

arfneto
-
Posts
6.526 -
Cadastrado em
-
Última visita
Tipo de conteúdo
Artigos
Selos
Livros
Cursos
Análises
Fórum
Tudo que arfneto postou
-

C contar caracteres distintos em uma string em C
arfneto respondeu ao tópico de matheuscrluiz em C/C#/C++
Há uma controvérsia nessa conta, já que as letras "originais" são C A L e U, 4... Há claro um milhão de maneiras de fazer isso, e confesso que não entendi direito a maneira que você está tentando usar. Mas vou explicar uma outra: Como você já leu a string e ela não serve mais de nada, já que seu único interesse é contar as letras únicas você já sabe quantas são porque pode usar strlen() como de fato usou... Então você pode ir varrendo seu vetor até a última posição, determinada por strlen(texto) e a cada passo se a letra não for zero considera a letra que está vendo, digamos o primeiro C de CALCULO essa é uma letra única porque acabou de ver e se já tivesse passado por ela estaria com zero E então soma ao contador e usa um outro loop para ir desta posição inclusive até o fim do texto inclusive trocando todo C por zero imprime o total pronto Você declarou uma variável total apenas pra usar na última linha num printf() então podia usar a própria subtração no printf() -
C++ c++ Como fazer com que clique em jogar novamente e o jogo começe do zero?
arfneto respondeu ao tópico de Fran Botene em C/C#/C++
Muito bom! SDL é a biblioteca que foi usada para construir essa que está usando, libUnicornio. Eu não conhecia essa mas já usei a primeira. Pode ver mais no site da SDL Encontri o site de referência da libUnicornio e lá tem um documento de introdução... Talvez você devesse fdar uma olhada se ainda não fez isso. Está em https://github.com/GuilhermeAlanJohann/libUnicornio/blob/master/libUnicornio/docs/Como começar.txt Direto do autor -
C++ Como acessar resultado da variavel de uma classe
arfneto respondeu ao tópico de Reberth Siqueira em C/C#/C++
Olá! Suspeito que não queira salvar apenas esse modesto boolean ok... Uma variável dessas existe apenas dentro do bloco mais interno {}. Imagino que queira a conexão com o banco disponível em várias partes do programa e não uma variável indicando que esteve disponível em algum canto, então talvez uma classe estática com os parâmetros de conexão seja a solução, a menos que pretenda ter várias instâncias de conexão disponíveis durante o programa -
Olá! Se usa Windows o caminho oficial para endereçar o cursor na console é como está nesse trecho de programa: HANDLE H = GetStdHandle(STD_OUTPUT_HANDLE); COORD coord; coord.X = X; coord.Y = Y; SetConsoleCursorPosition(H, coord); E a função é essa aí. Se quer pode declarar uma com esse nome tradicional gotoxy() e incluir dentro esses comandos. Note que uma vez que tenha o Handle H para a saída padrão não precisa ficar chamando GetStdHandle() de novo toda hora. Mais uma coisa: isso endereça o cursor em termos de linha e coluna e não em pixels como seria esperado para um programa de colisão de partículas. Em relação à colisão, apenas considere o ângulo em que as duas partículas se movimentam e aplique uma rotação no caso da colisão. E resolva o que vai fazer quando elas colidem com a borda da tela. Pode mudar um pouco a velocidade delas ou a cor pra dar um efeito. Experimente usar coordenadas polares ao invés de (x,y) e vai ser que facilita bem a sua vida
-
C++ c++ Como fazer com que clique em jogar novamente e o jogo começe do zero?
arfneto respondeu ao tópico de Fran Botene em C/C#/C++
Entendo. Mas ao iniciar as classes algo vai, provavelmente no método inicializar, criar os objetos todos, como os Personagens. Se você não escreveu nada disso então não deve mesmo salvar nada. Essa biblioteca que está usando é baseada em SDL não é? -
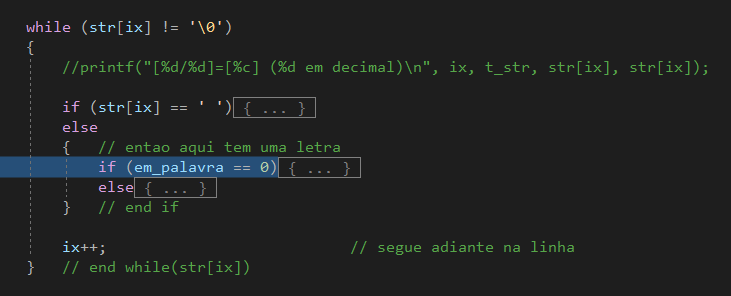
Entendo. Mas o objetivo de inserir aquelas linhas lá e deixar de ler --- porque demora e é chato de reproduzir --- é justamente facilitar os testes e salvar algumas condições significativas, como essas char* linha1 = " teste aaaaa AEITEstetee"; char* linha2 = " testeee"; char* linha3 = "teste testea testea"; char* linha4 = " "; char* linha5 = ""; char* linha6 = "aaaaa aaa"; char* linha7 = " aaaaa aaa "; Claro que cada um tem seu estilo de fazer as coisas, mas parece estranho você testar outras coisas antes de seu programa funcionar com sua única linha de teste, e mais ainda você não criar simplesmente outras para testar. Entendeu o que eu expliquei sobre a possível palavra interrompida pelo final da linha? Deve estar também faltando isso no seu caso... Vou te dar um exemplo. O programa que eu te mostrei antes e que imprimia isso Linha de teste - tamanho = 9: [ testeee] 0....*....0....*....0....*....0....*....0....*....0....*....0] 1 2 3 4 5 6] [0/9]=[ ] (32 em decimal) [1/9]=[ ] (32 em decimal) [2/9]=[t] (116 em decimal) [3/9]=[e] (101 em decimal) [4/9]=[s] (115 em decimal) [5/9]=[t] (116 em decimal) [6/9]=[e] (101 em decimal) [7/9]=[e] (101 em decimal) [8/9]=[e] (101 em decimal) Varre todas as linhas de teste e conta certo os tamanhos e passa pelas letras todas. Esse loop, que seria o seu loop em str: while (str[ix] != '\0') { printf("[%d/%d]=[%c] (%d em decimal)\n", ix, t_str, str[ix], str[ix]); ix++; } // end while return 0; Usando a mecânica que você criou, e as variáveis e tal. A partir daí você pode considerar o que eu disse antes: vem um caracter em str, que pode ou não ser um espaço. Se vem um espaço você tem duas situações: está procurando uma palavra ou está no meio de uma palavra. Se vem uma letra você tem duas situações: ou está procurando uma palavra ou está no meio de uma. Só isso. E a qualquer momento pode acabar a linha e aí você tem duas situações: se estava procurando uma palavra: aí já era, porque não tem nada mais pra fazer e pode encerrar. se não estava procurando tem uma palavra sendo montada lá em str2 e você tem que processá-la. É o que provavelmente está faltando em sua solução Voltando ao exemplo: Se você tinha um loop que varria a string e imprimia aquela tabela que está aí acima, e sabe que o processamento de uma letra ou espaço é definitivo, que não há razão pra voltar atrás. Então não toque naquele índice do loop externo em outros loops porque só vai criar problema pra você controlar. O loop original só imprimia o caracter, um por linha, como está aí, e incrementava o contador. Agora não queremos mais imprimir então comentamos a chamada a printf() porque ainda pode ser útil. E testamos as 4 possíveis situações e pronto. Quais 4? As que listei acima. Então seria algo assim Para 4 condições precisamos de dois if. Fica mais fácil se usarmos um indicador de estar ou não em uma palavra e vamos supor int em_palavra = 0; // quando 1 indica que esta em uma palavra E temos as 4. E por nada nesse mundo mexemos no índice externo, aquela variável ix no exemplo, i no seu programa Veja as condições, com o seu programa Para um branco // estaria em uma palavra ja? if (em_palavra == 0) { // um espaco: nao faz nada } else { // estava lendo uma palavra: acabou em_palavra = 0; // agora acabou a palavra str2[i_str2] = 0; // termina a string if (nVogais > 2) // essa sim { printf("%s\n", str2); } // end if } // end if Para uma letra if (em_palavra == 0) { // primeira letra de uma palavra nova nVogais = 0; // zera o contador str2[0] = str[ix]; // salva a primeira letra i_str2 = 1; // inicio da palavra em_palavra = 1; // agora em uma palavra if (e_vogal(str[ix])) nVogais = 1; // comecou com vogal ja else nVogais = 0; // ok continua lendo } else { // continua na palavra str2[i_str2] = str[ix]; // salva a primeira letra i_str2 = i_str2 + 1; if (e_vogal(str[ix])) nVogais = nVogais + 1; // comecou com vogal ja } // end if E no final? Quase igual... Como vimos são só duas condições e em uma não é preciso fazer nada --- e por isso seu programa funciona quando não a linha tem brancos no final // aqui acabou a linha mas pode // ter uma palavra sem terminar if (em_palavra == 1) { str2[i_str2] = 0; // termina a string if (nVogais > 2) // essa sim { printf("%s\n", str2); } // end if } Funciona? Claro. Mas como eu te disse é mais complicado assim: não precisa fazer isso tudo adicionado 22 minutos depois É claro que antes de tudo a gente quer testar aquelas com aquelas sete linhas e não ficar digitando e compilando toda hora então.. Eis um arquivo de teste com as sete linhas e esse seu programa usando os dois if e tal Linha de teste - tamanho = 29: [ teste aaaaa AEITEstetee] 0....*....0....*....0....*....0....*....0....*....0....*....0] 1 2 3 4 5 6] aaaaa AEITEstetee Linha de teste - tamanho = 9: [ testeee] 0....*....0....*....0....*....0....*....0....*....0....*....0] 1 2 3 4 5 6] testeee Linha de teste - tamanho = 19: [teste testea testea] 0....*....0....*....0....*....0....*....0....*....0....*....0] 1 2 3 4 5 6] testea testea Linha de teste - tamanho = 15: [ ] 0....*....0....*....0....*....0....*....0....*....0....*....0] 1 2 3 4 5 6] Linha de teste - tamanho = 0: [] 0....*....0....*....0....*....0....*....0....*....0....*....0] 1 2 3 4 5 6] Linha de teste - tamanho = 9: [aaaaa aaa] 0....*....0....*....0....*....0....*....0....*....0....*....0] 1 2 3 4 5 6] aaaaa aaa Linha de teste - tamanho = 25: [ aaaaa aaa ] 0....*....0....*....0....*....0....*....0....*....0....*....0] 1 2 3 4 5 6] aaaaa aaa Procure ver como essas linhas foram escolhidas

-
C++ c++ Como fazer com que clique em jogar novamente e o jogo começe do zero?
arfneto respondeu ao tópico de Fran Botene em C/C#/C++
Jogo tem um único construtor e um método inicializar(), mesmo caso do Personagem. Você escreveu esses métodos? Ou pode usar override e redefinir algo? Esse é o ponto onde pode salvar status para recontruir os personagens por exemplo. Ou suspender um jogo, essas coisas -
C++ c++ Como fazer com que clique em jogar novamente e o jogo começe do zero?
arfneto respondeu ao tópico de Fran Botene em C/C#/C++
Talvez pudesse detalhar a estrutura das classes, os destrutores, construtores, a maneira como salva a s informações durante o jogo, essas coisas. Tem uma especificação do jogo? A estrutura dos dados a serem salvos? -
Eu te disse no início que esse caminho é mais complicado. Você não precisa sequer salvar a linha de entrada porque o programa não tem memória. Depois de ler toda a linha pode ter uma palavra ainda sendo lida e você pode ter que que imprimir também Você precisa tratar também Se a linha começa por espaços Se a linha termina com espaços Se a linha está toda em branco Não entendi porque voltou a ler da entrada padrão se o seu programa não funciona ainda nem para as linhas de teste // char * str = "caixa jujuba casa bar telefone marinha melao"; char str [80];
-
Olá! Muito bem. Assim vai progredir muito mais depressa... Definir a frase não vai corrigir nada, só vai acelerar a solução... Devia ter copiado o resto que eu coloquei lá, inclusive a "régua" Antes de tudo: considere que o seu loop mais externo tem que consumir todos os caracteres da string de entrada. TODOS. Se você olhar para o que escreveu ele sequer faz isso... while (str[i] != '\0') { while (str[i] != ' ') { str2[j] = str[i]; // copiando as palavras para um vetor i = i + 1; } while (str[i] == ' ') { i = i + 1; } tam = strlen(str2); O segundo loop aí, esse que era pra copiar a palavra --- e não as palavras, como você escreveu --- vai "comer" a string inteira inclusive o \0.... Pense dessa maneira: as letras estão vindo, até vir um \0 ou um fim de arquivo. Cada letra pode ou não ser um espaço, e o significado de ser um espaço depende de eu estar já lendo uma palavra ou não. Só isso Só isso adicionado 25 minutos depois Veja a diferença de começar seu programa assim: { char str[80]; char str2[80]; int i, j, tam, qt; i = 0; j = 0; qt = 0; // primeiras linhas de teste char* linha1 = " teste aaaaa AEITEstetee"; char* linha2 = " testeee"; char* linha3 = "teste testea testea"; // copia uma i = strlen(linha2); for (j = 0; j <= i; j++) str[j] = linha2[j]; // short t_str = (short) strlen(str); short ix = 0; printf("\n\nLinha de teste - tamanho = %d:\n\n[%s]\n", t_str, str); printf(" 0....*....0....*....0....*....0....*....0....*....0....*....0]\n"); printf(" 1 2 3 4 5 6]\n"); while (str[ix] != '\0') { printf("[%d/%d]=[%c] (%d em decimal)\n", ix, t_str, str[ix], str[ix]); ix++; } E ele imprimir isso Linha de teste - tamanho = 9: [ testeee] 0....*....0....*....0....*....0....*....0....*....0....*....0] 1 2 3 4 5 6] [0/9]=[ ] (32 em decimal) [1/9]=[ ] (32 em decimal) [2/9]=[t] (116 em decimal) [3/9]=[e] (101 em decimal) [4/9]=[s] (115 em decimal) [5/9]=[t] (116 em decimal) [6/9]=[e] (101 em decimal) [7/9]=[e] (101 em decimal) [8/9]=[e] (101 em decimal) Então você já sabe que ele leu a linha2 direitinho. Ela tem 9 letras. Tem 4 vogais. Na régua você vê que "testeee"começa na coluna 2 e as duas primeiras estão em branco. Nas linhas você as letras passando e os códigos delas.... A partir daí você constrói sua lógica. Use seu programa pra te ajudar.
-
Entendo. Mas está seguro de que o enunciado te dá essa liberdade de supor limites? Se o instrutor testar seu programa apenas digitando um monte de letras seu programa vai cancelar... Como eu te disse, você não precisa ler e salvar palavras e tal. Muito menos que isso. É como se seu programa ficasse parado vendo as letras passarem... Começou uma palavra? Começa a contar as vogais Terminou a palavra? se tem mais de 3 vogais imprime. Se não tem esquece tudo e começa de novo. Não se esqueça das vogais maiúsculas... Elas também tem direitos Insisto: está fazendo muito mais que o necessário Imprima a frase que você leu pra ir te guiando nos testes Não precisa zerar a str2 a cada palavra. Você vai escrever as próximas palavras no mesmo lugar: basta colocar um único 0 quando acabar de copiar a palavra e estará ok Teste seu programa com uma string local ao invés de ficar lendo: demora muito e fica mais difícil de reproduzir um erro Veja char* linha1 = " teste aaaaa AEITEstetee"; char * linha2 = "teste"; char* linha3 = "teste testea testea"; já são testes válidos pra sua rotina... Use essas strings antes de passar a usar gets(). Vai progredir mais rápido e depois deixa as que já testou como comentário e continua... Acha que sabe fazer assim? quer um exemplo? Acho que seu programa não funciona se a cadeia de teste começar por brancos... É mais simples ler uma letra por vez e não se preocupar com a linha, porque na verdade não faz diferença: veja seu loop em str tem que passar por possíveis várias ocorrências de str2... Veja o exemplo acima linha3 por exemplo adicionado 21 minutos depois Veja a diferença de usar isso em seu próprio programa: i = 0; j = 0; qt = 0; // copia linha de teste sem usar strcpy() char* linha1 = " teste aaaaa AEITEstetee"; char* linha2 = "teste"; char* linha3 = "teste testea testea"; // i = strlen(linha1); for (j = 0; j <= i; j++) { str[j] = linha1[j]; } printf("Linha de teste:\n[%s]\n", str); printf(" 0....*....0....*....0....*....0....*....0....*....0....*....0]\n"); printf(" 1 2 3 4 5 6]\n"); /* // depois testa lendo do teclado. E um porre e demora demais j = 0; printf("digite a sequencia de strins: "); fgets(str, 80, stdin); // frase digitada */ //if (!qt) return 0; while (str[i] != '\0') Apenas acrescentei essas linhas antes do fgets(). Aí o programa roda com as linhas de teste. basta mudar a cópia no primeiro loop i = strlen(linha2); for (j = 0; j <= i; j++) str[j] = linha2[j]; E imprime a linha que vai usar pro teste e uma "régua" com os números de coluna que pode precisar durante o teste já que tem muitos índices... Veja para a linha2: Linha de teste: [ teste aaaaa AEITEstetee] 0....*....0....*....0....*....0....*....0....*....0....*....0] 1 2 3 4 5 6] Depois pra usar outros testes pode digitar direto sobre o texto lá na declaração... Continue escrevendo
-
C Encontrar palavra em uma frase e substituir por outra
arfneto respondeu ao tópico de Claudir Becher em C/C#/C++
Talvez devesse citar essas passagens estranhas e alguém poderia te ajudar. Talvez o próprio autor das estranhas passagens. Não acho que deva perder a oportunidade de perguntar qualquer coisa, afinal é um forum Sério? A noção de sílaba não ajuda em nada em C, C# ou C++. Imagine a frase "A casa de papel na verdade era de plastico", a palavra "de" e a palavra nova "quase de" A frase deveria terminar "A casa quase de papel era na verdade quase de plastico" e você teria que cuidar de evitar um loop porque a palavra "de" retorna na palavra nova "quase de". Nesse caso não poderia tocar na palavra "verdade". Nada especial, mas esse é um outro tema: é preciso definir uma palavra perfeitamente, estabelecer uma gramática, como - uma palavra é um sequência de caracteres delimitada por espaço ou TAB - tratar os casos em que uma palavra começa já no início da frase, porque não teria delimitador - tratar os casos em que a palavra ocorre no final da frase Não existe noção de sílaba em programação. Deve estar definida perfeitamente no enunciado a noção de palavra. Esse é um tema comum no processamento de texto, como compiladores ou editores de texto. Por acaso tem um tópico paralelo no forum sobre tratar palavras. Talvez ajude em algo. As rotinas e o método que expliquei aqui envolvem trocar uma ou todas ocorrências de uma string em outra maior ou igual à primeira. Talvez no outro tópico eu poste uma solução de como tratar palavras num sentido mais de gramática. Não é difícil incorporar aqui se entendeu as implementações oferecidas. lá que ajude talvez tenha algo -
Olá! Você só precisa imprimir as palavras com 3 ou mais vogais Você então não precisa se "lembrar" das palavras que não tenham ao menos 3 vogais salvar palavra por palavra em outro vetor se for salvar, ela tem que ter o mesmo tamanho que a linha inicial, então se str1 tem 80 str2 teria que ter ao menos 80 ou seu programa vai dar erro se testar com mais 20 (no seu caso) mas não pode cancelar também com mais de 80 na frase Pense assim: você nem mesmo precisa salvar a linha toda: basta: ir lendo as letras monta a palavra se tem ao menos 3 vogais imprime ao acabar a palavra continua lendo ao acabarem as letras acabou o programa Só isso. Acha que consegue escrever assim? adicionado 9 minutos depois Não se esqueça que as vogais maiúsculas também tem direitos...
-
C Encontrar palavra em uma frase e substituir por outra
arfneto respondeu ao tópico de Claudir Becher em C/C#/C++
@MB_ É como o princípio jurídico da presunção de inocência: você é inocente até que se prove o contrário. O enunciado é um contrato. Como um contrato de prestação de serviços ou a especificação de um projeto: você não pode fazer menos do que está claro lá. Mas não deve fazer mais. Em certos casos você pode mesmo ter dificuldades comerciais ou jurídicas se fizer mais. No enunciado não diz que você deve substituir todas as ocorrências. Está no tópico. Talvez esses longos posts não tenham te agradado --- ainda que não tenha lido --- porque não é sua a dúvida afinal. Vou resumir o que tem lá. Espero que o resumo não seja longo: uma rotina troca_palavra_na_frase(), com menos de 10 linhas, que é uma possível solução para o problema, trocando a primeira ocorrência da palavra na frase uma rotina troca_toda_palavra_na_frase(), também com menos de 10 linhas, que troca todas as ocorrências da palavra na frase apresentação da rotina strstr() da bliblioteca padrão, que é praticamente a solução para o problema uma discussão sobre a lógica desse problema e a aplicação da função strstr() uma implementação de uma idêntica função strstr() para o caso provável de não se poder usar essa função na solução do enunciado um programa de teste para as duas rotinas e que pega os 3 parâmetros da linha de comando, para não ter que ficar compilando o programa a cada teste um script de teste que roda um conjunto razoável de testes um arquivo de saída de uma execução desse script um link para download desse material Talvez --- e eu repito talvez --- se tiver você alguma dúvida sobre C ou C++ ou C# e postar algo aqui, aprecie o fato de alguém voluntariamente se dar ao trabalho de discutir desse modo "longo" a sua dúvida! Abraço a todos -
C Encontrar palavra em uma frase e substituir por outra
arfneto respondeu ao tópico de Claudir Becher em C/C#/C++
Não. O enunciado NÃO diz para substituir todas as ocorrências, então basta a primeira. E tem uma pegadinha nesse caso que eu acho que seria maldade passar para os alunos Veja o enunciado: Por outro lado, não tem nada de especial substituir todas, se temos uma rotina int troca_palavra_na_frase(char* frase, char* palavra, char* palavra_nova) que faz a troca e retorna a posição da palavra na frase ou (-1) se não achou a palavra na frase, então basta um loop para trocar todas Pegadinha Ao trocar todas as ocorrências é preciso adiantar a posição do ponteiro da frase para além da ocorrência substituída a cada vez na frase. Não dá pra chamar sempre com a frase completa porque podemos ter um loop infinito. Porque? A palavra nova pode trazer novas ocorrências da palavra antiga e aí a troca nunca acaba Sabendo disso, podemos escrever: int troca_toda_palavra_na_frase(char* frase, char* palavra, char* palavra_nova); Que usa a rotina anterior até se esgotarem as ocorrências e retorna o número de substituições feitas na frase. Eis um código possível, imune à pegadinha: int troca_toda_palavra_na_frase(char* frase, char* palavra, char* palavra_nova) { int n, quantos = 0; char* indice = frase; do { n = troca_palavra_na_frase(indice, palavra, palavra_nova); quantos += 1; if (n < 1) return quantos; // acabaram as palavras na frase indice += n; // adianta os indicadores } while (1>0); } // end troca_palavra_na_frase() A linha indice += n; adianta o ponteiro na frase... E fica claro porque o pessoal que escreveu strstr() tinha razão ao retornar o endereço. Tudo fica mais fácil... Caras espertos. Podendo usar strstr(), a rotina em string.h Como eu disse antes, acho que não é pra usar strstr() nesse exercício porque ficaria muito trivial. Mas não está escrito lá. Eu perguntaria ao instrutor. Na dúvida eu mostrei antes como escrever outra, ch_strstr(). Está logo acima, mas vamos supor que a gente possa usar: a rotina que troca podia ser só: int troca_palavra_na_frase(char* frase, char* palavra, char* palavra_nova) { int t = strlen(palavra); if (t != strlen(palavra_nova)) return -2; if (strlen(frase) < strlen(palavra)) return -3; char* pos = strstr(frase, palavra); // retorna 0 ou o endereco da palavra na frase if (pos == 0) return -1; // nao tinha a palavra na frase for (int i = 0; i < t; i += 1) *(pos + i) = *(palavra_nova + i); // posicao da troca return (pos - frase); // so isso } // end troca_palavra_na_frase() Só 4 linhas se não considerar os 3 testes óbvios... Usando a linha de comando: Abaixo está um programa desses, troca, que pode ser mais útil pra testar isso. Se chama assim, direto na linha de comando troca Frase Palavra Palavra_Nova e o programa faz a troca usando as duas rotinas, a que troca a primeira ocorrência e devolve a posição e a que troca todas as ocorrências e devolve o total de substituições. Se algum dos argumentos tem espaços então se usam aspas Exemplo da execução troca Banananana na n4 troca() frase ..........[Banananana] palavra ........[na] palavra nova ...[n4] retornou 2 frase no final..[Ban4nanana] testando trocar todas as ocorrencias da palavra na frase retornou 4 frase no final..[Ban4n4n4n4] Exemplo da execução quando tem espaços nos argumentos troca "frase abcd frasefraseXYZT" " abcd " "_ABCD_" troca() frase ..........[frase abcd frasefraseXYZT] palavra ........[ abcd ] palavra nova ...[_ABCD_] retornou 5 frase no final..[frase_ABCD_frasefraseXYZT] testando trocar todas as ocorrencias da palavra na frase retornou 1 frase no final..[frase_ABCD_frasefraseXYZT] De todo modo, este programa abaixo implementa as DUAS rotinas #define _CRT_SECURE_NO_WARNINGS #include "stdio.h" #include "string.h" int troca_palavra_na_frase(char*, char*, char*); int troca_toda_palavra_na_frase(char*, char*, char*); int main(int argc, char** argv) { if (argc < 4) { printf("\nARFNeto\n\n\tUse: troca Frase Palavra Palavra_Nova\n\n"); return 0; } // end if printf("\ \n troca()\n\n\ frase ..........[%s]\n\ palavra ........[%s]\n\ palavra nova ...[%s]\n\n", argv[1], argv[2], argv[3] ); int n = troca_palavra_na_frase(argv[1], argv[2], argv[3]); printf(" retornou %d\n\n", n); printf(" frase no final..[%s]\n\n", argv[1]); printf("testando: trocar TODAS as ocorrencias da palavra na frase"); n = troca_toda_palavra_na_frase(argv[1], argv[2], argv[3]); printf(" retornou %d\n\n", n); printf(" frase no final..[%s]\n\n", argv[1]); return 0; } int troca_palavra_na_frase(char* frase, char* palavra, char* palavra_nova) { int t = strlen(palavra); if (t != strlen(palavra_nova)) return -2; if (strlen(frase) < strlen(palavra)) return -3; char* pos = strstr(frase, palavra); // retorna 0 ou o endereco da palavra na frase if (pos == 0) return -1; // nao tinha a palavra na frase for (int i = 0; i < t; i += 1) *(pos + i) = *(palavra_nova + i); // retorna a posicao da troca return (pos - frase); // so isso } // end troca_palavra_na_frase() int troca_toda_palavra_na_frase(char* frase, char* palavra, char* palavra_nova) { int n, quantos = 0; char* indice = frase; do { n = troca_palavra_na_frase(indice, palavra, palavra_nova); quantos += 1; if (n < 1) return quantos; // acabaram as palavras na frase indice += n; // adianta os indicadores } while (1>0); } // end troca_palavra_na_frase() Nenhuma das funções tem mais que uns poucos comandos então nem vou postar o programa de teste no site onde tem os programas que eu posto às vezes aqui.. Um arquivo de saída com vários testes está anexado, bem como um arquivo com as linhas de execução do teste saida-bat.txt teste.bat.txt -
C Encontrar palavra em uma frase e substituir por outra
arfneto respondeu ao tópico de Claudir Becher em C/C#/C++
menos, bem menos meu amigo! Mas escrevo também nesse forum e outros para tirar dúvidas ou conhecer algum problema mais interessante. Abraço -
C++ Enviar endereço de memoria do vetor para função e QListWidget ( QTCREATOR + C++)
arfneto respondeu ao tópico de Reberth Siqueira em C/C#/C++
Olá Control e Shift são os modificadores comuns no Windows e no Linux para seleção. Veja numa pasta de arquivos no Windows Explorer por exemplo: ao selecionar um elemento e depois ao selecionar um segundo apertando shift seleciona o intervalo todo entre eles. E com Control seleciona um a um. é muito comum ao selecionar fotos por exemplo nas pastas de imagens. No seu caso deve ser possível manipular a seleção no evento que trata o click nas células da lista... Talvez deva abrir outro tópico pra ver se alguém já fez isso... De volta ao tópico, só duas notas: Em declarações como int *a[] Você começa a ler da direita para a esquerda na hora de preparar os parâmetros. Eu sempre acho mais claro declarar int* a[]; Para deixar claro de a[] é do tipo int* e nunca misturo declarações de ponteiros com variáveis normais. Nesse caso você lê, da direita para a esquerda colchetes: então tem um vetor a esquerda --- tem uma exceção aqui, como no caso do new(type[]) mas não é assunto para esse tópico: trata-se da sobrecarga do operador [] . depois vem a variável a, que então é o vetor depois vem o asterisco, então a é um vetor de ponteiros depois vem int, e aí se vê que é um vetor de ponteiros para int Note a versão abaixo do mesmo programa de teste que postei, desta vez sem usar a notação [ ] #include <iostream> #include <stdio.h> void teste(int** a) { printf("%d", **a); return; } // end teste() int main(void) { int** a; std::cout << ":) testando teste()" << std::endl; a = new(int*[1]); // um vetor, mas de um so *a = new(int); // aloca o primeiro **a = 12345678; // usa o primeiro teste(a); std::cout << std::endl << "deve ter mostrado... " << *a[0] << std::endl; free(*a); // libera o primeiro free(a); // libera o vetor return 0; } // end main() Esta é a maneira mais comum de usar isso, ou de ler isso, quando se usa esses frameworks tipo SDL ou Qt ou GTK+ e coisas assim. Em geral não se vê colchetes misturados com *. O resultado, claro, é o mesmo. -
C Encontrar palavra em uma frase e substituir por outra
arfneto respondeu ao tópico de Claudir Becher em C/C#/C++
Olá! Acho que está indo bem, mas precisa separar dois pontos: estar certo de que encontrou a palavra na frase depois ir até o local e trocar letra por letra. como sempre sugiro aqui: não misture as coisas durante os testes: não comece lendo valores da tela: leva uma eternidade a toa. depois que estiver ok você coloca a parte da leitura em minutos evite usar tantas variáveis de uma letra só juntas. Fica mais difícil para você mesmo acompanhar comente o que você acha que devia estar acontecendo, direto nas linhas de código atente para o enunciado: é um contrato entre você e o instrutor: procure não fazer mais, mas se garantir de que fez o mínimo. Nesse caso aqui, a frase pode ter até 500 caracteres, imagino. Então a palavra também pode ter esse tamanho: uma frase pode ser de uma palavra só. Eis um possível roteiro comentado para escrever isso, com exemplo e o código. Atente para esta possibilidade e para o que eu escrevi acima: não tente escrever tudo de uma vez. isso aqui é só um exemplo: pode não ser nem bom ou conter erros... Mas pode ser bom e estar certinho A gente precisa aqui de uma rotina assim: int troca_palavra_na_frase(char* frase, char* palavra, char* palavra_nova) { // ... }; O tamanho máxima da frase é de 500 caracteres uma frase pode ter uma palavra só e então o tamanho máximo de palavra é também 500 a nova palavra tem o mesmo tamanho, está escrito lá. Então o tamanho máximo da palavra nova também é 500. Se eu rodar char* frase = "azul"; char teste[501]; // 500 mais o null no final strcpy( teste, frase ); troca_palavra_na_frase(teste, "azul", "abcd"); printf("final: [%s]\n", teste); No final a frase vai ficar "abcd". Seguindo o plano: strstr() Em C tem na biblioteca padrão uma rotina que em muitos lugares -- livros e sites --- aparece assim char *strstr(const char *haystack, const char *needle); Exemplo aqui podia ser assim char *strstr(const char *palheiro, const char *agulha) claro que em português se fala em encontrar a agulha no palheiro --- needle e haystack --- e em português as posições provavelmente seriam invertidas: char *strstr(const char *agulha, const char *palheiro); Essa rotina devolve o endereço da string agulha na string palheiro, ou zero se não acha. É quase a solução para o exercício e assim imagino que não podemos usar essa strstr(). Esse é quase o nosso objetivo afinal. Mas se a gente tivesse uma rotina dessas a nossa rotina troca_palavra_na_frase() ficaria bem simpes: strstr() devolve a posição inicial da agulha no palheiro, ou zero. Então se strstr() existisse bastaria --- se ela não voltou zero --- começar a colocar na frase o novo valor, a partir da exata posição que a rotina devolveu. Nada mais. Como elas são do mesmo tamanho, não tem que ver o 0 no final nem nada. Uma possível rotina: int troca_palavra_na_frase(char* frase, char* palavra, char* palavra_nova) { int t = strlen(palavra); if (t != strlen(palavra_nova)) return -2; if (strlen(frase) < strlen(palavra)) return -3; char* pos = ch_strstr(frase, palavra); // retorna 0 ou o endereco da palavra na frase if (pos == 0) return -1; // nao tinha a palavra na frase for (int i = 0; i < t; i += 1) // tinha, entao faz a troca { *(pos + i) = *(palavra_nova + i); // retorna a posicao da troca } return (pos - frase); // so isso } // end troca_palavra_na_frase() São 5 linhas de código na verdade. Note que ela retorna -1 quando não achou a palavra na frase -2 quando a palavra e a palavra nova não tem o mesmo tamanho -3 quando a palavra for menor que a frase Ou retorna a posição da palavra na frase E essa ch_strstr()? Era a strstr()? Se você puder usar isso em seu exercício já terminamos: apenas troque ch_strstr() por strstr() e já estará funcionando. O header "string.h" já está declarado lá em seu programa mesmo #include "string.h" E essa rotina fica com a família lá, como strcpy() e strlen(). A gente não pode escrever outra strstr() assim fácil aqui, com o mesmo nome, porque elá está na biblioteca padrão junto com as outras. E eu não queria escrever essas duas outras também... A gente escreve aqui no tempo livre afinal... E ao incluir #include "string.h" vem tudo junto. Então...Criando outra strstr() Essa é a primeira consideração: veja o exemplo abaixo 0 XYZT 01234567890123456789 frase com 20 caracteres XYZT | \ - 16 Na frase a palavra pode estar a partir do inicio, 0 ate a posição final em que ela cabe: Uma versão .br.ch de strstr() podia ser char* ch_strstr(const char* Palheiro, const char* Agulha) { int n = strlen(Palheiro); int t = strlen(Agulha); int ultimo = n - t; int matches = 0; char* pos = 0; char* posFrase = (char*) Palheiro; char* posPalavra = (char*) Agulha; int candidato = 0; // ja sei onde procurar: de 0 ate 'ultimo' for (int i = 0; i <= n; i++) { // tem duas situações: posso estar em uma parte // da string que eu procuro ou nao if (candidato!=0) { // ja estou em um candidato if (*(i + posFrase) != *(posPalavra)) { matches = 0; candidato = 0; posPalavra = (char*)Agulha; // comeca de novo } else { matches = matches + 1; if (matches == t) return pos; posPalavra += 1; } // end if } else { // ainda buscando um inicio if (i > ultimo) return 0; // nao cabe mais if ( *(i + posFrase) != *(posPalavra) ) continue; // achou a primeira letra candidato = 1; posPalavra += 1; pos = posFrase + i; matches = 1; // achei a primeira letra } // end if } // end for return 0; } // end strstr() Preste atenção especial ao if interno ao for e vai ver algo parecido com o que está faltando em seu programa exemplo. Se não entender escreva perguntando De volta à função, nada complicado. Apenas um loop nesse intervalo que definimos, procurando pela palavra na frase. Tem um if dentro porque a gente pode estar em duas situações: ou procurando o início da palavra ou vendo se ela está todinha lá a partir do início. E ela pode não estar inteira então temos que poder voltar a procurar. Esse é o código, nessa ordem. Claro, é só um exemplo. Note que ch_strstr() devolve um endereço e isso é bem conveniente. Estamos reproduzindo o comportamento da rotina strstr() porque como eu já disse, os caras que escreveram isso são bem melhores que eu... Quando eu escrevo aqui eu sempre recomendo: escrever e testar aos poucos, sem ler da console ou ficar compilando. Assim, no programa de teste tem uma rotina teste1() que faz vários testes para ch_strstr() e a gente não passa adiante até ter uma certa convicção de que ela funciona... Veja o início dessa rotina de testes: void teste1() { // // testes para strstr // char* Palheiro = "Palheiro"; char* Agulha = "Agulha"; char teste_frase[80]; char teste_palavra[80]; int n; strcpy(teste_frase, Palheiro); strcpy(teste_palavra, "iro"); n = testa_strstr(teste_frase, teste_palavra); printf("strstr(%s,%s) retornou %d\n", Palheiro, teste_palavra, n); e a testa_strstr() int testa_strstr(char* palheiro, char* agulha) { char* r = ch_strstr(palheiro, agulha); if (r == 0) { printf("nao achou [%s] em [%s]\n", agulha, palheiro); } else { printf("achou [%s] em [%s]!\n", agulha, palheiro); printf("posicao: %d\n", (r - palheiro) ); } return (r != 0); } // end testa_strstr() Adiante então Supondo que a ch_ststr() funciona, então a troca_palavra_na_frase() também deve funcionar, com todas as suas 10 linhas de código. Um código de teste podia ser assim, considerando o exemplo acima. Note que os casos óbvios de ter a palavra XYZT no começo no meio no fim ausente e o caso de a palavra ser a frase inteira já estão cobertos no teste... Veja logo nas primeiras linhas void teste2() { char* palavra = "XYZT"; char* palavra_nova = "abcd"; char* frase = "01234567890123456789"; // sem a palavra char* frase_i = "XYZT4567890123456789"; // palavra no inicio char* frase_m = "01234567XYZT23456789"; // palavra no meio char* frase_f = "0123456789012345XYZT"; // palavra no fim char teste_frase[501]; char teste_palavra[501]; char teste_palavra_nova[501]; int n; // o exemplo inicial strcpy(teste_frase, "azul"); strcpy(teste_palavra, "azul"); strcpy(teste_palavra_nova, "abcd"); printf("\ troca_palavra_na_frase()\n\ frase ..........[%s]\n\ palavra ........[%s]\n\ palavra nova ...[%s]\n\n", teste_frase, teste_palavra, teste_palavra_nova ); n = troca_palavra_na_frase(teste_frase, teste_palavra, teste_palavra_nova); printf(" retornou %d\n\n", n); printf(" frase no final..[%s]\n\n\n", teste_frase); ...... O resto da rotina teste2() faz isso. E o código da saída de um teste desses está disponível junto com o programa de teste troca_palavra_na_frase() frase ..........[azul] palavra ........[azul] palavra nova ...[abcd] retornou 0 frase no final..[abcd] A saída do teste completo está aqui saída do programa de teste está aqui como exemplo O programa de teste Tem um botão para download em formato zip da pasta toda em https://github.com/ARFNeto-CH/ch-191006-frase A função main() não podia ser mais simples: tem uma linha só: teste1(); até estar mais ou menos seguro com a ch_strstr() teste2(); para testar a rotina que troca a palavra E estão preservadas lá teste1() e teste2() porque se achar um erro pode ser na primeira função e não queremos perder isso. -
C++ Enviar endereço de memoria do vetor para função e QListWidget ( QTCREATOR + C++)
arfneto respondeu ao tópico de Reberth Siqueira em C/C#/C++
Olá. Ainda está bem errado Note que o argumento da função não é apenas um vetor: é um vetor de ponteiros para int. Então quando chega em teste() ... void teste(int *a[]) { printf("%d", *a); } *a é do tipo int[] e está errado o printf(). Como você disse e declarou, vetor é um vetor, então podia ser, para imprimir o primeiro printf("%d", (*a)[0]); Agora em main() também está errado... a[0] = 1; Veja, você declarou vetor como int*[] na função: vetor é um vetor de ponteiros para int. Então você atribuir um valor a ele por sua conta é quase sempre um erro e vai cancelar seu programa. Ao invés disso: int main(void) { int a[1]; a[0] = 1; teste(&a); return 0; } Escreva assim: int main(void) { int* a[1]; std::cout << ":) testando teste()" << std::endl; a[0] = new(int); *a[0] = 12345678; teste(a); std::cout << std::endl << "deve ter mostrado... " << *a[0] << std::endl; free(a[0]); // melhor se acostumar a liberar tudo que aloca return 0; } // end main() E verá isso :) testando teste() 12345678 deve ter mostrado... 12345678 Use seu programa para testar seu programa... adicionado 17 minutos depois Por outro lado, pela documentação de QListWidget() essa função só tem um parâmetro, que é o endereço da parent window, do tipo QWidget() QListWidget(QWidget *parent = nullptr) e pode ou deve ser declarado como nullptr De volta ao programa, não custa nada deixar um teste inteiro #include <iostream> #include <stdio.h> void teste(int* a[]) { printf("%d", (*a)[0]); return; } // end teste() int main(void) { int* a[1]; std::cout << ":) testando teste()" << std::endl; a[0] = new(int); *a[0] = 12345678; teste(a); std::cout << std::endl << "deve ter mostrado... " << *a[0] << std::endl; free(a[0]); return 0; } // end main() -
Quando der um tempo vou postar um exemplo a partir do seu programa
-
É assim que funciona. Para mudar de linha apenas termine a linha com \ e continue nas próximas. No entanto para longas strings talvez seja mais claro escrever as strings todas em outro lugar e usar %s no printf() Veja abaixo Escrever entre aspas "entre aspas" Escrever entre aspas "entre aspas e """""""" em varias linhas assim aspas" As strings, uma por linha: longa strings e tem aspas [""""""""""] entre colchetes longa strings e tem aspas """""""""" Fim Impresso por esses comandos char* longa_string1 = "longa strings e tem\ aspas [\"\"\"\"\"\"\"\"\"\"] entre colchetes"; char* longa_string2 = "longa strings e tem\ aspas \"\"\"\"\"\"\"\"\"\""; printf("Escrever entre aspas \"entre aspas\" \n"); printf("Escrever entre aspas \"entre \ aspas e \"\"\"\"\"\"\"\" em varias linhas \ assim aspas\" "); printf( "\n\nAs strings, uma por linha:\n%s\n%s\nFim", longa_string1, longa_string2 );
-
Olá Use a barra invertida antes de cada "
-
Muito bem! Boa ideia usar char** e alocar o vetor como fez. É exatamente assim que o compilador prepara o vetor de argumentos da linha de comando, argv, que é o char** mais declarado do universo Vejo que acabou não escrevendo a rotina única de comparação como te disse. Devia ter feito isso. O programa ficaria um pouco mais limpo e poderia como eu disse comparar mais facilmente os tempos de execução. Claro que tem o custo associado a chamar uma função. Mais dois palpites Podia ter antes de tudo escrito uma função simples para mostrar o vetor na tela. Você sabe porque. Podia ter usado antes de tudo o qsort() da biblioteca padrão e a sua função compara() para validar as coisas sem testar duas coisas ao mesmo tempo. O que eu falei sobre os tempos não era sobre a teoria dos algoritmos: eu falava sobre usar o próprio computador e seu programa para testar os tempos de classificação de cada método, usado algo como time() ou getTicks() ou sei lá. De todo modo, parabéns. Legal você postar o código. É um problema clássico e pode ajudar muita gente.
-
muito bom! Parabéns Então já deve ter entendido porque 100% dos métodos admite --- ou exige --- um ponteiro para uma rotina de comparação. Para uma struct particular não tem como o método saber como classificar. Pode ser que o critério de classificação também seja parâmetro por exemplo. Considere :Uma série de struct de cadastro pode ser classificada ora por nome, ora por CPF ora por CEP do endereço de entrega por exemplo Uma série de struct de pedidos para envio pode ser classificada através de uma consulta ao sistema de frete no momento da classificação, mas só se o sistema estiver on-line...... Você pode estar testando suas rotinas de sort então claro quer testar com os mesmos critérios de classificação Imagino que se referia a postar seu código em outro tópico. Meu palpite seria para postar aqui mesmo. E abrir outro tópico apenas se tiver outra dúvida ou comentar algo diferente sobre suas versões de sort(). Comparou os tempos de execução?
-
Olá Danielle Até aqui seu problema não tem a ver com o método de sort. Trata-se apenas da rotina de comparação. Escreva apenas a rotina de comparação e teste em separado. Não faz diferença para o método de sort que vai usar. Vai escrever isso em C ou C++ ou C#? Exemplo de caso em C Apenas para ajudar a entender: C tem acho que em stdlib.h void qsort ( void* vetor, size_t quantos, size_t tamanho, int (*compara)(const void* valor1, const void* valor2) ); e usa o método quicksort que é bem parecido com o merge sort. A chave para esse método é a compara(), que retorna -1, 0 ou 1 conforme a posição relativa dos dois parâmetros valor1 e valor2. E para mudar a ordem de classificação você só precisa mudar a função.... Exemplo de caso em C++ Na biblioteca padrão do C++ acho que em <algorithm> tem a função sort void sort( Iterator primeiro, Iterator ultimo, Bool compara ); e nesse caso primeiro e ultimo são iteradores apontando para o primeiro valor e o indicador de último valor da série, e compara é uma função que retorna true se os dois valores já estão na ordem, false se devem ser invertidos exemplo de caso em C# ih... Não programo em C# Em resumo escreva uma função compara() que compara os dois nomes, e teste com a linguagem que precisar usar. E depois escreva o seu sort(). Merge Sort no caso. Merge sort, selection sort, bubble sort, quicksort, XYZSort não faz diferença: já terá sua função compara() pronta e testada... E sem ela não vai classificar nada. C strcmp() int strcmp(const char *str1, const char *str2) retorna <0, 0 ou > 0 conforme o valor de str1 e str2 e serve direitinho para o que precisa. Pode usar essas funções ou tem que escrever sua comparação? Postei dias atrás aqui um programa em C que usava qsort() eu acho, em C. e tinha umas funções de comparação, claro. Avise se precisar e eu procuro aqui. Ou use as ferramentas do forum. Escreva mais





Sobre o Clube do Hardware
No ar desde 1996, o Clube do Hardware é uma das maiores, mais antigas e mais respeitadas comunidades sobre tecnologia do Brasil. Leia mais
Direitos autorais
Não permitimos a cópia ou reprodução do conteúdo do nosso site, fórum, newsletters e redes sociais, mesmo citando-se a fonte. Leia mais
