nos quebra-cabeças dos "dip-switches" e "jumpers", para a definição de IRQ’s, canais de DMA ou endereços de I/O. O USB utiliza um conector universal que permite ao usuário instalar e remover periféricos sem sequer abrir o computador. E ainda, com a característica de inserção e remoção automáticas, os periféricos podem ser instalados e removidos a qualquer momento, mesmo com o computador ligado e inicializado. Além da facilidade de utilização de periféricos convencionais, o USB abre caminho para novos aplicações, como a integração PC/telefonia e jogos multiusuários. Dois importantes atributos do USB são também destacados: a compatibilidade universal, pois nada impede que o USB seja aproveitado por outra arquitetura, e a simplicidade no projeto de periféricos, pois são eliminados diversos custos, como o de interfaces auxiliares (ex: alguns scanners e CD ROM precisam de uma interface SCSI). O USB pode ser usado com a maioria dos periféricos de PC’s, tais como: controladoras de vídeo, drives de CD ROM, joysticks, unidades de fita, drives de disco-flexível externos, scanners ou impressoras. A taxa de transmissão especificada de 12 Megabits/s também acomoda uma nova geração de periféricos, incluindo os produtos baseados em vídeo (ex: câmeras digitais). Quanto à organização das camadas de software necessárias para operar-se um dispositivo, o sistema USB HOST é composto por vários níveis de hardware e programas, conforme mostrado na Figura 1. Figura 1: Camadas de software necessárias para operarem-se dados via USB. Conforme a Figura 1 indica, um aplicativo requer o acesso a um periférico USB da forma padrão, como é feita para os periféricos comuns: chama funções da API. Num segundo estágio, a API chama rotinas do driver Cliente do periférico USB instalado. Este driver traduz os comandos da API para comandos USB. O driver Cliente é geralmente parte do sistema operacional ou vem instalável com o dispositivo USB. A terceira camada de software indicada é o driver USB (USBD), que é aquela que dá ao sistema operacional o suporte ao USB. A quarta camada de interesse é o driver do controlador HOST (HCD), que funciona a nível de Kernel do sistema operacional. O HCD provê o nível de software entre o hardware do controlador HOST e o USBD. É esta camada que realiza os acessos de I/O necessários para a operação do dispositivo USB. O HCD interpreta as chamadas do USBD e constrói uma lista de estruturas, um descritor de transferências, uma fila principal e um buffer de dados para o controlador HOST. A Figura 1 apresenta também duas camadas de hardware. A primeira delas é o Controlador HOST (HC), que é o circuito onde serão feitas as conexões de todos os dispositivos USB. Tal circuito executa eletronicamente os comandos programadas pelo HCD, além de registrar o estado das transações do USB. Sua operação é gerenciada pelo HCD. A segunda delas é constituída pelo conjunto de Dispositivos USB conectados, que são os periféricos que usam esse tipo de barramento. Uma característica extremamente inovadora do USB é a possibilidade de conectar-se um novo dispositivo durante a execução do aplicativo. Neste caso, o controlador HOST detecta a conexão e envia uma mensagem ao HCD para avisá-lo do fato. Em seguida, o HCD faz a mesma notificação ao driver USB (USBD). Este, então, inicializa o driver cliente do periférico conectado e, em seguida, torna-o operacional, de forma que o aplicativo já possa dispor de seus recursos. Tal seqüência está ilustrada na Figura 2. Figura 2: Seqüência de eventos desde a conexão da placa até a inicialização dos drivers. O USB é mais do que uma conexão Plug-and-Play. Esta nova tecnologia permite usar o PC em novos e interessantes caminhos. Seguem-se alguns exemplos de benefícios especiais que o USB pode proporcionar. Em Jogos Apesar de já existirem jogos onde é possível, via conexão de rede, que várias pessoas participem, o USB tem a interessante característica de permitir a entrada de novos jogadores sem que se interrompa a partida. Isto porque o USB permite conectar e desconectar joysticks e outros dispositivos de entrada sem que ocorra uma ação de parada. Lembrar que isto ocorre num único computador. Não há o ambiente de rede envolvido. Outro benefício associado a jogos é a possibilidade de sentir-se a massa de objetos virtuais e ter-se noção de aceleração em veículos. No fundo, é também um grande passo para simulações realísticas em robótica, devido à grande capacidade de fluxo de dados nos dois sentidos do cabo USB, que mantém um computador apto a receber as últimas novidades tecnológicas em termos de periféricos. Conexões na Internet O USB fornece a alternativa de utilizarem-se modem's externos de grande velocidade ou mesmo terminais de rede. Com isto, o acesso a Internet pode ser realizado sem a utilização de placas de rede. Fica também bastante flexível a topologia de um projeto de rede local, pois a substituição de nós (troca de computadores conectados) pode ser realizada com a simples troca do cabo, sem que se precise reinicializar qualquer computador. Compartilhamento Um dos mais importantes benefícios trazidos pelo USB é que ele permite o compartilhamento de periféricos entre PC’s, como dispositivos de segurança, telefones, monitores e outros. Telefonia e VIA PC A conexão via USB é imediata e flexível entre telefones e PC’s, especialmente com as novas aplicações que transformaram um simples computador numa sofisticada central de chamadas. Selecionar chamadas, adaptar as mensagens a serem enviadas, salvar e recuperar mensagens em voz ou fax e muitas outras ações podem ser controladas diretamente do PC através de aplicativos. A maioria dos computadores USB compatíveis apresenta pelo menos um um par de portas USB. Deve-se verificar a presença dos conectores. Outra maneira de saber se o sistema é compatível com o USB é analisar a característica do processador Pentium com tecnologia MMX ou Pentium II. Os PC’s vendidos em 1997 com esses processadores têm o hardware necessário instalado. Para trabalhar com o USB, é preciso ter um sistema operacional compatível. A maioria dos computadores vendidos em 1997 já têm essa característica. Caso se esteja utilizando uma versão do Windows incompatível, pode-se carregar um utilitário do USB através do site http://www.teleport.com/~usb Para verificar se o periférico comprado possui interface USB, verificar se o cabo de conexão tem forma semelhante à da Figura 3. Figura 3: Plug USB. A tecnologia USB reúne qualidades que tornam o PC mais flexível e capaz de explorar ainda mais suas potencialidades em termos de aplicação prática . O que antes limitava o PC a uns poucos periféricos, hoje o lança num ambiente de grande multiplicidade sem grandes complicações tecnológicas, facilitando a vida dos usuários. Na segunda parte, serão estudadas de forma bastante técnica as estruturas elétricas da especificação USB. Para saber mais: Ler parte 2 Artigo sobre USB Livro USB System Architecture, de Don Anderson -
 Nota: O Merced foi lançado com o nome comercial "Itanium", voltado a servidores de alto desempenho. Ao contrário do que afirma o artigo, não era o sucessor do Pentium II. Será que não é muito cedo para se falar do sucessor do Pentium II? Afinal, ele foi lançado há apenas 1 ano. A resposta é não, pois o projeto do sucessor do Pentium II já está bastante adiantado e recebeu o nome de Merced. O ponto mais interessante desse projeto é que seu desempenho não será conseguido apenas com o aumento do barramento, cache e alguns megahertz no relógio. Esses recursos estão próximos do limite físico. Essa CPU caminha por terreno inédito e não muito sólido. Será usada uma arquitetura inovadora que vai além dos já consagrados RISC e CISC. Essa nova arquitetura, denominada LIW ("Large Instruction Word" ou Palavra de Instrução Grande), nunca foi provada comercialmente, existindo apenas sob a forma experimental em alguns centros de pesquisa. Ao analisarmos a evolução dos computadores pessoais, vemos duas épocas distintas: a década de 80 dominada pelas máquinas CISC, e a década de 90 pelas das máquinas RISC (incluímos ai as máquinas RISC mascaradas de CISC: Pentium Pro e o Pentium II). Já estamos no final dos anos 90! Como será a arquitetura que vai dominar a primeira década do segundo milênio? Desde 1994, Intel e HP vêm trabalhando no desenvolvimento de uma CPU que suplantasse as já quase esgotadas arquiteturas CISC e RISC. Essa nova CPU tomaria como base aquela técnica experimental, a LIW. O resultado foi radicalmente diferente de tudo que já foi tentado em escala comercial e deverá mudar a indústria de computadores. A nova máquina não é uma CPU puramente LIW, mas uma grande reunião de técnicas e otimizações que a Intel denominou IA-64 ("Intel Architecture-64") e que deverá chegar ao mercado na segunda metade de 1999. O microprocessador Merced terá perto de dez milhões de transistores (vide Figura 1) construídos com processo de 0,18 mícron (vide Figura 2) e a tensão de alimentação deverá ficar abaixo dos 2 Volts. O relógio ainda permanece uma incógnita, mas com certeza estará acima dos 300 MHz. Está prometida a compatibilidade com as instruções x86 e com as da arquitetura PA-RISC da HP. Vários fatores contribuirão para o desempenho: instruções LIW, execução em paralelo, eliminação dos desvios e carregamento especulativo. Porém, isso tudo só será possível com o uso de compiladores inteligentes. O Merced será o primeiro de uma família de processadores onde a complexidade de CPU foi trocada pela otimização durante a compilação. De forma mais direta: a CPU ficou mais simples porque boa parte do seu trabalho foi transferido para o compilador. Figura 1: Evolução da capacidade de integração. Figura 2: Diminuição da espessura das linhas usadas no processode integração, por ocasião do lançamento das CPU’s (1 mícron é igual à milésima parte do milímetro). As modernas CPU's utilizam várias unidades funcionais arrumadas em um enorme pipeline. Algumas dessas unidades operam em paralelo (ou seja, simultaneamente), executando até 4 instruções por ciclo de relógio. Quando uma CPU executa instruções de forma concorrente, ela é dita "superescalar". Nos microprocessadores superescalares, uma boa parte de sua lógica é usada para detectar o paralelismo intrínseco do programa em execução, de forma a iniciar operações concorrentes sempre que for possível. Ora, um compilador inteligente poderia ajudar bastante a CPU detectando o paralelismo do programa, arrumando as instruções de forma a facilitar a concorrência, organizando os dados e diminuindo a dependência entre eles. Poderia também dar dicas para a CPU sobre onde estão os desvios do programa e suas ramificações, antecipando o carregamento dos dados necessários ao processamento. É exatamente isso que se espera de um compilador para a família IA-64. Atualmente, as CPUs executam as instruções da forma como elas chegam, tentando fazer isso da maneira mais rápida possível. É interessante observar que as CPU's que têm capacidade de executar até 4 instruções por ciclo de relógio, na prática, ficam abaixo de 2 instruções por ciclo. Se as instruções chegassem já preparadas para serem executadas de forma concorrente, o desempenho com certeza seria melhor. Um compilador otimizado para a IA-64 deverá arrumar as instruções da melhor forma possível, evitando as dependências e inclusive indicando para o processador quais podem ser executadas em paralelo. As modernas CPU's com seu enorme pipeline sempre tropeçaram nos desvios. Nessas CPU's, enquanto uma instrução está sendo executada, as próximas já foram capturadas e estão sendo decodificadas e preparadas para execução. Aí surge um problema: se a instrução atual for um salto, todo o trabalho de busca e preparação das próximas instruções é perdido e o processamento precisa parar enquanto a instrução correta é lida da memória e percorre todo o pipeline. Nos programas atuais, em média ocorre um desvio a cada 6 instruções. Para minimizar esse problema, usa-se a predição de desvios. Quando surge um desvio condicional, a unidade que busca as próximas instruções tenta adivinhar se ele será efetivado ou não e inicia a busca das próximas instruções no endereço que foi julgado correto. Isso é chamado de execução especulativa. Mas a predição nem sempre acerta e o erro implica em grande perda de tempo. O compilador pode ajudar muito pois ele dispõe de mais tempo para analisar se um desvio será efetivado e pode dar uma dica para a CPU do que deverá acontecer. Na grande maioria das vezes o compilador prepara a CPU para executar de forma especulativa todos os ramos do desvio e depois descartar os resultados de que não necessitar. O pior veneno para microprocessadores com pipeline grande é o surgimento de instruções com dependências que obriguem a esvaziar o pipeline antes de iniciar a execução da instrução seguinte. Exagerando com a analogia, é como se uma agência bancária só permitisse a entrada de uma cliente quando o que está lá dentro saísse. Um compilador inteligente poderia arrumar os dados de forma a criar a menor dependência possível e esse trabalho seria muito facilitado se a CPU oferecesse uma grande quantidade de registradores. Isso facilitaria o planejamento para a execução em paralelo e diminuiria a necessidade de reutilização. Um outro galho para esse tipo de CPU é parar o processamento enquanto o dada necessário não chega. Isso foi minimizado com a utilização das memórias cache, mas ainda não está satisfatório. Ora, o compilador sabe os instantes em que haverá carregamento de dados e pode dar uma dica para a CPU, permitindo que esta antecipe a leitura do dado. A ideia é iniciar a carga do dado bem antes da CPU necessitar-lhe. Conta a história que as máquinas RISC ("Reduced Instruction Set Computer") surgiram quando os projetistas substituíram as instruções complexas por um conjuntos mais simples, mais veloz e de controle mais fácil. Com isso, o chip ficou menos sobrecarregado, sobrando mais área para ser usada em outras unidades funcionais. A história real é um pouco diferente! As máquinas RISC nasceram da necessidade de simplificar-se a CPU. A ideia foi trocar complexidade da CPU por otimização durante a compilação. Usou-se então um conjunto de instruções pequeno mas veloz, que pudesse ser executado em paralelo e ainda que fosse de fácil controle. Um grande conjunto de registradores substituiu os complexos modos de endereçamento. Com a simplificação da unidade de controle, uma maior área do CI pode ser empenhada diretamente no processamento. O trabalho de arrumar as instruções, de forma a espremer o máximo desempenho da CPU, foi transferido para o compilador. Em outras palavras, boa parte da complexidade da CPU foi transferida para o compilador. Assim o termo RISC não é muito feliz pois ele faz referência apenas ao conjunto de instruções e ignora o importante papel do compilador em gerar programas otimizados para essas máquinas. A família x86 começou com a CPU 8086, que é uma máquina CISC. Com a demanda por desempenho, os projetistas da Intel espremeram todo o desempenho passível de ser obtida com essa arquitetura. A evolução natural seria para uma arquitetura RISC, mas isso comprometeria seriamente a compatibilidade com o passado. A solução encontrada foi a de projetar uma máquina híbrida: uma casca CISC com um coração RISC. Assim são os Pentium Pro e Pentium II que traduzem as complexas instruções x86 em uma ou mais micro-operações que são executadas por uma máquina RISC. Essa micro-operações são de mais fácil controle e podem ser executadas em paralelo. Porém uma grande parte da CPU ainda é dedicada ao controle dessas instruções, à predição dos desvios e à tradução. As atuais CPUs possuem milhões de transistores, mas, desse total, apenas uma pequena parte é usada diretamente no processamento, pois a grande maioria é consumida no controle das instruções para possibilitar a execução fora de ordem e na predição dos desvios, ou seja, as atuais arquiteturas RISC/CISC estão complexas novamente e, por isso, é hora de aplicar o método: vamos simplificar a CPU e passar o trabalho de otimização para o compilador. Essa é a grande máxima da arquitetura IA-64, empregada no desenvolvimento da CPU Merced. A arquitetura IA-64 usa instruções de tamanho fixo (40 bits) e elas são executadas em um único período de relógio, ou seja, são semelhantes às instruções RISC: comprometidas com o desempenho. É interessante confrontar a simplicidade dessas instruções de tamanho fixo, com a complexidade da cansada arquitetura x86, cujas instruções têm tamanho variando entre 8 e 108 bits. Somente após decodificar uma instrução, a CPU descobre qual o seu tamanho (onde está sua fronteira). As instruções IA-64 são arrumadas em pacotes de 128 bits, cada pacote com 3 instruções, como está mostrado na Figura 3. Isso é o que se chama LIW, mas a Intel prefere usar o termo EPIC ("Explicitily Parallel Instruction Computing"), pois nesse pacote, além das três instruções, existem bits para indicar quais podem ser executadas em paralelo. A CPU não mais precisa ficar analisando (durante a execução) o fluxo de instruções tentando descobrir o paralelismo intrínseco do problema, pois ele é explicitado durante a compilação. Figura 3: Uma suposição para o empacotamento das instruções IA-64. Cada instrução tem o tamanho fixo de 40 bits. A seqüência das instruções é fornecida pelo compilador e não necessariamente coincide com a ordem original do programa. O campo de 8 bits, denominado "template", indica quais instruções desse pacote, e dos próximos, podem ser executadas em paralelo. Figura 4: Possível formato de uma instrução IA-64. As instruções IA-64, vide Figura 4, têm um tamanho de 40 bits e estão divididas em 5 campos, cada um com uma finalidade específica. O campo "Opcode" indica a operação a ser executada: soma, multiplicação, incremento, etc.. O campo "Predicate", com 6 bits, define uma das 64 possíveis predições usadas para resolver os problemas gerados pelos desvios. Os registradores com os dados a serem operados são indicados pelos campos GPR. Uma instrução pode manipular até três registradores. Cada campo GPR tem 7 bits e especifica um dos 128 registradores da CPU. Na verdade, existem 128 registradores para números inteiros e 128 registradores para números em representação com ponto-flutuante. Os campos GPR são específicos para cada instrução, ou seja, de acordo com a instrução, os campos GPR selecionam registradores inteiros ou registradores ponto-flutuante. Devemos comparar essa quantidade de registradores (256) com os oferecidos pela arquitetura x86: 8 registradores inteiros e uma pilha com 8 registradores ponto-flutuante. Os compiladores para as CPU’s IA-64 usarão uma técnica denominada "Predication", que permite eliminar os efeitos danosos provocados pelos desvios. Ao encontrar um desvio, diferente do que acontecia com os modelos anteriores, a CPU não precisa mais apostar um dos ramos. Ela simplesmente executa todos os desvios possíveis e depois descarta os resultados irrelevantes. Todos os desvios e suas ramificações são preditos pelo compilador. Assim, durante a execução, quando a CPU encontra um desvio já predito pelo compilador, ela começa a executar os códigos ao longo de todos os possíveis destinos. Quando o destino correto é decidido, a CPU armazena os resultados válidos e descarta os demais. É muito importante o papel do compilador. Quando este encontra um desvio, ele o analisa para ver se é um candidato para a predição. A grande maioria dos desvios o é. Caso positivo, marca com um "Predicate" diferente as instruções de cada ramo do desvio. Por exemplo, uma instrução do tipo "salte se a variável R for igual a zero" tem duas ramificações possíveis, como é mostrado na Figura 5 (I3). Figura 5: Ilustração da operação de predição dos desvios. As instruções pertencentes a um mesmo ramo têm o "predicate" igual. Existem disponíveis 64 "predicates" diferentes. Após marcar as instruções de cada ramo do desvio, o compilador verifica quais podem ser executadas em paralelo e depois empacota as instruções em palavras de 128 bits, de forma que o microprocessador as receba arrumadas da melhor forma possível. Durante a execução, a CPU despacha para execução em paralelo as instruções que não têm dependências e cuida para que as que apresentam dependências sejam executadas na ordem correta. O lado ruim desta técnica de predição é que a CPU sempre executa instruções cujos resultados serão descartados; porém, segundo especialistas, haverá um ganho em relação às arquiteturas atuais. Na verdade, o Merced, por ser mais simples, tem uma maior abundância de recursos e, por isso, pode desperdiçar um pouco do seu potencial executando instruções que se vão revelar desnecessárias. O carregamento especulativo permite a carga de um dado antes que o programa venha a necessitar-lhe. A ideia básica é separar o carregamento do dado do instante de sua utilização. O dado sempre estará disponível e, por isso, o processador não se detém esperando que a memória, ou o cache, seja lido. O compilador é o responsável por analisar o programa buscando operações que necessitam de dados que estão na memória. Sempre que possível, o compilador insere antecipadamente uma instrução de carregamento (bem antes do ponto onde o dado será necessário) e uma instrução de verificação imediatamente antes da instrução que usa o dado. Isso resulta que, muito antes do dado ser necessário, ele já está sendo buscado na memória. A verificação é importante porque o dado pode não mais ser válido e, além disso, é necessário checar as exceções. Por exemplo, um dado pode não mais ser válido porque a CPU executou um salto. Tudo isso é preparado pelo compilador visando a obter o máximo de paralelismo. Há realmente grandes novidades com a arquitetura IA-64 e o compilador vai desempenhar um papel importantíssimo, pois de sua inteligência dependerá o desempenho da CPU. As novas versões dessa CPU apresentarão compatibilidade, ou seja, um compilador antigo poderá rodar numa nova CPU, porém o desempenho máximo só será possível após esse compilador ser reprojetado para essa nova CPU. Tomando lições com os supercomputadores, já aprendeu-se que é muito mais fácil gerar códigos para execução em paralelo a partir de programas onde o paralelismo foi claramente expresso do que a partir de programas onde o programador construiu obscuros e entrelaçados loops. Assim, deverão surgir linguagens estendidas para o processamento paralelo (na verdade essas extensões já existem, mas não para a plataforma IA-64), onde, através de instruções especiais, o programador possa indicar ao compilador o paralelismo intrínseco do seu programa. A chegada do Merced ao mercado não deverá ser diferente do aconteceu com as outras CPU's: inicialmente ele será um chip grande e caro, mas, ao longo do tempo, deverá diminuir de tamanho e preço. No começo, apenas máquinas topo de linha farão uso desse microprocessador e, para a maioria dos usuários, o velho x86 ainda apresentará um desempenho bastante satisfatório.
Nota: O Merced foi lançado com o nome comercial "Itanium", voltado a servidores de alto desempenho. Ao contrário do que afirma o artigo, não era o sucessor do Pentium II. Será que não é muito cedo para se falar do sucessor do Pentium II? Afinal, ele foi lançado há apenas 1 ano. A resposta é não, pois o projeto do sucessor do Pentium II já está bastante adiantado e recebeu o nome de Merced. O ponto mais interessante desse projeto é que seu desempenho não será conseguido apenas com o aumento do barramento, cache e alguns megahertz no relógio. Esses recursos estão próximos do limite físico. Essa CPU caminha por terreno inédito e não muito sólido. Será usada uma arquitetura inovadora que vai além dos já consagrados RISC e CISC. Essa nova arquitetura, denominada LIW ("Large Instruction Word" ou Palavra de Instrução Grande), nunca foi provada comercialmente, existindo apenas sob a forma experimental em alguns centros de pesquisa. Ao analisarmos a evolução dos computadores pessoais, vemos duas épocas distintas: a década de 80 dominada pelas máquinas CISC, e a década de 90 pelas das máquinas RISC (incluímos ai as máquinas RISC mascaradas de CISC: Pentium Pro e o Pentium II). Já estamos no final dos anos 90! Como será a arquitetura que vai dominar a primeira década do segundo milênio? Desde 1994, Intel e HP vêm trabalhando no desenvolvimento de uma CPU que suplantasse as já quase esgotadas arquiteturas CISC e RISC. Essa nova CPU tomaria como base aquela técnica experimental, a LIW. O resultado foi radicalmente diferente de tudo que já foi tentado em escala comercial e deverá mudar a indústria de computadores. A nova máquina não é uma CPU puramente LIW, mas uma grande reunião de técnicas e otimizações que a Intel denominou IA-64 ("Intel Architecture-64") e que deverá chegar ao mercado na segunda metade de 1999. O microprocessador Merced terá perto de dez milhões de transistores (vide Figura 1) construídos com processo de 0,18 mícron (vide Figura 2) e a tensão de alimentação deverá ficar abaixo dos 2 Volts. O relógio ainda permanece uma incógnita, mas com certeza estará acima dos 300 MHz. Está prometida a compatibilidade com as instruções x86 e com as da arquitetura PA-RISC da HP. Vários fatores contribuirão para o desempenho: instruções LIW, execução em paralelo, eliminação dos desvios e carregamento especulativo. Porém, isso tudo só será possível com o uso de compiladores inteligentes. O Merced será o primeiro de uma família de processadores onde a complexidade de CPU foi trocada pela otimização durante a compilação. De forma mais direta: a CPU ficou mais simples porque boa parte do seu trabalho foi transferido para o compilador. Figura 1: Evolução da capacidade de integração. Figura 2: Diminuição da espessura das linhas usadas no processode integração, por ocasião do lançamento das CPU’s (1 mícron é igual à milésima parte do milímetro). As modernas CPU's utilizam várias unidades funcionais arrumadas em um enorme pipeline. Algumas dessas unidades operam em paralelo (ou seja, simultaneamente), executando até 4 instruções por ciclo de relógio. Quando uma CPU executa instruções de forma concorrente, ela é dita "superescalar". Nos microprocessadores superescalares, uma boa parte de sua lógica é usada para detectar o paralelismo intrínseco do programa em execução, de forma a iniciar operações concorrentes sempre que for possível. Ora, um compilador inteligente poderia ajudar bastante a CPU detectando o paralelismo do programa, arrumando as instruções de forma a facilitar a concorrência, organizando os dados e diminuindo a dependência entre eles. Poderia também dar dicas para a CPU sobre onde estão os desvios do programa e suas ramificações, antecipando o carregamento dos dados necessários ao processamento. É exatamente isso que se espera de um compilador para a família IA-64. Atualmente, as CPUs executam as instruções da forma como elas chegam, tentando fazer isso da maneira mais rápida possível. É interessante observar que as CPU's que têm capacidade de executar até 4 instruções por ciclo de relógio, na prática, ficam abaixo de 2 instruções por ciclo. Se as instruções chegassem já preparadas para serem executadas de forma concorrente, o desempenho com certeza seria melhor. Um compilador otimizado para a IA-64 deverá arrumar as instruções da melhor forma possível, evitando as dependências e inclusive indicando para o processador quais podem ser executadas em paralelo. As modernas CPU's com seu enorme pipeline sempre tropeçaram nos desvios. Nessas CPU's, enquanto uma instrução está sendo executada, as próximas já foram capturadas e estão sendo decodificadas e preparadas para execução. Aí surge um problema: se a instrução atual for um salto, todo o trabalho de busca e preparação das próximas instruções é perdido e o processamento precisa parar enquanto a instrução correta é lida da memória e percorre todo o pipeline. Nos programas atuais, em média ocorre um desvio a cada 6 instruções. Para minimizar esse problema, usa-se a predição de desvios. Quando surge um desvio condicional, a unidade que busca as próximas instruções tenta adivinhar se ele será efetivado ou não e inicia a busca das próximas instruções no endereço que foi julgado correto. Isso é chamado de execução especulativa. Mas a predição nem sempre acerta e o erro implica em grande perda de tempo. O compilador pode ajudar muito pois ele dispõe de mais tempo para analisar se um desvio será efetivado e pode dar uma dica para a CPU do que deverá acontecer. Na grande maioria das vezes o compilador prepara a CPU para executar de forma especulativa todos os ramos do desvio e depois descartar os resultados de que não necessitar. O pior veneno para microprocessadores com pipeline grande é o surgimento de instruções com dependências que obriguem a esvaziar o pipeline antes de iniciar a execução da instrução seguinte. Exagerando com a analogia, é como se uma agência bancária só permitisse a entrada de uma cliente quando o que está lá dentro saísse. Um compilador inteligente poderia arrumar os dados de forma a criar a menor dependência possível e esse trabalho seria muito facilitado se a CPU oferecesse uma grande quantidade de registradores. Isso facilitaria o planejamento para a execução em paralelo e diminuiria a necessidade de reutilização. Um outro galho para esse tipo de CPU é parar o processamento enquanto o dada necessário não chega. Isso foi minimizado com a utilização das memórias cache, mas ainda não está satisfatório. Ora, o compilador sabe os instantes em que haverá carregamento de dados e pode dar uma dica para a CPU, permitindo que esta antecipe a leitura do dado. A ideia é iniciar a carga do dado bem antes da CPU necessitar-lhe. Conta a história que as máquinas RISC ("Reduced Instruction Set Computer") surgiram quando os projetistas substituíram as instruções complexas por um conjuntos mais simples, mais veloz e de controle mais fácil. Com isso, o chip ficou menos sobrecarregado, sobrando mais área para ser usada em outras unidades funcionais. A história real é um pouco diferente! As máquinas RISC nasceram da necessidade de simplificar-se a CPU. A ideia foi trocar complexidade da CPU por otimização durante a compilação. Usou-se então um conjunto de instruções pequeno mas veloz, que pudesse ser executado em paralelo e ainda que fosse de fácil controle. Um grande conjunto de registradores substituiu os complexos modos de endereçamento. Com a simplificação da unidade de controle, uma maior área do CI pode ser empenhada diretamente no processamento. O trabalho de arrumar as instruções, de forma a espremer o máximo desempenho da CPU, foi transferido para o compilador. Em outras palavras, boa parte da complexidade da CPU foi transferida para o compilador. Assim o termo RISC não é muito feliz pois ele faz referência apenas ao conjunto de instruções e ignora o importante papel do compilador em gerar programas otimizados para essas máquinas. A família x86 começou com a CPU 8086, que é uma máquina CISC. Com a demanda por desempenho, os projetistas da Intel espremeram todo o desempenho passível de ser obtida com essa arquitetura. A evolução natural seria para uma arquitetura RISC, mas isso comprometeria seriamente a compatibilidade com o passado. A solução encontrada foi a de projetar uma máquina híbrida: uma casca CISC com um coração RISC. Assim são os Pentium Pro e Pentium II que traduzem as complexas instruções x86 em uma ou mais micro-operações que são executadas por uma máquina RISC. Essa micro-operações são de mais fácil controle e podem ser executadas em paralelo. Porém uma grande parte da CPU ainda é dedicada ao controle dessas instruções, à predição dos desvios e à tradução. As atuais CPUs possuem milhões de transistores, mas, desse total, apenas uma pequena parte é usada diretamente no processamento, pois a grande maioria é consumida no controle das instruções para possibilitar a execução fora de ordem e na predição dos desvios, ou seja, as atuais arquiteturas RISC/CISC estão complexas novamente e, por isso, é hora de aplicar o método: vamos simplificar a CPU e passar o trabalho de otimização para o compilador. Essa é a grande máxima da arquitetura IA-64, empregada no desenvolvimento da CPU Merced. A arquitetura IA-64 usa instruções de tamanho fixo (40 bits) e elas são executadas em um único período de relógio, ou seja, são semelhantes às instruções RISC: comprometidas com o desempenho. É interessante confrontar a simplicidade dessas instruções de tamanho fixo, com a complexidade da cansada arquitetura x86, cujas instruções têm tamanho variando entre 8 e 108 bits. Somente após decodificar uma instrução, a CPU descobre qual o seu tamanho (onde está sua fronteira). As instruções IA-64 são arrumadas em pacotes de 128 bits, cada pacote com 3 instruções, como está mostrado na Figura 3. Isso é o que se chama LIW, mas a Intel prefere usar o termo EPIC ("Explicitily Parallel Instruction Computing"), pois nesse pacote, além das três instruções, existem bits para indicar quais podem ser executadas em paralelo. A CPU não mais precisa ficar analisando (durante a execução) o fluxo de instruções tentando descobrir o paralelismo intrínseco do problema, pois ele é explicitado durante a compilação. Figura 3: Uma suposição para o empacotamento das instruções IA-64. Cada instrução tem o tamanho fixo de 40 bits. A seqüência das instruções é fornecida pelo compilador e não necessariamente coincide com a ordem original do programa. O campo de 8 bits, denominado "template", indica quais instruções desse pacote, e dos próximos, podem ser executadas em paralelo. Figura 4: Possível formato de uma instrução IA-64. As instruções IA-64, vide Figura 4, têm um tamanho de 40 bits e estão divididas em 5 campos, cada um com uma finalidade específica. O campo "Opcode" indica a operação a ser executada: soma, multiplicação, incremento, etc.. O campo "Predicate", com 6 bits, define uma das 64 possíveis predições usadas para resolver os problemas gerados pelos desvios. Os registradores com os dados a serem operados são indicados pelos campos GPR. Uma instrução pode manipular até três registradores. Cada campo GPR tem 7 bits e especifica um dos 128 registradores da CPU. Na verdade, existem 128 registradores para números inteiros e 128 registradores para números em representação com ponto-flutuante. Os campos GPR são específicos para cada instrução, ou seja, de acordo com a instrução, os campos GPR selecionam registradores inteiros ou registradores ponto-flutuante. Devemos comparar essa quantidade de registradores (256) com os oferecidos pela arquitetura x86: 8 registradores inteiros e uma pilha com 8 registradores ponto-flutuante. Os compiladores para as CPU’s IA-64 usarão uma técnica denominada "Predication", que permite eliminar os efeitos danosos provocados pelos desvios. Ao encontrar um desvio, diferente do que acontecia com os modelos anteriores, a CPU não precisa mais apostar um dos ramos. Ela simplesmente executa todos os desvios possíveis e depois descarta os resultados irrelevantes. Todos os desvios e suas ramificações são preditos pelo compilador. Assim, durante a execução, quando a CPU encontra um desvio já predito pelo compilador, ela começa a executar os códigos ao longo de todos os possíveis destinos. Quando o destino correto é decidido, a CPU armazena os resultados válidos e descarta os demais. É muito importante o papel do compilador. Quando este encontra um desvio, ele o analisa para ver se é um candidato para a predição. A grande maioria dos desvios o é. Caso positivo, marca com um "Predicate" diferente as instruções de cada ramo do desvio. Por exemplo, uma instrução do tipo "salte se a variável R for igual a zero" tem duas ramificações possíveis, como é mostrado na Figura 5 (I3). Figura 5: Ilustração da operação de predição dos desvios. As instruções pertencentes a um mesmo ramo têm o "predicate" igual. Existem disponíveis 64 "predicates" diferentes. Após marcar as instruções de cada ramo do desvio, o compilador verifica quais podem ser executadas em paralelo e depois empacota as instruções em palavras de 128 bits, de forma que o microprocessador as receba arrumadas da melhor forma possível. Durante a execução, a CPU despacha para execução em paralelo as instruções que não têm dependências e cuida para que as que apresentam dependências sejam executadas na ordem correta. O lado ruim desta técnica de predição é que a CPU sempre executa instruções cujos resultados serão descartados; porém, segundo especialistas, haverá um ganho em relação às arquiteturas atuais. Na verdade, o Merced, por ser mais simples, tem uma maior abundância de recursos e, por isso, pode desperdiçar um pouco do seu potencial executando instruções que se vão revelar desnecessárias. O carregamento especulativo permite a carga de um dado antes que o programa venha a necessitar-lhe. A ideia básica é separar o carregamento do dado do instante de sua utilização. O dado sempre estará disponível e, por isso, o processador não se detém esperando que a memória, ou o cache, seja lido. O compilador é o responsável por analisar o programa buscando operações que necessitam de dados que estão na memória. Sempre que possível, o compilador insere antecipadamente uma instrução de carregamento (bem antes do ponto onde o dado será necessário) e uma instrução de verificação imediatamente antes da instrução que usa o dado. Isso resulta que, muito antes do dado ser necessário, ele já está sendo buscado na memória. A verificação é importante porque o dado pode não mais ser válido e, além disso, é necessário checar as exceções. Por exemplo, um dado pode não mais ser válido porque a CPU executou um salto. Tudo isso é preparado pelo compilador visando a obter o máximo de paralelismo. Há realmente grandes novidades com a arquitetura IA-64 e o compilador vai desempenhar um papel importantíssimo, pois de sua inteligência dependerá o desempenho da CPU. As novas versões dessa CPU apresentarão compatibilidade, ou seja, um compilador antigo poderá rodar numa nova CPU, porém o desempenho máximo só será possível após esse compilador ser reprojetado para essa nova CPU. Tomando lições com os supercomputadores, já aprendeu-se que é muito mais fácil gerar códigos para execução em paralelo a partir de programas onde o paralelismo foi claramente expresso do que a partir de programas onde o programador construiu obscuros e entrelaçados loops. Assim, deverão surgir linguagens estendidas para o processamento paralelo (na verdade essas extensões já existem, mas não para a plataforma IA-64), onde, através de instruções especiais, o programador possa indicar ao compilador o paralelismo intrínseco do seu programa. A chegada do Merced ao mercado não deverá ser diferente do aconteceu com as outras CPU's: inicialmente ele será um chip grande e caro, mas, ao longo do tempo, deverá diminuir de tamanho e preço. No começo, apenas máquinas topo de linha farão uso desse microprocessador e, para a maioria dos usuários, o velho x86 ainda apresentará um desempenho bastante satisfatório. -
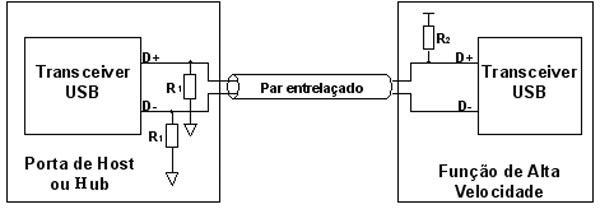 Este artigo complementa o estudo sobre o USB, quando foram abordadas as estruturas de software associadas aos processos de instalação e operação de dispositivos via USB. Desta vez, serão detalhadas as estruturas elétricas envolvidas. O Universal Serial Bus (USB) é uma nova filosofia de barramento serial para o fluxo de dados entre um computador e dispositivos periféricos. O USB foi projetado para preencher certas lacunas deixadas, até então, pelos outros barramentos seriais. Ele oferece: Melhor integração entre a computação e os sistemas de comunicações, focalizando-se na CTI (Computer Telephony Integration); Maior comodidade para o usuário, que não necessita de configurar o dispositivo, pois o próprio sistema se encarrega desta tarefa; o USB incorpora a filosofia plug-and-play; Expansão no número de portas; ele pode endereçar até 127 dispositivos. O sistema USB é composto pelo Controlador Host USB, por dispositivos USB e por interconexões. A Figura 1 mostra a topologia de um sistema USB. O host é responsável por: detectar a inserção e a remoção de um dispositivo, por gerenciar o fluxo de dados e de controle, monitorando o estado das transferências, e por controlar a interface elétrica entre ele e os dispositivos. Figura 1: Topologia de um sistema USB Um dispositivo USB pode ser de dois tipos: função ou hub. A função é capaz de transmitir ou receber dados ou informações de controle pelo barramento. Ela serve para aumentar a capacidade do sistema. Exemplos de funções são: mouse, teclado, impressora e adaptador telefônico como um ISDN. Cada função contém informações descrevendo suas capacidades e os recursos dos quais necessita. O hub é o elemento chave na topologia USB, pois é ele que permite a expansão do número de conexões do sistema. Cada hub converte um ponto de conexão em outros múltiplos pontos. A arquitetura USB permite o uso de múltiplos hubs. O USB permite dois modos de comunicação: um de alta velocidade, operando a 12 Mb/s, e outro de baixa velocidade, a 1,5 Mb/s. O modo de baixa velocidade visa a atender a um pequeno número de dispositivos com largura de banda estreita, como mouses. Cada função é responsável por indicar em que modo irá operar. O barramento físico é composto de um cabo com quatro fios: VBus, D+, D- e GND. O fio VBus é o meio de fornecimento de alimentação para os dispositivos que necessitarem dela. Em um sistema USB, existem hubs e funções que possuem alimentação própria e hubs e funções que são alimentados pelo barramento através de VBus. VBus é nominalmente +5 V. Para aplicações de alta velocidade, os fios D+ e D- são entrelaçados. Os dados são transmitidos através de D+ e D- por meio de diferenças de tensão entre eles. O USB usa uma codificação NRZI. Os cabos são conectados aos dispositivos conforme ilustrado na Figura 2. A posição dos resitores de pull-up muda dependendo de tratar-se de alta ou baixa velocidade. Quando não existe função conectada ao hub, os resistores de pull-down fazem com que ambos D+ e D- fiquem abaixo de um valor de tensão de limiar para a detecção da presença do dispositivo. Se essa condição persistir por mais que 2,5 microssegundos, é caracterizada a desconexão do dispositivo. A conexão de um dispositivo é caracterizada pela situação oposta, ou seja, quando apenas uma das linhas é levada além da tensão de limiar e esta situação persiste por mais de 2,5 microssegundos. Figura 2: Esquema Físico de Conexão do Barramento A transmissão de dados via USB é baseada no envio de pacotes. A transmissão começa quando o o Controlador Host envia um pacote (Token Packet) descrevendo o tipo e a direção da transmissão, o endereço do dispositivo USB e o referido número de endpoint. A transmissão de dados pode ser realizada tanto do Host para o dispositivo quanto em sentido inverso. O dispositivo USB decodifica o campo de endereço, reconhecendo que o pacote lhe é referente. A seguir, a fonte da transmissão envia um pacote de dados (Data Packet) ou indica que não há dados a transferir. O destino responde com um pacote de Handshake (Handshake Packet) indicando se a transferência obteve sucesso. O USB utiliza três tipos de pacotes: Token, Data e Handshake Packets, mostrados nas figuras 3(a), (b) e (c), respectivamente. Esses pacotes possuem os seguintes campos: Figura 3: (a) Token, (b) Data e (c) Handshake Packets PID (Packet Identifier): composto de oito bits. Os quatro mais significativos identificam e descrevem o pacote e os restantes são bits de verificação para prevenção de erros (check bits). Esses check bits são constituídos pelo complemento um dos quatros bits identificadores; ADDR (Address): endereço do dispositivo USB envolvido. Composto de 7 bits, limita o número de dispositivos endereçáveis em 127; ENDP (Endpoint): possui 4 bits que representam o número do endpoint envolvido. Permite maior flexibilidade no endereçamento de funções que necessitem de mais de um subcanal; CRC (Cyclic Redundancy Checks): bits destinados à detecção de erros na transmissão; DATA : bits de dados. Um Token Packet pode identificar a transmissão como sendo de transferência para o Host (IN), de transferência para a função (OUT), de início de frame (SOF) ou de transferência de informações de controle para o endpoint (SETUP). O CRC de um Token Packet possui 5 bits e atua apenas sobre os campos ADDR e ENDP, uma vez que o PID possui seu próprio sistema de prevenção contra erros. Os dados transmitidos via Data Packet devem ter um número inteiro de bytes. O CRC de um Data Packet possui 16 bits e age apenas sobre o campo DATA. O Handshake Packet é constituído apenas de um PID. Esse pacote pode significar que o receptor recebeu os dados livres de erros (ACK), que o receptor não pode receber os dados, que o transmissor não pode transmitir (NAK) ou que o endpoint está em parado (STALL). O USB aceita quatro tipos de transferências diferentes: Control, Bulk, Interrupt e Isochronous. A transferência do tipo Control serve para configurar ou transmitir parâmetros de controle a um dispositivo. Inicialmente, em idle, ele recebe um Token de SETUP oriundo do Controlador Host. Em seguida, o Host envia um Data Packet para o endpoint de controle da função. A função envia, então, ao Host um Handshake Packet de reconhecimento (ACK) e entra em idle. A transferência Bulk é utilizada para a transmissão de grande quantidade de dados, como em impressoras ou scanners. Ela garante uma transmissão livre de erros por meio da detecção de erros e de novas retransmissões, se necessário. Caso o Host deseje receber uma grande quantidade de dados, ele envia um Token de IN e a função devolve um Data Packet. Se houver algum problema, a função envia um STALL ou NAK e entra em idle. Ao final, o Host devolve um ACK. Se, em vez de receber, o Host desejar enviar dados, ele manda um Token de OUT em vez de IN. A transmissão do tipo Interrupt é requisitada pelo Host e consiste numa transferência de pequena quantidade de dados. Os dados podem representar a notificação de algum evento, como os de um mouse ou caneta ótica. A transferência tipo Isochronous permite o tráfego de dados que são criados, enviados e recebidos continuamente em tempo real. Nessa situação não há handshake, devido à própria continuidade com que os dados são transmitidos. Caso contrário, haveria atraso e a transmissão em tempo real seria comprometida. Todas as especificações técnicas do padrão USB estão rigorosamente estabelecidas na Universal Serial Bus Specification Revision 1.0. Para saber mais: Ler parte 1 Artigo sobre USB Livro USB System Architecture, de Don Anderson
Este artigo complementa o estudo sobre o USB, quando foram abordadas as estruturas de software associadas aos processos de instalação e operação de dispositivos via USB. Desta vez, serão detalhadas as estruturas elétricas envolvidas. O Universal Serial Bus (USB) é uma nova filosofia de barramento serial para o fluxo de dados entre um computador e dispositivos periféricos. O USB foi projetado para preencher certas lacunas deixadas, até então, pelos outros barramentos seriais. Ele oferece: Melhor integração entre a computação e os sistemas de comunicações, focalizando-se na CTI (Computer Telephony Integration); Maior comodidade para o usuário, que não necessita de configurar o dispositivo, pois o próprio sistema se encarrega desta tarefa; o USB incorpora a filosofia plug-and-play; Expansão no número de portas; ele pode endereçar até 127 dispositivos. O sistema USB é composto pelo Controlador Host USB, por dispositivos USB e por interconexões. A Figura 1 mostra a topologia de um sistema USB. O host é responsável por: detectar a inserção e a remoção de um dispositivo, por gerenciar o fluxo de dados e de controle, monitorando o estado das transferências, e por controlar a interface elétrica entre ele e os dispositivos. Figura 1: Topologia de um sistema USB Um dispositivo USB pode ser de dois tipos: função ou hub. A função é capaz de transmitir ou receber dados ou informações de controle pelo barramento. Ela serve para aumentar a capacidade do sistema. Exemplos de funções são: mouse, teclado, impressora e adaptador telefônico como um ISDN. Cada função contém informações descrevendo suas capacidades e os recursos dos quais necessita. O hub é o elemento chave na topologia USB, pois é ele que permite a expansão do número de conexões do sistema. Cada hub converte um ponto de conexão em outros múltiplos pontos. A arquitetura USB permite o uso de múltiplos hubs. O USB permite dois modos de comunicação: um de alta velocidade, operando a 12 Mb/s, e outro de baixa velocidade, a 1,5 Mb/s. O modo de baixa velocidade visa a atender a um pequeno número de dispositivos com largura de banda estreita, como mouses. Cada função é responsável por indicar em que modo irá operar. O barramento físico é composto de um cabo com quatro fios: VBus, D+, D- e GND. O fio VBus é o meio de fornecimento de alimentação para os dispositivos que necessitarem dela. Em um sistema USB, existem hubs e funções que possuem alimentação própria e hubs e funções que são alimentados pelo barramento através de VBus. VBus é nominalmente +5 V. Para aplicações de alta velocidade, os fios D+ e D- são entrelaçados. Os dados são transmitidos através de D+ e D- por meio de diferenças de tensão entre eles. O USB usa uma codificação NRZI. Os cabos são conectados aos dispositivos conforme ilustrado na Figura 2. A posição dos resitores de pull-up muda dependendo de tratar-se de alta ou baixa velocidade. Quando não existe função conectada ao hub, os resistores de pull-down fazem com que ambos D+ e D- fiquem abaixo de um valor de tensão de limiar para a detecção da presença do dispositivo. Se essa condição persistir por mais que 2,5 microssegundos, é caracterizada a desconexão do dispositivo. A conexão de um dispositivo é caracterizada pela situação oposta, ou seja, quando apenas uma das linhas é levada além da tensão de limiar e esta situação persiste por mais de 2,5 microssegundos. Figura 2: Esquema Físico de Conexão do Barramento A transmissão de dados via USB é baseada no envio de pacotes. A transmissão começa quando o o Controlador Host envia um pacote (Token Packet) descrevendo o tipo e a direção da transmissão, o endereço do dispositivo USB e o referido número de endpoint. A transmissão de dados pode ser realizada tanto do Host para o dispositivo quanto em sentido inverso. O dispositivo USB decodifica o campo de endereço, reconhecendo que o pacote lhe é referente. A seguir, a fonte da transmissão envia um pacote de dados (Data Packet) ou indica que não há dados a transferir. O destino responde com um pacote de Handshake (Handshake Packet) indicando se a transferência obteve sucesso. O USB utiliza três tipos de pacotes: Token, Data e Handshake Packets, mostrados nas figuras 3(a), (b) e (c), respectivamente. Esses pacotes possuem os seguintes campos: Figura 3: (a) Token, (b) Data e (c) Handshake Packets PID (Packet Identifier): composto de oito bits. Os quatro mais significativos identificam e descrevem o pacote e os restantes são bits de verificação para prevenção de erros (check bits). Esses check bits são constituídos pelo complemento um dos quatros bits identificadores; ADDR (Address): endereço do dispositivo USB envolvido. Composto de 7 bits, limita o número de dispositivos endereçáveis em 127; ENDP (Endpoint): possui 4 bits que representam o número do endpoint envolvido. Permite maior flexibilidade no endereçamento de funções que necessitem de mais de um subcanal; CRC (Cyclic Redundancy Checks): bits destinados à detecção de erros na transmissão; DATA : bits de dados. Um Token Packet pode identificar a transmissão como sendo de transferência para o Host (IN), de transferência para a função (OUT), de início de frame (SOF) ou de transferência de informações de controle para o endpoint (SETUP). O CRC de um Token Packet possui 5 bits e atua apenas sobre os campos ADDR e ENDP, uma vez que o PID possui seu próprio sistema de prevenção contra erros. Os dados transmitidos via Data Packet devem ter um número inteiro de bytes. O CRC de um Data Packet possui 16 bits e age apenas sobre o campo DATA. O Handshake Packet é constituído apenas de um PID. Esse pacote pode significar que o receptor recebeu os dados livres de erros (ACK), que o receptor não pode receber os dados, que o transmissor não pode transmitir (NAK) ou que o endpoint está em parado (STALL). O USB aceita quatro tipos de transferências diferentes: Control, Bulk, Interrupt e Isochronous. A transferência do tipo Control serve para configurar ou transmitir parâmetros de controle a um dispositivo. Inicialmente, em idle, ele recebe um Token de SETUP oriundo do Controlador Host. Em seguida, o Host envia um Data Packet para o endpoint de controle da função. A função envia, então, ao Host um Handshake Packet de reconhecimento (ACK) e entra em idle. A transferência Bulk é utilizada para a transmissão de grande quantidade de dados, como em impressoras ou scanners. Ela garante uma transmissão livre de erros por meio da detecção de erros e de novas retransmissões, se necessário. Caso o Host deseje receber uma grande quantidade de dados, ele envia um Token de IN e a função devolve um Data Packet. Se houver algum problema, a função envia um STALL ou NAK e entra em idle. Ao final, o Host devolve um ACK. Se, em vez de receber, o Host desejar enviar dados, ele manda um Token de OUT em vez de IN. A transmissão do tipo Interrupt é requisitada pelo Host e consiste numa transferência de pequena quantidade de dados. Os dados podem representar a notificação de algum evento, como os de um mouse ou caneta ótica. A transferência tipo Isochronous permite o tráfego de dados que são criados, enviados e recebidos continuamente em tempo real. Nessa situação não há handshake, devido à própria continuidade com que os dados são transmitidos. Caso contrário, haveria atraso e a transmissão em tempo real seria comprometida. Todas as especificações técnicas do padrão USB estão rigorosamente estabelecidas na Universal Serial Bus Specification Revision 1.0. Para saber mais: Ler parte 1 Artigo sobre USB Livro USB System Architecture, de Don Anderson
Sobre o Clube do Hardware
No ar desde 1996, o Clube do Hardware é uma das maiores, mais antigas e mais respeitadas comunidades sobre tecnologia do Brasil. Leia mais
Direitos autorais
Não permitimos a cópia ou reprodução do conteúdo do nosso site, fórum, newsletters e redes sociais, mesmo citando-se a fonte. Leia mais