

arfneto
-
Posts
6.526 -
Cadastrado em
-
Última visita
Tipo de conteúdo
Artigos
Selos
Livros
Cursos
Análises
Fórum
Tudo que arfneto postou
-
? E não poderia publicar o header da classe? E algumas linhas em torno do código que imprime?
-

C Como utilizar printf para printar ponteiros
arfneto respondeu ao tópico de Francine Guimarães em C/C#/C++
Bom que conseguiu. De todo modo recomendo comparar o que eu expliquei com o seu primeiro programa e com o definitivo. Talvez possa aproveitar algo no futuro -
C FIZ UM PROGRAMA PRA SALVAR EM .TXT, porém está salvando em codigo morse
arfneto respondeu ao tópico de Crístofer Tartaglia em C/C#/C++
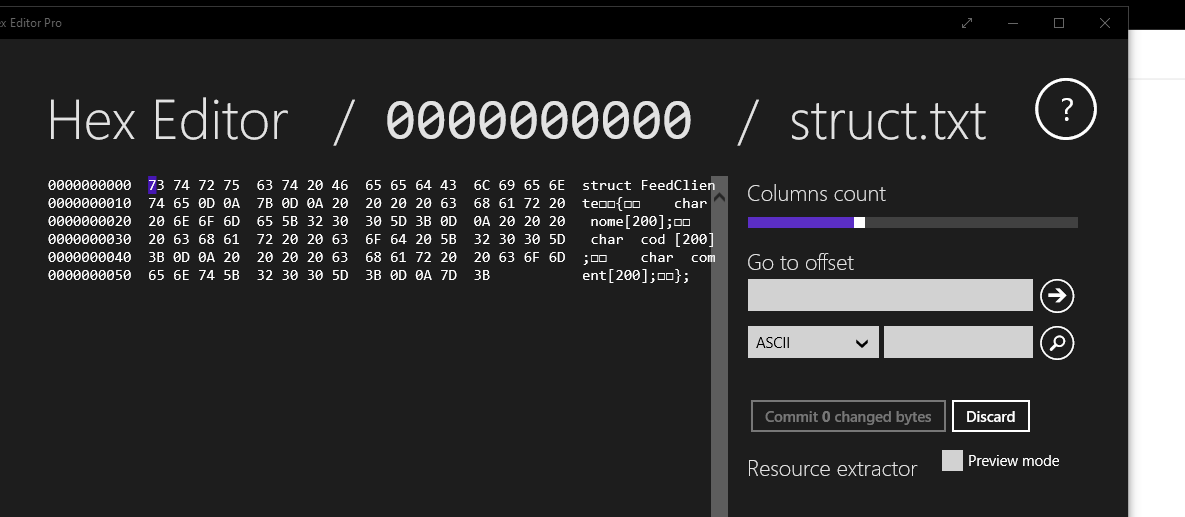
Olá Sua estrutura struct FeedCliente { char nome[200]; char cod [200]; char coment[200]; }; é um registro para o arquivo. Cada fwrite() em seu programa vai gravar um troço desse, que tem tamanho fixo como está aí. Algo como uma linha com uns 600 caracteres. E nem é bem isso, porque cada linha teria um terminador, esse '\n' que aparece nos programas às vezes. E você não gravou. Por outro lado cada campo que você leu vai estar dentro desse limite de 200. Entrando "Qualquer Um" para nome tem menos que 200: tem 11. E um '\0' no fim indicando o fim da string, o tal null. E foi isso que você gravou no arquivo naquela área de 200 posições. E nem se preocupou com o resto até dar 200. E o bloco de notas não entende isso. Acho que deu para você entender. Você não preparou sequer aquela área toda para ficar por exemplo em branco antes de gravar. E mesmo assim tem o problema dos tais null ao final de cada campo. O bloco de notas por outro lado considera texto de tamanho variável, apenas algumas letras e símbolos em linhas terminadas por esse tal newline, ou 10, ou '\n' ou LF ou CRLF dependendo do livro que está lendo e do sistema que está usando. E dai? Veja, gravei em arquivo struct.txt essa declaração da struct que está acima e abaixo está a representação disso no disco, para um arquivo que o bloco de notas entende: apenas texto, com 6 linhas como está acima Estou usando windows. Se usa Unix/Linux/MacOS tem o comando od --- Veja em man od --- bem mais versátil que meu pobre editor. Mas o layout é o mesmo: do lado esquerdo os bytes em hexadecimal, 16 por linha, e na coluna da direita os valores em texto, os mesmos 16 e vai ver sua struct lá. O que importa é olhar os códigos: fora as letras, você vai ver só uns grupos de 0D 0A lá que são os tais newline, '\n\ ou 10 ou 0A mesmo. No Unix e derivados em geral vai ver apenas 0A que é 10, e não vai ver os 13, 0d em hexa que seria o grupo CRLF que no Linux é só LF. Mas isso é lido de maneira portável e você só lê mesmo o 10 no windows também. E tem 5 grupos desses e aparecem mesmo uns caracteres estranhos do lado direito na posição deles. Só que isso o bloco de notas e os editores de texto entendem: fim de linha Agora pense no seu caso de gravar 600 bytes por linha sem se preocupar com o que tem lá dentro adiante do que foi digitado e já entendeu que vai gravar muito mais do que precisa. Por exemplo esse arquivo aí tem 93 bytes e 6 linhas apenas. Se fosse usar o seu formato teria 3600 ao menos. Dois caminhos: ou você grava assim e lê apenas através de seus programas, que vão saber o que está lá dentro ou usa funções, como foi recomendado aqui, que gravam texto em formato variável e assim pode abrir depois também com o editor. Só que aí depois é o diabo para editar no meio deles via programa, certo? Mas acho que já sabe o que esperar em um caso e em outro. Gravar os registros com fwrite() não é anormal e gravar texto puro --- plain text --- não é normal. O que é um banco de dados em txt? Com linhas nome/cod/comment de tamanho variável até 200 bytes. Vai ter dificuldade em tratar isso. Num banco de dados provavelmente você indexaria isso tudo por uma chave, tipo o tal cod que não seria numérico... Talvez possa explicar melhor o que está tentando fazer...
-
C Programa C cadastro de produtos e atualiza
arfneto respondeu ao tópico de lucas.suanderhus em C/C#/C++
E o que seria? um percentual de aumento? -
Volto a explicar: as vírgulas não são uma necessidade e sim uma consequência. A razão óbvia é que só tem um campo por linha então não tem o que delimitar. Coloque um valor em B2 na planilha por exemplo e gere novo csv e veja o que acontece. Nova linha delimita registros e não campos. Vírgulas delimitam campos na linha. Se tiver mais de um. @VitorToresin Entenda que seu arquivo exemplo CSV é um arquivo no formato CSV por eliminição. Acho que eu já expliquei e dei exemplos e suficientes referências, mas entenda que esse é um formato de intercâmbio de dados, onde tem um registro por linha e os campos são separados por vírgula. Seu arquivo exemplo só tem um valor, então não há o que separar por vírgula e ninguém pode vir falando que seu arquivo não é um arquivo no formato CSV. O V é de Values, mas você não tem culpa de só ter um valor por linha.Mas veja seu programa exemplo e o que vai acontecer se alguém apagar o valor em A4 Seu arquivo vai ficar assim 1 2 3 5 6 7 8 9 10 E do jeito que seu programa lê vai desalinhar tudo e não vai conseguir ler os campos todos porque não percebeu que o campo em A4 está em branco. Mesmo tendo uma coluna só não está certo. A linha em branco indica que um registro, o quarto, não tem um campo, o unico, presente. E seu programa não viu. Agora veja o que acontece se alguém digita algo em B2 na planilha e gera novo CSV pra você ler E gera novo CSV para você ler 1,2 2, 3, , 5, 6, 7, 8, 9, 10, Agora os valores são sim separados por vírgula, e seu programa já era. Um arquivo CSV é sempre quadradinho: tem uma linha para cada registro exportado e tem um campo para cada campo na entrada. Agora temos 2 colunas e 10 linhs então o CSV será assim, mesmo que seja chato. A primeira linha tem 1,2 mostrando os dois campos Como a linha 4 está em branco, aparece uma vírgula solitária, para seu programa saber que tem um campo antes e outro depois da vírgula Todas as outras linhas terminam em vírgula porque o campo da coluna dois está em branco em todos os registros exceto o primeiro Pense nisso. Caso de uso 1 Os programas de mala direta usam sempre esse formato para o arquivo de etiquetas para imprimir os envelopes e o formato é assim óbvio, e muito anterior a internet por exemplo. Eis uma planilha para imprimir aquelas etiquetas adesivas Aí gera o CSV destinatario,rua,cidade,estado,CEP Microsoft Redmond Town Center 5,7240 166th Ave NE,Redmond,WA,98052 Microsoft Redmond Town Center 5,7240 166th Ave NE,Redmond,WA,98052 Microsoft Redmond Town Center 5,7240 166th Ave NE,Redmond,WA,98052 Microsoft Redmond Town Center 5,7240 166th Ave NE,Redmond,WA,98052 Microsoft Redmond Town Center 5,7240 166th Ave NE,Redmond,WA,98052 Microsoft Redmond Town Center 5,7240 166th Ave NE,Redmond,WA,98052 Microsoft Redmond Town Center 5,7240 166th Ave NE,Redmond,WA,98052 Microsoft Redmond Town Center 5,7240 166th Ave NE,Redmond,WA,98052 E aquele programa da PIMACO que você comprou começa a imprimir as etiquetas pra colar nos envelopes. Caso de uso 2 Copiar endereços de contatos do Outlook para o gmail Você seleciona os contatos no Microsoft Outlook, exporta para um arquivo csv e grava. Abre o gmail e seleciona a opção de importar contatos, escolhe o csv que gravou e tecla ENTER. Não vou explicar o processo. Tem muitos exemplos online por exemplo em Do Outlook para CSV Do CSV para o gmail Como criar um CSV @Mauro Britivaldo Mauro, em relação às suas considerações sobre csv. eu apresentei exemplos, o link para os documentos e até o RFC4180 que descreve o formato e é sempre autoritativo. Não foi publicado um STD e tal, porque esse formato antecede a internet e o IETF e o W3C. No entanto, como o formato MIME text/csv é oficial desde os anos 80 essa informação é oficial. Tudo que trafega na internet é padronizado e essas são as organizações que cuidam disso. Veja em cada ágina os links para os documentos E o IETF Respeito sua ideia que tudo é questão de implementação e a norma de fato não existe. Mas é uma curiosa opinião: o que seria de todos os exemplos que te mostrei? Isso está embutido até no SQL, a linguagem de consulta de bancos de dados. Está no Office. Está em toda parte. Se você quer trocar dados via csv, imagine que há um padrão. "Não é norma porque de fato não existe" Se ainda não entendeu, não sei o que falta e não sou eu que vou te dizer. Afinal você não parece ter nenhuma dúvida a respeito, a julgar pelo "de fato não existe". Parece nosso mitológico presidente falando. Nos anos 80 eu usava arquivos csv para gravar dados de programas numéricos, em equipamentos que eram chamados na época mini-computadores rodando AT&T Unix SVR IV, e levar para importar em outros computadores da época, que eram chamados mainframes, rodando VM/CMS, para importar para outros programas de cálculo. Nunca precisei consultar Bell Labs para o padrão no UNIX, nem consultar a IBM sobre como gravar. Usava o tal formato CSV um registro por linha e a matriz chegava do outro lado.
-
C Como utilizar printf para printar ponteiros
arfneto respondeu ao tópico de Francine Guimarães em C/C#/C++
Olá Escrevi uma mínima implementação de sua lógica usando malloc() e realloc() para mostrar o que eu queria dizer com os cuidados para implementar isso. Procurei mudar um mínimo no que escreveu e recomendo que leia com cuidado. Rode em sua máquina se possível. Como eu disse, recomendo usar uma estrutura de dados diferente, mas usar um vetor tem seu apelo e é muito rápido, apesar dos efeitos colaterais de usar realloc() e dos riscos de perder um ponteiro no caminho Usei uma implementação para a sua agenda como se fosse uma classe em C++ e acho que vai entender porque: para não correr riscos com os ponteiros Nas declarações inicias não há qualquer alocação, apenas declaramos as estruturas e protótipos das funções. Não há variáveis globais O programa sempre começa por main() e por uma boa razão: a execução começa por main(). Recomendo sempre fazer isso em seus programas A estrutura básica struct contact { int ID; char name[100]; }; typedef struct contact Contact; struct control { int capacity; int in_use; // quando esgotar aloca uma igual quantia Contact* schedule; }; typedef struct control Control; Veja que a agenda fica dentro dessa struct Control para manter o isolamento. Assim pode até usar qualquer número de agendas no mesmo programa. Não usei os outros campos da agenda porque seria irrelevante, e acrescentei um ID que nunca duplica, para os testes. E usei nomes com "sobrenome" BulkInsertnnnn onde nnnn é o próprio ID do contato, assim se sabe se sumiu alguém só de olhar. Bulk Insert é uma expressão comum para funções que inserem registros "no atacado". Criei novos nomes Control e Contact para as structs pra não ter que ficar repetindo struct toda hora e porque na verdade eu sempre esqueço . E usei a primeira letra em maiúscula porque é uma convenção comum em java e C++ para nomes de Classes. A Estrutura de controle Usei as mesmas variáveis que usou: a capacidade e o total em uso até o momento. E o ponteiro para o endereço de início da agenda. Como todas as funções recebem o endereço essa estrutura de controle como parâmetro, estamos seguros que esse ponteiro está preservado, porque ele será o alvo de malloc()/realloc() afinal. E um erro aqui vai certamente cancelar o programa. E temos pressa. As funções Usei um prefixo x_ para as funções, para criar um micro namespace como em C++ para evitar colisão com nomes que você use já Control* x_inicia(int c); recebe um int que é a quantia inicial de registros a alocar e devolve o endereço da estrutura Control gerada. Control* x_termina(Control* control); recebe um endereço de uma estrutura Control e apaga tudo. Retorna um endereço de Control que será sempre NULL, e serve para exercitar o saudável hábito de invalidar o ponteiro em seu programa, já que uma referência posterior a ele vai, claro, cancelar seu programa. int x_bulkInsert(int t, Control* control); Insere t registros na agenda em control, usando ID sequenciais e nomes 'name BulkInsertnnnn' onde nnnn é o ID do contato. Assim não precisamos inventar nomes durante os testes e se pode confirmar sequencia e unicidade deles, de graça e por definição. int x_newContact(Contact* novo, Control* c); Insere o contato novo na agenda incluída em c. É diferente do modo como fez: recomendo NUNCA pegar os dados, validar e coisas assim na rotina que insere: chame a rotina que insere com um valor confiável e teste antes. Facilita muito a sua vida quando se tem pressa. Contact* x_realoca(Control* control); Realoca a estrutura de contatos, usando sua lógica de dobrar o tamanho a partir do início. Como seu exemplo inicia com 1 vamos ter 1,2,4,8,16 ou seja 2^n. E devolve o novo endereço da estrutura. Claro que o endereço já está dentro de control, mas assim pode acrescentar mais um nível de garantia de que o ponteiro será preservado. int x_showAll(Control* c); Só imprime o conteúdo da agenda de contatos incluída em c. Só usei o nome e ID porque claro não faz a menor diferença. E temos pressa. Um programa de teste int main(int argc, char** argv) { Control* control = x_inicia(1); // inicia com 1 x_bulkInsert(21, control); // insere 21 x_showAll(control); // mostra todos control = x_termina(control); // libera os registros return 0; // termina } Ao inserir 21 vai usar 1/2/4/8/16/32 registros e ao final a capacidade deve estar em 32. Sempre é melhor saber antes o que se espera do teste... O resultado inicia(): sizeof(Contact) = 104, capacidade = 1, em uso = 0 ***** BulkInsert(21) ***** realoca(): capacidade vai ser alterada para 2 realoca(): sizeof(Contact) = 104, capacidade = 2, em uso = 1 realoca(): capacidade vai ser alterada para 4 realoca(): sizeof(Contact) = 104, capacidade = 4, em uso = 2 realoca(): capacidade vai ser alterada para 8 realoca(): sizeof(Contact) = 104, capacidade = 8, em uso = 4 realoca(): capacidade vai ser alterada para 16 realoca(): sizeof(Contact) = 104, capacidade = 16, em uso = 8 realoca(): capacidade vai ser alterada para 32 realoca(): sizeof(Contact) = 104, capacidade = 32, em uso = 16 showAll(): sizeof(Contact) = 104, capacidade = 32, em uso = 21 001, Nome: 'Name BulkInsert0001', ID=1 002, Nome: 'Name BulkInsert0002', ID=2 003, Nome: 'Name BulkInsert0003', ID=3 004, Nome: 'Name BulkInsert0004', ID=4 005, Nome: 'Name BulkInsert0005', ID=5 006, Nome: 'Name BulkInsert0006', ID=6 007, Nome: 'Name BulkInsert0007', ID=7 008, Nome: 'Name BulkInsert0008', ID=8 009, Nome: 'Name BulkInsert0009', ID=9 010, Nome: 'Name BulkInsert0010', ID=10 011, Nome: 'Name BulkInsert0011', ID=11 012, Nome: 'Name BulkInsert0012', ID=12 013, Nome: 'Name BulkInsert0013', ID=13 014, Nome: 'Name BulkInsert0014', ID=14 015, Nome: 'Name BulkInsert0015', ID=15 016, Nome: 'Name BulkInsert0016', ID=16 017, Nome: 'Name BulkInsert0017', ID=17 018, Nome: 'Name BulkInsert0018', ID=18 019, Nome: 'Name BulkInsert0019', ID=19 020, Nome: 'Name BulkInsert0020', ID=20 021, Nome: 'Name BulkInsert0021', ID=21 showAll() ***** end of listing ***** Até aqui OK: não sumiu ninguém, realloc() funcionou e o último é, bem, o último com ID=21 Um outro teste com duas agendas e uma maior int main(int argc, char** argv) { Control* control = x_inicia(1); // inicia com 1 x_bulkInsert(21, control); // insere 21 x_showAll(control); // mostra todos control = x_termina(control); // libera os registros printf( "\n\nCriando agenda maior e mostrando os 2 primeiros e os dois ultimos\n"); Control* bigOne = x_inicia(1); x_bulkInsert(2049, bigOne); // insere 2049 = 2^11 + 1 /* mostra nome e ID dos ultimos caras */ printf( "\n%03d, Nome: '%s', ID=%d\n\n...\n\n", 1, bigOne->schedule[0].name, bigOne->schedule[0].ID ); printf( "%03d, Nome: '%s', ID=%d\n", 2047 + 1, bigOne->schedule[2047].name, bigOne->schedule[2047].ID ); printf( "%03d, Nome: '%s', ID=%d\n", 2048 + 1, bigOne->schedule[2048].name, bigOne->schedule[2048].ID ); bigOne = x_termina(bigOne); return 0; // termina } A primeira parte é a mesma, claro. Mas depois uma segunda agenda, bigOne é criada com 2049 registros, apenas para forçar realloc() a alocar 4096. E mostramos apenas o primeiro e os dois últimos nomes, para ver que podemos usar a agenda inteira como um vetor comum, que é o objetivo afinal Resultado (apenas da segunda parte) Criando agenda maior e mostrando o primeiro e os dois ultimos inicia(): sizeof(Contact) = 104, capacidade = 1, em uso = 0 ***** BulkInsert(2049) ***** realoca(): capacidade vai ser alterada para 2 realoca(): sizeof(Contact) = 104, capacidade = 2, em uso = 1 realoca(): capacidade vai ser alterada para 4 realoca(): sizeof(Contact) = 104, capacidade = 4, em uso = 2 realoca(): capacidade vai ser alterada para 8 realoca(): sizeof(Contact) = 104, capacidade = 8, em uso = 4 realoca(): capacidade vai ser alterada para 16 realoca(): sizeof(Contact) = 104, capacidade = 16, em uso = 8 realoca(): capacidade vai ser alterada para 32 realoca(): sizeof(Contact) = 104, capacidade = 32, em uso = 16 realoca(): capacidade vai ser alterada para 64 realoca(): sizeof(Contact) = 104, capacidade = 64, em uso = 32 realoca(): capacidade vai ser alterada para 128 realoca(): sizeof(Contact) = 104, capacidade = 128, em uso = 64 realoca(): capacidade vai ser alterada para 256 realoca(): sizeof(Contact) = 104, capacidade = 256, em uso = 128 realoca(): capacidade vai ser alterada para 512 realoca(): sizeof(Contact) = 104, capacidade = 512, em uso = 256 realoca(): capacidade vai ser alterada para 1024 realoca(): sizeof(Contact) = 104, capacidade = 1024, em uso = 512 realoca(): capacidade vai ser alterada para 2048 realoca(): sizeof(Contact) = 104, capacidade = 2048, em uso = 1024 realoca(): capacidade vai ser alterada para 4096 realoca(): sizeof(Contact) = 104, capacidade = 4096, em uso = 2048 001, Nome: 'Name BulkInsert0001', ID=22 ... 2048, Nome: 'Name BulkInsert2048', ID=2069 2049, Nome: 'Name BulkInsert2049', ID=2070 Tudo ok: alocou 2048 a mais e usou um só O último é o último e os primeiros 21 estão na outra agenda. Eis o programa todo #define _CRT_SECURE_NO_WARNINGS #include <stdio.h> #include <stdlib.h> #include <string.h> struct contact { int ID; char name[100]; //char street[100]; //char ngbhood[100]; //char city[100]; //char state[100]; //int bday[15]; //int cellnumber[20]; //int number[10]; //int CEP[20]; }; typedef struct contact Contact; struct control { int capacity; int in_use; // quando esgotar aloca uma igual quantia Contact* schedule; }; typedef struct control Control; int x_bulkInsert(int, Control*); // insere muitos registros Control* x_inicia(int); // inicia estrutura com determinada capacidade int x_newContact(Contact*, Control* c); // cria um Contact* x_realoca(Control*); // duplica o tamanho da agenda int x_showAll(Control*); // lista todos Control* x_termina(Control*); // inicia estrutura com determinada capacidade int main(int argc, char** argv) { Control* control = x_inicia(1); // inicia com 1 x_bulkInsert(21, control); // insere 21 x_showAll(control); // mostra todos control = x_termina(control); // libera os registros printf( "\n\nCriando agenda maior e mostrando os 2 primeiros e os dois ultimos\n"); Control* bigOne = x_inicia(1); x_bulkInsert(2049, bigOne); // insere 2049 = 2^11 + 1 /* mostra nome e ID dos ultimos caras */ printf( "\n%03d, Nome: '%s', ID=%d\n\n...\n\n", 1, bigOne->schedule[0].name, bigOne->schedule[0].ID ); printf( "%03d, Nome: '%s', ID=%d\n", 2047 + 1, bigOne->schedule[2047].name, bigOne->schedule[2047].ID ); printf( "%03d, Nome: '%s', ID=%d\n", 2048 + 1, bigOne->schedule[2048].name, bigOne->schedule[2048].ID ); bigOne = x_termina(bigOne); qsort return 0; // termina } int x_bulkInsert(int t, Control* control) { // insere n registros no cadastro, com nome a partir // de 'Name BulkInsert0001' em diante // para acelerar os testes. Realoca a agenda quando for preciso Contact contato; int n; printf("\n***** BulkInsert(%d) *****\n", t); for (int i = 1; i <= t; i += 1) { sprintf(contato.name, "Name BulkInsert%04d", i); n = x_newContact(&contato, control); if (n < 0) { control->schedule = x_realoca(control); n = x_newContact(&contato, control); } // end if } // for i return 0; } // x_bulkInsert() Control* x_inicia(int c) { int q; Control* control = (Control*) malloc(sizeof(Control)); control->capacity = c; q = sizeof(Contact) * c; control->in_use = 0; control->schedule = (Contact*)malloc(sizeof(Contact) * c); printf("inicia(): sizeof(Contact) = %d, capacidade = %d, em uso = %d\n", sizeof(Contact), control->capacity, control->in_use ); return control; }; int x_newContact(Contact* novo, Control* c) { static int sequence = 0; if (c->in_use >= c->capacity) return -1; // não cabe mais Contact* next = c->schedule + c->in_use; sequence += 1; strcpy(next->name, novo->name); // usa so o nome next->ID = sequence; //printf("Criado contato com ID = %d e nome '%s'\n", // next->ID, next->name); c->in_use += 1; return 1; } Contact* x_realoca(Control* control) { int q = control->capacity + control->capacity; // dobra o tamanho da agenda printf("realoca(): capacidade vai ser alterada para %d\n", q); control->schedule = (Contact*) realloc(control->schedule, sizeof(struct contact) * q); control->capacity = q; if (control->schedule == NULL) { printf("realoca(): ERRO ao realocar agenda\n"); exit(1); } printf("realoca(): sizeof(Contact) = %d, capacidade = %d, em uso = %d\n", sizeof(Contact), control->capacity, control->in_use ); return control->schedule; }; int x_showAll(Control* c) { printf("\nshowAll(): sizeof(Contact) = %d, capacidade = %d, em uso = %d\n\n", sizeof(Contact), c->capacity, c->in_use ); for (int i = 0; i < c->in_use; i += 1) { printf( "%03d, Nome: '%s', ID=%d\n", i+1, c->schedule[i].name, c->schedule[i].ID ); } // for printf("\nshowAll() ***** end of listing *****\n\n"); return 0; }; // x_showAll() Control* x_termina(Control* control) { // apaga tudo free(control->schedule); free(control); return NULL; }; // fim do texto -
Sim. É muito bom e muito rápido, como o MErgeSort e o HeapSort. Genial. E se você inclui a função que compara fica genérico, de modo que pode classificar qualquer coisa mesmo. Tipo pegar uma tabela e classificar por Nome e depois por CPF e depois pelo CEP do local de entrega e tal. Note que C inclui uma implementação de Quicksort declarada assim void qsort( void* inicio, size_t total_de_itens, size_t tamanho de cada um, int (*funcao_que_compara)(const void *, const void*) ); E você pode usar para classificar qualquer coisa para a qual possa apontar
-
Olá dias atrás postei uma explicação sobre a lógica de fazer isso, com exemplos. Veja em De qualquer forma o procedimento é Considerar uma fila, do tipo LIFO, last in first out, a fila em que você coloca os caras e o primeiro a sair é o último que entrou, como a clássica pilha de pratos. Você pega a palavra e coloca na tal fila --- pilha --- de letras, letra a letra. Claro que ela vai ficar ao contrário Claro que vai ter o mesmo tamanho de sua string, porque são as mesmas letras Aí você compara letra a letra o que vem da fila e o que tem na string, até a metade dela. Se encontrar algo diferente já pode afirmar que não são iguais. Se chegar até a metade então a palavra é sim palíndroma. Sugiro ler os exemplos que escrevi lá e se ainda assim tiver dúvida volte a perguntar
-
Esqueci de comentar: é importante considerar que esse troço funciona in-place, por exemplo no próprio array, então uma vez que o pivo chega no lugar certo --- ou os segmentos, dependendo de como você vê isso --- são posições permanentes. É como o HeapSort, onde a cada passo sai um classificado, ou o fim de cada loop no bubble sort onde o maior vai "afundando" por exemplo
-
É assim, mas entenda que seu arquivo CSV é muito peculiar, na medida em que ele sequer tem o C. CSV separa S os valores V dos campos de cada registro por algo que em geral é uma vírgula, o C Leu os exemplos que mostrei? Se por acaso em sua planilha apagar o conteúdo de A3 e a4 exemplo, o csv criado vai ser diferente e seu programa não vai rodar... Entendeu que esse formato é para separar os campos na linha e não as linhas?
-
C Como utilizar printf para printar ponteiros
arfneto respondeu ao tópico de Francine Guimarães em C/C#/C++
Olá! Eu diria que seu problema está espalhado pelo programa todo por enquanto. Esse vetor de itens da agenda estaria declarado onde? Não está. Usar realloc() para ir aumentando o espaço e usar aritmética para acessar os elementos funciona, claro. Mas é chato. Talvez pudesse usar outra estrutura de dados, como uma lista ou uma pilha. Está seguindo um enunciado ou inventou esse problema para aprender? newContact() poderia devolver o endereço de um novo registro e você insere em sua estrutura. Pode simplificar as coisas. showAll() poderia devolver o total de itens que percorreu no cadastro. É mais comum e dá pra conferir com o total que você tem. Isso não é um problema: é a realidade de você querer que por exemplo o nome tenha mais de uma letra, char. E assim por diante, com o telefone, endereço e tal. Você precisa alocar espaço para os dados, permanentemente ou declara tudo como char* e vai dar um trabalho danado para alocar um a um e liberar depois. realloc() é um inferno porque nada garante que ao mudar de tamanho os dados vão ficar a partir do mesmo endereço, então pode ser que durante o programa a agenda inteira seja movida na memória algumas vezes sem seu controle. Mas funciona. Em geral o que se faz é usar coisas como uma lista de itens, onde um item aponta para o próximo na agenda, e aí você tem a vantagem de poder inserir já na ordem em que vai pesquisar os dados. Ou usar vetores de ponteiros com um certo número de posições, e ir alocando mais sob demanda. Claro que isso se seu programa for salvar a agenda em disco e recuperar de novo da próxima vez... De todo modo, apenas usando essa sua ideia e malloc() realloc() faça o seguinte: crie uma pequena estrutura de controle com a capacidade atual da agenda e o endereço de início dela, e passe um ponteiro para esse endereço como argumento de suas rotinas show() update() showAll() newContact() e tal. adicionado 51 minutos depois Eu não entendi mesmo a relação entre o título do tópico e seu programa -
Olá! Os dois segmentos nunca se encontram. O limite entre eles é o pivo. As trocas acontecem entre os segmentos, que tem um tamanho elástico digamos: você apenas garante que tudo que ficou a esquerda do pivo é menor e tudo que fica a direita é maior e vai reajustando os tamanhos. Quando conseguir isso então faz o mesmo com os dois segmentos, recursivamente ou interativamente mesmo, e continua fazendo isso até os segmentos ficarem bem pequenos, com 1 elemento ou nenhum. E aí estará tudo em ordem. é mais rápido para classificar do que para explicar. É muito rápido. Exemplo com 9 números [1 3 4 12 10 10 8 9 0] Se o primeiro pivo for o 9 vai ficar com [1 3 4 8 0] 9 [12 10 10] Ao fim do primeiro passo No caso do primeiro segmento com o pivo 8 [1 3 4 0] [8] [9] [12 10 10] E usando o 4 como pivo [0 1 3] [4] [8] [9] [12 10 10] E usando o 1 como pivo [0] [1] [3] [4] [8] [9] [12 10 10] E usando o 10 como pivo [0] [1] [3] [4] [8] [9] [10] [10] [12] E não é que ficou tudo em ordem?
-
@Mauro Britivaldo Exercite sua imaginação, ou leia mais, porque eu por exemplo expliquei e dei exemplos logo acima. E vou dar mais referências abaixo. O que eu escrevi não é minha opinião. Não deve ter tido tempo de ler o que eu escrevi ou talvez apenas ache que não vale a pena Os registros são separados por linha, esse é o sentido. Leu o que expliquei sobre extrair valores de uma tabela do banco de dados? Se você extrai as vendas no final do dia nesse formato, vai ter uma linha para cada venda e os dados da venda serão os campos em cada linha. Não entendeu isso? Arquivos CSV no IETF Sim, existe um RFC -- daqueles documentos que descrevem todos os padrões na internet --- esclarecendo aspectos sobre o formato CSV. E existe um MIME Type text/csv , e isso significa que todos os navegadores e programas de e-mail tem que saber tratar arquivos e anexos nesse formato. RFC4180 é um documento informativo, e diz que CSV é um formato muito antigo e tradicional e que nunca foi de fato padronizado por um comitê como em geral é o caso. Arquivos CSV na Biblioteca do Congresso Sim o maior repositório de documentos do mundo tem um artigo sobre isso e algumas referências. Aqui Um validador online para seus arquios CSV Sim, você pode acessar esse site e mandar um CSV que seu programa gerou e ele será validado online. Aqui você pode validar seu arquivo CSV, de graça Incrível não? E se usa isso desde os anos 70. Como já está embutido em programas que existem mesmo antes de você poder se acostumar, há que se seguir alguma norma. O Chrome lê CSV, como mostrei. O Excel e o Google Sheets leêm e gravam CSV, o MySQL, o PostGRES, o SQL Server.... E como um programa desses pode e precisa poder ler arquivos gerados talvez pelo outro programa deve imaginar que, mesmo que você "ache graça e não esteja acostumado" seja preciso seguir alguma norma e ela exista. A razão é intercâmbio de dados. E é uma norma. Do outro lado disse que você chama de "rotina" tem um aplicativo que vai consumir esses dados. Ou não daria pra exportar resultados do banco de dados para ler em planilhas como é rotina em muitas situações. Ou vice-versa, pegar os resultados de uma planilha e importar no banco de dados. E os programas de mala direta? Talvez você ainda não tenha se acostumado com o fato de que todos eles leem arquivos no formato CSV E como ficou claro isso se eu te mostrei um exemplo de um comando SQL onde o delimitador é um parâmetro e eu já havia explicado que em programas como o Excel o delimitador é parametrizável? SELECT customer_id, firstname, surname INTO OUTFILE '/exportdata/customers.txt' FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"' LINES TERMINATED BY '\n' FROM customers; Se você trocar ',' por '-' no comando acima acha que vai acontecer o que? Está escrevendo seriamente essas coisas? Baseado em coisas com as quais vem se acostumando desde 2014?
-
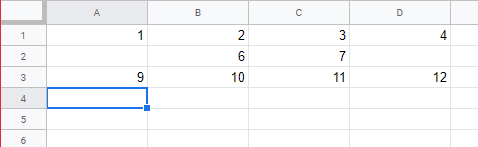
@Mauro Britivaldo em relação a essas coisas, recomendo ler o que postei um pouco antes. Sim, CSV é um formato bem definido para troca de dados, importação ou exportação de dados. E você definiu bem quando escreveu "CSV diz repeito a estruturação dos dados, a maneira com se dispõe interiormente as informações" No entanto, um arquivo CSV é organizado de modo a ter um registro por linha, e os registros tem campos, e não o contrário, como você escreveu. Essa designação é coerente com a troca de dados: por exemplo um banco de dados ou planilha onde cada linha é um REGISTRO e cada coluna um CAMPO na nomenclatura usual. Essa linha que mostrou 1,2,3,4,5, tem SEIS campos e não cinco, e um único registro: trata-se de um registro por linha e só tem uma linha. A vírgula ao final indica que o sexto campo está em branco. Veja um exemplo que vou deixar a seguir. Claro que podemos redefinir qualquer coisa, mas estamos falando de uma nomenclatura consagrada há décadas. Exportar uma planilha como a do autor do tópico, com 10 linhas de uma coluna, vai levar ao arquivo CSV que foi postado lá, sem vírgulas, e que você pode reproduzir aí com qualquer programa de planilha por exemplo. O formato conhecido como CSV é esse onde os registros são exportados linha a linha com um delimitador que geralmente é a vírgula, separando os campos. "sem formatação" pode indicar apenas o fato de ele conter apenas texto, mas um arquivo CSV é um arquivo contendo texto cuidadosamente formatado, com cada campo sendo separado por um delimitador, campos em branco deixados sem espaço entre os delimitadores, e um único '\n' ao final de cada registro. E todos os registros tem exatamente o mesmo número de campos. Veja o exemplo abaixo Outro exemplo CSV 1,2,3,4 ,6,7, 9,10,11,12 Correspondente a essa planilha Note que todas as linhas --- registros --- tem 4 campos. Ilustrando mais a aplicação da nomenclatura, veja esse comando de um banco de dados --- MySQL, hoje MariaDB Criando um CSV a partir de um banco de dados SELECT customer_id, firstname, surname INTO OUTFILE '/exportdata/customers.txt' FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"' LINES TERMINATED BY '\n' FROM customers; Note que esse comando vai pegar a tabela customers --- clientes --- que tem registros --- records --- que contem campos --- fields --- e vai gerar um arquivo no formato CSV chamado customers.txt são 3 campos por linha: id, firstname e surname delimitador é vírgula separador de linhas é '\n' vai colocar também aspas em volta de todos os valores exatamente o que faz o Google Sheets nos exemplos que mostrei. O Microsoft Excel tem um assistente --- wizard -- para tratar essas coisas. Se eu tiver tempo depois posso mostrar uma parte. Muito sofisticado e configurável.
-
Olá! Seu exemplo é curioso. Talvez não tenha entendido ao certo o que é um arquivo CSV. Esse é um formato clássico para exportação de dados e é muito muito comum a gente precisar disso na prática. CSV quer dizer "Valores separados por vírgula" e em muitos casos, como no Microsoft Excel, você pode trocar a vírgula por outra coisa, como um TAB ou um hífen ou o que for conveniente na sua lógica na hora de importar. E não são apenas planilhas que usam isso, claro. Esse formato precede as planilhas em décadas. Bancos de dados e programas de escritório oferecem CSV como um formato comum de exportação de arquivos em modo texto. E os programas de planilha podem importar dados gravados em CSV e assim usuários sem experiência em programação podem usar esses arquivos para transportar dados entre programas. Em geral na primeira linha vão os títulos dos campos. Mas as vírgulas separam AS COLUNAS e não as linhas. Como seu exemplo só tem uma coluna, é um arquivo CSV sem vírgulas: apenas um arquivo no formato texto com um valor por linha. Não é exatamente um arquivo CSV, embora formalmente o seja. Como importar o seu exemplo Trata-se de um arquivo texto comum com um registro por linha, então um loop até final de arquivo, lendo e gravando no vetor Como importar um CSV com V Se sua planilha fosse essa o arquivo de saída seria algo assim: 1,2,3,4 5,6,7,8 Como importar esse exemplo scanf() foi criada com esse propósito e resolve bem, mas pode usar um loop lendo a linha toda como string e separando os campos pelo delimitador, a vírgula, e colocando os elementos no vetor no loop. Note que CSV é para importar dados linha a linha, possivelmente tabela com muitas linhas... Um exemplo mais comum Aqui tem algo bem comum e mostra porque isso foi criado. Essa planilha é uma simplista nota fiscal, alguns itens e um total só para você entender a mecânica. Note que a primeira linha tem os nomes dos campos. Se você tem um banco de dados e quer importar os valores, já sabe onde arrumar os nomes para as colunas da tabela no banco... Veja o CSV quantidade,descricao,valor ,total 1,parte1,$123.23,$123.23 2,parafuso,$100.00,$100.00 8,coisa,$128.12,$128.12 2,outro,$12.00,$12.00 total geral,,,$363.35 Como importar isso? Igualzinho, claro. Apenas no seu programa você trata a primeira linha diferentemente, sabendo que ela tem o nome dos campos, e note que quando um campo não está presente aparecem delimitadores em sequência Escreva algum código e poste alguma dúvida. Espero ter ajudado
-
Olá! Parabéns! Bom que o programa rodou ok afinal. Vou te mostrar um exemplo de como tratar isso do jeito que eu te falei acima. Apenas porque agora fica fácil de você comparar porque já sabe o trabalho que teve e talvez possa usar isso no futuro. Testar programas que tem menus e leem coisas da tela é sempre chato e lento. Essa é uma razão pra não fazer essas coisas nunca ao mesmo tempo. Como começar então? O programa é isso: Temos uma estrutura e vamos criar um arquivo com os registros que o usuário criou numa primeira fase do programa, um a um. E depois vamos ler os dados do disco e filtrar por um critério, o mês e ano de nascimento das pessoas cadastradas. Imagine uma fictícia função declarada assim: int xyz_grava_uns(FILE* file, int ano, int quantos_anos, int quantos_por_mes, int maximo); Onde file - o ponteiro para o arquivo já aberto ano - o primeiro ano de nascimento das pessoas quantos_anos - registros para quantos anos a partir de ano. quantos_por_mes - quantos registros de pessoas nascidas em cada mês vão ser gerados maximo - total maximo de registros a gerar, só pra evitar algum exagero inesperado E os nomes dos caras? são do tipo 'Nome XYZnnnn' numerados a partir de um. Assim fica fácil acompanhar se algo está duplicando sem ter que inventar nada.. E a função retorna o número de registros efetivamente gravados no disco que seria uma próxima pergunta. Exemplo 1 int total = xyz_grava_uns(arquivo, 2010, 1, 2, 1000); Vai gerar um arquivo contendo nascidos a partir de 2010, 1 único ano então apenas esse, 2 por mês, e um máximo de 1000 registros. vai gerar 24, claro: 2 por mês, 12 meses, 1 ano. E o arquivo vai estar lá enquanto você testa outras partes do programa, ao invés de ficar A CADA TESTE rodando um menu e inventando nomes meses e anos e tal Exemplo 2 int total = xyz_grava_uns(arquivo, 2010, 10, 20, 1000); Vai gerar registros, 20 por mês para cada mês a partir de 2010, mas parando no registro 1000 porque iria passar do limite estipulado Uma possível função int xyz_grava_uns(FILE* file, int ano, int quantos_anos, int quantos_por_mes, int maximo) { int sequencia = 1; Pessoa modelo; modelo.dia = 1; // nao faz diferenca no teste if (file == NULL) return -1; for (int a = 0; a < quantos_anos; a += 1) { modelo.ano = ano + a; // cria registros para esse ano for (int m = 1; m <= 12; m += 1) { modelo.mes = m; // cria para esse mes for (int n = 0; n < quantos_por_mes; n += 1) { sprintf(modelo.nome, "Nome XYZ%04d", sequencia); printf( "%03d: '%s'nascido em %02d/%02d/%04d\n", sequencia, modelo.nome, modelo.dia, modelo.mes, modelo.ano ); fwrite(&modelo, sizeof(Pessoa), 1, file); if (sequencia >= maximo) return 0; sequencia = sequencia + 1; } // for n } // for m } // for a return sequencia - 1; }; // xyz_grava_uns() Eis o que ela mostra para o exemplo 1 Arquivo coisa.txt aberto com sucesso 001: 'Nome XYZ0001'nascido em 01/01/2010 002: 'Nome XYZ0002'nascido em 01/01/2010 003: 'Nome XYZ0003'nascido em 01/02/2010 004: 'Nome XYZ0004'nascido em 01/02/2010 005: 'Nome XYZ0005'nascido em 01/03/2010 006: 'Nome XYZ0006'nascido em 01/03/2010 007: 'Nome XYZ0007'nascido em 01/04/2010 008: 'Nome XYZ0008'nascido em 01/04/2010 009: 'Nome XYZ0009'nascido em 01/05/2010 010: 'Nome XYZ0010'nascido em 01/05/2010 011: 'Nome XYZ0011'nascido em 01/06/2010 012: 'Nome XYZ0012'nascido em 01/06/2010 013: 'Nome XYZ0013'nascido em 01/07/2010 014: 'Nome XYZ0014'nascido em 01/07/2010 015: 'Nome XYZ0015'nascido em 01/08/2010 016: 'Nome XYZ0016'nascido em 01/08/2010 017: 'Nome XYZ0017'nascido em 01/09/2010 018: 'Nome XYZ0018'nascido em 01/09/2010 019: 'Nome XYZ0019'nascido em 01/10/2010 020: 'Nome XYZ0020'nascido em 01/10/2010 021: 'Nome XYZ0021'nascido em 01/11/2010 022: 'Nome XYZ0022'nascido em 01/11/2010 023: 'Nome XYZ0023'nascido em 01/12/2010 024: 'Nome XYZ0024'nascido em 01/12/2010 gravados 24 registros E para listar? Imagine uma função int xyz_filtra_uns(FILE* file, int mes, int ano); Você chama passando um mês e ano e ela vai no arquivo e lista os que satisfazem o critério. E retorna quantos ela leu. Se passar um ano ou mês inválido ela lista todo mundo assim não precisamos escrever outra função pra isso. Afinal a primeira coisa que vamos querer testar é se está lendo e gravando certo. O critério para o filtro é simples: Lista se o mês é inválido o ano é inválido o cara nasceu no mês e ano fornecido Veja um exemplo da função int xyz_filtra_uns(FILE* file, int mes, int ano) { Pessoa modelo; int sequencia = 1; int esse_sim = 0; // lista todo mundo que nasceu nesse mes e ano. Se // os valores forem invalidos lista todo mundo while ( 1 == fread(&modelo, sizeof(Pessoa), 1, file)) { // fread() retorna 1 se leu uma Pessoa /* aqui entra o criterio: lido ja foi: se passar pelo filtro mostra. se o mes ou o ano forem invalidos lista todo mundo assim não precsia escrever outra funcao e podemos testar logo de uma vez */ esse_sim = 0; if ((mes < 1) || (mes > 12)) esse_sim = 1; // if ((ano < 1919) || (ano > 2019) ) esse_sim = 1; // if ((modelo.mes == mes) && (modelo.ano == ano)) esse_sim = 1; if( esse_sim ) { printf( "%03d: '%s'nascido em %02d/%02d/%04d\n", sequencia, modelo.nome, modelo.dia, modelo.mes, modelo.ano ); sequencia += 1; } } // while return sequencia - 1; } // xyz_filtra_uns() Eis um programa de teste usando essas funções Criando o arquivo int total; arquivo = xyz_abrir_arquivo("coisa.txt", "w"); // abre para gravar os caras total = xyz_grava_uns(arquivo, 2010, 1, 2, 1000); // grava printf("gravados %d registros\n", total); fclose(arquivo); // fecha Mostraria Arquivo coisa.txt aberto com sucesso 001: 'Nome XYZ0001'nascido em 01/01/2010 002: 'Nome XYZ0002'nascido em 01/01/2010 003: 'Nome XYZ0003'nascido em 01/02/2010 004: 'Nome XYZ0004'nascido em 01/02/2010 005: 'Nome XYZ0005'nascido em 01/03/2010 006: 'Nome XYZ0006'nascido em 01/03/2010 007: 'Nome XYZ0007'nascido em 01/04/2010 008: 'Nome XYZ0008'nascido em 01/04/2010 009: 'Nome XYZ0009'nascido em 01/05/2010 010: 'Nome XYZ0010'nascido em 01/05/2010 011: 'Nome XYZ0011'nascido em 01/06/2010 012: 'Nome XYZ0012'nascido em 01/06/2010 013: 'Nome XYZ0013'nascido em 01/07/2010 014: 'Nome XYZ0014'nascido em 01/07/2010 015: 'Nome XYZ0015'nascido em 01/08/2010 016: 'Nome XYZ0016'nascido em 01/08/2010 017: 'Nome XYZ0017'nascido em 01/09/2010 018: 'Nome XYZ0018'nascido em 01/09/2010 019: 'Nome XYZ0019'nascido em 01/10/2010 020: 'Nome XYZ0020'nascido em 01/10/2010 021: 'Nome XYZ0021'nascido em 01/11/2010 022: 'Nome XYZ0022'nascido em 01/11/2010 023: 'Nome XYZ0023'nascido em 01/12/2010 024: 'Nome XYZ0024'nascido em 01/12/2010 gravados 24 registros Lista todo mundo arquivo = xyz_abrir_arquivo("coisa.txt", "r"); // abre para ler total = xyz_filtra_uns(arquivo, 0, 0); // mes ou ano invalido lista todo mundo printf("lidos %d registros\n", total); fclose(arquivo); Mostraria Arquivo coisa.txt aberto com sucesso 001: 'Nome XYZ0001'nascido em 01/01/2010 002: 'Nome XYZ0002'nascido em 01/01/2010 003: 'Nome XYZ0003'nascido em 01/02/2010 004: 'Nome XYZ0004'nascido em 01/02/2010 005: 'Nome XYZ0005'nascido em 01/03/2010 006: 'Nome XYZ0006'nascido em 01/03/2010 007: 'Nome XYZ0007'nascido em 01/04/2010 008: 'Nome XYZ0008'nascido em 01/04/2010 009: 'Nome XYZ0009'nascido em 01/05/2010 010: 'Nome XYZ0010'nascido em 01/05/2010 011: 'Nome XYZ0011'nascido em 01/06/2010 012: 'Nome XYZ0012'nascido em 01/06/2010 013: 'Nome XYZ0013'nascido em 01/07/2010 014: 'Nome XYZ0014'nascido em 01/07/2010 015: 'Nome XYZ0015'nascido em 01/08/2010 016: 'Nome XYZ0016'nascido em 01/08/2010 017: 'Nome XYZ0017'nascido em 01/09/2010 018: 'Nome XYZ0018'nascido em 01/09/2010 019: 'Nome XYZ0019'nascido em 01/10/2010 020: 'Nome XYZ0020'nascido em 01/10/2010 021: 'Nome XYZ0021'nascido em 01/11/2010 022: 'Nome XYZ0022'nascido em 01/11/2010 023: 'Nome XYZ0023'nascido em 01/12/2010 024: 'Nome XYZ0024'nascido em 01/12/2010 lidos 24 registros Lista os que nasceram em 09/2010 // ja que deu certo listar todos vamos testar com um intervalo arquivo = xyz_abrir_arquivo("coisa.txt", "r"); // abre para ler total = xyz_filtra_uns(arquivo, 9, 2010); // setembro de 2010 printf("\"filtrados\" %d registros\n", total); fclose(arquivo); Mostraria Arquivo coisa.txt aberto com sucesso 001: 'Nome XYZ0017'nascido em 01/09/2010 002: 'Nome XYZ0018'nascido em 01/09/2010 "filtrados" 2 registros Tenta listar os que nasceram em 09/2018, e não deve ter nenhum // e testamos para um valor que nao tem no arquivo arquivo = xyz_abrir_arquivo("coisa.txt", "r"); // abre para ler total = xyz_filtra_uns(arquivo, 9, 2018); // setembro de 2010 printf("\"filtrados\" %d registros\n", total); fclose(arquivo); Mostraria Arquivo coisa.txt aberto com sucesso "filtrados" 0 registros Claro que esses testes todos são apenas recortar e colar e mudar um parâmetro, e você testa um por vez. E partir daí assim você pode continuar com o programa sabendo que vai ler, gravar e filtrar, sem perder tempo com menu, cursor, cores, seek(), rewind() ftell(), scanf(), abrir e fechar arquivos e tal. De modo similar você escreve o resto, menu, cadastro e fim. Eis o programa de teste #define _CRT_SECURE_NO_WARNINGS #include <stdio.h> struct reg_pessoa { char nome[30]; int dia, mes, ano; }; typedef struct reg_pessoa Pessoa; FILE* arquivo; Pessoa p; FILE* xyz_abrir_arquivo(char* nome, char* modo); int xyz_filtra_uns(FILE*, int mes, int ano); int xyz_grava_uns(FILE* file, int ano, int quantos_anos, int quantos_por_mes, int maximo); int main( int argc, char** argv ) { int total; arquivo = xyz_abrir_arquivo("coisa.txt", "w"); // abre para gravar os caras total = xyz_grava_uns(arquivo, 2010, 1, 2, 1000); // grava printf("gravados %d registros\n", total); fclose(arquivo); // fecha arquivo = xyz_abrir_arquivo("coisa.txt", "r"); // abre para ler total = xyz_filtra_uns(arquivo, 0, 0); // mes ou ano invalido lista todo mundo printf("lidos %d registros\n", total); fclose(arquivo); // ja que deu certo listar todos vamos testar com um intervalo arquivo = xyz_abrir_arquivo("coisa.txt", "r"); // abre para ler total = xyz_filtra_uns(arquivo, 9, 2010); // setembro de 2010 printf("\"filtrados\" %d registros\n", total); fclose(arquivo); // e testamos para um valor quenao tem no arquivo arquivo = xyz_abrir_arquivo("coisa.txt", "r"); // abre para ler total = xyz_filtra_uns(arquivo, 9, 2018); // setembro de 2010 printf("\"filtrados\" %d registros\n", total); fclose(arquivo); return 0; } FILE* xyz_abrir_arquivo(char* nome, char* modo) { arquivo = fopen(nome, modo); if (arquivo == NULL) { perror("Erro ao tentar abrir o arquivo"); } else { printf("Arquivo %s aberto com sucesso\n", nome); }; return arquivo; }; int xyz_filtra_uns(FILE* file, int mes, int ano) { Pessoa modelo; int sequencia = 1; int esse_sim = 0; // lista todo mundo que nasceu nesse mes e ano. Se // os valores forem invalidos lista todo mundo while ( 1 == fread(&modelo, sizeof(Pessoa), 1, file)) { // fread() retorna 1 se leu uma Pessoa /* aqui entra o criterio: lido ja foi: se passar pelo filtro mostra. se o mes ou o ano forem invalidos lista todo mundo assim não precsia escrever outra funcao e podemos testar logo de uma vez */ esse_sim = 0; if ((mes < 1) || (mes > 12)) esse_sim = 1; // if ((ano < 1919) || (ano > 2019) ) esse_sim = 1; // if ((modelo.mes == mes) && (modelo.ano == ano)) esse_sim = 1; if( esse_sim ) { printf( "%03d: '%s'nascido em %02d/%02d/%04d\n", sequencia, modelo.nome, modelo.dia, modelo.mes, modelo.ano ); sequencia += 1; } } // while return sequencia - 1; } // xyz_filtra_uns() int xyz_grava_uns(FILE* file, int ano, int quantos_anos, int quantos_por_mes, int maximo) { int sequencia = 1; Pessoa modelo; modelo.dia = 1; // nao faz diferenca no teste if (file == NULL) return -1; for (int a = 0; a < quantos_anos; a += 1) { modelo.ano = ano + a; // cria registros para esse ano for (int m = 1; m <= 12; m += 1) { modelo.mes = m; // cria para esse mes for (int n = 0; n < quantos_por_mes; n += 1) { sprintf(modelo.nome, "Nome XYZ%04d", sequencia); printf( "%03d: '%s'nascido em %02d/%02d/%04d\n", sequencia, modelo.nome, modelo.dia, modelo.mes, modelo.ano ); fwrite(&modelo, sizeof(Pessoa), 1, file); if (sequencia >= maximo) return 0; sequencia = sequencia + 1; } // for n } // for m } // for a return sequencia - 1; }; // xyz_grava_uns() // fim do texto
-
@allison vasconcelos Talvez pudesse postar sua dificuldade e a parte relevante do código, de modo que alguém possa ajudar. Implementou já a parte da árvore? Se não fez isso recomendo muito fazer isso em separado, sem misturar com a lógica de seu programa
-
Olá Notei que não usa parâmetros em suas funções. É de propósito ou ainda não aprendeu isso? Veja essas duas funções por exemplo: void abrir_arquivo() { parq = fopen("teste", "ab+"); if (parq == NULL) { printf("Erro ao acessar o arquivo"); } else { printf("Arquivo aberto com sucesso"); } } void ler_arquivo() { parq = fopen("teste", "r"); if (parq == NULL) { printf("Erro ao acessar o arquivo"); } else { printf("Arquivo lido com sucesso\n"); } } Podia escrever void abre_arquivo(char* modo) { parq = fopen("teste", modo); if (parq == NULL) { printf("Erro ao acessar o arquivo"); } else { printf("Arquivo lido com sucesso\n"); } } E se entendeu isso, aí pode entender que é melhor não misturar a lógica com o processamento de arquivo e pode tirar a leitura de valores da função de listar_nascidos() por exemplo, e fica muito mais fácil e rápido para testar. Use por exemplo void listar_nascidos(int mes, int ano); E use um parâmetro inválido para listar todos, (tipo mes == 0). Assim pode chamar direto listar_nascidos(0,0); listar_nascidos(10,90); por exemplo, em seus testes adicionado 4 minutos depois resposta() não pode ser declarado como void se pretende retornar um char, então use char resposta();
-
C Conversão de numero natural para binário com recursão - C
arfneto respondeu ao tópico de Reberth Siqueira em C/C#/C++
Olá Não há qualquer indicação de como retornar os valores, mas talvez ache mais flexível usar algo assim void i_to_strbin(int n, char** b) { if (n >= 1) { i_to_strbin((n / 2), b); int len = strlen(*b); *(*b + len) = n % 2 + '0'; *(*b + len + 1) = 0; } } // i_to_strbin() Onde você passa em b o endereço de uma string vazia e com tamanho suficiente para conter o valor, e recebe a string em b correspondendo ao valor em binário de n, como esperado. É a mesma coisa? Sim, mas nesse caso pode usar o resultado --- retornado na string *b --- como preferir. No caso dessa função bin() só imprime via printf() separando cada dígito por um espaço. Veja esse resultado para alguns valores conhecidos 1 em binario = [1] 2 em binario = [10] 3 em binario = [11] 4 em binario = [100] 5 em binario = [101] 6 em binario = [110] 7 em binario = [111] 8 em binario = [1000] 127 em binario = [1111111] 32767 em binario = [111111111111111] 2147483647 em binario = [1111111111111111111111111111111] 1073741824 em binario = [1000000000000000000000000000000] Com essa função e esse programa de teste: int main(int argc, char** argv) { int i; for ( i = 1; i <= 8; i+=1) { testa_com(i); } testa_com(127); testa_com(SHRT_MAX); testa_com(INT_MAX); testa_com(1 + INT_MAX/2); return 0; } // main() Eis o programa todo #define _CRT_SECURE_NO_WARNINGS #include "limits.h" #include "stdio.h" #include "string.h" void i_to_strbin(int, char**); void testa_com(int); int main(int argc, char** argv) { int i; for (i = 1; i <= 8; i += 1) { testa_com(i); } testa_com(127); testa_com(SHRT_MAX); testa_com(INT_MAX); testa_com(1 + INT_MAX / 2); return 0; }; // main() void i_to_strbin(int n, char** b) { if (n >= 1) { i_to_strbin((n / 2), b); int len = strlen(*b); *(*b + len) = n % 2 + '0'; *(*b + len + 1) = 0; } }; // i_to_strbin() void testa_com(int i) { char v[80]; char* p = v; v[0] = 0; i_to_strbin(i, &p); printf("%i em binario = [%s]\n", i, p); return; }; // testa_com() limits.h é o header onde estão essas constantes limite como INT_MAX e SHRT_MAX . -
Sim. Exatamente como descreveu. Por definição uma lista circular é assim, circular, e o processamento segue infinitamente. Não tem um NULL exceto para o momento em que a lista está vazia. A menor lista circular tem um nó, que é o caso de qualquer lista. A gente usa muito isso em processos em que a prioridade é do lado do atendimento, então você tem uma fila em que você não recusa ninguém, atende o primeiro e eventualmente descarta o mais antigo quando atinge uma certa capacidade.
-
Essa é uma situação folclórica mas um pouco simplificada porque as duas listas que serão abstração das engrenagens então já devem ser criadas com tamanho fixo e completas, e com talvez um único dado que seria o número do dente. divertido isso
-
Olá (imaginando que não possa usar nenhuma das estruturas que já tem disponíveis em C++ na STL, como listas, mapas e coisas assim) apenas crie algo como um vetor de tarefas, com nome e descrição, algo mínimo. E ao iniciar o programa tente ler do arquivo para essa estrutura na memória as tarefas já existentes. Ao inserir uma nova coloque já na ordem no vetor ou na estrutura que escolheu. E ao final grava tudo em disco na ordem, em um arquivo novo. Muda o nome do antigo para algo como .old e aí mude o nome do novo para o nome original. Nada original, mas funciona.
-
Olá listas circulares em especial quando tem uma capacidade limitada --- buffers circulares comuns em áudio/vídeo/transmissão --- são uma estrutura curiosa, em especial quando tem iteradores e a estrutura ainda não está cheia. Mas no caso de uma lista encadeada circular talvez seja mais simples ter ao inserir já dois ponteiros e um indicador marcando qual o sentido atual, e uma disciplina marcando se uma operação de inserção ocorre no fim ou no começo, que vai ser o mesmo lugar: um novo elemento será o primeiro ou o último --- como em pilhas FIFO/LIFO --- e o resto. E o sentido inicial seria um prâmetro agregado à estrutura, como a capacidade e o tamanho O resto da implementação seguiria igual, eu acho,escrevendo sem pensar muito adicionado 8 minutos depois Então tem uma necessidade objetiva de inverter uma lista encadeada apenas, e não está de fato usando uma lista circular? Nesse caso basta adaptar a função que lista imprime*(). Como não tem ponteiros para o outro lado ao passar para cada terceiro nó pode inverter os ponteiros dos dois anteriores porque não há outro vínculo exceto o único ponteiro mesmo. O início da lista vai ao final apontar claro para NULL, e ao encontrar o fim da lista original esse será o novo início... Pode testar com a técnica que se usa para classificar listas por vários critérios quando a estrutura é muito grande: cria uma nova lista sem estrutura, apontando apenas para os nós da lista original, e assim pode conferir o resultado sem risco porque se zoar os ponteiros antes de testar tudo já era: deve perder tudo.
-
C Alterar cadastro dentro da struct do Arquivo Binário
arfneto respondeu ao tópico de gabrielzin44 em C/C#/C++
Acho que é o mais simples. Mais um palpite: evite misturar o código que trata os dados com o que trata a estrutura. Coisas como ler e escrever no terminal no meio da inserção por exemplo. Menus, endereçar cursor, escolher cores. Escolha uma estrutura e implemente as funções. Teste. O simples: primeiro a que insere depois a que lista pra poder conferir depois a que apaga, depois a que altera. Depois tente salvar e ler a estrutura. Depois junte tudo na lógica de seu programa. Tem muitas referêrncias on-line. Estruturas de dados é um campo enorme. Aqui neste forum acho que eu mesmo postei uma implementação completa de lista em C ou C++. -
Entendeu o comportamento da função? Alguns autores dizem que ela "consome" a entrada em busca do que está tentando ler e nesse caminho ela pode descartar coisas como linhas inteiras e espaços em branco. Ou deixa o usuário teclando ENTER a vida inteira e não retorna...









Sobre o Clube do Hardware
No ar desde 1996, o Clube do Hardware é uma das maiores, mais antigas e mais respeitadas comunidades sobre tecnologia do Brasil. Leia mais
Direitos autorais
Não permitimos a cópia ou reprodução do conteúdo do nosso site, fórum, newsletters e redes sociais, mesmo citando-se a fonte. Leia mais
