

arfneto
-
Posts
6.526 -
Cadastrado em
-
Última visita
Tipo de conteúdo
Artigos
Selos
Livros
Cursos
Análises
Fórum
Tudo que arfneto postou
-
Meu compilador não aceitou bem esse programa Deixe ver Sugiro você fazer uma parte por vez...
-
vou ler em seguida Sobre os theta(i) parece ser uma interpolação linear em torno da série de gdp, mas os valôres de gdp(i) são independentes, mais precisamente GDP de países distintos. Consigo entender talvez a parte formal, mas como isso vai dar algo relevante eu tenho dúvidas... Num dado momento o GDP vai ser Bolivia/Botswana/Brazil/Brunei por exemplo e não entendo o que vai significar interpolar entre valores de GDP desses países. Claro, não pensei muito nisso... adicionado 1 minuto depois fala da função void leArquivocsv(struct gdpperc *pib) ?
-
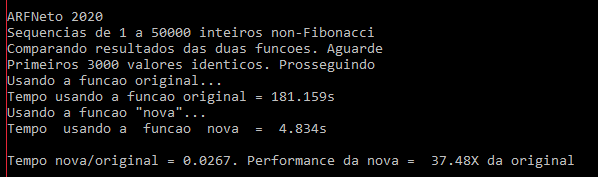
Olá! Como eu imaginava fiquei curioso e escrevi uma função simples para calcular o n-ésimo inteiro "não-Fibonacci", para comparar com aquela folclórica função-título que discutimos. E escrevi uma função para tabular os tempos para alguns milhares de execuções e comparar. Sem surpresas, a função abaixo é algo como 40X mais rápida para os mesmos cálculos: uint64_t non_fib_nova(uint64_t target) { uint64_t non_fib_count = 0, fib_count = 0; uint64_t prev_prev_fib = 0, prev_fib = 1; uint64_t next_fib = 0; uint64_t next_non_fib = 0; uint64_t limit = 0x7fffffffffffffff, i = 0; while (limit > prev_prev_fib) { // segue em frente ate atingir o limite do teste if (i == next_fib) { next_fib = prev_fib + prev_prev_fib; prev_prev_fib = prev_fib; prev_fib = next_fib; fib_count += 1; } else { next_non_fib = i; non_fib_count += 1; }; // if() if (non_fib_count == target) return next_non_fib; i = i + 1; }; // while() return 0; }; // non_fib_nova() A ideia aqui é a mais simples: segue a figura do post anterior. Como se fosse o Crivo de Eratóstenes para um único fator primo: - os números vão passando - se é um número da sequência de Fibonacci passa para o próximo - se não é conta esse número como não-Fibonacci - se é o n-ésimo retorna - se vai estourar o valor retorna zero: só temos 8 bytes Antes de começar a comparar os tempos, o programa chama as duas funções, a original e a "nova" para valores de 1 a 3000 e compara os resultados para ver se está tudo certo: eles devem ser claro os mesmos. Se não forem avisa onde deu diferença para ajudar a testar. Só que não deu. Depois o programa marca o tempo necessário para calcular o n-ésimo não-Fibonacci para N indo de 1 até o limite especificado na linha de comando, ou o padrão na constante _LIMITE_ que aqui era de 50.000, usando primeiro a função original e depois a função "nova". Eis a original e as funções acessórias: uint64_t non_fib_original(uint64_t a) { uint64_t cont = 0, i, res = 0; for (i = 4; cont != a; i++) { if (!isFib(i)) { cont++; res = i; }; // if() }; // for() return res; }; // non_fib_original() bool isFib(uint64_t c) { return ( Square(5 * c * c + 4) || Square(5 * c * c - 4) ); }; // isFib() bool Square(uint64_t x) { unsigned long long int s; s = (unsigned long long int) sqrt((double)x); return (s * s == x); }; // Square() Tem os problemas já discutidos. A única alteração foi usar o tipo typedef unsigned long long int uint64_t; // como em C++ que é o simples int de 8 bytes sem sinal mas com o nome curtinho de C++ e é claro o mesmo usado na outra função. Essa é a função que compara os resultados: bool resultado_identico(int limite) { for (uint64_t i = 1; i < limite; i += 1) { uint64_t original = non_fib_original(i); uint64_t novo = non_fib_nova(i); if (novo != original) { printf( "valores diferentes retornados para N=%llu\n", i); printf("original: %llu\n", original); printf(" \"nova\": %llu\n", novo); return false; }; // if() }; // for() return true; }; // resultado_identico() Nada especial mesmo: apenas chama as duas funções e compara o valor de retorno. A função de teste double testa_funcao(uint64_t(*funcao)(uint64_t), uint64_t limite) { uint64_t v; clock_t tempo = clock(); for (uint64_t target = 1; target <= limite; target += 1) v = (*funcao)(target); tempo = clock() - tempo; return (double)(tempo) / CLOCKS_PER_SEC; }; // testa_funcao() A lógica é primária: um loop de 1 até o limite chama a função cujo endereço veio por parâmetro, e retorna o tempo decorrido em segundos... Um resultado Eis o simples main() para o programa de teste int main(int argc, char** argv) { double secsA, secsB; uint64_t limite = _LIMITE_; if (argc > 1) limite = (uint64_t) atoll(argv[1]); printf( "\nARFNeto 2020\nSequencias de 1 a %llu inteiros non-Fibonacci\n", (uint64_t) limite); printf("Comparando resultados das duas funcoes. Aguarde\n"); if (resultado_identico(3000)) printf("Primeiros 3000 valores identicos. Prosseguindo\n"); else { printf("Valores nao coincidem. Verifique. Abortando\n"); exit(-1); }; // if() printf("Usando a funcao original...\n"); secsB = testa_funcao(non_fib_original, limite); printf("Tempo usando a funcao original = %6.3fs\n", secsB); printf("Usando a funcao \"nova\"...\n"); secsA = testa_funcao(non_fib_nova, limite); printf("Tempo usando a funcao nova = %6.3fs\n", secsA); printf( "\nTempo nova/original = %6.3g. Performance da nova = %6.2fX da original\n", secsA/secsB, (secsB/secsA)); }; // end main() O programa de teste inteiro #pragma once #include "math.h" #include <stdbool.h> #include "stdio.h" #include "stdlib.h" #include "time.h" #define _LIMITE_ (50000) typedef unsigned long long int uint64_t; // como em C++ bool isFib(uint64_t); uint64_t non_fib_nova(uint64_t); uint64_t non_fib_original(uint64_t); bool resultado_identico(int); bool Square(uint64_t); double testa_funcao(uint64_t (*f)(uint64_t), uint64_t l); int main(int argc, char** argv) { double secsA, secsB; uint64_t limite = _LIMITE_; if (argc > 1) limite = (uint64_t) atoll(argv[1]); printf( "\nARFNeto 2020\nSequencias de 1 a %llu inteiros non-Fibonacci\n", (uint64_t) limite); printf("Comparando resultados das duas funcoes. Aguarde\n"); if (resultado_identico(3000)) printf("Primeiros 3000 valores identicos. Prosseguindo\n"); else { printf("Valores nao coincidem. Verifique. Abortando\n"); exit(-1); }; // if() printf("Usando a funcao original...\n"); secsB = testa_funcao(non_fib_original, limite); printf("Tempo usando a funcao original = %6.3fs\n", secsB); printf("Usando a funcao \"nova\"...\n"); secsA = testa_funcao(non_fib_nova, limite); printf("Tempo usando a funcao nova = %6.3fs\n", secsA); printf( "\nTempo nova/original = %6.3g. Performance da nova = %6.2fX da original\n", secsA/secsB, (secsB/secsA)); }; // end main() // // retorna 0 se passou dos limites, ou o N-esimo inteiro // nap-Fibonacci // uint64_t non_fib_nova(uint64_t target) { uint64_t non_fib_count = 0, fib_count = 0; uint64_t prev_prev_fib = 0, prev_fib = 1; uint64_t next_fib = 0; uint64_t next_non_fib = 0; uint64_t limit = 0x7fffffffffffffff, i = 0; while (limit > prev_prev_fib) { // segue em frente ate atingir o limite do teste if (i == next_fib) { next_fib = prev_fib + prev_prev_fib; prev_prev_fib = prev_fib; prev_fib = next_fib; fib_count += 1; } else { next_non_fib = i; non_fib_count += 1; }; // if() if (non_fib_count == target) return next_non_fib; // achou! i = i + 1; }; // while() return 0; }; // non_fib_nova() uint64_t non_fib_original(uint64_t a) { uint64_t cont = 0, i, res = 0; for (i = 4; cont != a; i++) { if (!isFib(i)) { cont++; res = i; }; // if() }; // for() return res; }; // non_fib_original() bool resultado_identico(int limite) { for (uint64_t i = 1; i < limite; i += 1) { uint64_t original = non_fib_original(i); uint64_t novo = non_fib_nova(i); if (novo != original) { printf("valores diferentes retornados para N=%llu\n", i); printf("original: %llu\n", original); printf(" \"nova\": %llu\n", novo); return false; } }; // for() return true; }; // resultado_identico() bool isFib(uint64_t c) { return ( Square(5 * c * c + 4) || Square(5 * c * c - 4) ); }; // isFib() bool Square(uint64_t x) { uint64_t s; s = (uint64_t) sqrt((double)x); return (s * s == x); }; // Square() double testa_funcao(uint64_t(*funcao)(uint64_t), uint64_t limite) { uint64_t v; clock_t tempo = clock(); for (uint64_t target = 1; target <= limite; target += 1) v = (*funcao)(target); tempo = clock() - tempo; return (double)(tempo) / CLOCKS_PER_SEC; }; // testa_funcao() // fim de compare.c Não tive tempo de testar isso, mas parece que Square() pode ter um erro de arredondamento e dar erro na comparação no return em algum caso. Se alguém puder testar e postar o compilador e as opções em uso... De todo modo não há razão para usar Square() afinal bool Square(uint64_t x) { uint64_t s; s = (uint64_t) sqrt((double)x); return (s*s == x); }; // Square()

-
fascinante. É uma série convergente? Mas se os dados são os mesmos theta calcula o que? Aí sim Não são nem 200 linhas, não entendo porque selecionar por número. Até entenderia se o usuário oferece uma lista de países ou um critério baseado no GDP ou LSI, tipo os 30 com maor índice ou um cruzamento para tentar mostrar alguma correlação entre GDP e LSI. Mas um simples número que vai acabar na ordem alfabética parece bobagem. Não vai ensinar nada em termos de C ou de estatística Não acho que precise de mais de uma struct, eu já disse. Já sabe como calcular o valor que está faltando?
-
Melhor alocar uma a uma no formato da saida. Uma só. Não vejo a necessidade de mais de uma. E não precisa salvar esses dados dos csv. Apenas processe linha a linha como te falei no primeiro post Entendeu o que eu disse sobre usar free() na linha seguinte ao malooc()? Não faz sentido. Agora não entendi mesmo. Qual o propósito de repetir 50 a 100 vezes os mesmos cálculos para o mesmo país? Pois é. Ainda não estão assim bons, mas ao menos são formalmente corretos.
-
Olá! Muito ruim esse enunciado. Acho que podiam pensar um pouco mais formalmente ao escrever uma especificação de exercício. os dados devem ser pré-processados? Então você recebeu por exemplo esse gdp.csv junto com o enunciado? Ou instruções de como obter isso? Sério? Está errado. Acho que já entendeu que um arquivo CSV é uma tabela (X,Y) e TODAS as X linhas tem Y colunas. Por definição desde sempre. Se tem uma linha inicial com o total de países não é um arquivo CSV Se você vai alocar dinamicamente um vetor de structs, digamos com uma para cada país, não precisa saber antes o valor de N: basta esperar acabar o arquivo de entrada, por definição. Repetir entre 50 e 100 vezes quer dizer o que? Não vai ter uma única linha para cada país? Isso quer dizer entre 50 e 100 países? Sua tabela parece ter 189 países. Não é fixo? Life Satisfaction Real está no arquivo de entrada. E o Life Satisfaction Calculado deve ser algo que você aprendeu, certo? E deve ter um valor de theta envolvido já que aparece em seu código. Esse é o valor de theta mencionado aqui: A última linha deve ter o EAM do LS? OK, então a saída não é um arquivo CSV também... De todo modo o calculo é trivial: apenas a média das diferenças em módulo dos índices para cada país. Sobre seu programa: Não sou eu quem vai julgar seu trabalho, se isso é um projeto de escola, mas alocar dinamicamente um vetor de structs não é bem alocar EXATAMENTE 189 no início do programa e pronto. E você aloca e libera na linha seguinte. Que pretende? Se liberou não vai usar mais... A ideia é: - você define uma struct igualzinho ao que vai ter na saída - aloca uma ao ler cada país, - preenche com o que tem de dados - calcula o que falta: o LFC - acumula a diferença em módulo pra calcular o EAM no final - e repete isso para cada país Depois ao final - grava o header do csv - grava uma linha do csv para cada struct do seu vetor - chama free() e libera as structs - calcula o EAM e grava na última linha, de modo que seu CSV não será mais um csv Eis a definição de csv direto do IETF https://www.ietf.org/rfc/rfc4180.txt Note que não é um standard IETF porque o formato já estava estabelecido décadas antes do IETF, já que o I é de ... internet. Teve uma discussão sobre isso semanas atrás nesse mesmo forum, e tem lá mais alguns exemplos e detalhes, Não foi algo assim produtivo, mas pode ser útil
-
No caso desse problema estruturas de dados não se aplicam. Por outro lado esse é um exemplo clássico para introduzir uma estrutura de dados, e acho que já foi até discutido aqui: implementar uma classe ou uma biblioteca para tratar números de, digamos, 1.000 dígitos para poder usar com essas sequências numéricas, já que são sequências infinitas e um int não vai assim muito longe Não. Não. Leu mesmo os post anteriores ? Por definição existem (fib(N-1) -1) elementos aí. É a simples definição da série! Esse desenho vai te dar uma ideia melhor de como seria um programa desses. Na primeira linha está o início da sequência de Fibonacci para manter o foco neles. Na segunda linha você tem a sequência dos inteiros até 21 inclusive, com os números da sequência de Fibonacci em vermelho e os outros em preto. E nas linhas 3 4 e 5 você vê que o comprimento da sequência de números não-Fibonacci cresce com uma regra bem clara. A que eu disse. Então um programa mais simples e barato em termos de recursos para calcular o n-ésimo valor não Fibonacci simplesmente vai passando pelos números inteiros e acompanhando a série: ao atingir um valor "Fibonacci" calcula o próximo. Ao atingir um valor "Não-Fibonacci" verifica a contagem. Se achou o tal n-ésimo mostra e encerra. Só isso. E quando para? Sem a estrutura de dados tem que parar quando estourar o valor de long long int
-
Olá! Você já tem dois exemplos ao menos. E na internet http://www.cplusplus.com/reference/iomanip/ está a referência para algumas dessas funções. Tem em exemplo do que quer fazer? São simples filtros.
-
Bem, o que seria o " caminho das pedras" o @Flávio Pedroza já explicou. E é só usar a fórmula. E se você não conhece a fórmula e não sabe como derivar tal fórmula, seria o caso de estudar matemática, mais precisamente Teoria dos Números, e não programação. E se você conhecesse a fórmula seria tentado a usar esse método afinal. Eu estudei mas não me lembrava dela afinal vergonha Agora tenho dúvidas de que esse código seja de fato eficiente ou enxuto. Usar um contador para achar o próximo número é inevitável. Mas chamar duas funções, Square() para saber se um número é um quadrado perfeito e IsFib() para saber se ele faz parte da sequência de Fibonacci é exagerado e não enxuto. Quando der um tempo eu vou escrever e postar uma comparação dos tempos gastos para calcular algo como os primeiros 5000 deles usando esse método e outro mais ortodoxo que vou descrever a seguir. Mas eu acho que essa ideia não é assim o máximo. Talvez seja mesmo meio besta. Vou explicar Square() bool Square(long long int x) { long long int s; s = sqrt(x); return (s * s == x); } Chamar uma função já sai caro por si só: tem que salvar o contexto, empilhar parâmetros e uma série de coisas. Mas lendo essa aí você vê: um long long int tem em geral 8 bytes. sqrt() é: double sqrt (double x); então você tem uma conversão de x para double: sqrt(x) depois tem outra conversão de double, o retorno de sqrt() para long long int: s = sqrt(x) depois tem uma multiplicação de dois long long int, de 8 bytes cada um (s*s) e esse resultado é guardado em uma variável temporária long long int para ser comparado com x: (s*s == x) Nada eficiente na verdade. Nadinha.E numa série baseada em simples somas... IsFib() bool isFib(long long int c) { return (Square(5 * c * c + 4) || Square(5 * c * c - 4)) ; } aqui você tem uma expressão complexa, e alguém vai pagar a conta. O mais tosco nesse caso é calcular potencialmente duas vezes 5 * c * c em metade dos casos. Sério? Quando a gente trata programação numérica de sequências --- que como se sabe são infintas --- em geral se pensa com mais cuidado ao escrever código que vai rodar milhões de vezes. Seria claro mais esperto calcular 5*c*c uma vez, já que não vai mudar em uma linha ou em uma vida. E depois retornar 1 para + ou - 4 ser um quadrado perfeito. Algo como bool isFib(long long int c) { long long int produto = c * c * 5; if( Square(produto-4) ) return true; if( Square(produto+4) ) return true; return false; //return (Square(5 * c * c + 4) || Square(5 * c * c - 4)) ; } Mas o melhor é nem escrever isFib() ou Square() Exemplo para 233, o #13 na sequência 5*233*233 = 271.445. E 521*521 = 271.441. Claro, 271.441 = (271.445 - 4). E a função claro iria mostrar isso porque é apenas a fórmula. Ou seja, vai fazer duas vezes a conta toda, incluindo chamar duas vezes Square() já que ela testa por +4 primeiro. Mais um pouco de teoria Conforme aumenta o valor de c, o número na sequência de Fibonacci, os números vão ficando muito, mas muito mais distantes entre si., o que se pode ver na própria fórmula, que estará pertinho de sqrt(5*c*c) já que o 4 vai ser cada vez menos significativo. Em apenas 13 números o produto já está em 271.000 afinal. E o 4 não muda. Afinal o próximo número é dado pela soma dos anteriores, certo? Conforme os tais anteriores aumentam... Pensando em C ou FORTRAN ou qualquer outra linguagem Se o próximo número na sequência é dado pela soma dos dois números anteriores, nesse caso dois inteiros de 8 bytes. Simples assim. Em termos de CPU é a conta mais barata. Sem funções de biblioteca, sem doubles, nada. Conforme segue a sequência os números vão se afastando rapidamente. Não importa quantos já foram. Importa o próximo. E entre eles temos um certo número de alvos não Fibonacci que são o nosso objetivo. Um número grande, crescente.Sabe qual é né? O penúltimo na sequência, por definição. Ex: 89, 144, 233 na sequência. entre 144 e 233 tem... 88. É a definição da série. Então se tivermos uma função que devolve o próximo número da sequência ela já serve como limitante naquele for em main(). Não precisa de mais nada exceto contar de um em um até esse próximo número. Sem chamar mais funções, chamar funções de biblioteca com argumentos e retorno double, sem chamar uma OUTRA função para saber se um inteiro é um quadrado perfeito.... Semanas atrás postei uma função aqui que faz exatamente isso: devolvia o próximo número na sequència, mas você não deve ter dificuldade em escrever uma. Pode pesquisar aqui por isso entre as coisas que eu postei. Não estou agora com esse material. Estou de férias mas depois vou escrever esse programa de comparação para a gente ver a diferença ao calcular para digamos 100.000 números e ter uma noção da diferença de tempo entre um caso e outro. Mas provavelmente é como estou dizendo. Essa solução não é enxuta. Nem eficiente. essa ideia não era boa não: esse problema não tem memória. Você não precisa de um vetor. Só precisa do valor de N. Em especial porque estamos falando de uma série infinita. Você só precisa do valor do próximo número da sequência de Fibonacci, e de um indicador de quantos elementos não Fibonacci já passaram pelo seu programa. Se teve paciência de ler o que eu escrevi até aqui já deve ter entendido isso... Ou pergunte de novo e vamos escrever juntos um programa que compara. adicionado 8 minutos depois Ok, uma ajuda do Google: pesquisando por fibonacci + "Clube do Hardware" arfneto E temos o post E lá tem mais um pouco de números, e a função de que eu falei. E um programa de teste
-
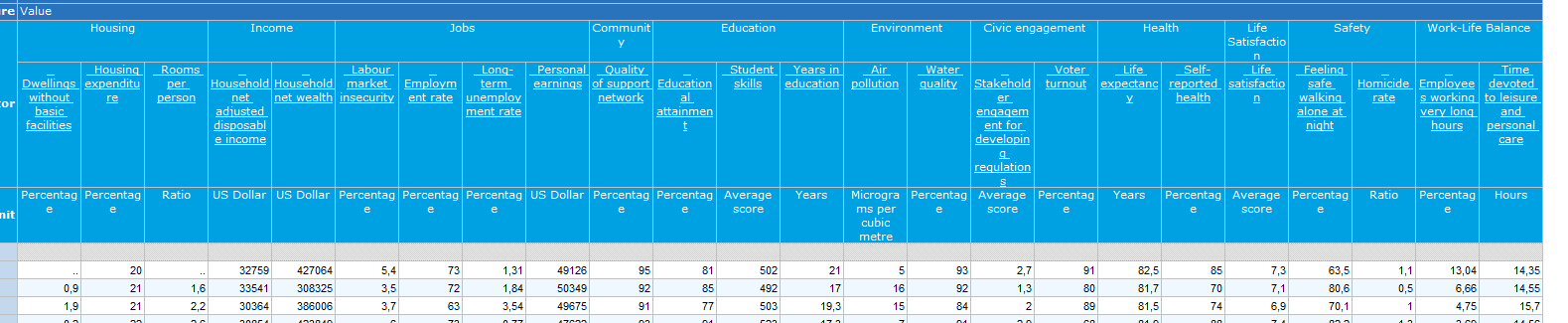
Aí sim! O problema da planilha do bli é que há nada menos que tres línhas de títulos, por questão de agrupamento da visualização. E faz sentido. Mas na hora de importar é melhor você simplesmente numerar um a um e colocar talvez um texto mais significativo y nas colunas de que precisa Aquele que eu te mostrei está correto...
-
No primeiro arquivo pra que serve o campo Header, que vale Unit para TODOS os registros? Porque dois campos idênticos para Country? Qual o sentido da primeira linha do segundo arquivo? Todos os campos tem o mesmo nome Shaded cells indicate IMF staff estimates;Shaded cells indicate IMF staff estimates;Shaded cells indicate IMF staff estimates;Shaded cells indicate IMF staff estimates;Shaded cells indicate IMF staff estimates;Shaded cells indicate IMF staff estimates Você ao menos tentou importar isso no Sheets como eu te expliquei?
-
Tem que colocar os cout dentro do loop. Como escreveu só vai mostrar ao final mesmo que sejam 20 números adicionado 1 minuto depois Deu a solução correta porque testou com n=1.
-
Não, não deu certo... Testou mesmo isso? Precisa mostrar algo do que está fazendo ao menos para saber o que está testando... Como não está usando uma função para os testes precisa zerar os valores de k entre cada execução, já que está fazendo as contas direto em main. E precisa mostrar o vetor antes de ir para o próximo. Do jeito que escreveu só vai mostrar depois de calcular para todos os n. Entendeu a alternativa recursiva? adicionado 10 minutos depois Algo assim para a versão sem recursão void teste_normal() { int n{}; long v{}; int k[10]{ }; cout << "Total de numeros para esse teste: "; cin >> n; cout << endl << "Testando para " << n << " valores\n\n"; for (int i = 1; i <= n; i = i + 1) { cout << "Entre numero " << i << " de " << n << endl; cin >> v; for (int i = 0; i < 10; i = i + 1) k[i] = 0; do { k[v % 10] += 1; v = v / 10; } while (v > 0); for (int i = 0; i < 10; i = i + 1) cout << "[" << i << ":" << k[i] << "] "; cout << endl; } // for return; } // teste_normal() E assim para a versão recursiva void teste_recursivo() { int n{}; long v{}; cout << "Total de numeros para esse teste: "; cin >> n; cout << endl << "Testando para " << n << " valores\n\n"; for (int i = 1; i <= n; i = i + 1) { cout << "Entre numero " << i << " de " << n << endl; cin >> v; conta_digito(v); } // for }; // teste_recursivo() E a função em si void conta_digito(long v) { static int k[10]{ }; static int primeiro = 1; if (primeiro == 1) { if (v == 0) k[0] = 1; // especial: 0 primeiro = 0; cout << "Para o valor " << v << ": "; }; // if if (v == 0) { for (int i = 0; i < 10; i = i + 1) cout << "[" << i << ":" << k[i] << "] "; cout << endl; for (int i = 0; i < 10; i = i + 1) k[i] = 0; return; } else { k[v % 10] += 1; conta_digito(v / 10); }; // if }; // conta_digito() Atente para as diferenças
-
Porque ficaria? Eis o que você tem que conferir: o que é k? static int k[10]{}; Então k é um array de int, 10 deles, que você vai acessar de k[0] a k[9]. E as {} indicam que foi inicialmente carregado todinho com zeros... v%10 vai te dar o resto da divisão de v por 10 então é um número entre zero e nove e não tem como dar erro ao somar 1 você pode ter claro overflow se ficar somando 1 até k passar de INT_MAX mas isso não é exatamente "lixo na memória" e sim uma exceção aritmética. Em relação ao seu código só dá pra dizer o que houve se você postar o programa em si. Mas em geral isso é devido a uma questão de escopo da variável como por exemplo quando você declara uma variável de controle dentro de um loop e tem outra igualzinha declarada fora dele... A variável "vive" dentro do par mais interno de {}
-
Já vi esse exercício muitas vezes em vários formatos para várias linguagens. Sempre a ideia é a mesma e é essa que descreveu: fazer as contas. Ler como string é absolutamente trivial e não ensinaria nada... bastaria ir varrendo a string e colocando no vetor. ao dividir por 10 você não obtem o resto, obtem o quociente. O resto você tem usando módulo %. E aí você divide por 10 e faz de novo. E de novo. E de novo até ficar com zero.... Te dei um exemplo do loop em detalhes usando o 224. E o código para uma função recursiva. O main() que postei funciona direitinho para a função conta_digito() e dá o resultado que mostrei. Um loop para a solução mais comum, não recursiva, seria algo como int n{}; long v{}; int k[10]{ }; cout << "Total de numeros para esse teste: "; cin >> n; cout << endl << "Testando para " << n << " valores\n\n"; for (int i = 1; i <= n; i = i + 1) { cout << "Entre numero " << i << " de " << n << endl; cin >> v; cout << "Para o valor " << v << ": "; do { k[v % 10] += 1; v = v / 10; } while (v > 0); for (int i = 0; i < 10; i = i + 1) cout << "[" << i << ":" << k[i] << "] "; cout << endl; } // for que também funciona Total de numeros para esse teste: 1 Testando para 1 valores Entre numero 1 de 1 224 Para o valor 224: [0:0] [1:0] [2:2] [3:0] [4:1] [5:0] [6:0] [7:0] [8:0] [9:0] Qual parte está mais complicado de entender? Não precisa considerar a rotina recursiva, apesar de ela fazer o programa ficar simples mas uma implementação seria que também funciona direitinho. Tem sempre a pegadinha do zero como te expliquei... De todo modo eis uma que funciona void conta_digito(long v) { static int k[10]{ }; static int primeiro = 1; if (primeiro == 1) { if (v == 0) k[0] = 1; // especial: 0 primeiro = 0; cout << "Para o valor " << v << ": "; }; // if if (v == 0) { for (int i = 0; i < 10; i = i + 1) cout << "[" << i << ":" << k[i] << "] "; cout << endl; return; } else { k[v % 10] += 1; conta_digito(v / 10); }; // if }; // conta_digito() Pergunte exatamente pelo trecho que não entendeu e tento explicar melhor
-
Acho que não entendeu. A função de exportação do site original está ERRADA. Do BLI. Não vai funcionar. Se sabe como fazer exporte do site para o Excel e no Excel simplesmente corrija o valor do header na linha 1/2/3: a linha 1 tem que ter exatamente 17 campos, que é o que tem nas outras 3000 linhas.... Depois de reparar o erro exporte a SUA planilha corrigida como um CSV e use em seu programa. E o último campo da linha 1 pra ajudar já te falei que tem que ser o 14,35 O outro arquivo tem que ser corrigido também, o de 7 campos. Tem que ficar como os exemplos que te mostrei. Para testar o seu programa bastam dois arquivos de duas linhas cada um. Acho que já entendeu isso. Um com 17 campos e outro com 7 campos, e podem ser numerados como os exemplos que te dei... adicionado 33 minutos depois Talvez não tenha familiaridade com essas ferramentas, então eis dois arquivos corrigidos mas com poucos dados O BLI só com dois países Country;;;1;2;3;4;5;6;7;8;9;10;11;12;13;14;15;16;17;18;19;20;21;22;23;24 Australia;;;..;20;..;32759;427064;5,4;73;1,31;49126;95;81;502;21;5;93;2,7;91;82,5;85;7,3;63,5;1,1;13,04;14,35 Austria;;;0,9;21;1,6;33541;308325;3,5;72;1,84;50349;92;85;492;17;16;92;1,3;80;81,7;70;7,1;80,6;0,5;6,66;14,55 E o outro com dados de alguns países incluindo, claro, esses dois Country;Subject Descriptor;Units;Scale;Country/Series-specific Notes;2015;Estimates Start After Afghanistan;Gross domestic product per capita, current prices;U.S. dollars;Units;See notes for: Gross domestic product, current prices (National currency) Population (Persons).;599.994;2013 Albania;Gross domestic product per capita, current prices;U.S. dollars;Units;See notes for: Gross domestic product, current prices (National currency) Population (Persons).;3,995.383;2010 Algeria;Gross domestic product per capita, current prices;U.S. dollars;Units;See notes for: Gross domestic product, current prices (National currency) Population (Persons).;4,318.135;2014 Angola;Gross domestic product per capita, current prices;U.S. dollars;Units;See notes for: Gross domestic product, current prices (National currency) Population (Persons).;4,100.315;2014 Antigua and Barbuda;Gross domestic product per capita, current prices;U.S. dollars;Units;See notes for: Gross domestic product, current prices (National currency) Population (Persons).;14,414.302;2011 Argentina;Gross domestic product per capita, current prices;U.S. dollars;Units;See notes for: Gross domestic product, current prices (National currency) Population (Persons).;13,588.846;2013 Armenia;Gross domestic product per capita, current prices;U.S. dollars;Units;See notes for: Gross domestic product, current prices (National currency) Population (Persons).;3,534.860;2014 Australia;Gross domestic product per capita, current prices;U.S. dollars;Units;See notes for: Gross domestic product, current prices (National currency) Population (Persons).;50,961.865;2014 Austria;Gross domestic product per capita, current prices;U.S. dollars;Units;See notes for: Gross domestic product, current prices (National currency) Population (Persons).;43,724.031;2015 Azerbaijan;Gross domestic product per capita, current prices;U.S. dollars;Units;See notes for: Gross domestic product, current prices (National currency) Population (Persons).;5,739.433;2014 The Bahamas;Gross domestic product per capita, current prices;U.S. dollars;Units;See notes for: Gross domestic product, current prices (National currency) Population (Persons).;23,902.805;2013 Bahrain;Gross domestic product per capita, current prices;U.S. dollars;Units;See notes for: Gross domestic product, current prices (National currency) Population (Persons).;23,509.981;2014 Assim pode entender e desenvolver seu programa... Note que a vírgula foi substituída por ';' e acho que sabe porque... Estou usando uma máquina em que o ponto decimal está configurado para ',' e assim ao exportar os dados claro que tinha que usar outro delimitador... No Brasil se exportar campos numéricos como csv teria que por os dados entre aspas porque o ponto decimal aqui é vírgula. Eu assino o Office 365 mas a versão que está nesse micro é em inglês. Uma zona. Talvez a versão em português use as aspas. O que você tem que fazer? Se quiser apenas troque o nome dos campos na primeira linha para o que quer usar em seu programa, se for importante
-
Entendeu o que te expliquei? Tem até uma parte do código lá. E a descrição do algoritmo. Note que ler os números como string vai contra o enunciado. O objetivo do exercício é justamente testar essa habilidade no aluno, de separar os dígitos usando operações. Ler como string e varrer os índices não acrescentaria nada em termos de aprendizado...
-
Você entendeu o que eu expliquei? Entendeu que os dados estão ERRADOS? Em formato E conteúdo? Você tinha tentado ao menos ler o conteúdo daqueles arquivos? Você tem um arquivo com 17 campos e outro com 7. Os campos --- se os arquivos estivessem ok --- seriam separados por virgula e fscanf() pode tratar isso quase no automático. Você sequer precisa importar os CSV na verdade. Nenhum dos dois. De todo modo seria mais fácil você especificar formalmente o resultado que espera. No geral: Você vai ter um arquivo mestre, provavelmente o de 7 campos, e vai completar com algo que vai ler do outro, imagino. Os campos que vai ler de cada arquivo são separados por vírgula (deveriam ser) Exemplo: "Work-Life Balance: Time Devoted to leisure and personal care (in hours)" Para a Austrália está definido como 14,35 horas no BLI, e é o campo 17. Em todas as linhas. Só isso. A linha da Austrália é a primeira, e o nome do país é o primeiro campo. Então basta abrir o arquivo, encontrar o país (campo 1) e encontrar os dados de que precisa na linha do país, contando as vírgulas até o valor e pronto. claro que você pode criar uma estrutura para cada tabela e importar direitinho todos os dados, mas se não vai fazer um trabalho extenso com isso não há razão. Apenas leia os dados e derive sua tabela.
-
Sim. Ou quase isso. Sobre o primeiro arquivo: A função de exportação do Better Life Index está errada. Então você precisa corrigir por sua conta. O gênio que programou aquilo não percebeu que os títulos das colunas iriam se perder e zoar o CSV, e não está exportando quase nada dos dados. A culpa no entanto é de quem distribuiu os títulos dos campos por nada menos que TRÊS linhas. Claro que ia dar m#$%a. Não perca seu tempo com esse. Veja o que tem em seu arquivo para a Austrália: "AUS","Australia","JE_LMIS","Labour market insecurity","L","Value","TOT", "Total","PC","Percentage","0","Units",,,5.4,, E o que tem no BLI Seu arquivo não só para na coluna I como ainda zera a J com aquele ,, e os dados vão até AA, 17 colunas No entanto parece que o XML e a planilha excel exportada estão ok, apesar do formato estar errado também e dar uma série de mensagens. No Excel online não abre. A versão desktop acaba abrindo, ao menos a última versão de Excel que é a única que eu tenho. E a partir do Excel se pode gerar o csv correto e continuar com o seu programa... Ou usar o XML. O segundo arquivo Esse tem apenas 7 colunas mas o arquivo CSV não tem sequer os delimitadores. Tem os mesmos problemas para abrir com o Excel mas acaba abrir e aí pode gerar um csv correto Porque não posta a especificação do resultado que quer? Quer um filtro? uma projeção?
-
Não. Apenas use esses programas --- qualquer programa que leia csv --- para refinar os seus arquivos de entrada pois estão errados. Um programa de computador é muito mais flexível, em especial porque você mesmo o está escrevendo. Uma vez que tenha os arquivos no formato correto. No Google Sheets é mais fácil importar seus dados que no Excel. Importar dados no Excel --- ou no Office de um modo geral ------ é muito mais flexível, tem uma espécie de assistente. Excelente quando precisa disso, mas aqui não é o caso. Basta File | Import | Upload e pode até arrastar o arquivo csv para a janela do Sheets. Difícil competir. Entendeu a diferença entre o arquivo que te mostrei e os arquivos que você tem? O segundo por exemplo é praticamente inútil. Como extraiu esses dados? Tem os arquivos originais? O primeiro tem todos aqueles campos duplicados, de pouco serve também. Se não tem mais acesso aos originais talvez possa -- se encontrar um padrão --- corrigir os arquivos de entrada antes de importar em seu programa, usando uma fase inicial em seu programa C. Como te disse, esse era o pen drive dos anos 70/80 e a gente usava isso para muitas coisas. Coisas como mala direta, bancos de dados e programas de escritório. Se o seu delimitador é ou pode ser a ', ' e pode colocar aspas nos campos que tem espaço qualquer programa trata isso. De um banco de dados Oracle ao seu programa da PIMACO de imprimir etiquetas, que naquela época vinha gravado em um diskette de 1.44 megabyte Mas tem que seguir o formato: valores separados por vírgula. Cada linha é um registro. A primeira linha em geral é especial e tem os nomes dos campos. Um número idêntico de campos existe em cada linha. Valores que não estão presentes são indicados por delimitadores consecutivos. O delimitador em geral é a vírgula, o C de CSV. O S é de separados e o V de valores, Comma Separated Values. Postei muitos detalhes sobre isso em um tópico recente aqui neste forum Novo Exemplo Esse arquivo "Campo 1", "Campo 2", "Campo 3" 1,2,3 ,, 1,,3 ,,3 Gera Assim recomendo voltar aos seus arquivos de entrada e colocá-los de acordo com o formato. Se quer escrever o programa em C ou C++ primeiro também pode ser, e pode postar aqui se precisar de algo. Apenas não vá testar com os seus arquivos originais porque eles tem problemas. Qualquer programa gera csv. Pode criar uma planilha em excel com seus valores válidos e testar assim seu programa C. Você sabe o que deveria estar naqueles dois arquivos CSV que postou. Os dados. Só isso. E não é isso que está lá.
-

C Código que leia e ordena os valores numa matriz bidimensional
arfneto respondeu ao tópico de Matheus Penha em C/C#/C++
Os valores, 16 no seu caso, serão classificados e colocados na matriz, então tanto faz. Note que 2 linhas e duas colunas tem então 4 elementos e não 16. Melhor considerar 4 x 4... Os elementos da matriz estarão lá na memória de todo modo, um depois do outro. Agora a matriz é endereçada POR LINHA em C. Então você precisa definir o que é ordenar a matriz no seu caso... 1 2 3 4 5 6 ou 1 3 5 2 4 6 Certo? Se for ordenar por linha então não precisa fazer nada: basta ordenar a partir do endereço inicial do vetor/matriz. Mas se vai ordenar por coluna o mais fácil é copiar a matriz para uma nova já na ordem e ir colocando os caras por coluna... int a[4][4]; int* pA = a; Se for ordenar por linha pode usar o ponteiro pA e classificar os 16 elementos de *(pA) até *(pA+15). Ou mesmo de *a até *(a+15) que é a mesma coisa -
Acho que antes precisa dar uma olhada nos dados que tem e ver como foi extraído cada um desses arquivos. CSV é um formato absolutamente estabelecido e era algo como o pen-drive dos anos 70. Importei seus dados em uma planilha, o meio mais simples de conferir. File | Import | upload no Google Sheets por exemplo leva segundos... A primeira linha tem o nome dos campos. Depois temos uma linha para cada registro, somente com os dados. Veja o seu caso: Arquivo 1 "LOCATION","Country","INDICATOR","Indicator","MEASURE","Measure","INEQUALITY", "Inequality","Unit Code","Unit","PowerCode Code","PowerCode","Reference Period Code", "Reference Period","Value","Flag Codes","Flags" esta é a linha dos campos (com umas quebras de linha pra facilitar a leitura). Como há campos com espaços então precisa mesmo das aspas. O delimitador claramente é a vírgula, mas vendo os campos fica claro que tem algo errado: aparecem campos duplicados e na linha de dados a situação não é melhor... A correspondência entre campos e dados é claro de 1 para 1, mas veja a linha para a Australia: "AUS","Australia","HO_BASE","Dwellings without basic facilities", "L","Value","TOT","Total","PC","Percentage","0", "units",,,1.1,"E","Estimated value" Nessa linha só deve ter dados... Arquivo 2 Esta é a linha dos campos (com umas quebras de linha pra facilitar a leitura) Country Subject Descriptor Units Scale Country/Series-specific Notes 2015 Estimates Start After E veja uma linha de dados Afghanistan Gross domestic product per capita, current prices U.S. dollars Units See notes for: Gross domestic product, current prices (National currency) Population (Persons). 599.994 2013 Qual seria o delimitador? Como um programa vai extrair esses dados? Exemplo de um arquivo válido Compare com isto nome,"O endereco", "valor do lote" "Nome 1", "Rua 1", "1.000.000" "Nome 2", "Rua 2", "2.000.000" "Nome 3", "Rua 3", "1.030.000" "Nome 4", "Rua 4", "1.400.000" E veja o resultado numa planilha do Sheets: Viu o efeito das aspas e a mecânica? Seus arquivos tem que ter esse comportamento antes de você programar qualquer coisa. O tratamento desses arquivos em C ou qualquer outra linguagem é simples. Não acho que precise de qualquer biblioteca exceto por exemplo stdlib.h ou string.h Mas precisa rever os dados.
-
Bem, seu exemplo não tem a ver com string nem com o título do tópico. Trata-se apenas de tabelar a ocorrência dos dígitos em um vetor e mostrar, para um conjunto de N números. Por outro lado você até mostrou um vetor k[] mas não usou no seu programa, declarando ao contrário 10 variáveis e deixando tudo mais difícil... E leu um valor inteiro k e depois acessou n como se fosse n um vetor... Não entendi. Talvez pudesse escrever mais sobre seu código. De todo modo vou te mostrar duas outras soluções para você considerar. Com essas variáveis: int n{}; // o total de numeros que vai ler long v{}; // o numero que esta testando no momento int k[10]{ }; // o vetor que marca os digitos Duas soluções Vou te mostrar duas possibilidades pra escrever isso: veja o caso do exemplo 224: Primeiro caso, para 224 224 = 220 + 4, e temos o primeiro dígito: 4. O operador % --- módulo --- vai te dar exatamente isso: 224 % 10 vai ser o resto da divisão de 224 por 10, 4, e você pode somar 1 em k[4] escrevendo k[224%10] += 1; Então resolvido o primeiro dígito. Aí divide 224 por 10 e tem 22. 22 % 10 vale 2 então em C k[22%10] += 1; Resolvido mais um dígito. Então divide por 10 de novo e temos 22 / 10 = 2 e então em C k[2%10] += 1; Resolvido o terceiro dígito. Então divide por 10 de novo e temos 2 / 10 = 0 E terminou. Olhando o vetor temos k[4] = 1 e k[2] = 2 como esperado. Total de numeros para esse teste: 1 Testando para 1 valores Entre numero 1 de 1 224 Para o valor 224: [0:0] [1:0] [2:2] [3:0] [4:1] [5:0] [6:0] [7:0] [8:0] [9:0] Caso limite Quando o número é zero tem que sair com k[0] = 1; certo? Então só pode testar depois de ter feito a conta. Como queremos fazer o simples, um do {} while é o comando certo em C, até o valor ficar zero... Para zero: Testando para 1 valores Entre numero 1 de 1 0 Para o valor 0: [0:1] [1:0] [2:0] [3:0] [4:0] [5:0] [6:0] [7:0] [8:0] [9:0] Claro que pode dividir sem usar o operador %, apenas fazendo as contas em C e o resto vai dar 4 int valor = 224; int quociente = valor / 10; int resto = valor - (quociente * 10); Segundo caso, para 224 Para o mesmo 224, pode-se pensar que o serviço é um pouco monótono: você marca no vetor um dígito, recalcula o valor e faz exatamente a mesma coisa de novo até acabarem os dígitos... Se fosse uma função chamada conta_digito() para o mesmo valor 224: marca o 4.e chama conta_digito(22) marca o 2 e chama conta_digito(2); marca o 2 e chama conta_digito(0); e aí acabou. Isso sugere uma função recursiva e o programa fica bem pequeno... Algo assim int main(int argc, char** argv) { int n{}; int v{}; int k[10]{ }; cout << "Total de numeros para esse teste: "; cin >> n; cout << endl << "Testando para " << n << " valores\n\n"; for (int i = 1; i <= n; i = i + 1) { cout << "Entre numero " << i << " de " << n << endl; cin >> v; conta_digito(v); } // for return 0; } // main() conta_digito() tabula um dígito e chama ela mesma com o número 10 vezes menor para ver o próximo dígito. E mostraria Total de numeros para esse teste: 1 Testando para 1 valores Entre numero 1 de 1 91000 Para o valor 91000: [0:3] [1:1] [2:0] [3:0] [4:0] [5:0] [6:0] [7:0] [8:0] [9:1] E quando chega a zero ela mostra os valores do vetor. Pense nisso e mostre como está indo
-
Veja pelo simples: você espera ler algo de um arquivo, algo da forma "campo = valor". No fundo 3 strings. string 1 = " K1_CONSTANT_BAND_10" string 2 é o próprio "=" string 3 deve ser o valor que precisa já que se fosse também constante não precisaria de um programa afinal. Você pode simplesmente ler o arquivo letra por letra com fgetc() e ir comparando até achar as tais 3 strings na sequência. Nada de especial Mas C tem a família de funções scanf() com o protótipo int scanf ( const char * format, ... ); E esse simples programa por exemplo #define _CRT_SECURE_NO_WARNINGS #include "stdio.h" void fase1(char*); int main() { char* arquivo = "entrada.txt"; fase1(arquivo); return 0; } // main() void fase1(char* arquivo) { const char* mascara = "%s"; char codigo[80]; int n; FILE* tabela; tabela = fopen(arquivo, "r"); if (tabela == NULL) exit(-1); while (!feof(tabela)) { n = fscanf(tabela, mascara, codigo); printf("scanf() leu %d\t[%s]\t(%d)\n", n, codigo, strlen(codigo)); } fclose(tabela); return; }; // fase1() // fim do texto Le e mostra todas as strings no arquivo de entrada. Veja o final, usando o seu arquivo string #625 scanf(1) leu [GROUP] (5) string #626 scanf(1) leu [=] (1) string #627 scanf(1) leu [TIRS_THERMAL_CONSTANTS] (22) string #628 scanf(1) leu [K1_CONSTANT_BAND_10] (19) string #629 scanf(1) leu [=] (1) string #630 scanf(1) leu [774.8853] (8) string #631 scanf(1) leu [K2_CONSTANT_BAND_10] (19) string #632 scanf(1) leu [=] (1) string #633 scanf(1) leu [1321.0789] (9) string #634 scanf(1) leu [K1_CONSTANT_BAND_11] (19) string #635 scanf(1) leu [=] (1) string #636 scanf(1) leu [480.8883] (8) string #637 scanf(1) leu [K2_CONSTANT_BAND_11] (19) string #638 scanf(1) leu [=] (1) string #639 scanf(1) leu [1201.1442] (9) string #640 scanf(1) leu [END_GROUP] (9) string #641 scanf(1) leu [=] (1) string #642 scanf(1) leu [TIRS_THERMAL_CONSTANTS] (22) string #643 scanf(1) leu [GROUP] (5) string #644 scanf(1) leu [=] (1) string #645 scanf(1) leu [PROJECTION_PARAMETERS] (21) string #646 scanf(1) leu [MAP_PROJECTION] (14) string #647 scanf(1) leu [=] (1) string #648 scanf(1) leu ["UTM"] (5) string #649 scanf(1) leu [DATUM] (5) string #650 scanf(1) leu [=] (1) string #651 scanf(1) leu ["WGS84"] (7) string #652 scanf(1) leu [ELLIPSOID] (9) string #653 scanf(1) leu [=] (1) string #654 scanf(1) leu ["WGS84"] (7) string #655 scanf(1) leu [UTM_ZONE] (8) string #656 scanf(1) leu [=] (1) string #657 scanf(1) leu [23] (2) string #658 scanf(1) leu [GRID_CELL_SIZE_PANCHROMATIC] (27) string #659 scanf(1) leu [=] (1) string #660 scanf(1) leu [15.00] (5) string #661 scanf(1) leu [GRID_CELL_SIZE_REFLECTIVE] (25) string #662 scanf(1) leu [=] (1) string #663 scanf(1) leu [30.00] (5) string #664 scanf(1) leu [GRID_CELL_SIZE_THERMAL] (22) string #665 scanf(1) leu [=] (1) string #666 scanf(1) leu [30.00] (5) string #667 scanf(1) leu [ORIENTATION] (11) string #668 scanf(1) leu [=] (1) string #669 scanf(1) leu ["NORTH_UP"] (10) string #670 scanf(1) leu [RESAMPLING_OPTION] (17) string #671 scanf(1) leu [=] (1) string #672 scanf(1) leu ["CUBIC_CONVOLUTION"] (19) string #673 scanf(1) leu [END_GROUP] (9) string #674 scanf(1) leu [=] (1) string #675 scanf(1) leu [PROJECTION_PARAMETERS] (21) string #676 scanf(1) leu [END_GROUP] (9) string #677 scanf(1) leu [=] (1) string #678 scanf(1) leu [L1_METADATA_FILE] (16) string #679 scanf(1) leu [END] (3) string #680 scanf(-1) leu [END] (3) Veja que a string 628 é a que está procurando... O valor entre () em scanf() é o valor de n, o total de itens lidos por scanf() e vale 1 quando leu uma string e -1 por exemplo o final de arquivo. strcmp() descrita em int strcmp ( const char * str1, const char * str2 ); compara as strings e faz o resto do que você precisa. A função retorna zero quando as strings são iguais. Então você procura a primeira, quando achar procura a segunda e aí o valor do campo vai ser o retornado em codigo no programa, a próxima strif se o arquivo não terminar bem nessa hora... É só isso. Entendeu? Quer ver um exemplo ainda?
-
C Como abrir os pixels de uma imagem e comparar com outra
arfneto respondeu ao tópico de Mayrinck Bernardo em C/C#/C++
Trata-se de uma imagem em movimento? É muito diferente isso. O game tem luz, reflexos, sombras... Se está falando em buscar polígonos na imagem é uma coisa, se está falando em procurar um personagem que se move para decidir se ele está na tela é outra... 2s é um tempo e tanto para comparar as imagens, mas a história pode ser outra. Como vai salvar essa imagem? Em que formato? Qual a resolução do jogo? Interferir com o jogo para capturar a tela é outra história. Como vai fazer?









Sobre o Clube do Hardware
No ar desde 1996, o Clube do Hardware é uma das maiores, mais antigas e mais respeitadas comunidades sobre tecnologia do Brasil. Leia mais
Direitos autorais
Não permitimos a cópia ou reprodução do conteúdo do nosso site, fórum, newsletters e redes sociais, mesmo citando-se a fonte. Leia mais
