
uotlaf
-
Posts
81 -
Cadastrado em
-
Última visita
3 Seguidores


(21).thumb.jpeg.f6af425fd1f1b4cb7a9b561db8d4e222.jpeg)
-

Posso colocar 2 placas de vídeo no mesmo PC? Para geração IA
uotlaf respondeu ao tópico de TheDemonLena em Placas de vídeo
Existe, mas não inteiro. A parte dele que existe pra windows é parte da HIP SDK for windows(inclusive vem com um fork do clang). Aqui tem a lista de diferenças entre os dois. É bem mais limitado que o próprio rocm pra linux(e olha que esse já é bem limitado). -
Posso colocar 2 placas de vídeo no mesmo PC? Para geração IA
uotlaf respondeu ao tópico de TheDemonLena em Placas de vídeo
Funciona, mas ainda tá bem atrás de CUDA: - Só tem suporte completo pra linux no pytorch - HIP Runtime só funciona oficialmente em certas gpus(tem uma opção pra ignorar o check, e aí ele funciona no resto) - A performance é bem abaixo do esperado - Mesmo no tensorflow o suporte é bem "as vezes funciona". Fora que o suporte em aplicativos de terceiros também é bem precário. Se ignorar tudo isso, dá pra usar. Eu usei na minha RX 6600(em linux) pra treinar um modelo pra uma matéria e deu tudo certo. Só tem que ter cuidado pra não dar OOM porque ele se recusa a ir pra shared mem -
Posso colocar 2 placas de vídeo no mesmo PC? Para geração IA
uotlaf respondeu ao tópico de TheDemonLena em Placas de vídeo
Uma correção: Agora que eu vi que você tem uma gpu amd e uma nvidia. Não vai dar pra usar as duas ao mesmo tempo pra IA com as APIs proprietárias delas(só se tu rodar modelos diferentes em instâncias diferentes). Talvez dê em DirectML ou Vulkan, mas não dá pra saber sem tentar. Fora que a 2060 tem menos vram que a 7800XT Os três ao mesmo tempo(5900XT, 7800XT e 2060) já ficam perigosamente perto dos 600W sem contar o resto do setup. Eu não arriscaria usar os três em ppt máximo ao mesmo tempo. Em IA raramente teu cpu vai trabalhar(a menos que seja em cenário de offload pra gpu, e ainda sim a memória RAM vai ser um limite), então o 5900XT não deve chegar próximo disso. Mas como você tem uma gpu amd e uma nvidia, creio que vá querer jogar na amd enquanto a nvidia roda os modelos(até porque IA na AMD é bem ruim). -
Posso colocar 2 placas de vídeo no mesmo PC? Para geração IA
uotlaf respondeu ao tópico de TheDemonLena em Placas de vídeo
Sim, dá pra fazer Tanto o ROCM quanto via CUDA, dá pra selecionar qual dispositivo você quer usar. Se for pra treinar ou usar modelos prontos manualmente, dá pra configurar isso tanto no tensorflow quanto no pytorch. Se for pra usar frontends ou programas de terceiros, tem que ver o suporte pra selecionar a gpu em cada um deles. -
Como funciona a Infinity Fabric de processadores AMD?
uotlaf respondeu ao tópico de ArturHW em Processadores
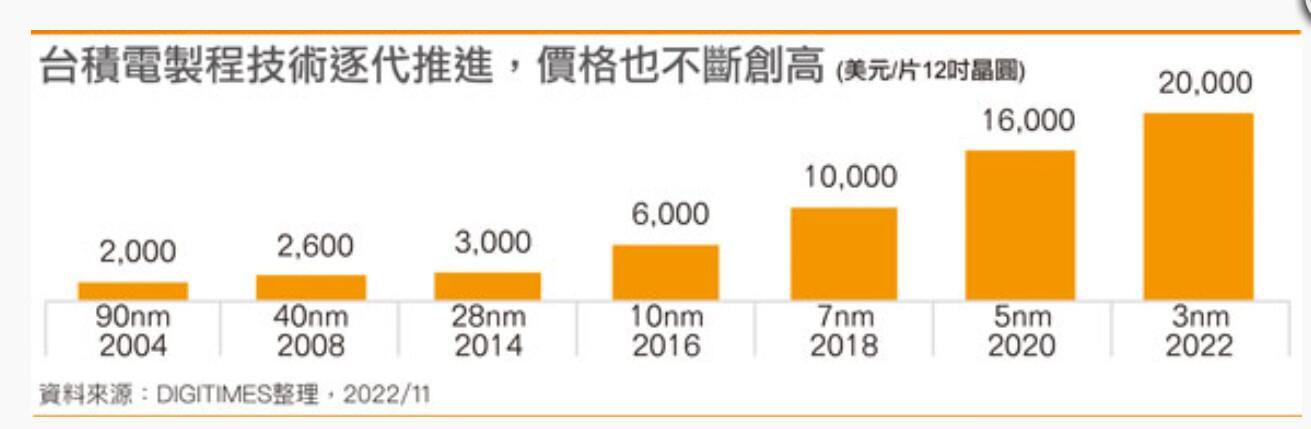
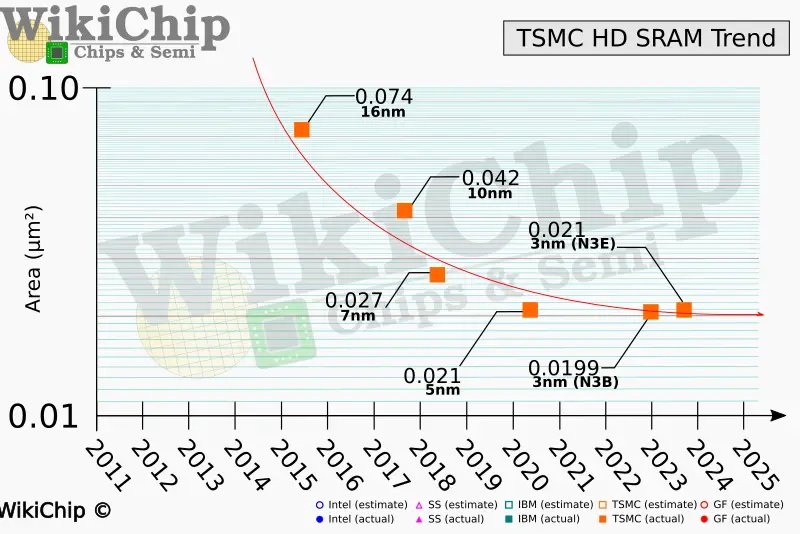
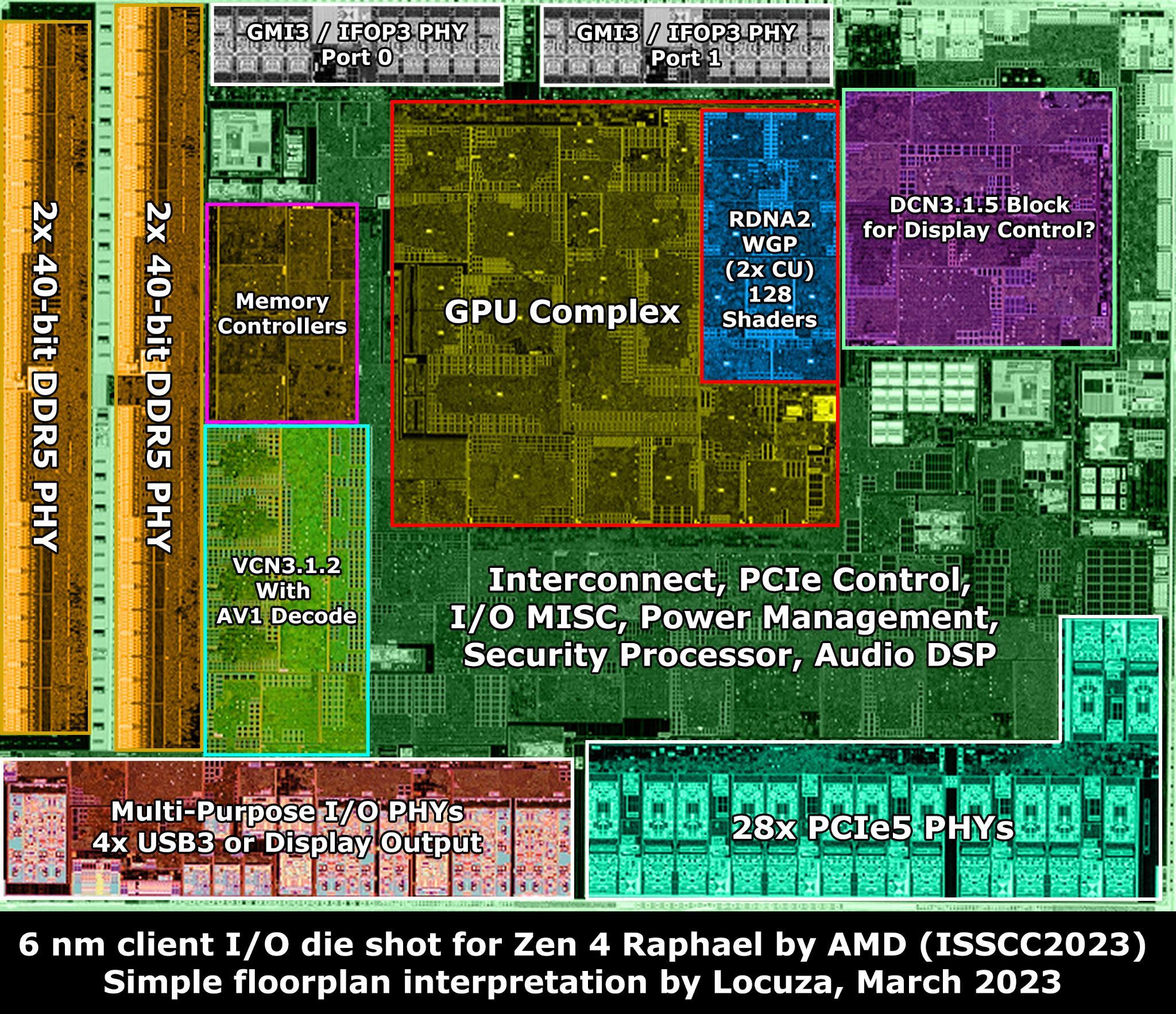
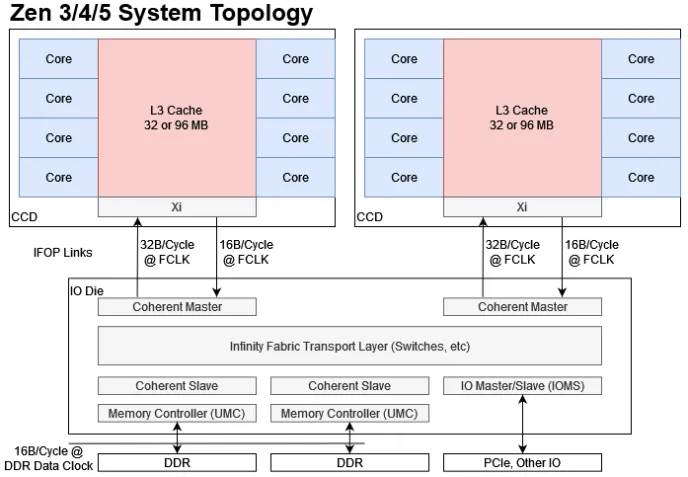
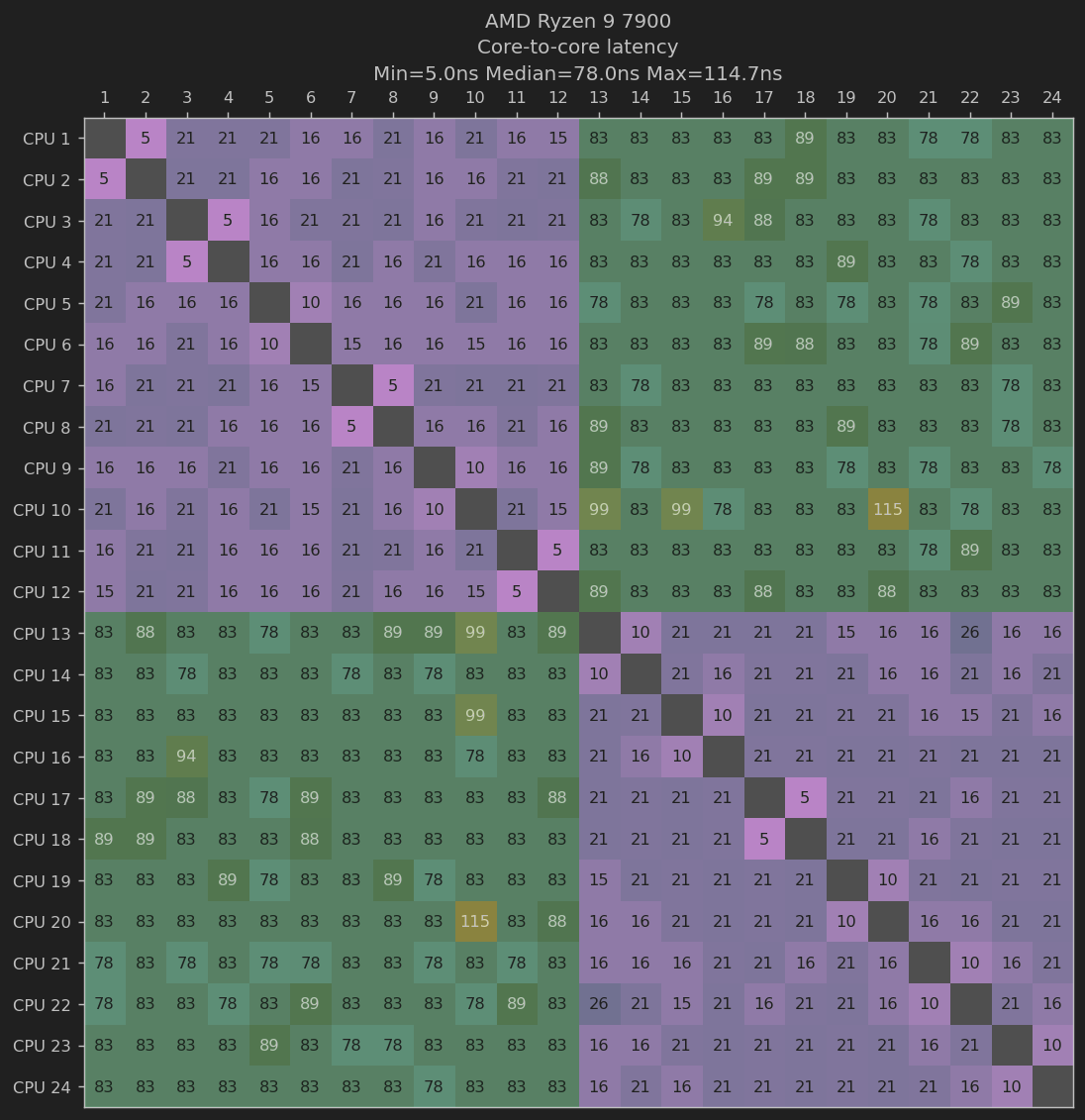
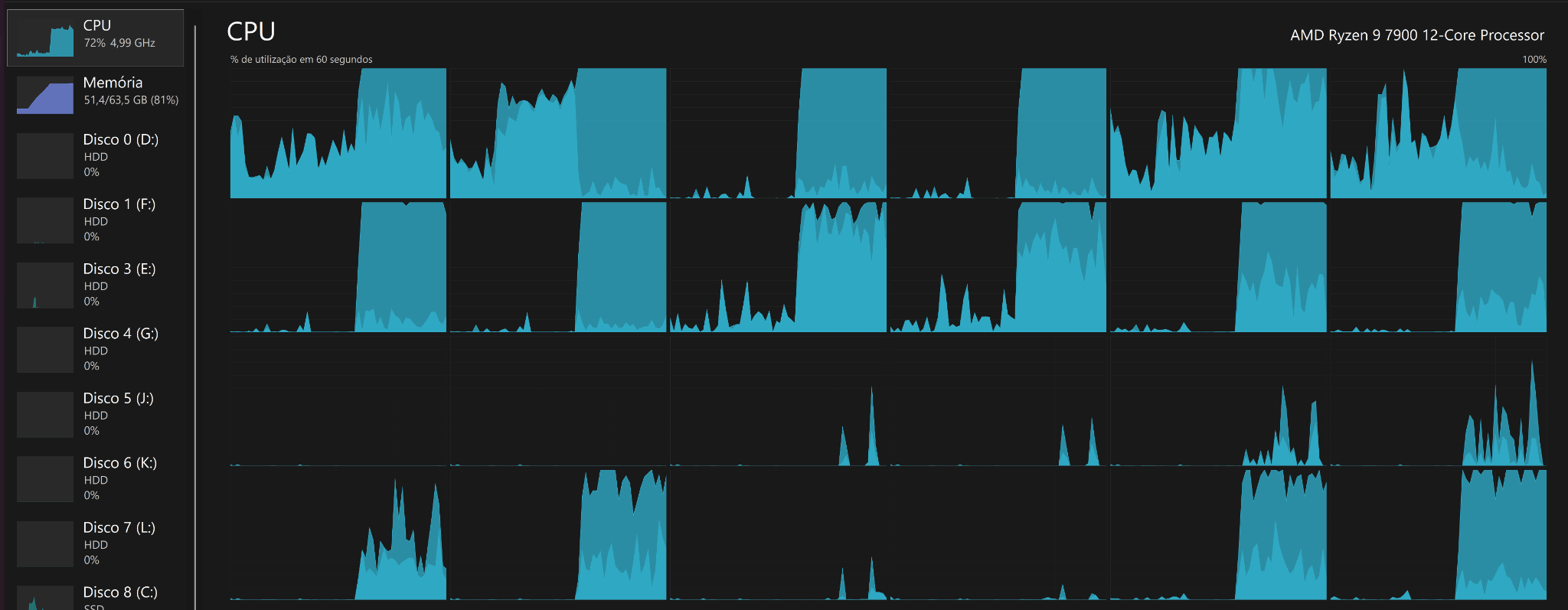
Pra entender o que é o infinity fabric, primeiro vamos entender porque ele existe e como é a estrutura de um cpu amd: Dies monolíticos Esse é um CPU Intel monolítico(I9-14900KS) Fonte: WCCFTech - Intel Core i9-14900KS CPU Delidded & Benchmarked Percebe que ele é só uma estrutura gigante no meio(chamada de DIE) ao redor de uma pcb(chamada de substrato/pacote). A intel manda o design do chip pras fábricas, que usam wafers de silício pra fazer os dies e retornar pra intel. Perceba que todo o cpu é integrado dentro do die: Fonte: Techpowerup - Intel Core i9-14900KS Review - The Last of its Kind O problema é que esses wafers tem uma probabilidade de serem problemáticos. Seja por impurezas do local(o que pode acontecer mesmo em um ambiente 100% controlado) ou por problemas de fabricação, as vezes uma parte do die vem com problemas. O que fazemos agora? A intel pagou por um cpu que não funciona. Existem algumas formas de resolver: - Se o cpu ainda funciona e só uma parte foi afetada(por exemplo, um core), o design já conta isso e é possível desativar o core. Assim a intel pode vender um i9 como um i7 e não perder tanto dinheiro pelo die. - Se o die foi comprometido em uma área crítica, a única forma é descartar. Isso sem contar com problemas que podem acontecer na montagem dos cpus também. Muita coisa pode dar errado nesse processo todo de fazer um cpu e enviar até a sua casa. Preço de fabricação por node Tem uma outra coisa que também vale a pena falar: O preço pra cada processo de fabricação. Preço pra fabricação de wafers na TSMC em 2022. Fonte: Techpowerup Como dá pra ver, o preço sobe bastante com nodes mais novos(o que é esperado). As empresas querem sempre os mais novos por questões de densidade e eficiência, o problema é que não é o chip inteiro que se beneficia disso. Escalonamento de certas partes do chip A SRAM é um ótimo exemplo disso: Mesmo em processos mais novos, o tamanho praticamente não mudou(falando de tsmc 7nm pra o atual N3e). Vale lembrar que esse número(3 nanômetros, 5 nanômetros) não é indicativo do tamanho dos transistors. Na verdade ele já perdeu o sentido faz muito tempo e hoje em dia é só o nome do processo mesmo. Fonte: Wikichip - IEDM 2022: Did We Just Witness The Death Of SRAM? Por outro lado, cores(o principal motivo pra as empresas quererem os nodes mais novos) se beneficiam muito de densidades mais altas. Nem tudo precisa estar no melhor possível Além disso, como deu pra ver no die shot do 14900KS, um soc não é feito só pelo cpu: tem a área do controlador de memória, controladores PCI, controladores USB(caso eles fiquem no soc), IGPU, I2C, DMI e LPC. Tem muita coisa aí que não precisa ser do melhor possível, e dá pra economizar muito dinheiro não botando eles no melhor node possível. Como sua pergunta foi sobre o infinity fabric, vou focar nele daqui pra frente. A solução da amd A AMD decidiu que ia separar toda área que pode se beneficiar de nodes melhores das áreas que não são foco do produto. Um exemplo é o Ryzen 9 7950x: Fonte: Techpowerup - AMD Ryzen 9 7900X Review - Creator Might, Priced Right Nos Ryzen, temos duas estruturas principais: O CCD e o I/O die. O CCD é responsável pelos cores pelo tiered cache(L1d+L1i, L2 e L3). Ele é a parte principal dos Ryzen, já que é ele que tem os processadores de fato. A AMD sempre mantém os CCDs no mais novo processo possível pra garantir a eficiência e performance que os novos nodes podem trazer(claro que com modificações na arquitetura também). Apesar do cache(que é SRAM) não escalonar bem, ele precisa estar extremamente próximo do CPU pra garantir latência baixa e banda altíssima, então a AMD deixa eles no CCD mesmo. Fonte: Chips and Cheese - Testing AMD’s Bergamo: Zen 4c Spam O I/O die, por outro lado, contém todo o resto do CPU(Não é só de processadores que vivem os nossos socs atuais). Isso inclui os controladores de memória, pontes PCI, GPU, USB e tudo o que foi mencionado a uns parágrafos atrás. Não é necessário ele estar em um processo mais novo, então a amd pode baratear os cpus e ainda economizar dinheiro fazendo o I/O die em 6nm Fonte: Locuza - Zen 4 Raphael 6 nm client I/O die (meu cpu hihihi) Ok, agora que temos todas as partes, vamos precisar de algo pra juntar as duas. É aí que o Infinity Fabric entra. Infinity Fabric Para demonstrar o infinity fabric, eu vou usar bastante do artigo incrível da galera do chips and cheese "Pushing AMD’s Infinity Fabric to its Limits". Recomendo muito a leitura. O infinity fabric nada mais é do que o nome que a AMD dá pra conexão inter-die pelo pacote. Ele é composto por três partes: - O conector do lado do CCD - O conector do lado do I/O die - A ponte que fica no substrato(Infinity Fabric Over Package Link) Fonte: Chips and Cheese - Pushing AMD’s Infinity Fabric to its Limits O lado bom Isso garante que a amd possa adaptar a topologia do sistema conforme ela queira. Um Ryzen 7 7800(8/16), um Ryzen 9 7950x(16/32) e um Threadripper PRO 7995WX(96/192) utilizam os mesmos CCDs, e os ccds com problema podem ser distribuídos entre chips que usam menos cores por ccd(Ryzen 5 e Ryzen 9 x900). Vale notar que os Threadripper e os Epic usam I/O dies maiores pra acomodarem os vários CCDs ao mesmo tempo. Inclusive, esse possivelmente é o principal motivo do porque a gente vê tão pouco Ryzen 5 e nenhum Ryzen 3 no mercado - A AMD só tem um design pra todo mundo e pouquíssimos dies dão problema o suficiente mas ainda serem utilizáveis pra virarem Ryzen 3. No lugar disso, ela tá com a estratégia de lançar chips específicos pra certas regiões(tipo o 5600X3D) pra se livrar dos que funcionaram. O lado ruim Nem tudo são flores. Passar os dados pelo substrato gasta bastante energia, e isso faz os Ryzen terem um consumo base bem alto. Mesmo que os núcleos sejam extremamente eficientes(o que explica o consumo baixo em full load), o infinity fabric + o i/o die estão sempre lá gastando energia. Pra tu ter uma ideia, meu Ryzen 9 7900 tá reportando menos de 1 W nos cores, 20 W no SOC(i/o die) e 35 W no pacote inteiro (soc+misc+IFoP+cores). Além disso, como dá pra ver alí em cima, o IFoP é ligado somente de CCD->I/O Die. Isso significa que passar de core pra core dentro do mesmo CCD é bem barato, mas passar de CCD pra CCD gasta bastante energia e ainda é lento: Latência core-a-core do 7900. Percebe como fica bem claro quais cores são de cada CCD. Fonte: Eu com o core-to-core-latency Outra desvantagem da infinity fabric é que ela limita tudo o que pode vir pro cpu. Voltando a imagem da topologia: Percebe que tem um limite pra quantidade de dados que podem passar pelo IFoP por clock(32B/ciclo de leitura e 16B/ciclo de escrita). Agora vamos fazer um cálculo: Se utilizarmos duas memórias RAM a 6000MT, temos 96 GB/s de banda teórica. O infinity fabric dos Ryzen 7000 roda a 2000MHz, então temos teoricos 64GB/s de leitura e 32GB/s de escrita por CCD. Percebe que só vai dar pra utilizar a banda toda da memória se tivermos 2 CCDs ou mais? E ainda sim, de que vai adiantar utilizar memórias mais rápidas se vamos estar limitados pela banda do infinity fabric? Além disso, sobrecarregar o infinity fabric também resulta em problemas de latência(assim como sobrecarregar o IMC resulta na mesma coisa). Se temos threads que não precisam acessar a memória de outras threads, dá pra jogar cada uma pra um CCD e aproveitar o dobro de banda de memória sem sobrecarregar o IFoP(inclusive eu fiz isso pra um programa de uma matéria do curso). O uso do infinity fabric também causa outros problemas: Como o cache é completamente separado entre os CCDs, a probabilidade de cache miss entre CCD é altíssima. Os Ryzen tem ótimos branch predictors pra isso(inclusive o dos Ryzen 9000 conseguem prever até dois pulos), mas ainda é uma coisa pra se levar em consideração. E nos notebooks e apus? Como fica? Eu disse lá em cima que o i/o die e o infinity fabric gastam muita bateria por si só. Mas se existe Ryzen mobile, como eles fazem pra ter o infinity fabric e ainda sim terem um bom desempenho em bateria? A resposta vem se olharmos pro die de um Phoenix(Ryzen 3, 5 e 7 7x40u/hs): Fonte: Anandtech Sim, a AMD usa dies monolíticos nos chips mobile. Ainda tem o infinity fabric e ainda tem as mesmas limitações, mas como ele não passa pelo pacote, o soc economiza muita energia com isso. Sem falar que o I/O die(ou a parte responsável por ele) está no mesmo node que o CPU, o que garante eficiência também, apesar de deixar o produto bem caro. A AMD também apresentou um cpu modular mobile, o strix halo: Fonte: Videocardz - AMD Ryzen AI MAX 300 “Strix Halo” reviews are here Perceba que ele é modular, mas o CCD fica extremamente colado ao I/O die. Isso é pra economizar energia e diminuir a latência do Infinity fabric. Além disso, o IMC do strix halo é bem maior(Ele suporta 256-bit LPDDR5x-8000 somente), e toda essa banda é usada pela IGPU gigantesca que ele tem(40 CUs RDNA 3.5) Resumindo: - Infinity fabric serve pra conectar o CCD no I/O die nos cpus AMD, justamente porque eles foram feitos pra serem modulares - Essa modularidade permite que eles sejam bem mais baratos de serem feitos e permite a troca de dies defeituosos sem ter que jogar o cpu inteiro fora(só pela amd, claro) - O lado ruim é que ele termina limitando a banda disponível pros cores e dificulta a passagem de informações entre CCDs. Fora gastar bastante energia. Tentei deixar o mais fácil possível de entender, mas qualquer dúvida, pode perguntar que eu respondo sobre. Como um exemplo engraçado de estresse do infinity fabric, aqui temos uma LLM rodando no meu 7900 em um só CCD: Percebe que a banda da memória tá batendo em um certo limite que não sai(64GB/s) E como resultado, um CCD inteiro fica em I/O wait por ficar memory-bounded(que na real é o infinity fabric limitando a conexão). O outro CCD não tá fazendo praticamente nada(tirando uns cores aí que eu não lembro o que tava fazendo)
-
Tela ficando granulada com processador Ryzen 5 8600G
uotlaf respondeu ao tópico de pnacibs21 em Processadores
Tem cara de problema de memória/IMC. Comece desativando o expo(a AMD garante até 5200MT. Qualquer coisa acima disso é overclock). Se ainda ocorrer, recomendo pedir um RMA desse cpu o quanto antes pra ver se resolvem. -
Posso usar duas placas de vídeo (AMD e Nvidia) para ganhar FPS em jogos?
uotlaf respondeu ao tópico de JGN-BRA em Placas de vídeo
Não vai. Existem tecnologias pra uso de múltiplas gpus(do mesmo fabricante e com pontes dedicadas pra isso - SLI e Crossfire), mas elas foram descontinuadas faz muito tempo. Botar a rx 580 não vai fazer diferença. A única coisa que dá pra fazer é usar uma pra codificação de vídeo e a outra pro jogo, mas o impacto é mínimo. Outro uso é usar o vídeo por uma e executar o programa pela outra. Assim dá pra usar algum upscaler pela que só tá sendo usada pra vídeo. O resultado ainda fica bem pior que a sua 3060(que tem hardware dedicado pra isso). -
O que você quer é deixar o gráfico integrado e o dedicado ligado ao mesmo tempo. Tem uma opção na uefi/BIOS setup pra forçar a deixar ele ligado. Na hora do boot, seu firmware verifica quais entradas estão conectadas a um monitor. Tem uma lista de prioridade sobre gpus(normalmente é dedicada -> integrada) e ele liga a que tiver um monitor conectado primeiro se tiver no modo automático. Você pode modificar esse comportamento no uefi/BIOS setup.
-
Notebook white-label do AliExpress com placa-mãe queimada: como reparar?
uotlaf respondeu ao tópico de William1719 em Notebooks
Notebooks não tem padrão de tamanho de placa nem de onde ficam os furos e o painel lateral. A única forma de botar outra placa aí sem adaptar é achando uma placa com tamanho compatível(o que não significa que os componentes vão estar no mesmo lugar). A única coisa que você pode fazer sem ter que adaptar algo é procurar por essa inscrição na placa e ter a sorte de ter alguém vendendo ela funcionando. -
Erro 0xc00000e impede boot com SSD após remover HD
uotlaf respondeu ao tópico de freitas.32 em Windows 11
Tem informação de como foi feita essa instalação do windows? É possível que tenha uma partição ESP no HD e o windows tenha usado ela(porque já tava criada) em vez de criar outra no SSD Você pode verificar isso com um pendrive de instalação do windows. Dá pra redimensionar, mover e criar outra ESP pro windows por uma distro linux e depois elo ambiente de instalação do windows. -
Devo trocar o Ryzen 7 5800X para jogar em 4K ultra com a GeForce RTX 5080?
uotlaf respondeu ao tópico de Lanzin21 em Processadores
A metodologia deste teste está errada. Nesse cenário, a gpu está sendo o gargalo. Por isso não teve ganhos(3fps é margem de erro). Testes de CPU não devem ser feitos em resoluções altas. Você só troca o CPU se ele não estiver mais conseguindo o framerate e frametime que você quer com tudo o que você executa. Resolução não vai importar pra um CPU. -
BIOS aparecendo no monitor secundário(Vertical) ao invés do primário
uotlaf respondeu ao tópico de Gleidson_ECV em Monitores de vídeo
Sua placa de vídeo tem uma ordem de pesquisa das saídas de vídeo(ex: A ordem da minha é DP1->DP2->HDMI1->DP3, da esquerda pra direita). Ela enumera nessa ordem e passa pro firmware na hora do boot. Você trocou esses cabos de lugar recentemente? Deve resolver só trocando a ordem das duas(trocando a DP de lugar, caso seja uma placa com 3xDP+1xHDMI) -
"Youtubers de Xeon" e a irresponsabilidade com o próprio público
uotlaf respondeu ao tópico de Mr.Robott em Processadores
Se você ver minha opinião no final, vai ver que eu disse justamente que o dever tanto dos youtubers quanto da gente é falar a verdade. Em nenhum momento disse que não acontecia(na verdade até citei um exemplo). A gente deve deixar claro que esses cpus não são pra jogos extremamente cpu-bound. Dá pra jogar alguma coisa? Com certeza. A pessoa não deve esperar que um cpu de 100 reais de 2014 vai executar um jogo de 200-300 reais de 2023-2024 perfeitamente. Quanto aos dois citados, não acho que seria de bom tom eu reclamar de pessoas específicas. O termo "youtubers que fazem isso" já me é suficiente. Ainda tem muito cpu ivy por aí, assim como tem cpus broadwell. Apesar de eu não ter resposta mais a fundo(por falta de documentação) e nem informação sobre a versão atual, o desenvolvedor do loseless scaling indica que eles usam um modelo também pra geração de quadros. Até que ponto isso é verdade, só se ele fizesse uma documentação sobre(como a nvidia fez). Se foi, peço desculpas. Intepretei completamente diferente(até porque ele deixou muito vago pra mim). O DLSS em sí provavelmente seria mais complicado porque ele é gigante e até pra não impactar mais na performance(até porque até onde me lembro o modelo é síncrono com o resto da pipeline, me corrija se eu estiver errado). Mas nada impede de executar um modelo menor via async compute. Não é a melhor solução, mas funciona(não que algum método de interpolação seja a melhor solução também). Eu acho que saímos do assunto da postagem original pra algo não relacionado(gpus e geração de quadros), então acho que irei deixar por aqui mesmo. -
Por que não existe processador Arm para computador de mesa?
uotlaf respondeu ao tópico de Calebones em Processadores
Apesar de ser uma thread antiga, creio que tenho algo a adicionar e a corrigir: Os designs dos cores da própria arm são feitos pra dispositivos assim. Designs de cores podem ser feitos pra alta performance ou para baixo consumo de bateria. Os cores da própria arm são feitos pra dispositivos com baixíssimo tdp e com limitações de arrefecimento muito altas. O que impede as empresas de fazerem cores de alto desempenho com ISA arm é a licença. A arm tem dois modelos grandes de licença para os CPUs: O da ISA e dos cores/IP. Não existe um core de desktop de alta performance arm pra desktop(na verdade existe pra cloud - Os neoverse N, usados nos cpus ampere). Nada impede de ter um cpu arm com socket e imc DDR. Na verdade eles existem: Os ampere são socketeados e tem imc DDR5 de 512 bits. Os cores são design da arm(Neoverse N1). O A18 pro do Iphone 16 pro max é TSMC N3E. Assim como foi com micrômetros, nada impede da gente passar pra angstrom ou picômetro. Além disso, o nome da litografia nada tem a ver com o tamanho dos transistors(pra ter uma ideia, 3 nanômetros tem gate próximo dos 48 nm). O nome da litografia já perdeu o significado faz muito tempo. Hoje em dia todo cpu é uma máquina de microinstruções emulando uma máquina risc ou cisc. Não existe mais essa distinção de "RISC consome menos energia e CISC consegue fazer mais coisas em menos tempo". Toda instrução da ISA alvo é convertida pra microops e deixada em um cache de microops pra uso posterior. Além disso, o preço de decodificação maior dos cisc não tem valor tão significativo e o preço de decodificação de arm é tão custoso quanto. A ISA não importa, quem importa é a implementação e onde o chip vai ser usado. Para informações mais a fundo, recomendo bastante dois artigos da galera do chips and cheese: "ARM or x86? ISA Doesn’t Matter" e "Why x86 Doesn’t Need to Die". Nada impede do 8 elite aguentar windows 11. Inclusive ele aguenta, já que os notebooks com SD X elite teoricamente tem os mesmos cores. Vale lembrar novamente que a ISA não importa - A qualcomm conseguiu a licença da ISA quando comprou a nuvia e está usando pra fazer os próprios designs. Os núcleos oryon - assim como os núcleos que a apple usa nos A e M - não são de design da arm. São designs próprios usando a licença que eles tem. Benchmarks tem que ser feitos usando o mesmo código base em arquiteturas diferentes. Não faz sentido executar código x86 em arm por um emulador e querer que a performance seja a mesma da nativa. Vai dar certo normalmente. Se conseguirem portar a edk pro SD 8 elite(não sei se os chips mobile da qualcomm ainda tem problema com o hipervirtualizador pra impedir a edk) e tiver os drivers corretos faltando pro windows 11, ele vai rodar normalmente assim como roda nos SD X elite de notebook. A ISA é a mesma, não tem porque não rodar Até onde eu me lembre, a samsung não tem uma licença de ISA da arm nem designs customizados. Ela utiliza os cores com design da arm(Licença de IP dos cores). Todos os cpus mobile pra consumidor hoje em dia são focados em entregar o máximo de desempenho dentro do seu limite térmico(tirando os mais baratos, mas aí é por estratégia e segmentação de mercado). Tanto cpus X86 quanto cpus ARM vão tentar segurar o maior clock possível dentro dos limites impostos pelos sensores(seja Tctrl, seja Tdie ou seja Tskin) caso o processo seja single threaded. Não vale a pena cortar o clock pra igualar a todo mundo em um cenário assim. É por isso que cpus de notebook e de celular tem clocks altíssimos mesmo que não cheguem nesse clock por mais de 2 segundos. Vale mais a pena entrar no maior clock possível pra fazer o trabalho o mais rápido possível e entrar em idle. Isso é chamado race to sleep. Isso acontece também em x86. Inclusive x86_64 está dividido em níveis de microarquitetura, e a um tempo algumas distribuições linux estavam estudando a possibilidade de subir os requerimentos pra x86_64 v2 e x86_64 v3. Agora voltando a pergunta original: Por que não existe processador Arm para computador de mesa? - Porque x86 dominou o mercado desde sempre. Seja por ser uma arquitetura bem definida, seja por terem poucas empresas na plataforma. O windows acaba fazendo a plataforma ser padronizada também, já que requer suporte pra UEFI completo. - Arm foi evoluindo pra mobile, onde a gente não tem padrão de nada até chegar no sistema operacional. Android não foi pensado pra ter um padrão do lado do firmware e muito menos o kernel linux. Além disso, a própria arm não tem designs bons pra desktop(os de cloud são caros) e conseguir uma licença da ISA é pra poucos(vide a briga entre a qualcomm e a arm por conta da licença da nuvia). Só agora com o windows pra arm é que as empresas estão pensando em certos aspectos em chips para consumidor(como o firmware em um SPI flash em vez do armazenamento primário) e obrigatoriedade no suporte pra UEFI completo. - Além disso, pra fazer uma placa X86 você precisa de um firmware(tanto a parte proprietária da intel quanto a implementação provavelmente baseada na referência EDK). Existem poucas empresas que fornecem esse serviço(American Megatrends, Phoenix Technologies e talvez alguma outra que eu esqueci). Em arm tu não precisa desse tipo de suporte porque tu provavelmente só vai rodar o u-boot como bootloader secundário e fazer chainload de um kernel em uma partição específica. Celulares e embarcados não foram pensados pra ter uma interface legal e segura no firmware onde tu pode trocar o sistema operacional pro que tu quiser. Eles já são. O que realmente importa pra arm são os dois segmentos que ela atua: O de embarcados+celulares e o de núvem. Nesses dois segmentos, todo programa tem suporte pra aarch64(arm64) ou aarch32(arm32), então não é um problema. Distribuições linux pra esse tipo de hardware tem repositórios com programas open source compilados e empresas podem compilar programas proprietários pra uso nesses hardwares. O problema só existe quando você vai pra uma plataforma com software proprietários feitos pra x86_64(O desktop/laptop, principalmente windows). Apesar disso, a qualcomm e a microsoft continuam fazendo força pra arm chegar no desktop em alguma hora. Essa licença da qualcomm foi e vai ser um ótimo boost pra esse caso. Só falta eles também redesenharem o resto das IPs(principalmente a iGP) e melhorarem a questão de drivers pros socs de laptop. Desculpa o textão. Achei sua pergunta ótima e queria explicar certinho(além de corrigir alguns equívocos dos outros comentários). -
SSD com Windows 11 funcionará em computador sem TPM 2.0?
uotlaf respondeu ao tópico de gkp04 em Windows 11
Porque toda outra plataforma tem uma chain of trust no processo de boot faz anos, menos pcs. Querendo ou não pcs sempre foram vulneráveis a esse tipo de ataque, e ftpm é uma ótima solução Dado o comportamento que a imposição teve e como a microsoft é, faz sentido eles ficarem nesse vai e vem Claro que eles ainda vão ter que suportar cliente enterprise sem ftpm, então a chave pra ignorar ainda vai ficar por muito tempo











Sobre o Clube do Hardware
No ar desde 1996, o Clube do Hardware é uma das maiores, mais antigas e mais respeitadas comunidades sobre tecnologia do Brasil. Leia mais
Direitos autorais
Não permitimos a cópia ou reprodução do conteúdo do nosso site, fórum, newsletters e redes sociais, mesmo citando-se a fonte. Leia mais