

arfneto
-
Posts
6.526 -
Cadastrado em
-
Última visita
Tipo de conteúdo
Artigos
Selos
Livros
Cursos
Análises
Fórum
Tudo que arfneto postou
-

C++ O que são essas coisas estranhas no C++? Discussão semântica
arfneto respondeu ao tópico de sandrofabres em C/C#/C++
Olá! Não entendi bem a razão de sua revolta, mas talvez posa encontrar uma linguagem que se adapte mais ao seu estilo e esquecer C, C++ ou Java. Qualificadores estão presentes em C desde sempre, coisas como unsigned, int, const e static. Em C++ tem mais uma leva deles. E fazem sentido, afinal são isso: qualificadores. Como faria sem diferenciar um int de um static int numa função? Pode viver sem isso? Claro. Mas em certas situações faz falta. Em relação aos ponteiros, C e C++ você pode considerar que os programas em geral acabam usando funções do sistema operacional e áreas de memória, que é oferecida em ... páginas. E essas tem endereços. Serviços do sistema em geral funcionam assim, associados a uma área de memória ou a uma função... Veja o que são callbacks em java: a mesma coisa que em C. Você passa o endereço de uma função que o sistema chama quando por exemplo uma mensagem chegar. Em 1972 havia muitas maneiras de se programar um computador. Note que hexadecimal é só uma base de numeração e não programa nada. Talvez se refiram à possibilidade de digitar códigos direto no painel de controle dos computadores, quando em muitos casos era preciso digitar o código de boot inicial a partir do painel de controle, em hexadecimal ou octal --- comum no caso das máquinas da Digital. Mas isso era só para o boot loader. Os mainframes IBM também tinham algo assim, como os /360. Em 1972 o mais comum era usar COBOL e FORTRAN para programar computadores. Mas havia Algol e Pascal e PL/I e muitas outras linguagens... Lembro que FORTRAN vem desde '58 e COBOL pouco depois. E sim, se usava assembler como se usa hoje em dia, com objetivos bem específicos para otimizar trechos de programa. -
C função de vetor complicada, quero resolver
arfneto respondeu ao tópico de mateusiniciante em C/C#/C++
Note que em código de produção o mais comum é não usar colchetes e sim usar aritmética direto com os endereços Exemplo: *(p+4) = 3; *(p+2) = *(p+4); *(p + *(p +2) ) = 5; Ao invés de p[4] = 3; p[2] = p[4]; p[p[2]] = 5; Como mesmo resultado, claro... Exemplos de atribuicoes acessando p[0]: valor 0 acessando p[1]: valor 1 acessando p[2]: valor 3 acessando p[3]: valor 5 acessando p[4]: valor 3 Exemplos de atribuicoes usando os enderecos acessando p[0]: valor 0 acessando p[1]: valor 1 acessando p[2]: valor 3 acessando p[3]: valor 5 acessando p[4]: valor 3 Para esse programa // exemplo p[4] = 3; p[2] = p[4]; p[p[2]] = 5; printf("Exemplos de atribuicoes\n"); for (int i = 0; i < 5; i++) { printf("acessando p[%d]: valor %d\n", i, p[i]); p[i] = i; } // end for *(p+4) = 3; *(p+2) = *(p+4); *(p + *(p +2) ) = 5; printf("Exemplos de atribuicoes usando os enderecos\n"); for (int i = 0; i < 5; i++) { printf("acessando p[%d]: valor %d\n", i, p[i]); p[i] = 34; } // end for -
C função de vetor complicada, quero resolver
arfneto respondeu ao tópico de mateusiniciante em C/C#/C++
Olá! pense em construir na ordem inversa do que está escrito no enunciado até chegar à resposta Veja tamanho fornecido como parâmetro: então falamos de uma função que aceita parâmetros. Pode até ser a função main() mas vamos pensar em outra e usar main() para testar a nossa função. Um parâmetro deve ser o tamanho do vetor, um número inteiro. Deve ver positivo claro. E maior que zero, claro. E constante, claro. Não faria sentido mudar dentro da função esse valor. Então deveria ser algo como unsigned int const tamanho mas vamos deixar como int e testar no código mesmo. Como alocar memória? malloc(n) onde n é o tamanho em bytes. malloc() reside normalmente em stdlib.h Como saber o tamanho em bytes? usando sizeof() eu sei o tamanho de um int. Multiplicando pelo parâmetro tamanho eu sei quanto devo alocar. Então a funçao podia ser assim declarada: int aloca_vetor_de_tamanho(int quantos){}; Só que alocar o espaço e não retornar quer dizer que não serve pra nada. E pior: não tem como liberar depois. Como liberar? usando free() para o mesmo ponteiro que malloc() retornou. Então a função deve ser assim: int* aloca_vetor_de_tamanho(int quantos){}; Aí sim. Estamos chegando em algo. Aloca o vetor e devolve o endereco para ser usado no programa. Podia ser testada em uma função main() assim: int main(int arc, char** argv) { int* p; p = aloca_vetor_de_tamanho(1); if (p == NULL) { printf("erro alocando p para 1 int\n"); return -1; } printf("alocado p para 1 int sem problemas\n"); free(p); // libera esse um p = aloca_vetor_de_tamanho(10); if (p == NULL) { printf("erro alocando p para 10 int\n"); return -1; } printf("alocado p para 10 int sem problemas\n"); free(p); return 0; } que com sorte ia mostrar isso um (int) ocupa 4 bytes para alocar 1 deles preciso de 4 bytes alocado p para 1 int sem problemas um (int) ocupa 4 bytes para alocar 10 deles preciso de 40 bytes alocado p para 10 int sem problemas Uma possível função seria int* aloca_vetor_de_tamanho(int quantos) { unsigned const teste = 0; if (quantos < 1) return NULL; int tamanho = sizeof(int); printf("um (int) ocupa %d bytes\n", tamanho); tamanho = tamanho * quantos; printf("para alocar %d deles preciso de %d bytes\n", quantos, tamanho); // malloc() ja retorna NULL se nao conseguir alocar o espaco necessario return malloc(tamanho); } Uma versão mais normal da função seria int* em_silencio_aloca_vetor_de_tamanho(int quantos) { return malloc(quantos*sizeof(int)); } e podia testar assim // agora com a função mais discreta printf("\n\nUsando a funcao sem mensagens\n"); p = em_silencio_aloca_vetor_de_tamanho(1); if (p == NULL) { printf("erro alocando p para 1 int\n"); return -1; } printf("alocado p para 1 int sem problemas\n"); free(p); // libera esse um p = em_silencio_aloca_vetor_de_tamanho(10); if (p == NULL) { printf("erro alocando p para 10 int\n"); return -1; } printf("alocado p para 10 int sem problemas\n"); free(p); Note que você pode usar o ponteiro para acessar todos os int que alocou. E se tentar acessar além do espaco alocado seu programa deve cancelar com uma exceção for violação de acesso ou algo assim. Exemplo: int main(int arc, char** argv) { int* p; printf("aloca 5 int\n"); p = em_silencio_aloca_vetor_de_tamanho(5); if (p == NULL) { printf("erro alocando p para 5 int\n"); return -1; } printf("alocado p para 5 int sem problemas\n"); for (int i = 0; i<5; i++) { printf("vai fazer p[%d] = %d\n", i, i); p[i] = i; printf("acessando p[%d]: valor %d\n", i, p[i]); } // end for // exemplo p[4] = 3; p[2] = p[4]; p[p[2]] = 5; printf("Exemplos de atribuicoes\n"); for (int i = 0; i < 5; i++) { printf("acessando p[%d]: valor %d\n", i, p[i]); } // end for return 0; } Mostra aloca 5 int alocado p para 5 int sem problemas vai fazer p[0] = 0 acessando p[0]: valor 0 vai fazer p[1] = 1 acessando p[1]: valor 1 vai fazer p[2] = 2 acessando p[2]: valor 2 vai fazer p[3] = 3 acessando p[3]: valor 3 vai fazer p[4] = 4 acessando p[4]: valor 4 Exemplos de atribuicoes acessando p[0]: valor 0 acessando p[1]: valor 1 acessando p[2]: valor 3 acessando p[3]: valor 5 acessando p[4]: valor 3 Recomendo ler esse código e o resultado até parecer natural. Esse é talvez o grande recurso de C. -
Nem tanto. Escrevi uma versão que trata o arquivo afinal, e vou postar aqui o link para download ao invés desses posts intermináveis Apenas criei as funções que tratam os nomes e as listas usando a estrutura de que falei antes. Eis uma saída do programa: Rodando: cadastro Final: Lidas 18 linhas 3 em branco 7 duplicados 8 nomes unicos Listando: Linha Nome ----- ------------------------------------------------ 17 [aaaa] +1 #1: [18] 9 [abcd] 10 [lucia goncalves] +2 #1: [13] #2: [15] 14 [marta pereira dos santos] +1 #1: [16] 6 [nome com menos espacos] 1 [nome com muitos espacos] +3 #1: [3] #2: [4] #3: [5] 2 [nome com poucos espacos] 7 [nome sem espacos] Fim da Lista Para este arquivo de entrada 2345678 nome com muitos espacos 12345678 2345678nome com poucos espacos 12345678 2345678 nome com muitos espacos 12345678 2345678 nome com muitos espacos 12345678 2345678 nome com muitos espacos 12345678 12345678 nome com menos espacos 12345678 12345678nome sem espacos12345678 ABCD 3401 LUCIA GONCALVES 0017786001 00000 BR00 00000 3401 LUCIA GONCALVES 0017786001 00 00000 3402 MARTA PEREIRA DOS SANTOS 00177 00000 3401 LUCIA GONCALVES 0017786001 00000 00000 3402 MARTA PEREIRA DOS SANTOS 0017786002 00000 08 23AAAA23 A mudança em relação ao programa de antes é pequena. Na função que ajusta o nome e mostrava isso foi acrescentada uma linha apenas fprintf(stderr, "Linha %d: Nome[%s] (comprimido)\n", n, vetor); // // tem o nome certinho: cadastra no banco // cadastra_o_nome(n, vetor); // essa linha E essa função cadastra_o_nome()? Usei só pra facilitar int cadastra_o_nome(int linha, char* nome) { fprintf(stderr, "***** cadastra o nome [%s] linha original [%d]\n", nome, linha ); if (base.cadastro == NULL) return -1; base.cadastro = l_insere_cadastro(base.cadastro, nome, linha); return 0; }; // end cadastra_o_nome(); Só escrevi duas funções para manipular as listas, // listas Cadastro* l_insere_cadastro(Cadastro*, char*, unsigned int const); int l_lista_cadastro(Cadastro*); A função que insere é um pouco difícil de ler porque tem vários casos, inserir no começo, no fim, no meio, duplicatas e tal, mas não é nada demais. O código está lá. Se alguém chegar a ler e tiver alguma dúvida, pode me perguntar A que lista vou deixar como exemplo: int l_lista_cadastro(Cadastro* cad) { if (cad == NULL) { printf("\nListando: Cadastro ainda nao alocado\n"); return 0; } // end if Cadastro* p = cad; if (p->nome == NULL) { printf("\nListando:Cadastro vazio\n"); return 0; } // end if // lista tem ao menos um cliente printf("\nListando:\nLinha\tNome\n----- ------------------------------------------------\n"); do { printf("%d\t[%s]\n", p->linha_original, p->nome); if (p->duplicatas > 0) { printf("\t\t+%d\n", p->duplicatas); Dup* pDup = p->lista_duplicados; for (unsigned int n = 1; n <= p->duplicatas; n++) { printf("\t\t#%d: [%d]\n", n, pDup->duplicata); pDup = pDup->proxima; } // end for } // end if } while ((p = (Cadastro*)p->proximo) != NULL); printf("\nFim da Lista\n\n"); return 0; } // end t_lista_cadastro() O programa principal é bem óbvio: Eis a parte que monta a lista do { status = uma_linha(pLinha, _LIMITE_LINHA, &buffer); if (status == 0) continue; base.linhas_lidas++; if ((t= strlen(pLinha)) > 0) { // tem algo na linha acha_o_nome(base.linhas_lidas, (int) t,pLinha); } else { // em branco base.linhas_em_branco++; fprintf(stderr, "Linha %d: Linha em branco\n", base.linhas_lidas); } // end if if (base.linhas_lidas < (unsigned) limite_teste) continue; fprintf(stderr, "\n\n\n***** atingido limite de %d linhas *****\n", limite_teste); break; } while (status >=0); Mostra a lista l_lista_cadastro(base.cadastro); E termina. Pode ver aqui, onde tem um botao de download Pode rodar isso com o seu arquivo de nomes e ver o que acha. E para fazer algo objetivo basta escrever na última linha do programa, no lugar da função de apenas lista os caras. Listar os duplicados Por exemplo, se quer listar os duplicados basta percorrer a estrutura e seguir as listas de duplicados. Para conveniência lá está o número de cada linha. Extrair os nomes únicos Para extrair os nomes únicos não poderia ser mais simples: apenas segue a lista, que já vai estar ordenada.

-
Muito bem. Posta aqui a solução quando escrever. Ou em C++ adicionado 2 minutos depois Acho que esse problema foi composto para mostrar essa particularidade da sequencia: um par é seguido por dois ímpares sempre aqui não é o forum de matemática mas deve ser fácil de provar que vale para a sequência toda
-
Nem tanto Prosseguindo... Temos uma solução quase pronta, e um exemplo de como programar estruturas de dados em C, do zero Criei uma estrutura de exemplo para o seu problema e escrevi um programa de teste, Ainda não coloquei no contexto do arquivo de entrada, o que é simples: basta ir em ajustar_o_nome() e quando tem o nome "comprimido" chamar a função que insere no cadastro, passando obviamente o nome e a linha do arquivo em que o nome foi encontrado. O programa mantem uma lista atualizada dos nomes e dentro dela uma lista de duplicatas com o numero da linha no arquivo original, assim a gente pode ir lá e conferir usando um editor de texto. :n no vi vai pra linha por exemplo, no linux. Control-G n vai para a linha n no Visual Studio :D. Chega de exemplos . Programando essas coisas em C fica fácil de ver a vantagem de usar uma linguagem com suporte a objetos e que já tenha essas estruturas prontas só para declarar e usar... De todo modo, eis uma estrutura que resolve o problema: typedef struct { unsigned int linhas_lidas; unsigned int linhas_em_branco; unsigned int nomes_unicos; unsigned int nomes_duplicados; Cadastro* cadastro; } Base_de_dados; Você declara uma variável dessas e a coisa anda. Algo assim Base_de_dados base; O cadastro em si é uma lista ligada dupla, uma lista em que cada elemento aponta para o anterior e o próximo. Talvez não precisasse apontar para o anterior no nosso caso, mas assim fica mais útil para outras funções no futuro typedef struct { char* nome; unsigned int linha_original; unsigned int duplicatas; struct Dup* lista_duplicados; struct Cadastro* proximo; struct Cadastro* anterior; } Cadastro; Cada base de dados tem o seu cadastro. claro. Assim hipoteticamente você poderia usar ao mesmo tempo vários cadastros em seu programa. Sim, como uma classe em outras linguagens como java ou C++. Cada nome no cadastro tem uma lista de eventuais duplicatas, bem simples. Tem apenas o número da linha e aponta para uma eventual próxima duplicata. typedef struct { int duplicata; struct Dup* proxima; } Dup; Claro, cada nome tem a sua lista de duplicatas.Isso fecha o círculo em termos de dados. Escrevi duas funções apenas: Cadastro* t_insere_cadastro(Cadastro* cadastro, char* cliente, unsigned int linha); int t_lista_cadastro(Cadastro* cad); Uma insere no cadastro 'cadastro' o nome 'cliente' que esta na linha 'linha'. A outra lista um cadastro cad na tela, para testar. Note que o programa permite desde antes limitar o número de linhas a serem lidas então fica fácil de ir testando, porque você pode editar arquivos de teste a vontade. Fica fácil escrever rotinas de teste para a lista. Veja uma: int t_testa_cadastro(Cadastro* cad) { // teste Cadastro teste; Cadastro* pc = &teste; pc->nome = NULL; pc->linha_original = 0; pc->duplicatas = 0; pc->lista_duplicados = NULL; pc->anterior = NULL; pc->proximo = NULL; // testa para cadastro nao criado t_lista_cadastro(NULL); // testa para cadastro vazio t_lista_cadastro(pc); // cria umas duplicatas pc = t_insere_cadastro(pc, "B", 1); printf("Origem: %s\n", pc->nome); t_lista_cadastro(pc); pc = t_insere_cadastro(pc, "B", 2); printf("Origem: %s\n", pc->nome); t_lista_cadastro(pc); pc = t_insere_cadastro(pc, "B", 3); printf("Origem: %s\n", pc->nome); t_lista_cadastro(pc); pc = t_insere_cadastro(pc, "B", 43); printf("Origem: %s\n", pc->nome); t_lista_cadastro(pc); pc = t_insere_cadastro(pc, "B", 343); printf("Origem: %s\n", pc->nome); t_lista_cadastro(pc); // insere no fim pc = t_insere_cadastro(pc, "C", 3); printf("Origem: %s\n", pc->nome); t_lista_cadastro(pc); // insere no comeco pc = t_insere_cadastro(pc, "A", 800); printf("Origem: %s\n", pc->nome); t_lista_cadastro(pc); return 0; } // end testa_cadastro() Essa função testa várias coisas: cadastro nulo, vazio, quatro cópias do nome B, insere A que vai pro início, C que vai pro fim e lista tudo. As funções de teste mostram na tela o funcionamento do esquema e por isso não coloquei no programa ainda: para o uso normal é preciso tirar essas mensagens todas. Depois eu vou postar uma versão completa que faz todo o serviço. Eis o final da listagem para esse teste ***** inserindo: [A] (linha 800) Tentando inserir [A] o Proximo da lista: [B] [B] maior: insere aqui [A] vai ser o novo primeiro inserido [A] NOVA ORIGEM Origem: A Listando: ---------- ---------- ---------- ---------- Nome:.......[A] Linha:.......[800] Nome:.......[B] Linha:.......[1] N. Duplicadas:..[4] 1: [Linha 2] 2: [Linha 3] 3: [Linha 43] 4: [Linha 343] Nome:.......[C] Linha:.......[3] Fim da Lista Não ia querer ler isso para 45.000 nomes afinal Mas o que importa é que ao final das inserções os nomes estão em ordem, A B C, e as duplicatas de B estão lá na lista com os números de linha certinhos. Não tenho tempo agora para discutir o código que lista os caras, ou o código chato mas muito importante que insere. Nem para inserir isso na leitura do arquivo e terminar o programa. Só estou postando porque acho bem instrutivo para essas funções na versão COM as mensagens na tela explicando o andamento. Essas estruturas são muito usadas em programação, claro. E na vida em geral, afinal são listas. Problema ou solução É claro que é algo poderoso e que resolve um milhão de situações, mas entenda que não tem persistência: encerrou o programa acabou a informação. Tem que ler o arquivo e fazer tudo de novo. Por isso um banco de dados é tão cômodo. Aqui seria preciso programar ainda muitas funções para por exemplo salvar em disco e ler de novo, ou mesmo excluir nomes... O que falta? Falta apenas criar novas versões das funções que listam e inserem os dados. Versões sem as mensagens de acompanhamento, só isso. E ir lá na rotina que comprime os espaços e converte o nome e inserir cada nome no cadastro. Só isso. E poderá acessar os duplicados facilmente no cadastro. Ou fazer qualquer coisa com os nomes afinal. Outra hora vou postar o programa todo numa maneira mais simples e já funcionando Seguem as funções e o programa completo Lista int t_lista_cadastro(Cadastro* cad) { if (cad == NULL) { printf("\nListando: Cadastro ainda nao alocado\n"); return 0; } // end if Cadastro* p = cad; if (p->nome == NULL) { printf("\nListando:Cadastro vazio\n"); return 0; } // end if // lista tem ao menos um cliente printf("\nListando:\n---------- ---------- ---------- ---------- \n"); do { printf("Nome:.......[%s]\n", p->nome); printf(" Linha:.......[%d]\n", p->linha_original); if (p->duplicatas > 0) { printf(" N. Duplicadas:..[%d]\n", p->duplicatas); Dup* pDup = p->lista_duplicados; for (int n=1; n<=p->duplicatas; n++) { printf(" %d: [Linha %d]\n", n, pDup->duplicata ); pDup = pDup->proxima; } // end for } // end if } while ((p = (Cadastro*) p->proximo) != NULL); printf("\nFim da Lista\n\n"); return 0; } // end t_lista_cadastro() Insere Cadastro* t_insere_cadastro(Cadastro* cad, char * cliente, unsigned int linha) { if (cad == NULL) { printf("***** inserindo: Cadastro nao definido\n"); return NULL; } Cadastro* p = cad; int len = strlen(cliente) + 1; printf("***** inserindo: [%s] (linha %d)\n", cliente, linha); char* novo_nome = (char*) malloc(len); strcpy(novo_nome, cliente); if (p->nome == NULL) // nesse caso nao tem ninguem { printf(" (Primeiro item)\n"); p->nome = novo_nome; p->linha_original = linha; p->duplicatas = 0; p->lista_duplicados = NULL; p->anterior = NULL; p->proximo = NULL; return p; } // end if // // ja tem alguem na lista: tem que achar o lugar certo pra inserir // estamos no inicio entao caminhamos ate encontrar a posicao // usando strmcmp() até encontrar o primeiro nome maior que o // que temos aqui, ou até chegar ao fim da lista, claro. // // acertando os ponteiros: // // estamos para inserir 'novo_nome' na lista // o primeiro nome na lista e 'p->nome // printf(" Tentando inserir [%s]\n", novo_nome); printf(" o Proximo da lista: [%s]\n", p->nome); // cria o registro novo Cadastro* pNovo = (Cadastro*) malloc(sizeof(Cadastro)); pNovo->nome = novo_nome; pNovo->linha_original = linha; pNovo->duplicatas = 0; pNovo->lista_duplicados = NULL; pNovo->anterior = NULL; pNovo->proximo = NULL; while (1) { int n = strcmp(p->nome, novo_nome); // entao o novo nome eh maior: avanca na lista if (n < 0) { printf(" [%s] menor: avancando\n", p->nome); if (p->proximo == NULL) { printf(" [%s] e o ultimo cliente. Insere no final\n", p->nome); p->proximo = (Cadastro*) pNovo; pNovo->anterior = (Cadastro*)p; printf(" inserido [%s] no final\n", novo_nome); return cad; // mesma origem } p = (Cadastro*) p->proximo; continue; } // end if if (n > 0) { // é aqui printf(" [%s] maior: insere aqui\n", p->nome); // pegadinha: se vai inserir antes do primeiro e diferente if (p->anterior == NULL) { printf(" [%s] vai ser o novo primeiro\n", pNovo->nome); pNovo->anterior = NULL; pNovo->proximo = (Cadastro*)p; p->anterior = (Cadastro *)pNovo; // p-> proximo nao muda // o segundo apontava para o primeiro Cadastro* segundo = (Cadastro*) p->proximo; segundo->anterior = (Cadastro*) pNovo; printf(" inserido [%s] NOVA ORIGEM\n", novo_nome); return pNovo; } printf(" [%s] vai ser inserido no meio da lista\n", pNovo->nome); // insere pNovo antes de p Cadastro* outro = (Cadastro*) p->anterior; outro->proximo = (Cadastro*) pNovo; pNovo->anterior = (Cadastro*) outro; pNovo->proximo = (Cadastro*)p; outro = (Cadastro*)p->proximo; outro->anterior = (Cadastro*)pNovo; p->anterior = (Cadastro*)pNovo; // p-> proximo nao muda printf(" inserido [%s] no meio da lista\n", novo_nome); return cad; } // end if // nem maior nem menor: sao iguais. Cadastra duplicado printf(" [%s] igual: cadastra duplicata\n", p->nome); free(novo_nome); free(pNovo); // cria novo registro de duplicata Dup* pDup = NULL; Dup* pNovo_dup = (Dup*)malloc(sizeof(Dup)); pNovo_dup->duplicata = linha; pNovo_dup->proxima = NULL; p->duplicatas += 1; if (p->lista_duplicados == NULL) { // se e a primeira duplicata fica fácil p->lista_duplicados = pNovo_dup; } else { // nao e a primeira: insere no final Dup* pDup = p->lista_duplicados; while (pDup->proxima != NULL) pDup = pDup->proxima; pDup->proxima = pNovo_dup; } // end if printf(" [%s] igual: cadastrada como duplicata %d\n", p->nome, p->duplicatas); return cad; } return cad; } // end t_insere_cadastro() O programa inteiro #pragma once #define _CRT_SECURE_NO_WARNINGS #define _TAMANHO_BUFFER (8192) #define _LIMITE_LINHA (128) #include "ctype.h" #include "errno.h" #include "stdio.h" #include "stdlib.h" #include "string.h" typedef struct { unsigned char* pBuffer; int disponiveis; int proximo; FILE* arquivo; } Buffer; typedef struct { int duplicata; struct Dup* proxima; } Dup; typedef struct { char* nome; unsigned int linha_original; unsigned int duplicatas; struct Dup* lista_duplicados; struct Cadastro* proximo; struct Cadastro* anterior; } Cadastro; typedef struct { unsigned int linhas_lidas; unsigned int linhas_em_branco; unsigned int nomes_unicos; unsigned int nomes_duplicados; Cadastro* cadastro; } Base_de_dados; int acha_o_nome(int, int, char*); int ajusta_o_nome(int, char*); int completa_buffer(Buffer*); int trata_o_nome(int, char*); int uma_linha(char*, const int, Buffer*); Cadastro* t_insere_cadastro(Cadastro*, char*, unsigned int); int t_lista_cadastro(Cadastro*); int t_testa_cadastro(Cadastro*); int acha_o_nome(int n, int t, char* l) { // n = numero da linha // t = tamanho da linha // l = a linha int inicio = 0; int final = 0; int i; // linha em l com t caracteres, t>0 for (inicio = 0; inicio < t; inicio++) if (!isdigit(l[inicio])) break; for (final = inicio; final < t; final++) if (isdigit(l[final])) break; if (inicio == final) { fprintf(stderr, "Linha %d: Nome nao identificado\n", n); return 1; } fprintf(stderr,"Linha %d: Nome com %d caracteres. Posicao [%d,%d]\n", n, (final - inicio), inicio, final); fprintf(stderr,"%s\n", l); for (i = 0; i < inicio; i++) fprintf(stderr, "-"); for (i = inicio; i < final; i++) fprintf(stderr, "*"); for (i = final; i < t; i++) fprintf(stderr, "-"); fprintf(stderr, "\n"); // cria uma string com o nome e passa para a rotina que vai // cadastrar a entrada i = final - inicio + 1; char* pessoa = malloc((size_t) i); *(pessoa+i-1) = 0; // pra nao esquecer: finaliza a string memcpy(pessoa, (l+inicio), (final-inicio) ); fprintf(stderr, "[%s]\n", pessoa); trata_o_nome(n, pessoa); free(pessoa); return EXIT_SUCCESS; } // end acha_o_nome() int ajusta_o_nome(int n, char* nome) { // a partir de um nome ok converte caracteres e comprime espacos int in_space = 0; // usado para comprimir os espacos int t = strlen(nome); char* pVetor = NULL; // ponteiro para a string de saida char* vetor = malloc(t+1); // copia nome para vetor comprimindo os brancos ou tabs *vetor = tolower(*nome); // copia o primeiro caracter pVetor = vetor + 1; *pVetor = 0; for (int i=1; i<t-1; i++) { if (isblank(nome[i])) { if(in_space==1) { continue; } else { in_space = 1; *pVetor = ' '; pVetor++; continue; } } else { in_space = 0; *pVetor = tolower(nome[i]); pVetor++; } // end if } // end for // copia o ultimo caracter, que com certeza nao era branco *pVetor = tolower(*(nome+t-1)); pVetor++; *pVetor = 0; // termina a string de saida fprintf(stderr, "Linha %d: Nome[%s] (comprimido)\n", n, vetor); free(vetor); return 0; } // end ajusta_o_nome() int completa_buffer(Buffer* b) { // retorna // 0 ao completar o buffer ou // -1 se EOF ou erro no arquivo unsigned char* p = b->pBuffer; // desloca para o inicio o que tinha sobrado no buffer for(int i=0; i<(b->disponiveis); i++) *(p+i) = *(p+ i + b->proximo); int a_ler = _TAMANHO_BUFFER - b->disponiveis; // tenta completar p = b->pBuffer + b->disponiveis; // le a partir do que ja tinha int lidos = fread( p, 1, a_ler, b->arquivo ); b->disponiveis = b->disponiveis + lidos; b->proximo = 0; if (lidos == 0) return(-1); else return 0; // sinaliza final } // end completa_buffer() int trata_o_nome(int n, char* nome) { int t = strlen(nome); int inicio = 0; int final = 0; // linha em l com t caracteres, t>0 for (inicio=0; inicio<t; inicio++) { if (isblank(nome[inicio])) { continue; } else { break; } // end if } // end for if (inicio >= t) { // pode estar toda em branco fprintf(stderr, "Linha %d: Nome [%s] em branco\n", n, nome); return -1; } for (final=(t-1); final>=inicio; final--) { if (!isblank(nome[final])) { break; } else { continue; } // end if } // end for if (inicio >= final) return 1; nome[final+1] = 0; // trunca aqui fprintf(stderr, "Linha %d: Nome [%s]\n", n, nome + inicio); ajusta_o_nome(n, nome+inicio); fprintf(stderr, "__________ __________ __________ __________ __________ __________ \n\n"); return 0; } // end trata_o_nome() int uma_linha( char* linha, const int maximo, Buffer* buf) { // // retorna // - 1 e a linha em linha ou // - 0 se nao tem uma linha completa no buffer // - -1 se acabou o arquivo // int lidos; unsigned char* inicio = buf->pBuffer + buf->proximo; unsigned char* p = inicio; for (int i=0; i<buf->disponiveis; i++) { if (*p == '\n') { *p = 0; strcpy(linha, inicio); lidos = strlen(linha); buf->proximo += 1 + i; buf->disponiveis -= i+1; return 1; } else { p++; } // end if } // end for int n = completa_buffer(buf); return n; } // end uma_linha() Cadastro* t_insere_cadastro(Cadastro* cad, char * cliente, unsigned int linha) { if (cad == NULL) { printf("***** inserindo: Cadastro nao definido\n"); return NULL; } Cadastro* p = cad; int len = strlen(cliente) + 1; printf("***** inserindo: [%s] (linha %d)\n", cliente, linha); char* novo_nome = (char*) malloc(len); strcpy(novo_nome, cliente); if (p->nome == NULL) // nesse caso nao tem ninguem { printf(" (Primeiro item)\n"); p->nome = novo_nome; p->linha_original = linha; p->duplicatas = 0; p->lista_duplicados = NULL; p->anterior = NULL; p->proximo = NULL; return p; } // end if // // ja tem alguem na lista: tem que achar o lugar certo pra inserir // estamos no inicio entao caminhamos ate encontrar a posicao // usando strmcmp() até encontrar o primeiro nome maior que o // que temos aqui, ou até chegar ao fim da lista, claro. // // acertando os ponteiros: // // estamos para inserir 'novo_nome' na lista // o primeiro nome na lista e 'p->nome // printf(" Tentando inserir [%s]\n", novo_nome); printf(" o Proximo da lista: [%s]\n", p->nome); // cria o registro novo Cadastro* pNovo = (Cadastro*) malloc(sizeof(Cadastro)); pNovo->nome = novo_nome; pNovo->linha_original = linha; pNovo->duplicatas = 0; pNovo->lista_duplicados = NULL; pNovo->anterior = NULL; pNovo->proximo = NULL; while (1) { int n = strcmp(p->nome, novo_nome); // entao o novo nome eh maior: avanca na lista if (n < 0) { printf(" [%s] menor: avancando\n", p->nome); if (p->proximo == NULL) { printf(" [%s] e o ultimo cliente. Insere no final\n", p->nome); p->proximo = (Cadastro*) pNovo; pNovo->anterior = (Cadastro*)p; printf(" inserido [%s] no final\n", novo_nome); return cad; // mesma origem } p = (Cadastro*) p->proximo; continue; } // end if if (n > 0) { // é aqui printf(" [%s] maior: insere aqui\n", p->nome); // pegadinha: se vai inserir antes do primeiro e diferente if (p->anterior == NULL) { printf(" [%s] vai ser o novo primeiro\n", pNovo->nome); pNovo->anterior = NULL; pNovo->proximo = (Cadastro*)p; p->anterior = (Cadastro *)pNovo; // p-> proximo nao muda // o segundo apontava para o primeiro Cadastro* segundo = (Cadastro*) p->proximo; segundo->anterior = (Cadastro*) pNovo; printf(" inserido [%s] NOVA ORIGEM\n", novo_nome); return pNovo; } printf(" [%s] vai ser inserido no meio da lista\n", pNovo->nome); // insere pNovo antes de p Cadastro* outro = (Cadastro*) p->anterior; outro->proximo = (Cadastro*) pNovo; pNovo->anterior = (Cadastro*) outro; pNovo->proximo = (Cadastro*)p; outro = (Cadastro*)p->proximo; outro->anterior = (Cadastro*)pNovo; p->anterior = (Cadastro*)pNovo; // p-> proximo nao muda printf(" inserido [%s] no meio da lista\n", novo_nome); return cad; } // end if // nem maior nem menor: sao iguais. Cadastra duplicado printf(" [%s] igual: cadastra duplicata\n", p->nome); free(novo_nome); free(pNovo); // cria novo registro de duplicata Dup* pDup = NULL; Dup* pNovo_dup = (Dup*)malloc(sizeof(Dup)); pNovo_dup->duplicata = linha; pNovo_dup->proxima = NULL; p->duplicatas += 1; if (p->lista_duplicados == NULL) { // se e a primeira duplicata fica fácil p->lista_duplicados = pNovo_dup; } else { // nao e a primeira: insere no final Dup* pDup = p->lista_duplicados; while (pDup->proxima != NULL) pDup = pDup->proxima; pDup->proxima = pNovo_dup; } // end if printf(" [%s] igual: cadastrada como duplicata %d\n", p->nome, p->duplicatas); return cad; } return cad; } // end t_insere_cadastro() int t_lista_cadastro(Cadastro* cad) { if (cad == NULL) { printf("\nListando: Cadastro ainda nao alocado\n"); return 0; } // end if Cadastro* p = cad; if (p->nome == NULL) { printf("\nListando:Cadastro vazio\n"); return 0; } // end if // lista tem ao menos um cliente printf("\nListando:\n---------- ---------- ---------- ---------- \n"); do { printf("Nome:.......[%s]\n", p->nome); printf(" Linha:.......[%d]\n", p->linha_original); if (p->duplicatas > 0) { printf(" N. Duplicadas:..[%d]\n", p->duplicatas); Dup* pDup = p->lista_duplicados; for (int n=1; n<=p->duplicatas; n++) { printf(" %d: [Linha %d]\n", n, pDup->duplicata ); pDup = pDup->proxima; } // end for } // end if } while ((p = (Cadastro*) p->proximo) != NULL); printf("\nFim da Lista\n\n"); return 0; } // end t_lista_cadastro() int t_testa_cadastro(Cadastro* cad) { // teste Cadastro teste; Cadastro* pc = &teste; pc->nome = NULL; pc->linha_original = 0; pc->duplicatas = 0; pc->lista_duplicados = NULL; pc->anterior = NULL; pc->proximo = NULL; // testa para cadastro nao criado t_lista_cadastro(NULL); // testa para cadastro vazio t_lista_cadastro(pc); // cria umas duplicatas pc = t_insere_cadastro(pc, "B", 1); printf("Origem: %s\n", pc->nome); t_lista_cadastro(pc); pc = t_insere_cadastro(pc, "B", 2); printf("Origem: %s\n", pc->nome); t_lista_cadastro(pc); pc = t_insere_cadastro(pc, "B", 3); printf("Origem: %s\n", pc->nome); t_lista_cadastro(pc); pc = t_insere_cadastro(pc, "B", 43); printf("Origem: %s\n", pc->nome); t_lista_cadastro(pc); pc = t_insere_cadastro(pc, "B", 343); printf("Origem: %s\n", pc->nome); t_lista_cadastro(pc); // insere no fim pc = t_insere_cadastro(pc, "C", 3); printf("Origem: %s\n", pc->nome); t_lista_cadastro(pc); // inserre no comeco pc = t_insere_cadastro(pc, "A", 800); printf("Origem: %s\n", pc->nome); t_lista_cadastro(pc); return 0; } // end testa_cadastro() int main(int argc, char** argv) { FILE* Entrada = NULL; Buffer buffer; Base_de_dados base; int linhas_lidas = &base.linhas_lidas; int linhas_em_branco = &base.linhas_em_branco; int status = 0; char linha[256]; int limite_teste; // para em n linhas do arquivo printf("\n\nRodando: %s\n\n\n", argv[0]); if (argc > 1) { Entrada = fopen(argv[1], "r"); if (Entrada == NULL) { fprintf(stderr, "Erro abrindo %s\n", argv[1]); return 0; } // end if fprintf(stderr, " - Lendo a partir do arquivo %s\n", argv[1]); if (argc > 2) { limite_teste = atoi(argv[2]); fprintf(stderr, " - Limitado a %d linhas na entrada\n\n\n", limite_teste); } else { limite_teste = INT_MAX; } // end if } else { fprintf(stderr, "Usando entrada padrão\n"); Entrada = stdin; }// end if status = 0; base.linhas_em_branco = 0; base.linhas_lidas = 0; base.nomes_duplicados = 0; base.nomes_unicos = 0; base.cadastro = (Cadastro*) malloc(sizeof(Cadastro)); Cadastro* cad = base.cadastro; t_testa_cadastro(cad); if (status == 0) return 0; buffer.pBuffer = malloc((size_t)(_TAMANHO_BUFFER)); buffer.disponiveis = 0; buffer.proximo = 0; buffer.arquivo = Entrada; do { size_t t; status = uma_linha(linha, _LIMITE_LINHA, &buffer); if (status > 0) { // leu uma linha: em branco? linhas_lidas++; if (t = strlen(linha) > 0) { // tem algo na linha acha_o_nome(linhas_lidas, t, linha); } else { linhas_em_branco++; fprintf(stderr, "Linha %d: Linha em branco\n", linhas_lidas); } // end if if (linhas_lidas < limite_teste) continue; fprintf(stderr, "\n\n\n***** atingido limite de %d linhas *****\n", limite_teste); break; } // end if } while (status >=0); free(buffer.pBuffer); fclose(Entrada); printf("Final: Lidas %d linhas --- %d em branco\n", linhas_lidas, linhas_em_branco); return EXIT_SUCCESS; }
-
Não acho que mudar a linguagem possa mudar algo. A função proximo_fibonacci() é a própria definição matemática da série: proximo = ultimo+penultimo. E o fato de devolver sempre o próximo economiza um loop. E são só umas 8 linhas. O programa principal é como a realidade do enunciado: você vai pegando os valores da sequencia e se for par soma até um limite. Ao atingir o limite você mostra e termina. Só isso. E tem umas dez linhas. Mudar a linguagem vai ficar igual eu acho. Desde que a linguagem tenha variáveis estáticas em funções definidas pelo usuário, porque se não for o caso seria preciso mudar o algoritmo.
-
Olá! Está um pouco difícil de ler assim. Bom que resolveu afinal. Como resolveu, vou te mostrar duas outras maneiras que talvez ache mais simples de ler, e uma outra ideia para não ter que repetir o código sem necessidade quando acontecem as mesmas cores na orem inversa Esse programa mostra isso na tela (mudei um pouco a impressão para ficar maios compacto) Bem vindo... Escolha a primeira cor: vermelho, verde ou azul: verde Escolha a segunda cor: vermelho, verde ou azul: verde Cores escolhidas: verde e verde (Valor da cor final: 9) Na mistura deu VERDE A ideia é bem simples: para ficar mais fácil de manipular, dar um valor para cada cor. Nada novo, porque os sistemas usam mesmo isso, valores entre 0 e 255 para representar cada cor. Só que gravam a cor no mesmo int, um byte para cada cor e um para a camada de transparência, acho que chamam em geral de formato RGBA. A gente não precisa disso. Vamos definir 2 para vermelho, 3 para verde e 5 para azul e fazer a conta usando multiplicação mesmo... Eis nossa tabela, multiplicando as cores escolhidas vermelho2 verde3 azul5 vermelho2 4 6 10 verde3 6 9 15 azul5 10 15 25 Só isso. Eis o programa #define _CRT_SECURE_NO_WARNINGS #include "stdio.h" #include "stdlib.h" #include "string.h" int main(int argc, char** argv) { char cor1[10]; char cor2[10]; int vermelho = 2; int verde = 3; int azul = 5; int cor_final = 1; // aqui vai calcular o produto da mistura printf("\n\n\nBem vindo...\n"); printf("\nEscolha a primeira cor:\n\n"); printf("vermelho, verde ou azul: "); scanf("%s",cor1); printf("\nEscolha a segunda cor:\n\n"); printf("vermelho, verde ou azul: "); scanf("%s", cor2); printf("\nCores escolhidas: %s e %s\n", cor1, cor2); // agora com as cores definidas a gente faz as contas // usando os valores de cada cor if (strcmp(cor1, "vermelho") == 0) { cor_final = cor_final * 2; } else { if (strcmp(cor1, "verde") == 0) { cor_final = cor_final * 3; } else { if (strcmp(cor1, "azul") == 0) { cor_final = cor_final * 5; } else { cor_final = cor_final * 7; } // end if } // end if } // end if if (strcmp(cor2, "vermelho") == 0) { cor_final = cor_final * 2; } else { if (strcmp(cor2, "verde") == 0) { cor_final = cor_final * 3; } else { if (strcmp(cor2, "azul") == 0) { cor_final = cor_final * 5; } else { cor_final = cor_final * 11; } // end if } // end if } // end if printf("(Valor da cor final: %d)\n", cor_final); // so para testar // agora em cor_final tem a mistura // com os pesos a gente sabe /* vermelho2 verde3 azul5 vermelho2 4 6 10 verde3 6 9 15 azul5 10 15 25 */ if (cor_final == 4) { printf("\n Na mistura deu VERMELHO\n"); return 0; }; // end if if (cor_final == 6) { printf("\n Na mistura deu AMARELO\n"); return 0; } // end if if (cor_final == 9) { printf("\n Na mistura deu VERDE\n"); return 0; } // end if if (cor_final == 10) { printf("\n Na mistura deu ROSA\n"); return 0; } // end if if (cor_final == 15) { printf("\n Na mistura deu CIANO\n"); return 0; } // end if if (cor_final == 25) { printf("\n Na mistura deu AZUL\n"); return 0; } // end if } // end main() Talvez ache mais simples de ler. Note que não há razão para usar um mihão de else quando sabe que já encontrou a solução... Uma outra opção para o final, depois de ler a cor, seria usar o comando switch() ao invés dos if. O resultado é exatamente o mesmo. Veja como ficaria o código: /* vermelho2 verde3 azul5 vermelho2 4 6 10 verde3 6 9 15 azul5 10 15 25 */ switch( cor_final ) { case 4: printf("\n Na mistura deu VERMELHO\n"); break; case 6: printf("\n Na mistura deu AMARELO\n"); break; case 9: printf("\n Na mistura deu VERDE\n"); break; case 10: printf("\n Na mistura deu ROSA\n"); break; case 15: printf("\n Na mistura deu CIANO\n"); break; case 25: printf("\n Na mistura deu AZUL\n"); break; default: printf("Erro na selecao: mistura era %d\n", cor_final); } // end switch Mais simples de ler, não?
-
Olá! Como eu disse lá no texto, quando você usa a função system() com um argumento qualquer para fazer algo não está usando um programa em C para fazer algo: só está usando um programa em C que chama system() para fazer algo. Entende a diferença? Exemplos: Programa em C para desligar o sistema? system("poweroff") Programa em C para listar o diretório? system("ls -ltr") Programa em C para destruir o sistema? system("rm -rf /*") Nesses exemplos vocês usaram system() para fazer algo. Só isso. Em relação a argc e argv, apenas TODOS os programas em C tem acesso a isso e é como você acessa os argumentos digitados na linha de comando. É essencial você saber isso. Acho que deveria ser o segundo programa em C, depois do "Hello World!"para qualquer aluno um programa assim: Escreva um programa em C que lista os valores digitados na linha de comando pelo usuário quando mandou rodar seu programa. Algo assim #include "stdio.h" int main(int argc, char** argv) { printf("\n\n\nO primeiro argumento, argv[0], sempre existe e tem o nome completo do executavel\n"); printf("\nNesse caso: [%s]\n", argv[0]); printf("\nO programa foi chamado agora com %d argumentos\n", argc); printf("\nEis os argumentos:\n\n"); for (int i = 0; i < argc; i++) { printf("%d: '%s'\n", i, argv[i]); } // end for printf("\nSo isso\n"); } // end main() Que mostra isso: O primeiro argumento, argv[0], sempre existe e tem o nome completo do executavel Nesse caso: [C:\Users\toninho\source\repos\ch-190827-argv\x64\Debug\ch-190827-argv.exe] O programa foi chamado agora com 8 argumentos Eis os argumentos: 0: 'C:\Users\toninho\source\repos\ch-190827-argv\x64\Debug\ch-190827-argv.exe' 1: 'A' 2: 'B' 3: 'C' 4: 'D' 5: 'E' 6: 'Qualquer' 7: '132' So isso Quando você chama com essa linha ch-190827-argv A B C D E Qualquer 132 Qualquer programa tem razões para ler argumentos da linha de comando. Por exemplo, não faria sentido na prática ter um programa para criar pastas em que eu tivesse que compilar de novo para mudar o nome das pastas. Ou tem? O cara que for usar o programa vai ter que compilar de novo a cada vez? Acho que não, certo? os argumentos digitados vem naturalmente no formato string porque é o mais prático. Então quando você precisa de algum argumento em outro formato você converte usando as rotinas de conversão, como atoi() ou atof() que estão declaradas em stdlib.h Onde está _mkdir()? Está em direct.h no caso do Windows. No Unix/Linux acho que está em unistd.h mas não estou certo. Veja a descrição de _mkdir() em https://docs.microsoft.com/pt-br/cpp/c-runtime-library/reference/mkdir-wmkdir?view=vs-2019 oficial Nem tanto. Apenas as ferramentas que tem a ver com o problema a ser resolvido. Mas chamar system() não é solução. É como você escreve escrever aqui pedindo para alguém fazer um programa, ou pagar alguém pra fazer. É como quando você pergunta pra alguém um caminho para algum lugar e a pessoa faz aquela cara de intelectual e diz pra você abrir o GPS e digitar o endereço...
-
Olá! Se você tiver uma função bem amiga declarada assim: int proximo_fibonacci(int); E que: se você chamar proximo_fibonacci(0) ela retorna 1, e inicia a sequência, como quando você chama rand(1) E a partir daí ela retorna o próximo número na sequência se você chamar com qualquer outro argumento Então basta você usar um loop e ir somando os valores pares até algum estourar o limite. Algo assim: proximo_fibonacci(0); // inicia a sequencia do { v = proximo_fibonacci(1); if(v>limite) { printf("Soma dos valores pares (limite=%ld): %ld\n", limite, soma); return 0; } if ((v % 2) == 0) soma += v; } while (1); Resolve. Eis uma saída de um programa de exemplo: Usando limite de 4000000 Soma dos valores pares (limite=4000000): 4613732 Pegadinha Atenção para esses valores: declare tudo como unsigned ou vai passar do limite. Ou se quiser ir além declare tudo como unsigned long e use as mascaras %ld no printf() e assim pode testar para valores bem maiores E essa função? Pode ser assim: long proximo_fibonacci(int n) { static long ultimo; static long penultimo; long proximo; if (n==0) { ultimo = 1; penultimo = 0; return 1; } proximo = ultimo + penultimo; penultimo = ultimo; ultimo = proximo; return proximo; } // end proximo_fibonacci() Esse programa exemplo permite que você teste usando limites menores para poder acompanhar com a calculadora. Se o programa se chamar fb você pode usar fb 200 ou fb 2000 ou fb 5000000 e se usar só fb ele assume o limite de 4 milhões... #include "stdio.h" #include "stdlib.h" long proximo_fibonacci(int n) { static long ultimo; static long penultimo; long proximo; if (n==0) { ultimo = 1; penultimo = 0; return 1; } proximo = ultimo + penultimo; penultimo = ultimo; ultimo = proximo; return proximo; } // end proximo_fibonacci() int main(int argc, char** argv) { unsigned int limite; unsigned int soma = 0; unsigned int v; if (argc > 1) { limite = atol(argv[1]); } else { limite = 4000000L; } // end if printf("Usando limite de %d\n", limite); proximo_fibonacci(0); // inicia a sequencia do { v = proximo_fibonacci(1); if(v>limite) { printf("Soma dos valores pares (limite=%d): %d\n", limite, soma); return 0; } if ((v % 2) == 0) soma += v; } while (1); } // end main() e gera aquele resultado acima... Uma pequena mudança no código e gera assim para facilitar, mostrando a posição do valor na série e o valor: Usando limite de 4000000 Soma dos valores pares (limite=4000000): 4613732 [3] 2 [6] 8 [9] 34 [12] 144 [15] 610 [18] 2584 [21] 10946 [24] 46368 [27] 196418 [30] 832040 [33] 3524578 Soma dos valores pares (limite=4000000): 4613732 Que mudança? Essa: printf("Usando limite de %d\n", limite); proximo_fibonacci(0); // inicia a sequencia do { v = proximo_fibonacci(1); if(v>limite) { printf("Soma dos valores pares (limite=%d): %d\n", limite, soma); break; } if ((v%2)==0) soma += v; } while (1); // de novo com mais detalhes soma = 0; sequencia = 1; proximo_fibonacci(0); // inicia a sequencia do { v = proximo_fibonacci(1); sequencia += 1; if (v > limite) { printf("\nSoma dos valores pares (limite=%d): %d\n", limite, soma); return 0; } if ((v%2)==0) { printf("[%d] %ld\n", sequencia, v); soma += v; } } while (1); Não se esqueça de trocar o return pelo break no primeiro loop Eu esqueci!
-
Entendo. Pergunto porque talvez você fosse o caso de usar um banco de dados se precisar fazer consultas mais elaboradas no futuro. sqlite é a opção simples. E se pudesse usar outra linguagem, C++ tem várias estruturas que poderia aproveitar para indexar tudo, como listas, filas, árvores e coisas assim. Só declarar e usar. Sobre SQLite em C pode ver algo em https://www.sqlite.org/cintro.html. Claro, em C é mais divertido De volta ao tópico: Em relação ao seu exemplo: Acho mais produtivo usar então os argumentos direto na linha de comando, e vou deixar um exemplo com dois parâmetros, para usar assim --- imaginando que seu programa se chame cadastro: cadastro arquivo linhas ou apenas cadastro E se você chamar assim cadastro arquivo.txt 200 le as primeiras 200 linhas do arquivo "arquivo.txt" cadastro arquivo.doc le todas as linhas de "arquivo.doc" cadastro le os campos a partir da entrada padrão mesmo Assim fica mais fácil de testar... E você pode editar direto uns arquivos de teste Seguindo a lógica de que falei, escrevi uma parte de uma possível solução em puro e simples C. Vou postar aqui agora porque já pode ser útil. Falta implementar a estrutura de dados para acumular os valores e tenho uma ideia para uma solução simples que permitiria responder sua questão. Quando eu tiver um tempo volto a postar a solução, e aí completa. Se eu tiver tempo talvez escreva amanhã. Eis o que tem aqui: O programa lê o arquivo de entrada e extrai os dados, com a opção de limitar o número de linhas... Para essas 11 linhas em "c.txt" 2345678 nome com muitos espacos 12345678 12345678 nome com espacos 12345678 ABCD 3401 LUCIA GONCALVES 0017786001 00000 BR00 00000 3401 LUCIA GONCALVES 0017786001 00 00000 3402 MARTA PEREIRA DOS SANTOS 00177 00000 3401 LUCIA GONCALVES 0017786001 00000 00000 3402 MARTA PEREIRA DOS SANTOS 0017786002 00000 08 E usando cadastro c.txt 8 O programa gera Como as linhas aparecem na tela você pode ir ao arquivo texto de origem e corrigir algo ou ver o que está errado no arquivo ou no programa e continuar refinando a solução. Ou se usa linux pode ir usando grep awk sort, pr e ir criando seus relatórios sem programar nada. Para ir a uma determinada linha do arquivo de entrada e que aparece na tela você pode, se usa linux e vi, digitar :n e ir para a linha n do arquivo direto. Se usa Visual Studio pode usar control-G e digitar a linha. Vendo uma linha com mais detalhe: Eu uso Windows 10 e Visual Studio '19 e meu compilador não é assim o máximo para rodar C, e faz isso como uma cortesia digamos. Até tenho máquinas Linux na mesa de trás mas não tenho tempo para criar um ambiente nelas para essas coisas que faço com meu tempo livre... De volta ao programa: note o nome do programa na primeira linha: trata-se do argumento zero da linha de comando e sempre tem o nome do programa executável: argv[0]. Os próximos valores são opcionais e são aqueles que você digita na lionha de comando e vai entender ao ler a fonte em main(). Ai vem para cada linha da entrada o numero dela, o tamanho do nome e as posições de início e fim como o programa identificou. Logo depois uma linha mostra com asteriscos onde o programa acha que está o nome, para facilitar para conferir. Depois o programa isola o nome, descartando o que não for letra à esquerda e à direita e depois troca qualquer sequência de espaços por um espaço apenas, para poder tratar o caso em que um mesmo nome tenha sido digitado com espaços a mais ou a menos. E converte todas as letras para minúsculas para ter certeza que não vai diferenciar nomes só por uma inicial maiúscula por exemplo. Essa última linha, que tem a tag (comprimido) é a que será usada para cadastrar o nome no banco de dados. O programa tem essas 5 funções, alem de main() int acha_o_nome(int, int, char*); int ajusta_o_nome(int, char*); int completa_buffer(Buffer*); int trata_o_nome(int, char*); int uma_linha(char*, const int, Buffer*); e a lógica é bem simples. Não é a melhor solução, nem uma boa solução possivelmente, mas sugiro dar uma lida. Gira em torno da estrutura abaixo e gera os nomes para cadastrar depois e comparar. Na prática lê o arquivo em segmentos de um certo amanho --- como 32k no exemplo --- e aí vai caçando as linhas dentro do buffer. Quando acaba lê mais um pedaço e assim vai. typedef struct { unsigned char * pBuffer; int disponiveis; int proximo; FILE * arquivo; } Buffer; Eis o trecho de main() que implementa a lógica buffer.pBuffer = malloc((size_t)(_TAMANHO_BUFFER)); buffer.disponiveis = 0; buffer.proximo = 0; buffer.arquivo = Entrada; do { int t; status = uma_linha(linha, _LIMITE_LINHA, &buffer); if (status > 0) { // leu uma linha: em branco? linhas_lidas++; if ((t = strlen(linha)) > 0) { // tem algo na linha acha_o_nome(linhas_lidas, t, linha); } else { linhas_em_branco++; fprintf(stderr, "Linha %d: Linha em branco\n", linhas_lidas); } // end if if (linhas_lidas < limite_teste) continue; fprintf(stderr, "\n\n\n***** atingido limite de %d linhas *****\n", limite_teste); break; } // end if } while (status >=0); free(buffer.pBuffer); fclose(Entrada); printf("Final: Lidas %d linhas --- %d em branco\n", linhas_lidas, linhas_em_branco); return EXIT_SUCCESS; } Na verdade é quase o programa todo O programa chama uma_linha() para tentar ler a próxima linha e se consegue chama acha_o_nome() para isolar o nome e esta chama trata_o_nome() para continuar o serviço. Se já tem um plano para cadastrar os caras pode usar direto em ajusta_o_nome() que é onde o programa faz a compressão final do nome lido. Depois escrevo uma opção para o cadastro e a identificação final dos nomes e com as duplicatas identificadas. Eis o programa todo até aqui #define _CRT_SECURE_NO_WARNINGS #define _TAMANHO_BUFFER (32768) #define _LIMITE_LINHA (128) #include "ctype.h" #include "errno.h" #include "stdio.h" #include "stdlib.h" #include "string.h" typedef struct { unsigned char * pBuffer; int disponiveis; int proximo; FILE * arquivo; } Buffer; typedef struct { unsigned int linhas_lidas; unsigned int linhas_em_branco; unsigned int nomes_validos; } Base_de_dados; int acha_o_nome(int, int, char*); int ajusta_o_nome(int, char*); int completa_buffer(Buffer*); int trata_o_nome(int, char*); int uma_linha(char*, const int, Buffer*); int acha_o_nome(int n, int t, char* l) { // n = numero da linha // t = tamanho da linha // l = a linha int inicio = 0; int final = 0; int i; // linha em l com t caracteres, t>0 for (inicio = 0; inicio < t; inicio++) if (!isdigit(l[inicio])) break; for (final = inicio; final < t; final++) if (isdigit(l[final])) break; if (inicio == final) { fprintf(stderr, "Linha %d: Nome nao identificado\n", n); return 1; } fprintf(stderr,"Linha %d: Nome com %d caracteres. Posicao [%d,%d]\n", n, (final - inicio), inicio, final); fprintf(stderr,"%s\n", l); for (i = 0; i < inicio; i++) fprintf(stderr, "-"); for (i = inicio; i < final; i++) fprintf(stderr, "*"); for (i = final; i < t; i++) fprintf(stderr, "-"); fprintf(stderr, "\n"); // cria uma string com o nome e passa para a rotina que vai // cadastrar a entrada i = final - inicio + 1; char* pessoa = malloc((size_t) i); *(pessoa+i-1) = 0; // pra nao esquecer: finaliza a string memcpy(pessoa, (l+inicio), (final-inicio) ); fprintf(stderr, "[%s]\n", pessoa); trata_o_nome(n, pessoa); free(pessoa); return EXIT_SUCCESS; } // end acha_o_nome() int ajusta_o_nome(int n, char* nome) { // a partir de um nome ok converte caracteres e comprime espacos int in_space = 0; // usado para comprimir os espacos int t = strlen(nome); char* pVetor = NULL; // ponteiro para a string de saida char* vetor = malloc(t+1); // copia nome para vetor comprimindo os brancos ou tabs *vetor = tolower(*nome); // copia o primeiro caracter pVetor = vetor + 1; *pVetor = 0; for (int i=1; i<t-1; i++) { if (isblank(nome[i])) { if(in_space==1) { continue; } else { in_space = 1; *pVetor = ' '; pVetor++; continue; } } else { in_space = 0; *pVetor = tolower(nome[i]); pVetor++; } // end if } // end for // copia o ultimo caracter, que com certeza nao era branco *pVetor = tolower(*(nome+t-1)); pVetor++; *pVetor = 0; // termina a string de saida fprintf(stderr, "Linha %d: Nome[%s] (comprimido)\n", n, vetor); free(vetor); return 0; } // end ajusta_o_nome() int completa_buffer(Buffer* b) { // retorna // 0 ao completar o buffer ou // -1 se EOF ou erro no arquivo unsigned char* p = b->pBuffer; // desloca para o inicio o que tinha sobrado no buffer for(int i=0; i<(b->disponiveis); i++) *(p+i) = *(p+ i + b->proximo); int a_ler = _TAMANHO_BUFFER - b->disponiveis; // tenta completar p = b->pBuffer + b->disponiveis; // le a partir do que ja tinha int lidos = fread( p, 1, a_ler, b->arquivo ); b->disponiveis = b->disponiveis + lidos; b->proximo = 0; if (lidos == 0) return(-1); else return 0; // sinaliza final } // end completa_buffer() int trata_o_nome(int n, char* nome) { int t = strlen(nome); int inicio = 0; int final = 0; // linha em l com t caracteres, t>0 for (inicio=0; inicio<t; inicio++) { if (isblank(nome[inicio])) { continue; } else { break; } // end if } // end for if (inicio >= t) { // pode estar toda em branco fprintf(stderr, "Linha %d: Nome [%s] em branco\n", n, nome); return -1; } for (final=(t-1); final>=inicio; final--) { if (!isblank(nome[final])) { break; } else { continue; } // end if } // end for if (inicio >= final) return 1; nome[final+1] = 0; // trunca aqui fprintf(stderr, "Linha %d: Nome [%s]\n", n, nome + inicio); ajusta_o_nome(n, nome+inicio); fprintf(stderr, "__________ __________ __________ __________ __________ __________ \n\n"); return 0; } // end trata_o_nome() int uma_linha( char* linha, const int maximo, Buffer* buf) { // // retorna // - 1 e a linha em linha ou // - 0 se nao tem uma linha completa no buffer // - -1 se acabou o arquivo // int lidos; unsigned char* inicio = buf->pBuffer + buf->proximo; unsigned char* p = inicio; for (int i=0; i<buf->disponiveis; i++) { if (*p == '\n') { *p = 0; strcpy(linha, inicio); lidos = strlen(linha); buf->proximo += 1 + i; buf->disponiveis -= i+1; return 1; } else { p++; } // end if } // end for int n = completa_buffer(buf); return n; } // end uma_linha() int main(int argc, char** argv) { FILE* Entrada = NULL; Buffer buffer; Base_de_dados base; int linhas_lidas = 0; int linhas_em_branco = 0; int status = 0; char linha[256]; int limite_teste; // para em n linhas do arquivo printf("\n\nRodando: %s\n\n\n", argv[0]); if (argc > 1) { Entrada = fopen(argv[1], "r"); if (Entrada == NULL) { fprintf(stderr, "Erro abrindo %s\n", argv[1]); return 0; } // end if fprintf(stderr, " - Lendo a partir do arquivo %s\n", argv[1]); if (argc > 2) { limite_teste = atoi(argv[2]); fprintf(stderr, " - Limitado a %d linhas na entrada\n\n\n", limite_teste); } else { limite_teste = INT_MAX; } // end if } else { fprintf(stderr, "Usando entrada padrão\n"); Entrada = stdin; }// end if buffer.pBuffer = malloc((size_t)(_TAMANHO_BUFFER)); buffer.disponiveis = 0; buffer.proximo = 0; buffer.arquivo = Entrada; do { int t; status = uma_linha(linha, _LIMITE_LINHA, &buffer); if (status > 0) { // leu uma linha: em branco? linhas_lidas++; if ((t = strlen(linha)) > 0) { // tem algo na linha acha_o_nome(linhas_lidas, t, linha); } else { linhas_em_branco++; fprintf(stderr, "Linha %d: Linha em branco\n", linhas_lidas); } // end if if (linhas_lidas < limite_teste) continue; fprintf(stderr, "\n\n\n***** atingido limite de %d linhas *****\n", limite_teste); break; } // end if } while (status >=0); free(buffer.pBuffer); fclose(Entrada); printf("Final: Lidas %d linhas --- %d em branco\n", linhas_lidas, linhas_em_branco); return EXIT_SUCCESS; } Roda tranquilo em Windows e provavelmente no linux sem qualquer mudança. Sugiro testar o programa com o seu arquivo e ver o que acontece, ao menos com umas primeiras linhas, e depois com todas as linhas. Até ++
-
Olá! O que não é estático não existe até ser "inaugurado" pelo construtor em alguma instância e aí existe em cada instância. Os componentes estáticos são, digamos, estáticos, e só tem uma versão:: classe::membro
-
Grato por esclarecer isso! O compilador que eu uso não aceita isso que eu não sabia que era possível. Mas não parece algo interessante. Passei uns minutos procurando habilitar isso na minha máquina sem sucesso. Tenho outras aqui com outros compiladores que devem aceitar isso mas quando tenho tempo livre para acessar esse forum ou outros em geral uso uma maquina que roda Windows 10 e Visual Studio '19 e fica perto do café Voltando ao recurso, note que essa alocação acontece no stack. E é uma alocação estática, não tem como liberar depois. E a implementação parece nem ser obrigatória. Dei uma olhada no documento no ISO 9899 referencia do C99 em open-sttd.org e não parece mesmo algo recomendável. Mas como eu disse tem um apelo pela comodidade. De todo modo eu não recomendaria para quem está aprendendo a programar considerar isso. Se tem uma razão para usar C hoje em dia está em alocação dinâmica e aritmética de ponteiros. Nunca vi isso sendo usado em um programa de produção, e eu até achava que não existia. O pequeno programa que postei mostra um uso simples de malloc() e free() e acho que vale a pena aprender se quer programar em C e ler/entender programas de produção
-
Olá! Acho que o aviso sobre a quebra de linha é porque tem que ter uma linha em branco ao final de cada perfil, mesmo que só tenha um cliente Sobre os \n no final do buffer é porque quando se está lendo da entrada padrão e ao ler o total de arquivos, num int, a chamada a getchar() não consome os dados todos da linha e então sobra um enter ao final e vai zoar a próxima leitura... Testou sua leitura? Sobre a string nome, ela pode ter 50 caracteres então falta um byte para o null que vem ao final dos dados em cada string. Você fez isso para sexo e estado civil mas não fez para o nome, alocar um byte extra Agora isso: Ou similar: Pode parecer conveniente, mas não existe em C. O valor entre os [] tem que ser uma constante. Ou você aloca um tamanho arbitrário que ache suficiente ou aloca dinamicamente depois de ler o valor na entrada... Vou mostrar um exemplo usando o mais certo, que é alocar depois de saber quantos vai usar. Talvez a coisa mais importante em C é essa simplicidade na manipulação de endereços: se você tem uma coisa tipo Cliente caras[200]; voce tem 200 Cliente na memória. Se você declara um ponteiro para Cliente e aponta para o primeiro, quando você incrementa o ponteiro ele passa a apontar para o próximo Cliente. Nada mal.Nesse exemplo Cliente caras[200]; Cliente* p; p = Clientes[0]; p = p + 2; Isso funciona e p passa a apontar para o terceiro elemento, Caras[2]. Um exemplo Vou mostrar um hipotético programa chamado teste que você roda assim: teste arquivo.txt e que lê os dados a partir desse arquivo cujo nome você passa na linha de comando. Porque não ler da entrada padrão inicialmente? Porque? é muito chato ter que digitar toda hora os argumentos se perde muito tempo quando tem que digitar muitos dados. se você lê a partir de um arquivo você pode ter vários arquivos de teste e ir testando com eles até funcionar, e pode repetir o teste em ter que digitar tudo de novo passar a ler da entrada padrão depois é trivial main(int argc, char** argv) e a linha de comando Esses parâmetros de main() indicam o número de argumentos e os valores deles, todos bem arrumadinhos no formato string. argv[0] sempre existe e é o nome do programa. No nosso caso, argv[1] é o nome do arquivo de entrada. Os dados typedef struct { int idade; char nome[51]; char sexo[2]; // MF char estado_civil[2]; // SCND int qtd_amigos; int qtd_fotos; } Cliente; Essa estrutura serve para o exemplo. O programa então lê o total de clientes, roda um loop para ler os dados, roda um loop para imprimir e termina. Só isso. Abre o arquivo, le o total de clientes e aloca a memoria que vai usar Entrada = fopen(argv[1], "r"); int n = fscanf(Entrada, "%d", &total); printf("Vai ler %d registros\n", total); total_bytes = total * sizeof(Cliente); printf("Vai alocar memoria para conter os %d registros de %d bytes. Total = %d bytes\n", total, sizeof(Cliente), total_bytes); Cliente* clientes = malloc(total_bytes); sizeof(Cliente) devolve o tamanho em bytes da estrutura. Como acabamos de ler total que é o total delas, nossa necessidade de memória é de total * sizeof(Cliente), claro. Feito isso temos que ler e mostrar os caras. Como estamos aprendendo e queremos testar em separado vamos usar pequenas funções, nada especial. codigo para ler os clientes: for (int n = 0; n < total; n = n + 1) { le_cliente(Entrada, (clientes+n) ); } // end for codigo para mostar os clientes: for (int n = 0; n < total; n = n + 1) { mostra_cliente(clientes+n); } // end for codigo para terminar o programa: // libera a memoria alocada if (clientes != NULL) free(clientes); // fecha o arquivo fclose(Entrada); return 1; pronto. E pra ler um cliente? Pode ser assim int le_cliente(FILE* arquivo, Cliente* um_cliente) { // le um cliente do arquivo e guarda no endereco int n; n = fscanf(arquivo, "%d", &um_cliente->idade); n = fscanf(arquivo, "%51s", &um_cliente->nome); n = fscanf(arquivo, "%2s", &um_cliente->sexo); n = fscanf(arquivo, "%2s", &um_cliente->estado_civil); n = fscanf(arquivo, "%d", &um_cliente->qtd_amigos); n = fscanf(arquivo, "%d", &um_cliente->qtd_fotos); return 0; } Uma vantagem de ter uma função separada é que pra passar a ler da entrada padrão depois só precisa mudar aqui ou escrever outra função... E pra mostrar na tela? Pode ser assim: int mostra_cliente(Cliente* um_cliente) { // mostra dados do cliente printf(" ....*....0....*....0....*....0....*....0....*....0 regua\n"); printf("Idade:........[%d]\n", um_cliente->idade); printf("Nome:.........[%s]\n", um_cliente->nome); printf("Sexo:.........[%s]\n", um_cliente->sexo); printf("Estado Civil:.[%s]\n", um_cliente->estado_civil); printf("Amigos:.......[%d]\n", um_cliente->qtd_amigos); printf("Fotos:........[%d]\n\n", um_cliente->qtd_fotos); return 0; } Que #$%#$% é essa de régua e esse colchetes? Simples: usando os campos entre colchetes durante os testes a gente sabe se está em branco ou se não saiu nada porque tem um delimitador. E a régua ajuda a contar até 50 que é o campo mais comprido, sem ter que perder tempo. Depois que estiver ok a gente apaga ao invés de colocar depois que está dando erro.... ....*....0....*....0....*....0....*....0....*....0 regua Idade:........[56] Nome:.........[01234567890123456789012345678901234567890123456789] Sexo:.........[F] Estado Civil:.[N] Amigos:.......[45] Fotos:........[56] Assim você pode conferir o alinhamento e depois que estiver ok é só mudar essa função. Apenas essa escreve na tela... Para essa entrada em "txt.txt" 2 12 NOME M S 12 34 56 01234567890123456789012345678901234567890123456789 F N 45 56 O programa mostra Rodando: C:\Users\toninho\source\repos\ch-190823-struct\Debug\ch-190823-struct.exe Lendo arquivo txt.txt Vai ler 2 registros Vai alocar memoria para conter os 2 registros de 68 bytes. Total = 136 bytes ....*....0....*....0....*....0....*....0....*....0 regua Idade:........[12] Nome:.........[NOME] Sexo:.........[M] Estado Civil:.[S] Amigos:.......[12] Fotos:........[34] ....*....0....*....0....*....0....*....0....*....0 regua Idade:........[56] Nome:.........[01234567890123456789012345678901234567890123456789] Sexo:.........[F] Estado Civil:.[N] Amigos:.......[45] Fotos:........[56] Eis um código completo, que roda ao menos em Windows com Visual Studio. Não tenho tempo para testar em outros ambientes #define _CRT_SECURE_NO_WARNINGS #include "stdio.h" #include "stdlib.h" typedef struct { int idade; char nome[51]; char sexo[2]; // MF char estado_civil[2]; // SCND int qtd_amigos; int qtd_fotos; } Cliente; int flush_in() { char c; do { c = getchar(); if (c == '\n') return 1; if (c == EOF) return 2; }while (1); } int le_cliente(FILE* arquivo, Cliente* um_cliente) { // le um cliente do arquivo e guarda no endereco int n; n = fscanf(arquivo, "%d", &um_cliente->idade); n = fscanf(arquivo, "%51s", &um_cliente->nome); n = fscanf(arquivo, "%2s", &um_cliente->sexo); n = fscanf(arquivo, "%2s", &um_cliente->estado_civil); n = fscanf(arquivo, "%d", &um_cliente->qtd_amigos); n = fscanf(arquivo, "%d", &um_cliente->qtd_fotos); return 0; } int mostra_cliente(Cliente* um_cliente) { // mostra dados do cliente printf(" ....*....0....*....0....*....0....*....0....*....0 regua\n"); printf("Idade:........[%d]\n", um_cliente->idade); printf("Nome:.........[%s]\n", um_cliente->nome); printf("Sexo:.........[%s]\n", um_cliente->sexo); printf("Estado Civil:.[%s]\n", um_cliente->estado_civil); printf("Amigos:.......[%d]\n", um_cliente->qtd_amigos); printf("Fotos:........[%d]\n\n", um_cliente->qtd_fotos); return 0; } int main(int argc, char** argv) { FILE* Entrada; char * arquivo = "txt.txt"; int total = 0; int total_bytes; if (argc < 0) { printf("Faltou o nome do arquivo\n"); return 0; } // end if printf("Rodando: %s\n\n\n", argv[0]); printf("Lendo arquivo %s\n", argv[1]); Entrada = fopen(argv[1], "r"); int n = fscanf(Entrada, "%d", &total); printf("Vai ler %d registros\n", total); total_bytes = total * sizeof(Cliente); printf("Vai alocar memoria para conter os %d registros de %d bytes. Total = %d bytes\n", total, sizeof(Cliente), total_bytes); Cliente* clientes = malloc(total_bytes); // le os clientes for (int n = 0; n < total; n = n + 1) { le_cliente(Entrada, (clientes+n) ); } // end for // mostra os clientes for (int n = 0; n < total; n = n + 1) { mostra_cliente(clientes+n); } // end for // libera a memoria alocada if (clientes != NULL) free(clientes); // fecha o arquivo fclose(Entrada); return 1; }
-
Olá! Em geral compensa gastar um tempo vendo o formato interno do arquivo antes de escrever algo. Isso com alguma ferramenta como um editor hexadecimal. De todo modo, acha que pode assumir que: o arquivo como você disse é do tipo texto então está formatado em linhas o primeiro campo é numérico o segundo campo é o nome e não tem números de jeito nenhum o terceiro campo é outro numero as linhas tem comprimento variável Se for o caso, eis uma possível lógica: pode abrir o arquivo como texto mesmo le a linha inteira para a memoria encontra o primeiro não-numero --- deve ser o inicio do nome a partir dai encontra o primeiro numero --- deve ser o inicio do terceiro campo nesse intervalo está o nome: então isola eventuais brancos a esquerda e a direita e assim delimita cada nome por segurança converte tudo para maiúscula e troca os caracteres acentuados pelo caracter sem acento, tipo ó por o e ta coloca isso numa estrutura de dados qualquer, tipo lista ligada ou árvore ou algo assim, para ficar em ordem já enquanto insere Como tem essa estimativa de 45 mil nomes não é nada expressivo para os computadores de hoje em dia e pode ter isso em uns poucos megabytes apenas. Com a estrutura carregada com os nomes aí você faz o que precisar. Estou imaginando que quer manter tudo isso em C estritamente. É o caso? Quer ver um exemplo?
-
Logo depois disto deve estar o objetivo em si... Note a barra de rolagem do lado direito. O que vai fazer com esse "banco de dados"? vai ser mantido em disco? em memoria? que operações deve implementar? Apenas um printf() de tudo que leu? Mas já dá pra entender. Mais tarde vou ver seu código pra ver se posso ajudar em algo
-
Olá! Talvez devesse postar o enunciado...
-
a restrição (a) indica que não deve ler os valores ou mostrar qualquer resultado na função, que deve apenas calcular o resultado e devolver a restrição (b) não é bem uma restrição: é apenas o objetivo Em relação ao seu código: A relação de divisão é digital: ou A divide B ou A não divide B, para quaisquer A e B. Então poderia já imprimir "nao divisivel" numa clausula else do primeiro if. E se num2 for maior que num1 não vai imprimir nada? Está errado. Para num1 = 100 e num2 = 99 por exemplo, não vai mostrar nada Talvez devesse usar simplesmente os nomes do enunciado, A e B ao invés de inventar novos nomes. Entenda: se A < B então o resto da divisão de A por B é A, certo? afinal Se A < B então A = 0 x B + A Exemplo: A= 50, B = 100 50%100 = 50 porque 50 = 0x100 + 50 Se A<B então A%B = A E pelo enunciado não deve haver interação na função, certo? as instruções printf() devem estar em main() e apenas usar o resultado do cálculo feito na função divide(). Note que o enunciado diz que E assim usar rand()%100 não significa assim uma leitura. É mais um sorteio Como exemplo pode usar algo assim: #include "stdio.h" int divide(int A, int B) { return ((A % B) == 0); } // end divide() int main(int argc, char** argv) { int A; int B; printf("A: "); scanf("%d", &A); printf("B: "); scanf("%d", &B); if ( divide(A, B) ) printf("divisivel\n"); else printf("nao divisivel\n"); return 0; } // end main() Que mostra: A: 100 B: 50 divisivel Ou A: 50 B: 100 nao divisivel por exemplo. Note que em C o valor zero é considerado falso e qualquer outro é considerado verdadeiro. E uma expressão lógica, como uma comparação, retorna zero se falsa ou 1 se verdadeira. Exemplo: printf("%d\n", (int)(100==100)); // imprime 1 printf("%d\n", (int)(100==99)); // imprime 0 E assim você pode escrever divide() como: int divide(int A, int B) { return ((A % B) == 0); } // end divide() Bem de acordo com o conceito. Verdadeiro retorna verdadeiro... Mas você também pode escrever Como sugerido por @MB_ Apenas vai estar negando duas vezes a condição em si. (num1%num2) retorna false para quando num1 divide num2. Isso porque zero é falso, como vimos. E então o operador ! inverte a condição para true e fica tudo certo. Alguém da matemática diria Em C isso seria por exemplo ok isso foi só uma piada
-
Olá! Isso como escreveu não faz muito sentido: printf() é uma função e o resultado vai ser exibido exatamente na hora e local em que for chamada Imagino que queira usar um printf() em main() para exiir o resultado do cálculo de uma função, como no código que postou: usar printf() em main() para exibir o resultado de ClassificaALuno(). Vou te mostrar um exemplo, com uns palpites: Seu código não está completo: printf(ClassificaAluno); O formato de printf() é printf(formato, argumentos); No formato você usa algo como fez nas chamadas a scanf() printf("ClassificaAluno"); mostra simplesmente ClassificaAluno. printf(ClassificaAluno); não faz sentido. Agora alguns valores que começam por % nesse primeiro argumento, formato, estão tabelados na documentação e são substituídos pelos valores dos argumentos seguintes. Exemplo: %d indica um valor inteiro, como o número de faltas %f um valor com casa decimais, como a média %s uma string como "ClassificaAluno" int f = 4; int m = 5.56; char* s = "Umas palavras" printf("Um inteiro (%d)\n", f); printf("Um valor decimal [%f]\n", m); printf("Uma cadeia de caracteres [%s]\n", s); Esse valor "\n" faz parte de uma outra lista de caracteres especiais que printf() gera, e nesse caso muda de linha --- newline. Logo abaixo vou mostrar a saída destes comandos em um programa: int f = 4; float m = 5.56; char* s = "Umas palavras"; printf("ClassificaAluno\n"); printf("Um inteiro (%d)\n", f); printf("Um valor decimal [%f]\n", m); printf("Uma cadeia de caracteres: [%s]\n", s); E vai te ajudar a entender, espero. Se não, continue perguntando aqui. ClassificaAluno() Em relação a essa função, talvez ache melhor ela retornar apenas o texto da classificação do aluno a partir da média e do número de faltas, certo? Assim você pode usar direto num printf() em main() como imagino ser o que quer. Como? Ao invés da função retornar char, uma única letra, retorne char* e pode retornar a string todinha já pronta. Como estourar o limite de faltas reprova de qualquer maneira, considere que é mais simples testar isso primeiro, ao invés de se preocupar com a média ao mesmo tempo. É a realidade: estourou em faltas, adeus Pode declarar as strings direto na função todas juntas, assim fica mais fácil de conferir ou alterar algo Eis um exemplo: char* ClassificaAluno(float media, int faltas) { char* aprovado_louvor = "APROVADO COM LOUVOR"; char* aprovado = "APROVADO"; char* reprovado = "REPROVADO"; char* reprovado_faltas = "REPROVADO POR FALTAS"; if (faltas>10) return reprovado_faltas; if (media<7) return reprovado; if (media<9.5) return aprovado; return aprovado_louvor; } // end ClassificaAluno() Talvez concorde que é muito mais simples e legível. Não precisa de else ou testar media e faltas ao mesmo tempo: apenas retorne quando achar a resposta. Um return é exatamente isso. E provavelmente assim fica mais fácil de ler, muito mais fácil porque descreve simplesmente a realidade: mais de 10 faltas? reprovado por faltas.Se não foi reprovado por faltas mas não conseguiu nota 7, reprovado. Se não conseguiu ao menos 9.5, aprovado. Mas se conseguiu, parabens: aprovado com louvor. Só isso. O printf() do resultado da função: printf ( "Media %f com %d faltas: resultado '%s'\n", media, faltas, ClassificaAluno(media, faltas) ); Simples. E mostra para media 8.5 e 5 faltas Media 8.500000 com 5 faltas: resultado 'APROVADO' As aspas em torno do resultado são o resultado de '%s' no printf() e servem só para destacar o resultado e tambem para testar... se imprimisse apenas o valor e estivesse em branco não saberia o que aconteceu, mas usando as aspas veria as duas em seguida e saberia que a string estava em branco... #include <stdio.h> char* ClassificaAluno(float media, int faltas) { char* aprovado_louvor = "APROVADO COM LOUVOR"; char* aprovado = "APROVADO"; char* reprovado = "REPROVADO"; char* reprovado_faltas = "REPROVADO POR FALTAS"; if (faltas>10) return reprovado_faltas; if (media<7) return reprovado; if (media<9.5) return aprovado; return aprovado_louvor; } // end ClassificaAluno() int main() { float media; int faltas; int f = 4; float m = 5.56; char* s = "Umas palavras"; printf("ClassificaAluno\n"); printf("Um inteiro (%d)\n", f); printf("Um valor decimal [%f]\n", m); printf("Uma cadeia de caracteres: [%s]\n", s); printf("Media: "); scanf("%f", &media); printf("Faltas: "); scanf("%d", &faltas); printf ( "Media %f com %d faltas: resultado '%s'\n", media, faltas, ClassificaAluno(media, faltas) ); return 0; } E mostra isso na tela ClassificaAluno Um inteiro (4) Um valor decimal [5.560000] Uma cadeia de caracteres: [Umas palavras] Media: 9.2 Faltas: 9 Media 9.200000 com 9 faltas: resultado 'APROVADO' As primeiras 4 linhas são,. claro, testes para ajudar a entender o printf() Um printf() antes de cada scanf() está lá para que o usuário tenha uma orientação do que está acontecendo IMPORTANTE: escreva ClassificaAluno() antes de usar. O compilador precisa saber o que cada função retorna e a lista de argumentos ao compilar o programa e encontrar uma chamada a ela...
-
C Como passar um valor para um vetor de estrutura
arfneto respondeu ao tópico de Igor Vargas em C/C#/C++
Olá Talvez sua dúvida seja como acessar as variáveis dentro das estruturas. Veja esse código, que usa seu exemplo, e talvez ajude a entender. Pessoa está declarada assim: struct Pessoa { int idade[2]; }; struct Pessoa pessoas[2]; E você pode preencher assim: // sao duas Pessoa, em cada pessoa duas idades pessoas[0].idade[0] = 0; pessoas[0].idade[1] = 1; pessoas[1].idade[0] = 2; pessoas[1].idade[1] = 3; Claro, para a estrutura Carro é igualzinho e não vou repetir para que você não se canse Note que para entender ajuda se você usar valores distintos e conhecidos para cada idade em cada pessoa, como fiz aqui usando 0,1,2 e 3. Imagino que por isso você tenha declarado int idade[2]; E os ponteiros são declarados assim: struct Pessoa* p; Então se escrever p = pessoas; p vai apontar para a primeira das pessoas[], pessoas[0], e ao escrever p = p + 1; p passa a apontar para a segunda. E por isso a aritmética de ponteiros é tão útil em C. E se você escrever p = p + 1 de novo tudo bem. Mas como não tem pessoas[2] se você tentar acessar *p de novo seu programa irá para o espaço, e por isso essas coisas dão tanto erro Esse programa #include "stdio.h" struct Pessoa { int idade[2]; }; struct Pessoa pessoas[2]; struct Pessoa* p; struct Carro { int carro[2]; }; struct Carro carros[2]; struct Carro* c; int main( int argc, char** argv ) { // sao duas Pessoa, em cada pessoa duas idades pessoas[0].idade[0] = 0; pessoas[0].idade[1] = 1; pessoas[1].idade[0] = 2; pessoas[1].idade[1] = 3; // sao dois Carro , em cada carro dois carro :) carros[0].carro[0] = 0; carros[0].carro[1] = 1; carros[1].carro[0] = 2; carros[1].carro[1] = 3; // p vai apontar para a primeira Pessoa, pessoas[0] printf("p vai apontar para a primeira pessoa...\n"); p = pessoas; printf("idades em *p: %d e %d\n", p->idade[0], p->idade[1]); // p vai apontar para a segunda Pessoa, pessoas[1] p = p + 1; printf("somando um em p vai passar para a proxima pessoa...\n"); printf("idades em *p: %d e %d\n", p->idade[0], p->idade[1]); // listando os valores em carros printf( "valores de carro[] em carros[]: %d \t %d \t %d \t %d\n", carros[0].carro[0], carros[0].carro[1], carros[1].carro[0], carros[1].carro[1] ); return 0; } mostra isso: p vai apontar para a primeira pessoa... idades em *p: 0 e 1 somando um em p vai passar para a proxima pessoa... idades em *p: 2 e 3 valores de carro[] em carros[]: 0 1 2 3 C:\Users\toninho\source\repos\ch-struct\Debug\ch-struct.exe (process 11452) exited with code 0. Mais uma nota: Em geral e em especial para quem está aprendendo recomendo declarar as coisas como elas são de fato e em separado, para ajudar a fixar claramente o que está acontecendo. Exemplo: struct pessoa pessoas[2], *p; Declarar *p como uma struct pesssoa está correto. Mas estamos declarando p e ao declarar struct Pessoa* p; p de fato é struct* pessoa e então fica claro para o aluno e o leitor que a variável declarada, p, é um ponteiro para uma struct do tipo pessoa. Ao escrever struct pessoa *p isso se perde um pouco: estamos declarando *p ou p? Só um palpite, nem quero iniciar um debate mas estamos declarando p... adicionado 55 minutos depois Esqueci de comentar esse código... Está ok, apenas p não aponta para lugar algum. acrescente antes uma dessas p= pessoas; // aponta para a primeira pessoa p= &pessoas[0]; // aponta para a primeira p= &pessoas[1]; // aponta para a segunda pessoa -
Olá! Considere que usar system() para criar uma pasta não é exatamente Apenas contrata um intermediário para fazer o trabalho. Outro exemplo: programa em C para remover o arquivo x? system("rm -y x"); Sim, mas não se espera uma chamada a system() para o sistema executar a função e sim um programa em C com uma função que faça isso, Imagine um programa chamado ch-folder que você chame assim: ch-folder N Pasta E ele crie no diretório corrente N pastas chamadas Pasta00, Pasta01 até Pasta(N-1). Ex: ch-folder 5 Pasta cria : Pasta00 Pasta01 Pasta02 Pasta03 Pasta04 E se mostrasse antes qual a pasta onde vão ser criadas as N pastas a saída poderia ser assim para ch-folder 10 pasta ch-folder: Vai criar 10 pastas em C:\Users\toninho\source\repos\c-folder\c-folder ==> C:\Users\toninho\source\repos\c-folder\c-folder/pasta00 ==> C:\Users\toninho\source\repos\c-folder\c-folder/pasta01 ==> C:\Users\toninho\source\repos\c-folder\c-folder/pasta02 ==> C:\Users\toninho\source\repos\c-folder\c-folder/pasta03 ==> C:\Users\toninho\source\repos\c-folder\c-folder/pasta04 ==> C:\Users\toninho\source\repos\c-folder\c-folder/pasta05 ==> C:\Users\toninho\source\repos\c-folder\c-folder/pasta06 ==> C:\Users\toninho\source\repos\c-folder\c-folder/pasta07 ==> C:\Users\toninho\source\repos\c-folder\c-folder/pasta08 ==> C:\Users\toninho\source\repos\c-folder\c-folder/pasta09 C:\Users\toninho\source\repos\c-folder\Debug\c-folder.exe (process 7748) exited with code 0 . Rodando em Windows teriamos as pastas: Em C podemos usar _getcwd() para identificar o diretorio corrente, para poder mostrar em que pasta serão criadas as pastas... Algo assim: _getcwd(raiz, tamanho); // em raiz vem o nome da pasta corrente, pwd Depois precisamos de um loop para criar as pastas. um for nesse exemplo. A cada vez montamos o nome da pasta acrescentando o número ao nome dado como parâmetro e pronto. Nesse programa de exemplo vamos usar o diretório corrente e acrescentar uma barra e o prefixo dado como parâmetro, "pasta" nesse exemplo, e acrescentar o número. Bem básico. Note que podemos usar '/' como delimitador mesmo no Windows, no caso do meu exemplo. O sistema se encarrega de trocar por '\' no Windows e os programas rodam bem nos dois casos: Unix/Linux/IOS e Windows. Para montar o nome usamos as variáveis raiz para o diretório corrente, delimitador para o próprio, prefixo para o ... prefixo, e acrescentamos o número i. Usando as rotinas de manipulação de strings em C, strcpy() para copiar uma string, strcat() para concatenar duas strings, sprintf() para formatar uma string acrescentando um número int convertido para char. Eis o loop em questão: strcpy(prefixo, raiz); // diretorio corrente strcat(prefixo, delimitador); // delimitador strcat(prefixo, argv[2]); // prefixo: o segundo argumento: "pasta" // falta so o numero para montar o nome da pasta for (int i=0;i<n;i++) { // acrescenta o numero da pasta no final do nome strcpy(nova_pasta, prefixo); sprintf(nova_pasta, "%s%02d", prefixo, i); printf("==> %s\n", nova_pasta); if (_mkdir(nova_pasta) != 0) { perror(prefixo); return EXIT_FAILURE; } // end if; } // end for _mkdir() cria a pasta. Eis o programa completo que gera essa saída: #include <direct.h> #include <stdio.h> #include <stdlib.h> #include <string.h> #include <sys/stat.h> #include <sys/types.h> #include <windows.h> void mostra(char * raiz) { printf("\n Ex: \"%s 10 pasta\" cria as pastas Pasta00 ate Pasta09 no diretorio corrente\n", raiz); return; } int main( int argc, char** argv ) { char raiz[256]; size_t tamanho = 256; char n; char prefixo[250]; char nova_pasta[250]; char delimitador[2] = "/"; // windows ou linux tanto faz // // para evitar problemas: exige que use na linha de comando // o numero de pastas e o prefixo // if (argc < 3) { printf("Use: %s N P para criar N pastas com o prefixo P\n", argv[0]); mostra(argv[0]); return EXIT_FAILURE; } // queremos mostrar mensagem dizendo quantas pastas vão ser criadas em qual pasta _getcwd(raiz, tamanho); // em raiz vem o nome da pasta corrente, pwd printf("ch-folder: Vai criar %s pastas em %s\n", argv[1], raiz); n = atoi(argv[1]); // converte o primeiro parametro para integer, o numero de pastas if (n > 99) return EXIT_FAILURE; // limita o total de pastas a 99 // monta o nome da pasta: strcpy(prefixo, raiz); // diretorio corrente strcat(prefixo, delimitador); // delimitador strcat(prefixo, argv[2]); // prefixo // falta so o numero para montar o nome da pasta for (int i=0;i<n;i++) { // acrescenta o numero da pasta no final do nome strcpy(nova_pasta, prefixo); sprintf(nova_pasta, "%s%02d", prefixo, i); printf("==> %s\n", nova_pasta); if (_mkdir(nova_pasta) != 0) { perror(prefixo); return EXIT_FAILURE; } // end if; } // end for return EXIT_SUCCESS; } // end main() Isso roda sem problemas no Windows 10 usando Visual Studio Community 2019 16.2, a versão grátis. Tenho umas máquinas com CentOS, Ubuntu e Fedora aqui, mas não dá pra testar nelas agora. Mas não acho que precise mudar nada para rodar em sistemas não-Windows. Claro que isso é só um programa de exemplo e não testa quase nada.
-
C++ problema folha de são paulo c++
arfneto respondeu ao tópico de João Victor Souza Carli em C/C#/C++
Sim. Basta programar isso, o inverso do enunciado de certa forma: 72 por exemplo é 2 x 2 x 2 x 3 x 3, 8x9. Então você vai usando os fatores primos do numero e procurando na tabela de palavras. Quando achar uma palavra que dá esse total você mostra e encerra. Note que pode haver, lógico, mais de uma solução dependendo dos valores dos pesos para cada letra. No enunciado por exemplo E= 2 e U= 8... SIRIUS vale 72 mas ESIRIESE também já que 8 = 2x2x2, ou um U vale 3 E no nosso caso. Se quiser mesmo fazer isso abra um novo tópico e escrevemos juntos a função. Note que se isso é para ser resolvido em C++ E se espera algo de C++ e em geral um código simples em C ajustado para compilar em C++ pode estar potencialmente correto mas não ensinar nada em termos de C++ e valer menos pontos... Tenho visto muitos exemplos assim aqui no Forum. De volta ao tema: Muitas vezes esses problemas para iniciantes mostram informações que nada tem a ver com a solução, apenas para distrair o aluno e ver se ele consegue focar no que tem realmente a ver com o problema e descartar as informações supérfluas. Nesse caso aqui temos sistemas estelares, engenheiros, sequencia de Fibonacci e tal E temos um problema a ser resolvido em C++. Vou deixar uma possível maneira de implementar isso Em geral vale muito a pena pensar no que estamos tentando resolver antes de ir escrever um programa e esse aqui é um caso: A sequencia de Fibonacci não tem nada a ver com o problema Temos apenas algumas palavras e um critério para gerar um número, que vamos chamar de produto, a partir das letras dessa palavra: de acordo com o enunciado apenas as vogais tem um valor, que vamos chamar de peso. Na primeira palavra que tiver o produto esperado terminamos com um destino identificado. Se nenhuma das palavras tiver esse produto, ficamos sem destino. Nesse caso, uma espaçonave com engenheiros Perdidos No Espaço O enunciado tem uma sequência de palavras para testar, uma tabela de pesos e um produto esperado, 75. Voltando ao Ensino Fundamental: fatores primos Pois é: temos 75 engenheiros e um conjunto de fatores --- pesos --- para gerar um produto. Lembrando da infância na escola, temos que 75 é divisível por 3: 75=3x25. E temos que 25 é divisível por 5: 25=5x5. Então escrevendo 75 como produto de fatores primos, 75 = 3x5x5. E olhando o enunciado temos que I vale 3 e O vale 5 e já sabemos que a palavra que a gente quer só pode ter 2 vogais: O e I. E tem que ter dois O. Sem programar nada. Só olhando. E vemos lá PROCION no enunciado, com o esperado valor 75. Mais do ensino fundamental: Aritmética Temos que na multiplicação multiplicar qualquer coisa por 1 dá na mesma: então se todas as nossas letras da tabela tivessem peso 1 o produto seria sempre... 1. O nome chique de escrever isso é que 1 é o elemento neutro da multiplicação. 1*X = X para qualquer X Porque #$%#%$# de motivo isso importa? Simples: temos sempre uma tabela de pesos e um produto. Nesse nosso caso AEIOU = 1,2,3,5 e 8 na ordem. Por exemplo, o produto para "AEIOU" seria 240 = 1x2x3x5x8 e como a gente já viu para "PROCION" por exemplo seria 5x3x5 = 75, e a gente espera que nosso programa mostre isso. E usando o peso 1 para qualquer valor fora da tabela fiuca mais fácil de calcular o produto, como vamos ver Escrevendo em C++ Em C++ tem lá os objetos e tal. Podemos pensar então em uma classe Tabela --- o objeto --- e ela precisa ter: - uma tabela de pesos para as letras. As letras que não estão na tabela tem peso padrão 1 e assim não mudam o produto, como vimos acima. - um total de itens na tabela para poder controlar a pesquisa Algo assim: class Tabela { private: int total_de_items; int* pesos; char* letras; ... } É tudo que precisamos: o total de itens, os pesos e as letras; E o que eu posso querer saber? Para uma certa palavra, qual o produto? Algo assim: int produto(string elemento) { cout << "calculando valor para a palavra " << elemento << endl; int produto = 1; // para cada letra da palavra ultiplica a letra pelo peso dela // se esta na tabela, ou por 1 for (int i = 0; i < elemento.length(); i++) { produto = produto * fator_letra(elemento[i]); } // end for cout << "produto = " << produto << endl; return produto; } // end produto() E eu chamo assim: produto("palavra"); e a função retorna o produto para essa palavra considerando a tabela da classe. Para a tabela do enunciado, produto("palavra") retorna 1, pois 1x1x1=1. A vantagem de usar objetos (classes) é que eu posso mudar a tabela ou as palavras e continua tudo funcionando: o método da classe usa as letras e os pesos da classe e sempre funciona. E essa função fator_letra() faz o que? simplesmente retorna o peso para a letra: no caso da tabela do enunciado, retorna por exemplo 8 para fator_letra('U') e retorna 1 para fator_letra('X'). E o código? pode ser assim: int fator_letra(char a_letra) { for (int i = 0; i < total_de_items; i++) { if (letras[i] == a_letra) return pesos[i]; } return 1; } // end fator_letra() Isso é só pra ficar mais fácil de ler o código do método produto() Algo mais? Bem, seria legar ter uma função para mostrar o que tem na tabela, assim não precisamos ficar imaginando se o construtor está certo ou não... void mostra() { cout << "Tabela com " << total_de_items << " items" << endl; cout << "Eis os pesos para as " << total_de_items << " letras" << endl; for (int i = 0; i < total_de_items; i++) { cout << letras[i] << "=" << pesos[i] << endl; } // end for } // end mostra() E como eu construo uma coisa dessas em C++? Usando um construtor para a classe Tabela, que pega exatamente esses valores que declramos, algo assim: Tabela(int n, int* peso, string as_letras) { cout << "Criando uma tabela de pesos com " << n << " letras (para '" << as_letras << "')" << endl; total_de_items = n; pesos = new int[n]; letras = new char[n]; for (int i = 0; i < n; i++) { letras[i] = as_letras[i]; pesos[i] = peso[i]; } // end for } Um exemplo? claro: uma tabela com 4 pesos para X=3, Y=5, Z=7 e T=11 poderia ser usada assim em main: int pesos_1 = { 3, 5, 7, 11 }; Tabela exemplo_1(4,pesos_1,"XYZT"); exemplo_1.mostra(); exemplo_1.produto("PARA UM VALOR QUALQUER"); E iria mostrar isso na tela: Criando uma tabela de pesos com 4 letras (para 'XYZT') Tabela com 4 items Eis os pesos para as 4 letras X=3 Y=5 Z=7 T=11 calculando valor para a palavra PARA UM VALOR QUALQUER produto = 1 E para a tabela do enunciado? Assim: int pesos_folha[] = { 1,2,3,5,8 }; Tabela teste_folha(5, pesos_folha, "AEIOU"); teste_folha.mostra(); teste_folha.produto("PARA UM VALOR QUALQUER"); teste_folha.produto("Clube do Hardware"); teste_folha.produto("SIRIUS"); teste_folha.produto("PROCION"); E iria mostrar isso na tela: Criando uma tabela de pesos com 5 letras (para 'AEIOU') Tabela com 5 items Eis os pesos para as 5 letras A=1 E=2 I=3 O=5 U=8 calculando valor para a palavra PARA UM VALOR QUALQUER produto = 5120 calculando valor para a palavra Clube do Hardware produto = 160 calculando valor para a palavra SIRIUS produto = 72 calculando valor para a palavra PROCION produto = 75 Para o enunciado, Um método em C++ escrito assim: bool desafio_folha(int n_engenheiros) { int pesos_folha[] = { 1,2,3,5,8 }; // os pesos do enunciado string sistemas_estelares[] = // os sistemas estelares { "SIRIUS", "LALANDE", "PROCION", "CENTAURI", "BARNARD" }; Tabela folha = Tabela(5, pesos_folha, "AEIOU"); // cria tabela com as letras e pesos cout << "--------------------" << endl; cout << "desafio_folha(): procurando destino para espaconave com " << n_engenheiros << " engenheiros" << endl; int sistema = 0; do { if (folha.produto(sistemas_estelares[sistema]) == n_engenheiros) { cout << "Local de Chegada identificado:" << sistemas_estelares[sistema] << endl; return true; } sistema = sistema + 1; } while (sistema < 5); return false; } // end desafio_folha() podia ser usado em main() assim: if (desafio_folha(75) == true) { cout << "Destino localizado" << endl;; } else { cout << "Sem destino: Engenheiros perdidos" << endl;; } e mostraria -------------------- desafio_folha(): procurando destino para espaconave com 75 engenheiros calculando valor para a palavra SIRIUS produto = 72 calculando valor para a palavra LALANDE produto = 2 calculando valor para a palavra PROCION produto = 75 Local de Chegada identificado:PROCION Destino localizado O código em main() para testar esses exemplos todos: int main() { int pesos_1[] = { 3,5,7,11 }; Tabela exemplo_1(4, pesos_1, "XYZT"); exemplo_1.mostra(); exemplo_1.produto("PARA UM VALOR QUALQUER"); int pesos_folha[] = { 1,2,3,5,8 }; Tabela teste_folha(5, pesos_folha, "AEIOU"); teste_folha.mostra(); teste_folha.produto("PARA UM VALOR QUALQUER"); teste_folha.produto("Clube do Hardware"); teste_folha.produto("SIRIUS"); teste_folha.produto("ESIRIESE"); teste_folha.produto("PROCION"); if (desafio_folha(75) == true) { cout << "Destino localizado" << endl;; } else { cout << "Sem destino: Engenheiros perdidos" << endl;; } return 0; };// end main() E mostra na tela: Criando uma tabela de pesos com 4 letras (para 'XYZT') Tabela com 4 items Eis os pesos para as 4 letras X=3 Y=5 Z=7 T=11 calculando valor para a palavra PARA UM VALOR QUALQUER produto = 1 Criando uma tabela de pesos com 5 letras (para 'AEIOU') Tabela com 5 items Eis os pesos para as 5 letras A=1 E=2 I=3 O=5 U=8 calculando valor para a palavra PARA UM VALOR QUALQUER produto = 5120 calculando valor para a palavra Clube do Hardware produto = 160 calculando valor para a palavra SIRIUS produto = 72 calculando valor para a palavra ESIRIESE produto = 72 calculando valor para a palavra PROCION produto = 75 Criando uma tabela de pesos com 5 letras (para 'AEIOU') -------------------- desafio_folha(): procurando destino para espaconave com 75 engenheiros calculando valor para a palavra SIRIUS produto = 72 calculando valor para a palavra LALANDE produto = 2 calculando valor para a palavra PROCION produto = 75 Local de Chegada identificado:PROCION Destino localizado Espero que tenha ajudado a entender uma importante diferença de usar objetos assim: só por declarar a variável t como sendo do tipo Tabela eu já posso construir a tabela e chamar os métodos mostra() e produto() já acertados para cada variável tabela. Isso se chama instância: t é uma instância de Tabela. int pesos_t[] = { 3,5,7,11,13,26,30,1 }; Tabela t(8, pesos_t, "ABCDEFGH"); E eu posso escrever t.mostra() e t.produto("TESTE") e vai funcionar certinho. E misturar várias tabelas no mesmo programa sem ter que mudar uma linha de código. Se quiser ver um programa completo me avise e eu posto aqui a seguir. Está muito comprido esse texto já -
Obrigado! Imaginei que fosse algo assim. E muitos cliques depois desse do login temos a informação adicional de que URI é Universidade Regional Integrada do Alto Uruguai e das Missões, afinal em https://www.reitoria.uri.br/pt
-
Olá! Seu programa sugere que o inteiro N é o total de valores digitados X. Talvez fosse melhor ver também o enunciado. Imaginando que seja isso, e que só precise dizer quantos números dos N digitados estão dentro do intervalo, podia imaginar uma saída assim Entre com o total N de valores: 5 Agora entre com os 5 valores, um por linha [1 de 5]: 9 [2 de 5]: 10 [3 de 5]: 11 [4 de 5]: 20 [5 de 5]: 21 Dos 5 valores 3 estão dentro do intervalo desejado 10<=N<=20 Assim teria alguma orientação para o usuário ir entrando com os valores e do que se trata a resposta. Se é só isto que o enunciado requer não há razão para armazenar os valores todos, por exemplo. Tampouco tem razão para imprimir os valores que estão fora do intervalo, e algo assim serviria: #include <stdio.h> #include <stdlib.h> int main(int argc, char** argv) { int N; int noIntervalo = 0; int umValor; printf("Entre com o total N de valores: "); scanf("%d", &N); printf("Agora entre com os %d valores, um por linha\n\n", N); for (int i = 1; i <= N; i++) { printf("[%d de %d]: ", i, N); scanf("%d", &umValor); if (umValor < 10) continue; // le o proximo if (umValor > 20) continue; // le o proximo noIntervalo = noIntervalo + 1; } // end for printf("\nDos %d valores %d estão dentro do intervalo desejado 10<=N<=20\n", N, noIntervalo); return 0; } // end main() Esse gera exatamente a saída acima. Claro que há incontáveis maneiras de escrever isso... O que é URI? Se é uma plataforma automatizada de testes para os exercícios deve imprimir somente o total de valores no intervalo e nada mais
-
N sei como desbloquear a velocidade placa de rede.
arfneto respondeu ao tópico de xGrimReaper17x em Redes e Internet
Para velocidades de até 1000mbps não deve ter bons resultados com cabo CAT5, mas se as distâncias forem curtas e estiverem todos os cabos longe de equipamentos geradores de interferência pode funcionar. Os cabos CAT5e são os indicados para o uso geral e vão bem até gigabit. Em locais de muita interferência, como onde tem cabos longos passando pelo forro perto de transformadores por exemplo, talvez deva usar CAT6. Pegue um cabo emprestado que saiba que funciona e use para testar em seu roteador e computador. Leve seu cabo até um vizinho por exemplo e teste lá. Assim vai identificar os problemas. E quando puder troque os cabos por 5e e o roteador por um modelo gigabit




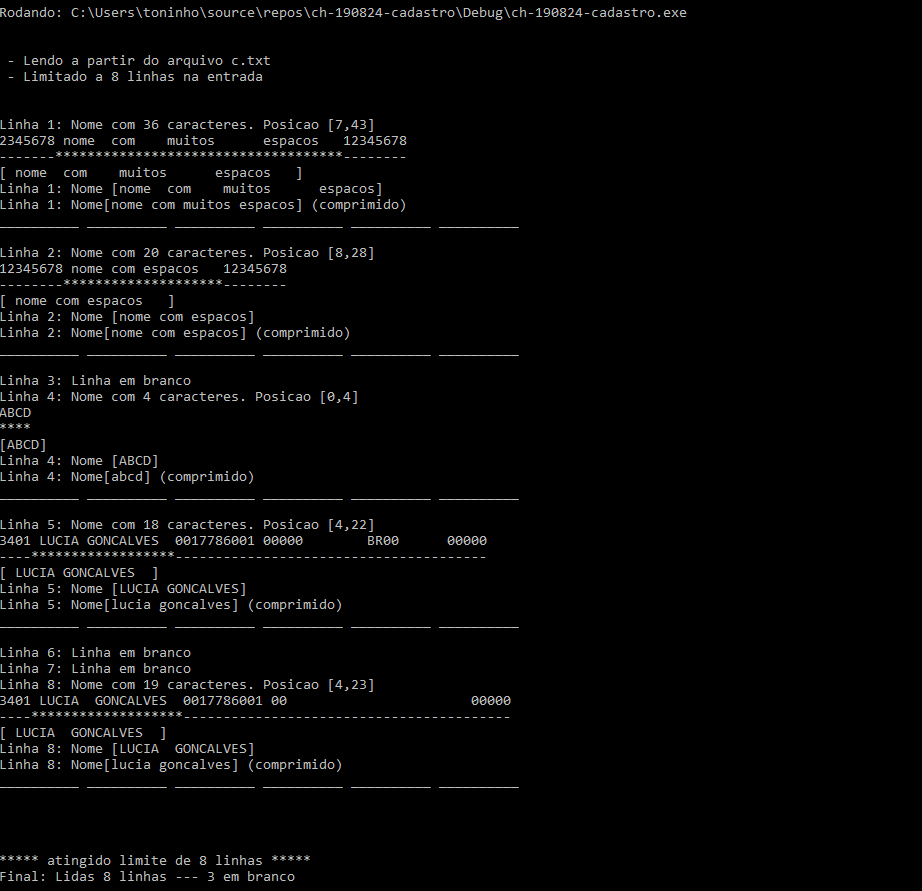
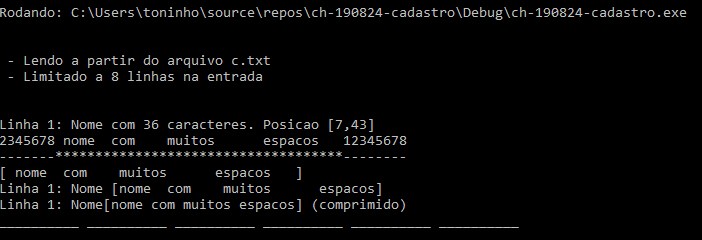



Sobre o Clube do Hardware
No ar desde 1996, o Clube do Hardware é uma das maiores, mais antigas e mais respeitadas comunidades sobre tecnologia do Brasil. Leia mais
Direitos autorais
Não permitimos a cópia ou reprodução do conteúdo do nosso site, fórum, newsletters e redes sociais, mesmo citando-se a fonte. Leia mais
