
Gabriel Torres
-
Posts
8.858 -
Cadastrado em
-
Última visita
Tipo de conteúdo
Artigos
Selos
Livros
Cursos
Análises
Fórum
Tudo que Gabriel Torres postou
-
Tópico para a discussão do seguinte conteúdo publicado no Clube do Hardware: Placa de Vídeo ATI Radeon X1900 XTX "Nossos testes com a mais nova placa de vídeo topo de linha da ATI, a Radeon X1900 XTX." Comentários são bem-vindos. Atenciosamente, Equipe Clube do Hardware https://www.clubedohardware.com.br
-
 O Radeon X1900 XTX, antes conhecido como R580, é o novo chip topo de linha da ATI, substituindo o Radeon X1800 XT como o mais rápido processador de vídeo da ATI. Nós recebemos uma amostra de referência deste modelo da ATI, então vamos comparar seu desempenho com o de outros membros da série Radeon X1000, com o de chips anteriores da ATI, e também com produtos concorrentes da NVIDIA, especialmente o GeForce 7800 GTX. Figura 1: Placa de referência Radeon X1900 XTX. Nós publicamos um artigo completo explicando o que há de novo na série Radeon X1900, portanto não repetiremos aqui tudo o que já explicamos lá. A característica mais importante desse novo chip é que ele possui 48 processadores pixel shader, três vezes mais que o Radeon X1800 XT e duas vezes mais que o GeForce 7800 GTX. Até agora existem dois chips na família Radeon X1900: o Radeon X1900 XT, rodando a 550 MHz e acessando a memória a 1,45 GHz (taxa de transferência de 46,4 GB/s), e o Radeon X1900 XTX, rodando a 650 MHz e acessando a memória a 1,55 GHz (taxa de transferência de 49,6 GB/s). Ambos acessam suas memórias a uma taxa de 256 bits. Você pode ver em nosso tutorial “Tabela comparativa dos chips ATI” a diferença entre este novo chip e os outros chips da ATI, ao passo que em nosso tutorial “Tabela comparativa dos chips NVIDIA” você pode compará-lo com seus concorrentes fabricados pela NVIDIA. Você pode ver a placa de referência para o Radeon X1900 XTX nas Figuras 2 e 3. Figura 2: Placa de referência ATI Radeon X1900 XTX. Figura 3: Placa de referência ATI Radeon X1900 XTX vista de trás. Vamos agora dar uma olhada mais de perto na placa de referência para o Radeon X1900 XTX da ATI. Nós desmontamos o dissipador de calor da placa de vídeo para dar uma olhada, veja a Figura 4. Se você prestar atenção, vai notar que a base do dissipador de calor – a parte que encosta no chip gráfico – é feita de cobre. As aletas do dissipador de calor também são feitas de cobre. A ventoinha puxa o ar quente para fora do gabinete, ajudando bastante a reduzir a temperatura interna do PC. Porém, por causa desse mecanismo de exaustão, além do slot PCI Express 16x essa placa usa o slot imediatamente ao lado (normalmente um slot PCI Express x1). Figura 4: Dissipador de calor da placa de referência Radeon X1900 XTX. Figura 5: Placa de vídeo com seu dissipador de calor removido. Esta placa de vídeo usa oito chips de memória GDDR3 de 512 Mbits e 1,1 ns chips da Samsung (K4J52324QC-BJ11), totalizando seus 512 MB de memória de vídeo (512 Mbits x 8 = 512 MB). Estes chips podem rodar a até 1,8 GHz. Como esta placa de vídeo acessa a memória a 1,55 GHz, há 16% de espaço para um overclock de memória dentro das suas especificações. Mas é claro que você pode tentar um overclock além das especificações. Figura 6: Chip de memória GDDR3 de 1,1 ns usado pela placa de referência da ATI para o Radeon X1900 XTX. Esta placa de referência possui função de captura de vídeo (VIVO), usando o chip ATI Rage Theater. Figura 7: Chip ATI Rage Theater para captura de vídeo. Processador: Radeon X1900 XTX rodando a 650 MHz. Memória: 512 MB GDDR3 de 1,2 ns a 256 bits da Samsung (K4J52324QC-BJ12), rodando a 1,55 GHz. Conexão: PCI Express 16x. Conectores: Dois DVI e um mini-DIN para a saída S-Video. Número de CDs que acompanham a placa: Não se aplica. Jogos que acompanham a placa: Não se aplica. Programas que acompanham a placa: Não se aplica. Mais informações: http://www.ati.com Preço médio nos EUA*: US$ 620 (para o modelo de 512 MB, que foi o que testamos). * Pesquisado em Shopping.com no dia da publicação deste teste. Este preço é apenas uma referência para comparação com outras placas. O preço no Brasil será sempre maior, pois devemos adicionar o câmbio, o frete e os impostos, além da margem de lucro do distribuidor e do lojista. Em nossos testes de desempenho usamos a configuração listada abaixo. Entre as nossas sessões de teste o único dispositivo diferente era a placa que estava sendo testada. Configuração de Hardware Placa-mãe: DFI LAN Party 925X-T2 (Intel 925X, BIOS de 20 de setembro de 2004) Processador: Pentium 4 3,4 GHz LGA 775 Memória: Dois módulos DDR2-533 CM2X512-4200 CL4 Corsair de 512 MB cada Disco rígido: Maxtor DiamondMax 9 Plus (40 GB, ATA-133) Resolução de vídeo: 1024x768x32@85 Hz Configuração de Software Windows XP Professional, instalado em NTFS Service Pack 2 Direct X 9.0c Versão do driver inf da Intel: 6.0.1.1002 Versão do driver de vídeo ATI: 4.10 (6.14.10.6483) Versão do driver de vídeo ATI: 4.12 (Radeon X850 Platinum Edition) Versão do driver de vídeo ATI: 5.3 (Radeon X800 GT) Versão do driver de vídeo ATI: 5.9 (Radeon X800 GTO) Versão do driver de vídeo ATI: 6.1 (Radeon X1600 XT da HIS) Versão do driver de vídeo ATI: 8.173 beta (Radeon X1000 series) Versão do driver de vídeo ATI: 8.203.3.0 (Radeon X1900 XTX) Versão do driver de vídeo NVIDIA: 66.93 Versão do driver de vídeo NVIDIA: 77.72 (GeForce 7800 GTX) Versão do driver de vídeo NVIDIA: 78.02 (GeForce 7800 GT) Versão do driver de vídeo NVIDIA: 81.98 (GeForce 6800 GS) Programas Usados 3DMark2001 SE 3DMark03 Business 3.50 3DMark05 Business 1.10 Doom III Far Cry 1.3 Adotamos uma margem de erro de 3%. Com isso, diferenças de desempenho inferiores a 3% não podem ser consideradas significativas. Em outras palavras, produtos onde a diferença de desempenho seja inferior a 3% deverão ser considerados como tendo desempenhos similares. O 3Dmark2001 SE mede o desempenho simulando jogos baseados DirectX 8.1. Ele continua sendo um bom programa para avaliar o desempenho de jogos da geração passada, programados em DirectX 8. Neste programa nós executamos seis testes. Rodamos o programa em três resoluções, 1024x768x32, 1280x1024x32 e 1600x1200x32, primeiro sem antialiasing e sem frame buffer, e depois colocando o antialiasing em 4 samples e o frame buffer em triplo. Isso faz aumentar a qualidade da imagem, mas diminui o desempenho. Queríamos ver justamente o quanto de desempenho perdíamos quando colocamos a placa de vídeo para trabalhar com o máximo de qualidade possível. Importante notar que os chips da ATI permitem que o anti-aliasing seja configurado em até 6x. Como os chips da NVIDIA não permitem essa configuração, tivemos de manter a configuração de alta qualidade em 4x, de forma a adotarmos uma configuração que seja válida para todos os chips, fazendo com que a comparação seja válida. Você pode estar se perguntando o motivo de incluirmos um programa "obsoleto" entre os nossos testes de placas de vídeo de última geração. Para nós, tão importante quanto saber o desempenho das placas de vídeo com jogos mais modernos é saber o desempenho da placa quando um jogo mais antigo é executado. Por isto mantivemos este programa em nossa metodologia. Na configuração de 1024x768 sem recursos de aumento de qualidade de imagem, a Radeon X1900 XTX da ATI foi 6,60% mais rápida do que a GeForce 6600 de 256 MB com overclock de fábrica da XFX, 20,47% mais rápida do que a Radeon X600 XT da ATI, 23,21% mais rápida do que a GeForce 6600 da Albatron e 38,80% mais rápida do que a Radeon X600 Pro da Sapphire. A Radeon X1900 XTX da ATI obteve desempenho semelhante ao da GeForce 6600 GT da XFX. A placa testada perdeu para a Radeon X850 XT P.E. da ATI, que foi 32,12% mais rápida, para a Radeon X1800 XT da ATI, que foi 30,55% mais rápida, para a GeForce 7800 GTX da MSI, que foi 25,53% mais rápida, para a Radeon X1800 XL da ATI, que foi 23,40% mais rápida, para a GeForce 7800 GT da NVIDIA, que foi 20,85% mais rápida, para a Radeon X800 GT da HIS, que foi 16,58% mais rápida, para a GeForce 6800 GS da NVIDIA, que foi 15,35% mais rápida, para a GeForce 6800 GT da NVIDIA, que foi 15,28% mais rápida, para a Radeon X1600 XT da ATI, que foi 14,09% mais rápida, para a Radeon X800 GTO da HIS, que foi 13,70% mais rápida, para a Radeon X1600 XT da HIS, que foi 13,24% mais rápida e para a Radeon X700 Pro da Sapphire, que foi 7,00% mais rápida. Na configuração de 1280x1024 sem recursos de aumento de qualidade de imagem, a Radeon X1900 XTX da ATI foi 6,55% mais rápida do que a Radeon X700 Pro da Sapphire, 8,32% mais rápida do que a GeForce 6600 GT da XFX, 19,67% mais rápida do que a GeForce 6600 de 256 MB com overclock de fábrica da XFX, 46,89% mais rápida do que a GeForce 6600 da Albatron, 48,57% mais rápida do que a Radeon X600 XT da ATI e 76,84% mais rápida do que a Radeon X600 Pro da Sapphire. A Radeon X1900 XTX da ATI obteve desempenho semelhante ao da Radeon X1600 XT da ATI e da HIS. A Radeon X1900 XTX da ATI perdeu para as demais placas do teste: a Radeon X1800 XT da ATI foi 25,60% mais rápida, a Radeon X850 XT P.E. da ATI foi 24,59% mais rápida, a GeForce 7800 GTX da MSI foi 19,98% mais rápida, a Radeon X1800 XL da ATI foi 18,02% mais rápida, a GeForce 7800 GT da NVIDIA foi 16,21% mais rápida, a GeForce 6800 GT da NVIDIA foi 10,07% mais rápida, a GeForce 6800 GS da NVIDIA foi 9,30% mais rápida, a Radeon X800 GT da HIS foi 7,96% mais rápida e a Radeon X800 GTO da HIS foi 5,42% mais rápida do que a placa testada. Na configuração de 1600x1200 sem recursos de aumento de qualidade de imagem, a Radeon X1900 XTX da ATI foi 6,18% mais rápida do que a Radeon X800 GTO da HIS, 6,36% mais rápida do que a Radeon X800 GT da HIS, 13,83% mais rápida do que a Radeon X1600 XT da ATI, 15,72% mais rápida do que a Radeon X1600 XT da HIS, 20,37% mais rápida do que a GeForce 6600 GT da XFX, 29,37% mais rápida do que a Radeon X700 Pro da Sapphire, 38,08% mais rápida do que a GeForce 6600 de 256 MB com overclock de fábrica da XFX, 81,95% mais rápida do que a GeForce 6600 da Albatron, 102,77% mais rápida do que a Radeon X600 XT da ATI e 144,95% mais rápida do que a Radeon X600 Pro da Sapphire. A Radeon X1900 XTX da ATI obteve desempenho semelhante da GeForce 6800 GT da NVIDIA e da GeForce 6800 GS da NVIDIA. A Radeon X1900 XTX da ATI perdeu para a Radeon X1800 XT da ATI, que foi 21,25% mais rápida, para a Radeon X850 XT P.E. da ATI, que foi 17,59% mais rápida, para a GeForce 7800 GTX da MSI, que foi 15,20% mais rápida, para a Radeon X1800 XL da ATI, que foi 11,57% mais rápida e para a GeForce 7800 GT da NVIDIA, que foi 10,05% mais rápida. Na configuração de 1024x768 com recursos de aumento de qualidade de imagem, a Radeon X1900 XTX da ATI foi 3,48% mais rápida do que a Radeon X800 GT da HIS, 4,29% mais rápida do que a Radeon X1600 XT da HIS, 7,84% mais rápida do que a Radeon X700 Pro da Sapphire, 24,53% mais rápida do que a GeForce 6600 GT da XFX, 43,63% mais rápida do que a GeForce 6600 de 256 MB com overclock de fábrica da XFX, 74,72% mais rápida do que a Radeon X600 XT da ATI, 90,18% mais rápida do que a GeForce 6600 da Albatron e 106,81% mais rápida do que a Radeon X600 Pro da Sapphire. A Radeon X1900 XTX da ATI obteve desempenho semelhante ao das placas GeForce 6800 GS da NVIDIA, Radeon X1600 XT da ATI, Radeon X800 GTO da HIS e GeForce 6800 GT da NVIDIA. A placa testada perdeu para a Radeon X1800 XT da ATI, que foi 22,40% mais rápida, para a Radeon X850 XT P.E. da ATI, que foi 20,17% mais rápida, para a Radeon X1800 XL da ATI, que foi 15,85% mais rápida, para a GeForce 7800 GTX da MSI, que foi 13,13% mais rápida e para a GeForce 7800 GT da NVIDIA, que foi 7,99% mais rápida. Na configuração de 1280x1024 com recursos de aumento de qualidade de imagem, a Radeon X1900 XTX da ATI foi 6,21% mais rápida do que a GeForce 6800 GT da NVIDIA, 6,47% mais rápida do que a GeForce 6800 GS da NVIDIA, 16,07% mais rápida do que a Radeon X1600 XT da ATI, 17,58% mais rápida do que a Radeon X800 GT da HIS, 17,61% mais rápida do que a Radeon X800 GTO da HIS, 19,80% mais rápida do que a Radeon X1600 XT da HIS, 29,86% mais rápida do que a Radeon X700 Pro da Sapphire, 53,10% mais rápida do que a GeForce 6600 GT da XFX, 86,81% mais rápida do que a GeForce 6600 de 256 MB com overclock de fábrica da XFX, 132,19% mais rápida do que a Radeon X600 XT da ATI, 165,43% mais rápida do que a GeForce 6600 da Albatron e 178,99% mais rápida do que a Radeon X600 Pro da Sapphire. A Radeon X1900 XTX da ATI obteve desempenho semelhante ao da GeForce 7800 GT da NVIDIA. A placa testada perdeu para a Radeon X1800 XT da ATI, que foi 20,54% mais rápida, para a Radeon X850 XT P.E. da ATI, que foi 14,89% mais rápida, para a Radeon X1800 XL da ATI, que foi 12,29% mais rápida e para a GeForce 7800 GTX da MSI, que foi 6,63% mais rápida. Na configuração de 1600x1200 com recursos de aumento de qualidade de imagem, a Radeon X1900 XTX da ATI foi 9,13% mais rápida do que a GeForce 7800 GT da NVIDIA, 33,01% mais rápida do que a GeForce 6800 GT da NVIDIA, 34,91% mais rápida do que a GeForce 6800 GS da NVIDIA, 41,40% mais rápida do que a Radeon X800 GTO da HIS, 47,61% mais rápida do que a Radeon X800 GT da HIS, 66,41% mais rápida do que a Radeon X700 Pro da Sapphire, 86,67% mais rápida do que a Radeon X1600 XT da ATI, 93,48% mais rápida do que a Radeon X1600 XT da HIS, 137,67% mais rápida do que a GeForce 6600 GT da XFX, 201,59% mais rápida do que a GeForce 6600 de 256 MB com overclock de fábrica da XFX, 342,21% mais rápida do que a GeForce 6600 da Albatron, 390,92% mais rápida do que a Radeon X600 XT da ATI e 503,76% mais rápida do que a Radeon X600 Pro da Sapphire. A Radeon X1900 XTX da ATI obteve desempenho semelhante ao da GeForce 7800 GTX da MSI. A placa testada perdeu apenas para a Radeon X1800 XT da ATI, que foi 14,97% mais rápida, para a Radeon X850 XT P.E. da ATI, que foi 3,59% mais rápida e para a Radeon X1800 XL da ATI, que foi 3,04% mais rápida. O 3Dmark03 mede o desempenho simulando jogos escritos para o DirectX 9, que são os jogos contemporâneos. Rodamos o programa em três resoluções, 1024x768x32, 1280x1024x32 e 1600x1200x32, primeiro sem antialiasing e filtragem anisotrópica, e depois colocando o antialiasing em 4x e a filtragem anisotrópica também em 4x. Isso faz aumentar a qualidade da imagem, mas diminui o desempenho. Queríamos ver justamente o quanto de desempenho perdíamos quando colocamos a placa de vídeo para trabalhar com o máximo de qualidade possível. Importante notar que os chips da ATI permitem que o anti-aliasing seja configurado em até 6x. Como os chips da NVIDIA não permitem essa configuração, tivemos de manter a configuração de alta qualidade em 4x, de forma a adotarmos uma configuração que seja válida para todos os chips, fazendo com que a comparação seja válida. Na configuração 1024x768 sem recursos de aumento de qualidade de imagem, a Radeon X1900 XTX da ATI foi mais rápida do que todas as placas do teste. Ela foi 5,84% mais rápida do que a Radeon X1800 XT da ATI, 10,26% mais rápida do que a GeForce 7800 GTX da MSI, 20,23% mais rápida do que a GeForce 7800 GT da NVIDIA, 25,87% mais rápida do que a Radeon X1800 XL da ATI, 29,43% mais rápida do que a Radeon X850 XT P.E. da ATI, 46,60% mais rápida do que a GeForce 6800 GS da NVIDIA, 47,41% mais rápida do que a GeForce 6800 GT da NVIDIA, 73,00% mais rápida do que a Radeon X800 GTO da HIS, 76,90% mais rápida do que a Radeon X1600 XT da ATI, 81,05% mais rápida do que a Radeon X1600 XT da HIS, 81,13% mais rápida do que a Radeon X800 GT da HIS, 105,36% mais rápida do que a GeForce 6600 GT da XFX, 126,79% mais rápida do que a Radeon X700 Pro da Sapphire, 151,54% mais rápida do que a GeForce 6600 de 256 MB com overclock de fábrica da XFX, 241,32% mais rápida do que a GeForce 6600 da Albatron, 300,78% mais rápida do que a Radeon X600 XT da ATI e 377,05% mais rápida do que a Radeon X600 Pro da Sapphire. Na configuração 1280x1024 sem recursos de aumento de qualidade de imagem, a Radeon X1900 XTX da ATI mais uma vez foi mais rápida do que todas as placas do teste. Ela foi 6,46% mais rápida do que a Radeon X1800 XT da ATI, 13,47% mais rápida do que a GeForce 7800 GTX da MSI, 26,29% mais rápida do que a GeForce 7800 GT da NVIDIA, 30,15% mais rápida do que a Radeon X1800 XL da ATI, 34,65% mais rápida do que a Radeon X850 XT P.E. da ATI, 57,18% mais rápida do que a GeForce 6800 GT da NVIDIA, 58,11% mais rápida do que a GeForce 6800 GS da NVIDIA, 85,87% mais rápida do que a Radeon X800 GTO da HIS, 97,30% mais rápida do que a Radeon X800 GT da HIS, 100,03% mais rápida do que a Radeon X1600 XT da ATI, 105,17% mais rápida do que a Radeon X1600 XT da HIS, 129,90% mais rápida do que a GeForce 6600 GT da XFX, 159,54% mais rápida do que a Radeon X700 Pro da Sapphire, 184,24% mais rápida do que a GeForce 6600 de 256 MB com overclock de fábrica da XFX, 292,54% mais rápida do que a GeForce 6600 da Albatron, 364,48% mais rápida do que a Radeon X600 XT da ATI e 453,97% mais rápida do que a Radeon X600 Pro da Sapphire. Na configuração 1600x1200 sem recursos de aumento de qualidade de imagem, a Radeon X1900 XTX da ATI foi 8,64% mais rápida do que a Radeon X1800 XT da ATI, 15,34% mais rápida do que a GeForce 7800 GTX da MSI, 18,92% mais rápida do que a GeForce 7800 GT da NVIDIA, 33,59% mais rápida do que a Radeon X1800 XL da ATI, 38,87% mais rápida do que a Radeon X850 XT P.E. da ATI, 63,49% mais rápida do que a GeForce 6800 GT da NVIDIA, 66,03% mais rápida do que a GeForce 6800 GS da NVIDIA, 96,63% mais rápida do que a Radeon X800 GTO da HIS, 120,59% mais rápida do que a Radeon X1600 XT da ATI, 123,75% mais rápida do que a Radeon X800 GT da HIS, 126,01% mais rápida do que a Radeon X1600 XT da HIS, 151,72% mais rápida do que a GeForce 6600 GT da XFX, 196,60% mais rápida do que a Radeon X700 Pro da Sapphire, 212,89% mais rápida do que a GeForce 6600 de 256 MB com overclock de fábrica da XFX, 336,15% mais rápida do que a GeForce 6600 da Albatron, 448,10% mais rápida do que a Radeon X600 XT da ATI e 549,97% mais rápida do que a Radeon X600 Pro da Sapphire. Na configuração 1024x768 com recursos de aumento de qualidade de imagem, a Radeon X1900 XTX da ATI mais uma vez bateu todas as placas do teste. Ela foi 5,34% mais rápida do que a Radeon X1800 XT da ATI, 16,59% mais rápida do que a GeForce 7800 GTX da MSI, 24,14% mais rápida do que a Radeon X1800 XL da ATI, 28,64% mais rápida do que a GeForce 7800 GT da NVIDIA, 42,77% mais rápida do que a Radeon X850 XT P.E. da ATI, 67,31% mais rápida do que a GeForce 6800 GT da NVIDIA, 69,22% mais rápida do que a GeForce 6800 GS da NVIDIA, 112,91% mais rápida do que a Radeon X800 GTO da HIS, 132,54% mais rápida do que a Radeon X1600 XT da ATI, 141,42% mais rápida do que a Radeon X1600 XT da HIS, 146,67% mais rápida do que a Radeon X800 GT da HIS, 177,14% mais rápida do que a GeForce 6600 GT da XFX, 233,89% mais rápida do que a GeForce 6600 de 256 MB com overclock de fábrica da XFX, 239,37% mais rápida do que a Radeon X700 Pro da Sapphire, 386,80% mais rápida do que a GeForce 6600 da Albatron, 488,81% mais rápida do que a Radeon X600 XT da ATI e 591,52% mais rápida do que a Radeon X600 Pro da Sapphire. Na configuração 1280x1024 com recursos de aumento de qualidade de imagem, a Radeon X1900 XTX da ATI foi 4,61% mais rápida do que a Radeon X1800 XT da ATI, 22,42% mais rápida do que a GeForce 7800 GTX da MSI, 30,60% mais rápida do que a Radeon X1800 XL da ATI, 38,39% mais rápida do que a GeForce 7800 GT da NVIDIA, 50,80% mais rápida do que a Radeon X850 XT P.E. da ATI, 83,04% mais rápida do que a GeForce 6800 GT da NVIDIA, 88,40% mais rápida do que a GeForce 6800 GS da NVIDIA, 138,94% mais rápida do que a Radeon X800 GTO da HIS, 152,66% mais rápida do que a Radeon X1600 XT da ATI, 161,59% mais rápida do que a Radeon X1600 XT da HIS, 172,43% mais rápida do que a Radeon X800 GT da HIS, 271,69% mais rápida do que a GeForce 6600 GT da XFX, 285,78% mais rápida do que a Radeon X700 Pro da Sapphire, 286,25% mais rápida do que a GeForce 6600 de 256 MB com overclock de fábrica da XFX, 532,40% mais rápida do que a GeForce 6600 da Albatron, 600,74% mais rápida do que a Radeon X600 XT da ATI e 681,11% mais rápida do que a Radeon X600 Pro da Sapphire. Na configuração 1600x1200 com recursos de aumento de qualidade de imagem, a Radeon X1900 XTX da ATI foi 6,63% mais rápida do que a Radeon X1800 XT da ATI, 27,72% mais rápida do que a GeForce 7800 GTX da MSI, 33,70% mais rápida do que a GeForce 7800 GT da NVIDIA, 35,22% mais rápida do que a Radeon X1800 XL da ATI, 56,29% mais rápida do que a Radeon X850 XT P.E. da ATI, 95,42% mais rápida do que a GeForce 6800 GT da NVIDIA, 103,37% mais rápida do que a GeForce 6800 GS da NVIDIA, 154,03% mais rápida do que a Radeon X800 GTO da HIS, 195,63% mais rápida do que a Radeon X1600 XT da ATI, 206,36% mais rápida do que a Radeon X800 GT da HIS, 206,84% mais rápida do que a Radeon X1600 XT da HIS, 329,07% mais rápida do que a GeForce 6600 de 256 MB com overclock de fábrica da XFX, 335,01% mais rápida do que a Radeon X700 Pro da Sapphire, 357,31% mais rápida do que a GeForce 6600 GT da XFX, 664,56% mais rápida do que a GeForce 6600 da Albatron, 972,68% mais rápida do que a Radeon X600 XT da ATI e 1.047,95% mais rápida do que a Radeon X600 Pro da Sapphire. O 3Dmark05 mede o desempenho simulando jogos escritos para o DirectX 9.0c, ou seja, usando o modelo Shader 3.0. Este modelo de programação é usado pelo jogo Far Cry e por jogos que serão lançados em 2005. Atualmente somente os chips da NVIDIA das série 6 e 7 são Shader 3.0. Os chips concorrentes da ATI continuam sendo Shader 2.0. Rodamos o programa em três resoluções, 1024x768x32, 1280x1024x32 e 1600x1200x32, primeiro sem antialiasing e filtragem anisotrópica, e depois colocando o antialiasing em 4x e a filtragem anisotrópica também em 4x. Isso faz aumentar a qualidade da imagem, mas diminui o desempenho. Queríamos ver justamente o quanto de desempenho perdíamos quando colocamos a placa de vídeo para trabalhar com o máximo de qualidade possível. Importante notar que os chips da ATI permitem que o anti-aliasing seja configurado em até 6x. Como os chips da NVIDIA não permitem essa configuração, tivemos de manter a configuração de alta qualidade em 4x, de forma a adotarmos uma configuração que seja válida para todos os chips, fazendo com que a comparação seja válida. Na configuração 1024x768 sem recursos de aumento de qualidade de imagem, a Radeon X1900 XTX da ATI foi 7,90% mais rápida do que a Radeon X1800 XL da ATI, 10,07% mais rápida do que a GeForce 7800 GT da NVIDIA, 21,81% mais rápida do que a Radeon X850 XT P.E. da ATI, 39,89% mais rápida do que a Radeon X1600 XT da ATI, 41,31% mais rápida do que a GeForce 6800 GS da NVIDIA, 42,29% mais rápida do que a Radeon X1600 XT da HIS, 53,89% mais rápida do que a GeForce 6800 GT da NVIDIA, 62,33% mais rápida do que a Radeon X800 GTO da HIS, 74,86% mais rápida do que a Radeon X800 GT da HIS, 141,93% mais rápida do que a Radeon X700 Pro da Sapphire, 143,11% mais rápida do que a GeForce 6600 GT da XFX, 165,48% mais rápida do que a GeForce 6600 de 256 MB com overclock de fábrica da XFX, 310,46% mais rápida do que a GeForce 6600 da Albatron, 387,23% mais rápida do que a Radeon X600 XT da ATI e 411,50% mais rápida do que a Radeon X600 Pro da Sapphire, A placa testada obteve desempenho semelhante ao da GeForce 7800 GTX da MSI e perdeu para a Radeon X1800 XT da ATI, que foi 3,44% mais rápida. Na configuração 1280x1024 sem recursos de aumento de qualidade de imagem, a Radeon X1900 XTX da ATI obteve desempenho similar ao da Radeon X1800 XT da ATI e foi 10,42% mais rápida do que a GeForce 7800 GTX da MSI, 20,62% mais rápida do que a Radeon X1800 XL da ATI, 21,71% mais rápida do que a GeForce 7800 GT da NVIDIA, 41,33% mais rápida do que a Radeon X850 XT P.E. da ATI, 62,20% mais rápida do que a GeForce 6800 GS da NVIDIA, 63,99% mais rápida do que a Radeon X1600 XT da ATI, 66,56% mais rápida do que a Radeon X1600 XT da HIS, 78,88% mais rápida do que a GeForce 6800 GT da NVIDIA, 92,56% mais rápida do que a Radeon X800 GTO da HIS, 109,87% mais rápida do que a Radeon X800 GT da HIS, 197,34% mais rápida do que a Radeon X700 Pro da Sapphire, 218,85% mais rápida do que a GeForce 6600 de 256 MB com overclock de fábrica da XFX, 242,31% mais rápida do que a GeForce 6600 GT da XFX, 432,09% mais rápida do que a GeForce 6600 da Albatron, 544,13% mais rápida do que a Radeon X600 Pro da Sapphire e 575,30% mais rápida do que a Radeon X600 XT da ATI. Na configuração 1600x1200 sem recursos de aumento de qualidade de imagem, a Radeon X1900 XTX da ATI foi mais rápida do que todas as placas do teste. Ela foi 11,11% mais rápida do que a Radeon X1800 XT da ATI, 21,26% mais rápida do que a GeForce 7800 GTX da MSI, 36,08% mais rápida do que a GeForce 7800 GT da NVIDIA, 36,11% mais rápida do que a Radeon X1800 XL da ATI, 65,68% mais rápida do que a Radeon X850 XT P.E. da ATI, 88,51% mais rápida do que a GeForce 6800 GS da NVIDIA, 92,92% mais rápida do que a Radeon X1600 XT da ATI, 96,12% mais rápida do que a Radeon X1600 XT da HIS, 110,71% mais rápida do que a GeForce 6800 GT da NVIDIA, 128,05% mais rápida do que a Radeon X800 GTO da HIS, 168,02% mais rápida do que a Radeon X800 GT da HIS, 264,06% mais rápida do que a Radeon X700 Pro da Sapphire, 273,02% mais rápida do que a GeForce 6600 de 256 MB com overclock de fábrica da XFX, 415,27% mais rápida do que a GeForce 6600 GT da XFX, 589,94% mais rápida do que a GeForce 6600 da Albatron, 700,12% mais rápida do que a Radeon X600 Pro da Sapphire e 819,92% mais rápida do que a Radeon X600 XT da ATI. Na configuração 1280x1024 com recursos de aumento de qualidade de imagem, a Radeon X1900 XTX da ATI obteve desempenho semelhante ao da Radeon X1800 XT da ATI e foi 10,99% mais rápida do que a GeForce 7800 GTX da MSI, 14,35% mais rápida do que a Radeon X1800 XL da ATI, 20,83% mais rápida do que a GeForce 7800 GT da NVIDIA, 35,12% mais rápida do que a Radeon X850 XT P.E. da ATI, 63,51% mais rápida do que a GeForce 6800 GS da NVIDIA, 64,96% mais rápida do que a Radeon X1600 XT da ATI, 69,19% mais rápida do que a Radeon X1600 XT da HIS, 81,54% mais rápida do que a GeForce 6800 GT da NVIDIA, 83,78% mais rápida do que a Radeon X800 GTO da HIS, 90,66% mais rápida do que a Radeon X800 GT da HIS, 200,94% mais rápida do que a Radeon X700 Pro da Sapphire, 227,02% mais rápida do que a GeForce 6600 de 256 MB com overclock de fábrica da XFX, 421,91% mais rápida do que a GeForce 6600 GT da XFX, 547,11% mais rápida do que a Radeon X600 Pro da Sapphire, 618,40% mais rápida do que a GeForce 6600 da Albatron e 643,85% mais rápida do que a Radeon X600 XT da ATI. Para rodar na configuração 1280x1024 com recursos de aumento de qualidade de imagem no 3DMark05, a placa de vídeo deve ter pelo menos 256 MB de memória, e é por isso que algumas placas de vídeo não puderam rodar esse teste. Aqui, a Radeon X1900 XTX da ATI foi 8,79% mais rápida do que a Radeon X1800 XT da ATI, 26,71% mais rápida do que a GeForce 7800 GTX da MSI, 33,69% mais rápida do que a Radeon X1800 XL da ATI, 40,89% mais rápida do que a GeForce 7800 GT da NVIDIA, 63,13% mais rápida do que a Radeon X850 XT P.E. da ATI, 99,42% mais rápida do que a Radeon X1600 XT da ATI, 99,97% mais rápida do que a GeForce 6800 GS da NVIDIA, 104,39% mais rápida do que a Radeon X1600 XT da HIS, 121,32% mais rápida do que a GeForce 6800 GT da NVIDIA, 127,29% mais rápida do que a Radeon X800 GTO da HIS, 161,79% mais rápida do que a Radeon X800 GT da HIS, 281,59% mais rápida do que a Radeon X700 Pro da Sapphire, 308,39% mais rápida do que a GeForce 6600 de 256 MB com overclock de fábrica da XFX, 718,31% mais rápida do que a Radeon X600 Pro da Sapphire e 1.030,98% mais rápida do que a Radeon X600 XT da ATI. Para rodar na configuração 1600x1200 com recursos de aumento de qualidade de imagem no 3DMark05, a placa de vídeo deve ter pelo menos 256 MB de memória, e é por isso que algumas placas de vídeo não puderam rodar esse teste. Aqui, a Radeon X1900 XTX da ATI foi 18,25% mais rápida do que a Radeon X1800 XT da ATI, 48,70% mais rápida do que a Radeon X1800 XL da ATI, 50,02% mais rápida do que a GeForce 7800 GTX da MSI, 66,92% mais rápida do que a GeForce 7800 GT da NVIDIA, 88,06% mais rápida do que a Radeon X850 XT P.E. da ATI, 136,50% mais rápida do que a Radeon X1600 XT da ATI, 141,71% mais rápida do que a Radeon X1600 XT da HIS, 164,40% mais rápida do que a Radeon X800 GTO da HIS, 179,78% mais rápida do que a GeForce 6800 GS da NVIDIA, 180,03% mais rápida do que a GeForce 6800 GT da NVIDIA, 221,00% mais rápida do que a Radeon X800 GT da HIS, 355,09% mais rápida do que a Radeon X700 Pro da Sapphire, 396,66% mais rápida do que a GeForce 6600 de 256 MB com overclock de fábrica da XFX, 961,63% mais rápida do que a Radeon X600 Pro da Sapphire e 1.733,72% mais rápida do que a Radeon X600 XT da ATI. O Doom 3 é um dos jogos mais pesados existentes atualmente. Assim como nos fizemos nos demais programas, rodamos este jogo em três resoluções, 1024x768x32, 1280x1024x32 e 1600x1200x32. Este jogo permite vários níveis de qualidade de imagem, e fizemos nossos testes em dois níveis, low e high. Rodamos o demo1 quatro vezes e anotamos a quantidade de quadros por segundo obtida. O primeiro resultado nós descartamos de cara, pois ele é bem inferior ao das demais rodadas. Isso ocorre porque na primeira vez em que rodamos o demo o jogo tem que carregar as texturas para a memória de vídeo da placa testada, coisa que não ocorre da segunda vez em diante em que o mesmo demo é rodado. Dos três resultados que sobraram, aproveitamos o resultado com valor intermediário, isto é, descartamos o maior e o menor valor. Interessante notar que na maioria das vezes os valores obtidos pela segunda rodada em diante eram os mesmos. Um detalhe importante que não podemos deixar de comentar é que o Doom 3 possui uma trava interna da quantidade de quadros por segundo que ele é capaz de gerar durante uma sessão normal de jogo: ele só gera 60 quadros por segundo, mesmo que sua placa possa gerar mais. Isso foi feito justamente para o jogo ter uma mesma sensação de "jogabilidade" independentemente da placa de vídeo instalada. Esta trava, entretanto, não atua no modo de medida de desempenho do jogo. Para mais detalhes de como efetuar testes de desempenho 3D com o Doom 3, leia o nosso tutorial sobre o assunto. Na configuração 1024x768 sem recursos de aumento de qualidade de imagem, a Radeon X1900 XTX da ATI foi 5,80% mais rápida do que a GeForce 6800 GS da NVIDIA, 14,44% mais rápida do que a Radeon X850 XT P.E. da ATI, 16,93% mais rápida do que a GeForce 6800 GT da NVIDIA, 25,42% mais rápida do que a Radeon X800 GTO da HIS, 27,40% mais rápida do que a GeForce 6600 GT da XFX, 38,74% mais rápida do que a Radeon X800 GT da HIS, 40,96% mais rápida do que a GeForce 6600 de 256 MB com overclock de fábrica da XFX, 45,20% mais rápida do que a Radeon X1600 XT da ATI, 46,29% mais rápida do que a Radeon X1600 XT da HIS, 73,92% mais rápida do que a Radeon X700 Pro da Sapphire, 78,74% mais rápida do que a GeForce 6600 da Albatron, 212,94% mais rápida do que a Radeon X600 XT da ATI e 283,73% mais rápida do que a Radeon X600 Pro da Sapphire. A Radeon X1900 XTX da ATI apresentou desempenho semelhante ao das placas Radeon X1800 XT da ATI, GeForce 7800 GTX da MSI, Radeon X1800 XL da ATI e GeForce 7800 GT da NVIDIA. Na configuração 1280x1024 sem recursos de aumento de qualidade de imagem, a Radeon X1900 XTX da ATI foi 3,87% mais rápida do que a GeForce 7800 GTX da MSI, 7,31% mais rápida do que a GeForce 7800 GT da NVIDIA, 16,21% mais rápida do que a Radeon X1800 XL da ATI, 21,16% mais rápida do que a GeForce 6800 GS da NVIDIA, 22,58% mais rápida do que a Radeon X850 XT P.E. da ATI, 23,88% mais rápida do que a GeForce 6800 GT da NVIDIA, 56,76% mais rápida do que a GeForce 6600 GT da XFX, 70,42% mais rápida do que a Radeon X800 GTO da HIS, 86,68% mais rápida do que a GeForce 6600 de 256 MB com overclock de fábrica da XFX, 100,64% mais rápida do que a Radeon X800 GT da HIS, 110,07% mais rápida do que a Radeon X1600 XT da ATI, 111,96% mais rápida do que a Radeon X1600 XT da HIS, 151,74% mais rápida do que a Radeon X700 Pro da Sapphire, 156,56% mais rápida do que a GeForce 6600 da Albatron, 379,08% mais rápida do que a Radeon X600 XT da ATI e 486,88% mais rápida do que a Radeon X600 Pro da Sapphire. A Radeon X1900 XTX da ATI obteve desempenho semelhante ao da Radeon X1800 XT da ATI. Na configuração 1600x1200 sem recursos de aumento de qualidade de imagem, a Radeon X1900 XTX da ATI foi mais rápida do que todas as placas do teste, sendo 7,18% mais rápida do que a GeForce 7800 GTX da MSI, 11,74% mais rápida do que a Radeon X1800 XT da ATI, 13,65% mais rápida do que a GeForce 7800 GT da NVIDIA, 34,47% mais rápida do que a GeForce 6800 GT da NVIDIA, 36,59% mais rápida do que a GeForce 6800 GS da NVIDIA, 37,24% mais rápida do que a Radeon X1800 XL da ATI, 38,78% mais rápida do que a Radeon X850 XT P.E. da ATI, 88,67% mais rápida do que a GeForce 6600 GT da XFX, 122,62% mais rápida do que a Radeon X800 GTO da HIS, 135,33% mais rápida do que a GeForce 6600 de 256 MB com overclock de fábrica da XFX, 173,19% mais rápida do que a Radeon X1600 XT da ATI, 174,92% mais rápida do que a Radeon X800 GT da HIS, 176,68% mais rápida do que a Radeon X1600 XT da HIS, 226,79% mais rápida do que a GeForce 6600 da Albatron, 239,61% mais rápida do que a Radeon X700 Pro da Sapphire, 561,07% mais rápida do que a Radeon X600 XT da ATI e 716,98% mais rápida do que a Radeon X600 Pro da Sapphire. Na configuração 1024x768 com recursos de aumento de qualidade de imagem, a Radeon X1900 XTX da ATI foi 3,38% mais rápida do que a GeForce 6800 GS da NVIDIA, 9,81% mais rápida do que a Radeon X850 XT P.E. da ATI, 12,36% mais rápida do que a GeForce 6800 GT da NVIDIA, 24,39% mais rápida do que a Radeon X800 GTO da HIS, 29,66% mais rápida do que a GeForce 6600 GT da XFX, 40,15% mais rápida do que a Radeon X800 GT da HIS, 40,37% mais rápida do que a GeForce 6600 de 256 MB com overclock de fábrica da XFX, 50,49% mais rápida do que a Radeon X1600 XT da ATI, 51,99% mais rápida do que a Radeon X1600 XT da HIS, 82,14% mais rápida do que a Radeon X700 Pro da Sapphire, 88,50% mais rápida do que a GeForce 6600 da Albatron, 230,22% mais rápida do que a Radeon X600 XT da ATI e 300,87% mais rápida do que a Radeon X600 Pro da Sapphire. A placa testada obteve desempenho semelhante ao das placas GeForce 7800 GT da NVIDIA, GeForce 7800 GTX da MSI e Radeon X1800 XL da ATI. A Radeon X1900 XTX da ATI perdeu apenas para a Radeon X1800 XT da ATI, que foi 3,81% mais rápida. Na configuração 1280x1024 com recursos de aumento de qualidade de imagem, a Radeon X1900 XTX da ATI foi mais rápida do que todas as placas do teste, sendo 5,10% mais rápida do que a Radeon X1800 XT da ATI, 6,88% mais rápida do que a GeForce 7800 GTX da MSI, 9,34% mais rápida do que a GeForce 7800 GT da NVIDIA, 21,23% mais rápida do que a Radeon X1800 XL da ATI, 27,42% mais rápida do que a Radeon X850 XT P.E. da ATI, 28,28% mais rápida do que a GeForce 6800 GS da NVIDIA, 30,94% mais rápida do que a GeForce 6800 GT da NVIDIA, 70,81% mais rápida do que a GeForce 6600 GT da XFX, 80,23% mais rápida do que a Radeon X800 GTO da HIS, 99,16% mais rápida do que a GeForce 6600 de 256 MB com overclock de fábrica da XFX, 113,51% mais rápida do que a Radeon X800 GT da HIS, 127,34% mais rápida do que a Radeon X1600 XT da ATI, 130,10% mais rápida do que a Radeon X1600 XT da HIS, 175,58% mais rápida do que a Radeon X700 Pro da Sapphire, 183,83% mais rápida do que a GeForce 6600 da Albatron, 415,22% mais rápida do que a Radeon X600 XT da ATI e 532,00% mais rápida do que a Radeon X600 Pro da Sapphire. Na configuração 1600x1200 com recursos de aumento de qualidade de imagem, a Radeon X1900 XTX da ATI também foi mais rápida do que todas as placas do teste, sendo 10,64% mais rápida do que a GeForce 7800 GTX da MSI, 16,62% mais rápida do que a Radeon X1800 XT da ATI, 17,55% mais rápida do que a GeForce 7800 GT da NVIDIA, 43,97% mais rápida do que a Radeon X1800 XL da ATI, 44,68% mais rápida do que a GeForce 6800 GT da NVIDIA, 45,87% mais rápida do que a GeForce 6800 GS da NVIDIA, 46,60% mais rápida do que a Radeon X850 XT P.E. da ATI, 103,69% mais rápida do que a GeForce 6600 GT da XFX, 134,48% mais rápida do que a Radeon X800 GTO da HIS, 150,42% mais rápida do que a GeForce 6600 de 256 MB com overclock de fábrica da XFX, 189,84% mais rápida do que a Radeon X800 GT da HIS, 190,79% mais rápida do que a Radeon X1600 XT da ATI, 194,67% mais rápida do que a Radeon X1600 XT da HIS, 253,60% mais rápida do que a GeForce 6600 da Albatron, 266,80% mais rápida do que a Radeon X700 Pro da Sapphire, 662,07% mais rápida do que a Radeon X600 XT da ATI e 758,25% mais rápida do que a Radeon X600 Pro da Sapphire. O Far Cry é um jogo baseado no modelo Shader 3.0 (DirectX 9.0c), modelo de programação presente nos chips das séries 6 e 7 da NVIDIA e nos chips da série X1000 da ATI. Assim como nos fizemos nos demais programas, rodamos este jogo em três resoluções, 1024x768x32, 1280x1024x32 e 1600x1200x32. Este jogo permite vários níveis de qualidade de imagem, e fizemos nossos testes em dois níveis, low e very high. Para efetuarmos a medida de desempenho usamos o demo criado pela revista alemã PC Games Hardware (PCGH), disponível em http://www.3dcenter.org/downloads/farcry-pcgh-vga.php. Rodamos este demo quatro vezes e fizemos uma média aritmética, sendo esta média o resultado que apresentamos. Este jogo tem um detalhe importantíssimo em sua configuração de qualidade de imagem. O anti-aliasing, em vez de ser configurado numericamente (1x, 2x, 4x ou 6x) é configurado como low, medium ou high. O problema é que em chips da NVIDIA, tanto medium quanto high significa 4x, enquanto que em chips da ATI medium significa 2x e high significa 6x, tornando a comparação entre chips da ATI e da NVIDIA injusta. Por este motivo nós configuramos o antialiasing em 4x e a filtragem anisotrópica em 8x manualmente através do painel de controle do driver. Para mais detalhes de como efetuar testes de desempenho 3D com o Far Cry, leia o nosso tutorial sobre o assunto. Na configuração 1024x768 sem recursos de aumento de qualidade de imagem, a Radeon X1900 XTX da ATI foi 5,37% mais rápida do que a GeForce 7800 GTX da MSI, 6,73% mais rápida do que a GeForce 7800 GT da NVIDIA, 6,74% mais rápida do que a GeForce 6800 GS da NVIDIA, 8,48% mais rápida do que a Radeon X600 XT da ATI, 9,45% mais rápida do que a GeForce 6600 de 256 MB com overclock de fábrica da XFX, 10,42% mais rápida do que a GeForce 6600 GT da XFX, 16,52% mais rápida do que a GeForce 6600 da Albatron, 19,46% mais rápida do que a GeForce 6800 GT da NVIDIA e 28,00% mais rápida do que a Radeon X600 Pro da Sapphire. A Radeon X1900 XTX da ATI apresentou desempenho semelhante ao das seguintes placas: Radeon X800 GT da HIS, Radeon X850 XT P.E. da ATI, Radeon X800 GTO da HIS, Radeon X1800 XT da ATI, Radeon X1600 XT da HIS, Radeon X700 Pro da Sapphire, Radeon X1800 XL da ATI e Radeon X1600 XT da ATI. Na configuração 1280x1024 sem recursos de aumento de qualidade de imagem, a Radeon X1900 XTX da ATI foi 11,22% mais rápida do que a GeForce 6600 de 256 MB com overclock de fábrica da XFX, 46,96% mais rápida do que a Radeon X600 XT da ATI, 49,19% mais rápida do que a GeForce 6600 da Albatron e 79,59% mais rápida do que a Radeon X600 Pro da Sapphire. A placa testada apresentou desempenho semelhante ao das seguintes placas: GeForce 7800 GTX da MSI, GeForce 6800 GS da NVIDIA, GeForce 7800 GT da NVIDIA, GeForce 6800 GT da NVIDIA e GeForce 6600 GT da XFX. A Radeon X1900 XTX da ATI perdeu para as demais placas do teste: a Radeon X850 XT P.E. da ATI foi 9,28% mais rápida, a Radeon X800 GT da HIS foi 9,12% mais rápida, a Radeon X800 GTO da HIS foi 8,69% mais rápida, a Radeon X1800 XL da ATI foi 8,17% mais rápida, a Radeon X1800 XT da ATI foi 7,39% mais rápida, a Radeon X1600 XT da ATI foi 7,22% mais rápida, a Radeon X1600 XT da HIS foi 6,96% mais rápida e a Radeon X700 Pro da Sapphire foi 5,65% mais rápida. Na configuração 1600x1200 sem recursos de aumento de qualidade de imagem, a Radeon X1900 XTX da ATI foi 8,13% mais rápida do que a Radeon X1600 XT da ATI, 10,53% mais rápida do que a Radeon X1600 XT da HIS, 19,72% mais rápida do que a GeForce 6600 GT da XFX, 24,36% mais rápida do que a Radeon X700 Pro da Sapphire, 47,01% mais rápida do que a GeForce 6600 de 256 MB com overclock de fábrica da XFX, 106,49% mais rápida do que a GeForce 6600 da Albatron, 118,74% mais rápida do que a Radeon X600 XT da ATI e 167,86% mais rápida do que a Radeon X600 Pro da Sapphire. A placa testada apresentou desempenho semelhante ao das seguintes placas: GeForce 7800 GTX da MSI, GeForce 7800 GT da NVIDIA, GeForce 6800 GS da NVIDIA, Radeon X800 GT da HIS e GeForce 6800 GT da NVIDIA. A Radeon X1900 XTX da ATI perdeu para a Radeon X850 XT P.E. da ATI, que foi 9,74% mais rápida, para a Radeon X1800 XT da ATI, que foi 8,75% mais rápida, para a Radeon X1800 XL da ATI, que foi 8,38% mais rápida e para a Radeon X800 GTO da HIS, que foi 6,45% mais rápida do que a placa testada. Na configuração 1024x768 com recursos de aumento de qualidade de imagem, a Radeon X1900 XTX da ATI foi 10,07% mais rápida do que a Radeon X800 GTO da HIS, 26,60% mais rápida do que a Radeon X800 GT da HIS, 44,85% mais rápida do que a Radeon X1600 XT da ATI, 47,50% mais rápida do que a Radeon X1600 XT da HIS, 70,43% mais rápida do que a Radeon X700 Pro da Sapphire, 81,30% mais rápida do que a GeForce 6600 GT da XFX, 86,71% mais rápida do que a GeForce 6600 de 256 MB com overclock de fábrica da XFX, 193,20% mais rápida do que a GeForce 6600 da Albatron, 240,03% mais rápida do que a Radeon X600 Pro da Sapphire e 270,33% mais rápida do que a Radeon X600 XT da ATI. A placa testada apresentou desempenho semelhante ao da GeForce 6800 GS da NVIDIA e da GeForce 6800 GT da NVIDIA. A Radeon X1900 XTX da ATI perdeu para a Radeon X850 XT P.E. da ATI, que foi 10,39% mais rápida, para a Radeon X1800 XL da ATI, que foi 10,30% mais rápida, para a Radeon X1800 XT da ATI, que foi 9,77% mais rápida, para a GeForce 7800 GT da NVIDIA, que foi 9,25% mais rápida e para a GeForce 7800 GTX da MSI, que foi 8,62% mais rápida do que a placa testada. Na configuração 1280x1024 com recursos de aumento de qualidade de imagem, a Radeon X1900 XTX da ATI foi 27,47% mais rápida do que a GeForce 6800 GS da NVIDIA, 33,11% mais rápida do que a GeForce 6800 GT da NVIDIA, 49,76% mais rápida do que a Radeon X800 GTO da HIS, 78,48% mais rápida do que a Radeon X800 GT da HIS, 92,72% mais rápida do que a Radeon X1600 XT da ATI, 102,27% mais rápida do que a Radeon X1600 XT da HIS, 143,23% mais rápida do que a Radeon X700 Pro da Sapphire, 165,65% mais rápida do que a GeForce 6600 GT da XFX, 177,47% mais rápida do que a GeForce 6600 de 256 MB com overclock de fábrica da XFX, 355,14% mais rápida do que a GeForce 6600 da Albatron, 384,73% mais rápida do que a Radeon X600 Pro da Sapphire e 403,60% mais rápida do que a Radeon X600 XT da ATI. A placa testada apresentou desempenho semelhante ao da Radeon X1800 XL da ATI, Radeon X850 XT P.E. da ATI e GeForce 7800 GT da NVIDIA. A Radeon X1900 XTX da ATI perdeu para a Radeon X1800 XT da ATI, que foi 9,75% mais rápida e para a GeForce 7800 GTX da MSI, que foi 3,70% mais rápida. Na configuração 1600x1200 com recursos de aumento de qualidade de imagem, a Radeon X1900 XTX da ATI foi 15,60% mais rápida do que a Radeon X1800 XL da ATI, 18,11% mais rápida do que a GeForce 7800 GTX da MSI, 26,54% mais rápida do que a Radeon X850 XT P.E. da ATI, 31,08% mais rápida do que a GeForce 7800 GT da NVIDIA, 71,85% mais rápida do que a GeForce 6800 GS da NVIDIA, 100,12% mais rápida do que a GeForce 6800 GT da NVIDIA, 101,47% mais rápida do que a Radeon X800 GTO da HIS, 147,37% mais rápida do que a Radeon X800 GT da HIS, 179,97% mais rápida do que a Radeon X1600 XT da ATI, 185,68% mais rápida do que a Radeon X1600 XT da HIS, 242,93% mais rápida do que a Radeon X700 Pro da Sapphire, 251,36% mais rápida do que a GeForce 6600 GT da XFX, 298,03% mais rápida do que a GeForce 6600 de 256 MB com overclock de fábrica da XFX, 508,33% mais rápida do que a GeForce 6600 da Albatron, 753,48% mais rápida do que a Radeon X600 Pro da Sapphire e 878,89% mais rápida do que a Radeon X600 XT da ATI. A Radeon X1900 XTX da ATI perdeu apenas para a Radeon X1800 XT da ATI, que foi 4,75% mais rápida. De acordo com os resultados obtidos, podemos dizer que o Radeon X1900 XTX parece estar otimizado para jogos DirectX 9.0 e 9.0c rodando em resoluções muito altas, com ajuste de qualidade de imagem habilitado. No 3DMark2001SE, que simula jogos DirectX 8.1, ele obteve desempenho ruim, portanto este parece não ser o produto ideal para jogos mais antigos. Mas no 3DMark03 e no 3DMark05, que simulam jogos DirectX 9.0 e 9.0c, respectivamente, a placa foi mais rápida que todas as outras placas de vídeo que testamos até hoje, incluindo a Radeon X1800 XT e a GeForce 7800 GTX. Tendo em mente que comparações entre o Radeon X1900 XTX e o Radeon X1800 XT em nossos testes não são definitivas, já que nossa GeForce 7800 GTX tinha 256 MB de memória de vídeo, ao passo que as amostras da ATI chegaram com 512 MB. No 3DMark03 (DirectX 9,0) o Radeon X1900 XTX foi entre 4,61% e 8,64% mais rápido que o Radeon X1800 XT e entre 10,26% e 27,72% mais rápido que o GeForce 7800 GTX, dependendo dos ajustes de resolução e qualidade de imagem. No 3DMark05 (DirectX 9.0c) os resultados variaram de acordo com a resolução usada. O Radeon X1900 XTX alcançou desempenho parecido com o do Radeon X1800 XT em 1280x1024 e 1024x768 com ajuste de qualidade de imagem habilitado, enquanto foi derrotado pelo Radeon X1800 XT em 1024x768. Nessa resolução ele atingiu desempenho parecido com o do GeForce 7800 GTX. Mas em outras resoluções e ajustes de qualidade de imagem, o Radeon X1900 XTX foi entre 8,79% e 18,25% mais rápido que o Radeon X1800 XT e entre 10,42% e 50,02% mais rápido que o GeForce 7800 GTX. Devemos mencionar que quanto maior a resolução, maior a diferença no desempenho. No Doom 3 o Radeon X1900 XTX obteve desempenho parecido com o do Radeon X1800 XT em 1024x768 e 1280x1024, e foi vencido por uma pequena margem pelo Radeon X1800 XT em 1024x768 com ajustes de qualidade de imagem habilitados (nesta resolução ele atingiu desempenho similar ao do GeForce 7800 GTX). Em outras resoluções e ajustes de qualidade de imagem, o Radeon X1900 XTX foi entre 5,10% e 16,62% mais rápido que o Radeon X1800 XT e entre 3,87% e 10,64% mais rápido que o GeForce 7800 GTX. Far Cry foi o calcanhar de Aquiles do Radeon X1900 XTX, como você pode ver na página anterior, o que é curioso, já que se trata de um jogo DirectX 9.0c. O único bom resultado nesse jogo foi em 1600x1200 com ajustes de qualidade de imagem no máximo, onde ele foi 18,11% mais rápido que o GeForce 7800 GTX. Uma falha em nosso teste foi que nós não testamos o desempenho em resoluções acima de 1600x1200, como 1920x1200, 2048x1536 e 2560x1600. Achamos que o Radeon X1900 XTX alcançaria desempenho ainda melhor nessas resoluções, já que os melhores resultados do Radeon X1900 XTX foram alcançados em 1600x1200. Com base nesses resultados, podemos afirmar que o Radeon X1900 XTX é destinado a jogadores “pesados” que rodam jogos DirectX 9.0 e acima em resolução de pelo menos 1600x1200 com todos os ajustes de qualidade de imagem no máximo. Se você não for rodar esse jogos com essas configurações, comprar uma Radeon X1900 XTX é sem propósito, já que você pode ter desempenho quase igual com produtos mais baratos. Em nossa opinião, pagar entre US$ 590 e US$ 650 nos EUA por uma placa de vídeo é loucura até pelos jogadores mais “barra-pesada”, já que existem placas de vídeo topo-de-linha no mercado que apresentam relação custo/benefício muito melhor (Radeon X1800 XT e GeForce 7800 GTX são boas opções se você tem dinheiro para comprá-las; Radeon X1800 XL e GeForce 7800 GT são ótimas soluções para quem não é louco o suficiente para pagar mais de US$ 400 [nos EUA] por uma placa de vídeo).
O Radeon X1900 XTX, antes conhecido como R580, é o novo chip topo de linha da ATI, substituindo o Radeon X1800 XT como o mais rápido processador de vídeo da ATI. Nós recebemos uma amostra de referência deste modelo da ATI, então vamos comparar seu desempenho com o de outros membros da série Radeon X1000, com o de chips anteriores da ATI, e também com produtos concorrentes da NVIDIA, especialmente o GeForce 7800 GTX. Figura 1: Placa de referência Radeon X1900 XTX. Nós publicamos um artigo completo explicando o que há de novo na série Radeon X1900, portanto não repetiremos aqui tudo o que já explicamos lá. A característica mais importante desse novo chip é que ele possui 48 processadores pixel shader, três vezes mais que o Radeon X1800 XT e duas vezes mais que o GeForce 7800 GTX. Até agora existem dois chips na família Radeon X1900: o Radeon X1900 XT, rodando a 550 MHz e acessando a memória a 1,45 GHz (taxa de transferência de 46,4 GB/s), e o Radeon X1900 XTX, rodando a 650 MHz e acessando a memória a 1,55 GHz (taxa de transferência de 49,6 GB/s). Ambos acessam suas memórias a uma taxa de 256 bits. Você pode ver em nosso tutorial “Tabela comparativa dos chips ATI” a diferença entre este novo chip e os outros chips da ATI, ao passo que em nosso tutorial “Tabela comparativa dos chips NVIDIA” você pode compará-lo com seus concorrentes fabricados pela NVIDIA. Você pode ver a placa de referência para o Radeon X1900 XTX nas Figuras 2 e 3. Figura 2: Placa de referência ATI Radeon X1900 XTX. Figura 3: Placa de referência ATI Radeon X1900 XTX vista de trás. Vamos agora dar uma olhada mais de perto na placa de referência para o Radeon X1900 XTX da ATI. Nós desmontamos o dissipador de calor da placa de vídeo para dar uma olhada, veja a Figura 4. Se você prestar atenção, vai notar que a base do dissipador de calor – a parte que encosta no chip gráfico – é feita de cobre. As aletas do dissipador de calor também são feitas de cobre. A ventoinha puxa o ar quente para fora do gabinete, ajudando bastante a reduzir a temperatura interna do PC. Porém, por causa desse mecanismo de exaustão, além do slot PCI Express 16x essa placa usa o slot imediatamente ao lado (normalmente um slot PCI Express x1). Figura 4: Dissipador de calor da placa de referência Radeon X1900 XTX. Figura 5: Placa de vídeo com seu dissipador de calor removido. Esta placa de vídeo usa oito chips de memória GDDR3 de 512 Mbits e 1,1 ns chips da Samsung (K4J52324QC-BJ11), totalizando seus 512 MB de memória de vídeo (512 Mbits x 8 = 512 MB). Estes chips podem rodar a até 1,8 GHz. Como esta placa de vídeo acessa a memória a 1,55 GHz, há 16% de espaço para um overclock de memória dentro das suas especificações. Mas é claro que você pode tentar um overclock além das especificações. Figura 6: Chip de memória GDDR3 de 1,1 ns usado pela placa de referência da ATI para o Radeon X1900 XTX. Esta placa de referência possui função de captura de vídeo (VIVO), usando o chip ATI Rage Theater. Figura 7: Chip ATI Rage Theater para captura de vídeo. Processador: Radeon X1900 XTX rodando a 650 MHz. Memória: 512 MB GDDR3 de 1,2 ns a 256 bits da Samsung (K4J52324QC-BJ12), rodando a 1,55 GHz. Conexão: PCI Express 16x. Conectores: Dois DVI e um mini-DIN para a saída S-Video. Número de CDs que acompanham a placa: Não se aplica. Jogos que acompanham a placa: Não se aplica. Programas que acompanham a placa: Não se aplica. Mais informações: http://www.ati.com Preço médio nos EUA*: US$ 620 (para o modelo de 512 MB, que foi o que testamos). * Pesquisado em Shopping.com no dia da publicação deste teste. Este preço é apenas uma referência para comparação com outras placas. O preço no Brasil será sempre maior, pois devemos adicionar o câmbio, o frete e os impostos, além da margem de lucro do distribuidor e do lojista. Em nossos testes de desempenho usamos a configuração listada abaixo. Entre as nossas sessões de teste o único dispositivo diferente era a placa que estava sendo testada. Configuração de Hardware Placa-mãe: DFI LAN Party 925X-T2 (Intel 925X, BIOS de 20 de setembro de 2004) Processador: Pentium 4 3,4 GHz LGA 775 Memória: Dois módulos DDR2-533 CM2X512-4200 CL4 Corsair de 512 MB cada Disco rígido: Maxtor DiamondMax 9 Plus (40 GB, ATA-133) Resolução de vídeo: 1024x768x32@85 Hz Configuração de Software Windows XP Professional, instalado em NTFS Service Pack 2 Direct X 9.0c Versão do driver inf da Intel: 6.0.1.1002 Versão do driver de vídeo ATI: 4.10 (6.14.10.6483) Versão do driver de vídeo ATI: 4.12 (Radeon X850 Platinum Edition) Versão do driver de vídeo ATI: 5.3 (Radeon X800 GT) Versão do driver de vídeo ATI: 5.9 (Radeon X800 GTO) Versão do driver de vídeo ATI: 6.1 (Radeon X1600 XT da HIS) Versão do driver de vídeo ATI: 8.173 beta (Radeon X1000 series) Versão do driver de vídeo ATI: 8.203.3.0 (Radeon X1900 XTX) Versão do driver de vídeo NVIDIA: 66.93 Versão do driver de vídeo NVIDIA: 77.72 (GeForce 7800 GTX) Versão do driver de vídeo NVIDIA: 78.02 (GeForce 7800 GT) Versão do driver de vídeo NVIDIA: 81.98 (GeForce 6800 GS) Programas Usados 3DMark2001 SE 3DMark03 Business 3.50 3DMark05 Business 1.10 Doom III Far Cry 1.3 Adotamos uma margem de erro de 3%. Com isso, diferenças de desempenho inferiores a 3% não podem ser consideradas significativas. Em outras palavras, produtos onde a diferença de desempenho seja inferior a 3% deverão ser considerados como tendo desempenhos similares. O 3Dmark2001 SE mede o desempenho simulando jogos baseados DirectX 8.1. Ele continua sendo um bom programa para avaliar o desempenho de jogos da geração passada, programados em DirectX 8. Neste programa nós executamos seis testes. Rodamos o programa em três resoluções, 1024x768x32, 1280x1024x32 e 1600x1200x32, primeiro sem antialiasing e sem frame buffer, e depois colocando o antialiasing em 4 samples e o frame buffer em triplo. Isso faz aumentar a qualidade da imagem, mas diminui o desempenho. Queríamos ver justamente o quanto de desempenho perdíamos quando colocamos a placa de vídeo para trabalhar com o máximo de qualidade possível. Importante notar que os chips da ATI permitem que o anti-aliasing seja configurado em até 6x. Como os chips da NVIDIA não permitem essa configuração, tivemos de manter a configuração de alta qualidade em 4x, de forma a adotarmos uma configuração que seja válida para todos os chips, fazendo com que a comparação seja válida. Você pode estar se perguntando o motivo de incluirmos um programa "obsoleto" entre os nossos testes de placas de vídeo de última geração. Para nós, tão importante quanto saber o desempenho das placas de vídeo com jogos mais modernos é saber o desempenho da placa quando um jogo mais antigo é executado. Por isto mantivemos este programa em nossa metodologia. Na configuração de 1024x768 sem recursos de aumento de qualidade de imagem, a Radeon X1900 XTX da ATI foi 6,60% mais rápida do que a GeForce 6600 de 256 MB com overclock de fábrica da XFX, 20,47% mais rápida do que a Radeon X600 XT da ATI, 23,21% mais rápida do que a GeForce 6600 da Albatron e 38,80% mais rápida do que a Radeon X600 Pro da Sapphire. A Radeon X1900 XTX da ATI obteve desempenho semelhante ao da GeForce 6600 GT da XFX. A placa testada perdeu para a Radeon X850 XT P.E. da ATI, que foi 32,12% mais rápida, para a Radeon X1800 XT da ATI, que foi 30,55% mais rápida, para a GeForce 7800 GTX da MSI, que foi 25,53% mais rápida, para a Radeon X1800 XL da ATI, que foi 23,40% mais rápida, para a GeForce 7800 GT da NVIDIA, que foi 20,85% mais rápida, para a Radeon X800 GT da HIS, que foi 16,58% mais rápida, para a GeForce 6800 GS da NVIDIA, que foi 15,35% mais rápida, para a GeForce 6800 GT da NVIDIA, que foi 15,28% mais rápida, para a Radeon X1600 XT da ATI, que foi 14,09% mais rápida, para a Radeon X800 GTO da HIS, que foi 13,70% mais rápida, para a Radeon X1600 XT da HIS, que foi 13,24% mais rápida e para a Radeon X700 Pro da Sapphire, que foi 7,00% mais rápida. Na configuração de 1280x1024 sem recursos de aumento de qualidade de imagem, a Radeon X1900 XTX da ATI foi 6,55% mais rápida do que a Radeon X700 Pro da Sapphire, 8,32% mais rápida do que a GeForce 6600 GT da XFX, 19,67% mais rápida do que a GeForce 6600 de 256 MB com overclock de fábrica da XFX, 46,89% mais rápida do que a GeForce 6600 da Albatron, 48,57% mais rápida do que a Radeon X600 XT da ATI e 76,84% mais rápida do que a Radeon X600 Pro da Sapphire. A Radeon X1900 XTX da ATI obteve desempenho semelhante ao da Radeon X1600 XT da ATI e da HIS. A Radeon X1900 XTX da ATI perdeu para as demais placas do teste: a Radeon X1800 XT da ATI foi 25,60% mais rápida, a Radeon X850 XT P.E. da ATI foi 24,59% mais rápida, a GeForce 7800 GTX da MSI foi 19,98% mais rápida, a Radeon X1800 XL da ATI foi 18,02% mais rápida, a GeForce 7800 GT da NVIDIA foi 16,21% mais rápida, a GeForce 6800 GT da NVIDIA foi 10,07% mais rápida, a GeForce 6800 GS da NVIDIA foi 9,30% mais rápida, a Radeon X800 GT da HIS foi 7,96% mais rápida e a Radeon X800 GTO da HIS foi 5,42% mais rápida do que a placa testada. Na configuração de 1600x1200 sem recursos de aumento de qualidade de imagem, a Radeon X1900 XTX da ATI foi 6,18% mais rápida do que a Radeon X800 GTO da HIS, 6,36% mais rápida do que a Radeon X800 GT da HIS, 13,83% mais rápida do que a Radeon X1600 XT da ATI, 15,72% mais rápida do que a Radeon X1600 XT da HIS, 20,37% mais rápida do que a GeForce 6600 GT da XFX, 29,37% mais rápida do que a Radeon X700 Pro da Sapphire, 38,08% mais rápida do que a GeForce 6600 de 256 MB com overclock de fábrica da XFX, 81,95% mais rápida do que a GeForce 6600 da Albatron, 102,77% mais rápida do que a Radeon X600 XT da ATI e 144,95% mais rápida do que a Radeon X600 Pro da Sapphire. A Radeon X1900 XTX da ATI obteve desempenho semelhante da GeForce 6800 GT da NVIDIA e da GeForce 6800 GS da NVIDIA. A Radeon X1900 XTX da ATI perdeu para a Radeon X1800 XT da ATI, que foi 21,25% mais rápida, para a Radeon X850 XT P.E. da ATI, que foi 17,59% mais rápida, para a GeForce 7800 GTX da MSI, que foi 15,20% mais rápida, para a Radeon X1800 XL da ATI, que foi 11,57% mais rápida e para a GeForce 7800 GT da NVIDIA, que foi 10,05% mais rápida. Na configuração de 1024x768 com recursos de aumento de qualidade de imagem, a Radeon X1900 XTX da ATI foi 3,48% mais rápida do que a Radeon X800 GT da HIS, 4,29% mais rápida do que a Radeon X1600 XT da HIS, 7,84% mais rápida do que a Radeon X700 Pro da Sapphire, 24,53% mais rápida do que a GeForce 6600 GT da XFX, 43,63% mais rápida do que a GeForce 6600 de 256 MB com overclock de fábrica da XFX, 74,72% mais rápida do que a Radeon X600 XT da ATI, 90,18% mais rápida do que a GeForce 6600 da Albatron e 106,81% mais rápida do que a Radeon X600 Pro da Sapphire. A Radeon X1900 XTX da ATI obteve desempenho semelhante ao das placas GeForce 6800 GS da NVIDIA, Radeon X1600 XT da ATI, Radeon X800 GTO da HIS e GeForce 6800 GT da NVIDIA. A placa testada perdeu para a Radeon X1800 XT da ATI, que foi 22,40% mais rápida, para a Radeon X850 XT P.E. da ATI, que foi 20,17% mais rápida, para a Radeon X1800 XL da ATI, que foi 15,85% mais rápida, para a GeForce 7800 GTX da MSI, que foi 13,13% mais rápida e para a GeForce 7800 GT da NVIDIA, que foi 7,99% mais rápida. Na configuração de 1280x1024 com recursos de aumento de qualidade de imagem, a Radeon X1900 XTX da ATI foi 6,21% mais rápida do que a GeForce 6800 GT da NVIDIA, 6,47% mais rápida do que a GeForce 6800 GS da NVIDIA, 16,07% mais rápida do que a Radeon X1600 XT da ATI, 17,58% mais rápida do que a Radeon X800 GT da HIS, 17,61% mais rápida do que a Radeon X800 GTO da HIS, 19,80% mais rápida do que a Radeon X1600 XT da HIS, 29,86% mais rápida do que a Radeon X700 Pro da Sapphire, 53,10% mais rápida do que a GeForce 6600 GT da XFX, 86,81% mais rápida do que a GeForce 6600 de 256 MB com overclock de fábrica da XFX, 132,19% mais rápida do que a Radeon X600 XT da ATI, 165,43% mais rápida do que a GeForce 6600 da Albatron e 178,99% mais rápida do que a Radeon X600 Pro da Sapphire. A Radeon X1900 XTX da ATI obteve desempenho semelhante ao da GeForce 7800 GT da NVIDIA. A placa testada perdeu para a Radeon X1800 XT da ATI, que foi 20,54% mais rápida, para a Radeon X850 XT P.E. da ATI, que foi 14,89% mais rápida, para a Radeon X1800 XL da ATI, que foi 12,29% mais rápida e para a GeForce 7800 GTX da MSI, que foi 6,63% mais rápida. Na configuração de 1600x1200 com recursos de aumento de qualidade de imagem, a Radeon X1900 XTX da ATI foi 9,13% mais rápida do que a GeForce 7800 GT da NVIDIA, 33,01% mais rápida do que a GeForce 6800 GT da NVIDIA, 34,91% mais rápida do que a GeForce 6800 GS da NVIDIA, 41,40% mais rápida do que a Radeon X800 GTO da HIS, 47,61% mais rápida do que a Radeon X800 GT da HIS, 66,41% mais rápida do que a Radeon X700 Pro da Sapphire, 86,67% mais rápida do que a Radeon X1600 XT da ATI, 93,48% mais rápida do que a Radeon X1600 XT da HIS, 137,67% mais rápida do que a GeForce 6600 GT da XFX, 201,59% mais rápida do que a GeForce 6600 de 256 MB com overclock de fábrica da XFX, 342,21% mais rápida do que a GeForce 6600 da Albatron, 390,92% mais rápida do que a Radeon X600 XT da ATI e 503,76% mais rápida do que a Radeon X600 Pro da Sapphire. A Radeon X1900 XTX da ATI obteve desempenho semelhante ao da GeForce 7800 GTX da MSI. A placa testada perdeu apenas para a Radeon X1800 XT da ATI, que foi 14,97% mais rápida, para a Radeon X850 XT P.E. da ATI, que foi 3,59% mais rápida e para a Radeon X1800 XL da ATI, que foi 3,04% mais rápida. O 3Dmark03 mede o desempenho simulando jogos escritos para o DirectX 9, que são os jogos contemporâneos. Rodamos o programa em três resoluções, 1024x768x32, 1280x1024x32 e 1600x1200x32, primeiro sem antialiasing e filtragem anisotrópica, e depois colocando o antialiasing em 4x e a filtragem anisotrópica também em 4x. Isso faz aumentar a qualidade da imagem, mas diminui o desempenho. Queríamos ver justamente o quanto de desempenho perdíamos quando colocamos a placa de vídeo para trabalhar com o máximo de qualidade possível. Importante notar que os chips da ATI permitem que o anti-aliasing seja configurado em até 6x. Como os chips da NVIDIA não permitem essa configuração, tivemos de manter a configuração de alta qualidade em 4x, de forma a adotarmos uma configuração que seja válida para todos os chips, fazendo com que a comparação seja válida. Na configuração 1024x768 sem recursos de aumento de qualidade de imagem, a Radeon X1900 XTX da ATI foi mais rápida do que todas as placas do teste. Ela foi 5,84% mais rápida do que a Radeon X1800 XT da ATI, 10,26% mais rápida do que a GeForce 7800 GTX da MSI, 20,23% mais rápida do que a GeForce 7800 GT da NVIDIA, 25,87% mais rápida do que a Radeon X1800 XL da ATI, 29,43% mais rápida do que a Radeon X850 XT P.E. da ATI, 46,60% mais rápida do que a GeForce 6800 GS da NVIDIA, 47,41% mais rápida do que a GeForce 6800 GT da NVIDIA, 73,00% mais rápida do que a Radeon X800 GTO da HIS, 76,90% mais rápida do que a Radeon X1600 XT da ATI, 81,05% mais rápida do que a Radeon X1600 XT da HIS, 81,13% mais rápida do que a Radeon X800 GT da HIS, 105,36% mais rápida do que a GeForce 6600 GT da XFX, 126,79% mais rápida do que a Radeon X700 Pro da Sapphire, 151,54% mais rápida do que a GeForce 6600 de 256 MB com overclock de fábrica da XFX, 241,32% mais rápida do que a GeForce 6600 da Albatron, 300,78% mais rápida do que a Radeon X600 XT da ATI e 377,05% mais rápida do que a Radeon X600 Pro da Sapphire. Na configuração 1280x1024 sem recursos de aumento de qualidade de imagem, a Radeon X1900 XTX da ATI mais uma vez foi mais rápida do que todas as placas do teste. Ela foi 6,46% mais rápida do que a Radeon X1800 XT da ATI, 13,47% mais rápida do que a GeForce 7800 GTX da MSI, 26,29% mais rápida do que a GeForce 7800 GT da NVIDIA, 30,15% mais rápida do que a Radeon X1800 XL da ATI, 34,65% mais rápida do que a Radeon X850 XT P.E. da ATI, 57,18% mais rápida do que a GeForce 6800 GT da NVIDIA, 58,11% mais rápida do que a GeForce 6800 GS da NVIDIA, 85,87% mais rápida do que a Radeon X800 GTO da HIS, 97,30% mais rápida do que a Radeon X800 GT da HIS, 100,03% mais rápida do que a Radeon X1600 XT da ATI, 105,17% mais rápida do que a Radeon X1600 XT da HIS, 129,90% mais rápida do que a GeForce 6600 GT da XFX, 159,54% mais rápida do que a Radeon X700 Pro da Sapphire, 184,24% mais rápida do que a GeForce 6600 de 256 MB com overclock de fábrica da XFX, 292,54% mais rápida do que a GeForce 6600 da Albatron, 364,48% mais rápida do que a Radeon X600 XT da ATI e 453,97% mais rápida do que a Radeon X600 Pro da Sapphire. Na configuração 1600x1200 sem recursos de aumento de qualidade de imagem, a Radeon X1900 XTX da ATI foi 8,64% mais rápida do que a Radeon X1800 XT da ATI, 15,34% mais rápida do que a GeForce 7800 GTX da MSI, 18,92% mais rápida do que a GeForce 7800 GT da NVIDIA, 33,59% mais rápida do que a Radeon X1800 XL da ATI, 38,87% mais rápida do que a Radeon X850 XT P.E. da ATI, 63,49% mais rápida do que a GeForce 6800 GT da NVIDIA, 66,03% mais rápida do que a GeForce 6800 GS da NVIDIA, 96,63% mais rápida do que a Radeon X800 GTO da HIS, 120,59% mais rápida do que a Radeon X1600 XT da ATI, 123,75% mais rápida do que a Radeon X800 GT da HIS, 126,01% mais rápida do que a Radeon X1600 XT da HIS, 151,72% mais rápida do que a GeForce 6600 GT da XFX, 196,60% mais rápida do que a Radeon X700 Pro da Sapphire, 212,89% mais rápida do que a GeForce 6600 de 256 MB com overclock de fábrica da XFX, 336,15% mais rápida do que a GeForce 6600 da Albatron, 448,10% mais rápida do que a Radeon X600 XT da ATI e 549,97% mais rápida do que a Radeon X600 Pro da Sapphire. Na configuração 1024x768 com recursos de aumento de qualidade de imagem, a Radeon X1900 XTX da ATI mais uma vez bateu todas as placas do teste. Ela foi 5,34% mais rápida do que a Radeon X1800 XT da ATI, 16,59% mais rápida do que a GeForce 7800 GTX da MSI, 24,14% mais rápida do que a Radeon X1800 XL da ATI, 28,64% mais rápida do que a GeForce 7800 GT da NVIDIA, 42,77% mais rápida do que a Radeon X850 XT P.E. da ATI, 67,31% mais rápida do que a GeForce 6800 GT da NVIDIA, 69,22% mais rápida do que a GeForce 6800 GS da NVIDIA, 112,91% mais rápida do que a Radeon X800 GTO da HIS, 132,54% mais rápida do que a Radeon X1600 XT da ATI, 141,42% mais rápida do que a Radeon X1600 XT da HIS, 146,67% mais rápida do que a Radeon X800 GT da HIS, 177,14% mais rápida do que a GeForce 6600 GT da XFX, 233,89% mais rápida do que a GeForce 6600 de 256 MB com overclock de fábrica da XFX, 239,37% mais rápida do que a Radeon X700 Pro da Sapphire, 386,80% mais rápida do que a GeForce 6600 da Albatron, 488,81% mais rápida do que a Radeon X600 XT da ATI e 591,52% mais rápida do que a Radeon X600 Pro da Sapphire. Na configuração 1280x1024 com recursos de aumento de qualidade de imagem, a Radeon X1900 XTX da ATI foi 4,61% mais rápida do que a Radeon X1800 XT da ATI, 22,42% mais rápida do que a GeForce 7800 GTX da MSI, 30,60% mais rápida do que a Radeon X1800 XL da ATI, 38,39% mais rápida do que a GeForce 7800 GT da NVIDIA, 50,80% mais rápida do que a Radeon X850 XT P.E. da ATI, 83,04% mais rápida do que a GeForce 6800 GT da NVIDIA, 88,40% mais rápida do que a GeForce 6800 GS da NVIDIA, 138,94% mais rápida do que a Radeon X800 GTO da HIS, 152,66% mais rápida do que a Radeon X1600 XT da ATI, 161,59% mais rápida do que a Radeon X1600 XT da HIS, 172,43% mais rápida do que a Radeon X800 GT da HIS, 271,69% mais rápida do que a GeForce 6600 GT da XFX, 285,78% mais rápida do que a Radeon X700 Pro da Sapphire, 286,25% mais rápida do que a GeForce 6600 de 256 MB com overclock de fábrica da XFX, 532,40% mais rápida do que a GeForce 6600 da Albatron, 600,74% mais rápida do que a Radeon X600 XT da ATI e 681,11% mais rápida do que a Radeon X600 Pro da Sapphire. Na configuração 1600x1200 com recursos de aumento de qualidade de imagem, a Radeon X1900 XTX da ATI foi 6,63% mais rápida do que a Radeon X1800 XT da ATI, 27,72% mais rápida do que a GeForce 7800 GTX da MSI, 33,70% mais rápida do que a GeForce 7800 GT da NVIDIA, 35,22% mais rápida do que a Radeon X1800 XL da ATI, 56,29% mais rápida do que a Radeon X850 XT P.E. da ATI, 95,42% mais rápida do que a GeForce 6800 GT da NVIDIA, 103,37% mais rápida do que a GeForce 6800 GS da NVIDIA, 154,03% mais rápida do que a Radeon X800 GTO da HIS, 195,63% mais rápida do que a Radeon X1600 XT da ATI, 206,36% mais rápida do que a Radeon X800 GT da HIS, 206,84% mais rápida do que a Radeon X1600 XT da HIS, 329,07% mais rápida do que a GeForce 6600 de 256 MB com overclock de fábrica da XFX, 335,01% mais rápida do que a Radeon X700 Pro da Sapphire, 357,31% mais rápida do que a GeForce 6600 GT da XFX, 664,56% mais rápida do que a GeForce 6600 da Albatron, 972,68% mais rápida do que a Radeon X600 XT da ATI e 1.047,95% mais rápida do que a Radeon X600 Pro da Sapphire. O 3Dmark05 mede o desempenho simulando jogos escritos para o DirectX 9.0c, ou seja, usando o modelo Shader 3.0. Este modelo de programação é usado pelo jogo Far Cry e por jogos que serão lançados em 2005. Atualmente somente os chips da NVIDIA das série 6 e 7 são Shader 3.0. Os chips concorrentes da ATI continuam sendo Shader 2.0. Rodamos o programa em três resoluções, 1024x768x32, 1280x1024x32 e 1600x1200x32, primeiro sem antialiasing e filtragem anisotrópica, e depois colocando o antialiasing em 4x e a filtragem anisotrópica também em 4x. Isso faz aumentar a qualidade da imagem, mas diminui o desempenho. Queríamos ver justamente o quanto de desempenho perdíamos quando colocamos a placa de vídeo para trabalhar com o máximo de qualidade possível. Importante notar que os chips da ATI permitem que o anti-aliasing seja configurado em até 6x. Como os chips da NVIDIA não permitem essa configuração, tivemos de manter a configuração de alta qualidade em 4x, de forma a adotarmos uma configuração que seja válida para todos os chips, fazendo com que a comparação seja válida. Na configuração 1024x768 sem recursos de aumento de qualidade de imagem, a Radeon X1900 XTX da ATI foi 7,90% mais rápida do que a Radeon X1800 XL da ATI, 10,07% mais rápida do que a GeForce 7800 GT da NVIDIA, 21,81% mais rápida do que a Radeon X850 XT P.E. da ATI, 39,89% mais rápida do que a Radeon X1600 XT da ATI, 41,31% mais rápida do que a GeForce 6800 GS da NVIDIA, 42,29% mais rápida do que a Radeon X1600 XT da HIS, 53,89% mais rápida do que a GeForce 6800 GT da NVIDIA, 62,33% mais rápida do que a Radeon X800 GTO da HIS, 74,86% mais rápida do que a Radeon X800 GT da HIS, 141,93% mais rápida do que a Radeon X700 Pro da Sapphire, 143,11% mais rápida do que a GeForce 6600 GT da XFX, 165,48% mais rápida do que a GeForce 6600 de 256 MB com overclock de fábrica da XFX, 310,46% mais rápida do que a GeForce 6600 da Albatron, 387,23% mais rápida do que a Radeon X600 XT da ATI e 411,50% mais rápida do que a Radeon X600 Pro da Sapphire, A placa testada obteve desempenho semelhante ao da GeForce 7800 GTX da MSI e perdeu para a Radeon X1800 XT da ATI, que foi 3,44% mais rápida. Na configuração 1280x1024 sem recursos de aumento de qualidade de imagem, a Radeon X1900 XTX da ATI obteve desempenho similar ao da Radeon X1800 XT da ATI e foi 10,42% mais rápida do que a GeForce 7800 GTX da MSI, 20,62% mais rápida do que a Radeon X1800 XL da ATI, 21,71% mais rápida do que a GeForce 7800 GT da NVIDIA, 41,33% mais rápida do que a Radeon X850 XT P.E. da ATI, 62,20% mais rápida do que a GeForce 6800 GS da NVIDIA, 63,99% mais rápida do que a Radeon X1600 XT da ATI, 66,56% mais rápida do que a Radeon X1600 XT da HIS, 78,88% mais rápida do que a GeForce 6800 GT da NVIDIA, 92,56% mais rápida do que a Radeon X800 GTO da HIS, 109,87% mais rápida do que a Radeon X800 GT da HIS, 197,34% mais rápida do que a Radeon X700 Pro da Sapphire, 218,85% mais rápida do que a GeForce 6600 de 256 MB com overclock de fábrica da XFX, 242,31% mais rápida do que a GeForce 6600 GT da XFX, 432,09% mais rápida do que a GeForce 6600 da Albatron, 544,13% mais rápida do que a Radeon X600 Pro da Sapphire e 575,30% mais rápida do que a Radeon X600 XT da ATI. Na configuração 1600x1200 sem recursos de aumento de qualidade de imagem, a Radeon X1900 XTX da ATI foi mais rápida do que todas as placas do teste. Ela foi 11,11% mais rápida do que a Radeon X1800 XT da ATI, 21,26% mais rápida do que a GeForce 7800 GTX da MSI, 36,08% mais rápida do que a GeForce 7800 GT da NVIDIA, 36,11% mais rápida do que a Radeon X1800 XL da ATI, 65,68% mais rápida do que a Radeon X850 XT P.E. da ATI, 88,51% mais rápida do que a GeForce 6800 GS da NVIDIA, 92,92% mais rápida do que a Radeon X1600 XT da ATI, 96,12% mais rápida do que a Radeon X1600 XT da HIS, 110,71% mais rápida do que a GeForce 6800 GT da NVIDIA, 128,05% mais rápida do que a Radeon X800 GTO da HIS, 168,02% mais rápida do que a Radeon X800 GT da HIS, 264,06% mais rápida do que a Radeon X700 Pro da Sapphire, 273,02% mais rápida do que a GeForce 6600 de 256 MB com overclock de fábrica da XFX, 415,27% mais rápida do que a GeForce 6600 GT da XFX, 589,94% mais rápida do que a GeForce 6600 da Albatron, 700,12% mais rápida do que a Radeon X600 Pro da Sapphire e 819,92% mais rápida do que a Radeon X600 XT da ATI. Na configuração 1280x1024 com recursos de aumento de qualidade de imagem, a Radeon X1900 XTX da ATI obteve desempenho semelhante ao da Radeon X1800 XT da ATI e foi 10,99% mais rápida do que a GeForce 7800 GTX da MSI, 14,35% mais rápida do que a Radeon X1800 XL da ATI, 20,83% mais rápida do que a GeForce 7800 GT da NVIDIA, 35,12% mais rápida do que a Radeon X850 XT P.E. da ATI, 63,51% mais rápida do que a GeForce 6800 GS da NVIDIA, 64,96% mais rápida do que a Radeon X1600 XT da ATI, 69,19% mais rápida do que a Radeon X1600 XT da HIS, 81,54% mais rápida do que a GeForce 6800 GT da NVIDIA, 83,78% mais rápida do que a Radeon X800 GTO da HIS, 90,66% mais rápida do que a Radeon X800 GT da HIS, 200,94% mais rápida do que a Radeon X700 Pro da Sapphire, 227,02% mais rápida do que a GeForce 6600 de 256 MB com overclock de fábrica da XFX, 421,91% mais rápida do que a GeForce 6600 GT da XFX, 547,11% mais rápida do que a Radeon X600 Pro da Sapphire, 618,40% mais rápida do que a GeForce 6600 da Albatron e 643,85% mais rápida do que a Radeon X600 XT da ATI. Para rodar na configuração 1280x1024 com recursos de aumento de qualidade de imagem no 3DMark05, a placa de vídeo deve ter pelo menos 256 MB de memória, e é por isso que algumas placas de vídeo não puderam rodar esse teste. Aqui, a Radeon X1900 XTX da ATI foi 8,79% mais rápida do que a Radeon X1800 XT da ATI, 26,71% mais rápida do que a GeForce 7800 GTX da MSI, 33,69% mais rápida do que a Radeon X1800 XL da ATI, 40,89% mais rápida do que a GeForce 7800 GT da NVIDIA, 63,13% mais rápida do que a Radeon X850 XT P.E. da ATI, 99,42% mais rápida do que a Radeon X1600 XT da ATI, 99,97% mais rápida do que a GeForce 6800 GS da NVIDIA, 104,39% mais rápida do que a Radeon X1600 XT da HIS, 121,32% mais rápida do que a GeForce 6800 GT da NVIDIA, 127,29% mais rápida do que a Radeon X800 GTO da HIS, 161,79% mais rápida do que a Radeon X800 GT da HIS, 281,59% mais rápida do que a Radeon X700 Pro da Sapphire, 308,39% mais rápida do que a GeForce 6600 de 256 MB com overclock de fábrica da XFX, 718,31% mais rápida do que a Radeon X600 Pro da Sapphire e 1.030,98% mais rápida do que a Radeon X600 XT da ATI. Para rodar na configuração 1600x1200 com recursos de aumento de qualidade de imagem no 3DMark05, a placa de vídeo deve ter pelo menos 256 MB de memória, e é por isso que algumas placas de vídeo não puderam rodar esse teste. Aqui, a Radeon X1900 XTX da ATI foi 18,25% mais rápida do que a Radeon X1800 XT da ATI, 48,70% mais rápida do que a Radeon X1800 XL da ATI, 50,02% mais rápida do que a GeForce 7800 GTX da MSI, 66,92% mais rápida do que a GeForce 7800 GT da NVIDIA, 88,06% mais rápida do que a Radeon X850 XT P.E. da ATI, 136,50% mais rápida do que a Radeon X1600 XT da ATI, 141,71% mais rápida do que a Radeon X1600 XT da HIS, 164,40% mais rápida do que a Radeon X800 GTO da HIS, 179,78% mais rápida do que a GeForce 6800 GS da NVIDIA, 180,03% mais rápida do que a GeForce 6800 GT da NVIDIA, 221,00% mais rápida do que a Radeon X800 GT da HIS, 355,09% mais rápida do que a Radeon X700 Pro da Sapphire, 396,66% mais rápida do que a GeForce 6600 de 256 MB com overclock de fábrica da XFX, 961,63% mais rápida do que a Radeon X600 Pro da Sapphire e 1.733,72% mais rápida do que a Radeon X600 XT da ATI. O Doom 3 é um dos jogos mais pesados existentes atualmente. Assim como nos fizemos nos demais programas, rodamos este jogo em três resoluções, 1024x768x32, 1280x1024x32 e 1600x1200x32. Este jogo permite vários níveis de qualidade de imagem, e fizemos nossos testes em dois níveis, low e high. Rodamos o demo1 quatro vezes e anotamos a quantidade de quadros por segundo obtida. O primeiro resultado nós descartamos de cara, pois ele é bem inferior ao das demais rodadas. Isso ocorre porque na primeira vez em que rodamos o demo o jogo tem que carregar as texturas para a memória de vídeo da placa testada, coisa que não ocorre da segunda vez em diante em que o mesmo demo é rodado. Dos três resultados que sobraram, aproveitamos o resultado com valor intermediário, isto é, descartamos o maior e o menor valor. Interessante notar que na maioria das vezes os valores obtidos pela segunda rodada em diante eram os mesmos. Um detalhe importante que não podemos deixar de comentar é que o Doom 3 possui uma trava interna da quantidade de quadros por segundo que ele é capaz de gerar durante uma sessão normal de jogo: ele só gera 60 quadros por segundo, mesmo que sua placa possa gerar mais. Isso foi feito justamente para o jogo ter uma mesma sensação de "jogabilidade" independentemente da placa de vídeo instalada. Esta trava, entretanto, não atua no modo de medida de desempenho do jogo. Para mais detalhes de como efetuar testes de desempenho 3D com o Doom 3, leia o nosso tutorial sobre o assunto. Na configuração 1024x768 sem recursos de aumento de qualidade de imagem, a Radeon X1900 XTX da ATI foi 5,80% mais rápida do que a GeForce 6800 GS da NVIDIA, 14,44% mais rápida do que a Radeon X850 XT P.E. da ATI, 16,93% mais rápida do que a GeForce 6800 GT da NVIDIA, 25,42% mais rápida do que a Radeon X800 GTO da HIS, 27,40% mais rápida do que a GeForce 6600 GT da XFX, 38,74% mais rápida do que a Radeon X800 GT da HIS, 40,96% mais rápida do que a GeForce 6600 de 256 MB com overclock de fábrica da XFX, 45,20% mais rápida do que a Radeon X1600 XT da ATI, 46,29% mais rápida do que a Radeon X1600 XT da HIS, 73,92% mais rápida do que a Radeon X700 Pro da Sapphire, 78,74% mais rápida do que a GeForce 6600 da Albatron, 212,94% mais rápida do que a Radeon X600 XT da ATI e 283,73% mais rápida do que a Radeon X600 Pro da Sapphire. A Radeon X1900 XTX da ATI apresentou desempenho semelhante ao das placas Radeon X1800 XT da ATI, GeForce 7800 GTX da MSI, Radeon X1800 XL da ATI e GeForce 7800 GT da NVIDIA. Na configuração 1280x1024 sem recursos de aumento de qualidade de imagem, a Radeon X1900 XTX da ATI foi 3,87% mais rápida do que a GeForce 7800 GTX da MSI, 7,31% mais rápida do que a GeForce 7800 GT da NVIDIA, 16,21% mais rápida do que a Radeon X1800 XL da ATI, 21,16% mais rápida do que a GeForce 6800 GS da NVIDIA, 22,58% mais rápida do que a Radeon X850 XT P.E. da ATI, 23,88% mais rápida do que a GeForce 6800 GT da NVIDIA, 56,76% mais rápida do que a GeForce 6600 GT da XFX, 70,42% mais rápida do que a Radeon X800 GTO da HIS, 86,68% mais rápida do que a GeForce 6600 de 256 MB com overclock de fábrica da XFX, 100,64% mais rápida do que a Radeon X800 GT da HIS, 110,07% mais rápida do que a Radeon X1600 XT da ATI, 111,96% mais rápida do que a Radeon X1600 XT da HIS, 151,74% mais rápida do que a Radeon X700 Pro da Sapphire, 156,56% mais rápida do que a GeForce 6600 da Albatron, 379,08% mais rápida do que a Radeon X600 XT da ATI e 486,88% mais rápida do que a Radeon X600 Pro da Sapphire. A Radeon X1900 XTX da ATI obteve desempenho semelhante ao da Radeon X1800 XT da ATI. Na configuração 1600x1200 sem recursos de aumento de qualidade de imagem, a Radeon X1900 XTX da ATI foi mais rápida do que todas as placas do teste, sendo 7,18% mais rápida do que a GeForce 7800 GTX da MSI, 11,74% mais rápida do que a Radeon X1800 XT da ATI, 13,65% mais rápida do que a GeForce 7800 GT da NVIDIA, 34,47% mais rápida do que a GeForce 6800 GT da NVIDIA, 36,59% mais rápida do que a GeForce 6800 GS da NVIDIA, 37,24% mais rápida do que a Radeon X1800 XL da ATI, 38,78% mais rápida do que a Radeon X850 XT P.E. da ATI, 88,67% mais rápida do que a GeForce 6600 GT da XFX, 122,62% mais rápida do que a Radeon X800 GTO da HIS, 135,33% mais rápida do que a GeForce 6600 de 256 MB com overclock de fábrica da XFX, 173,19% mais rápida do que a Radeon X1600 XT da ATI, 174,92% mais rápida do que a Radeon X800 GT da HIS, 176,68% mais rápida do que a Radeon X1600 XT da HIS, 226,79% mais rápida do que a GeForce 6600 da Albatron, 239,61% mais rápida do que a Radeon X700 Pro da Sapphire, 561,07% mais rápida do que a Radeon X600 XT da ATI e 716,98% mais rápida do que a Radeon X600 Pro da Sapphire. Na configuração 1024x768 com recursos de aumento de qualidade de imagem, a Radeon X1900 XTX da ATI foi 3,38% mais rápida do que a GeForce 6800 GS da NVIDIA, 9,81% mais rápida do que a Radeon X850 XT P.E. da ATI, 12,36% mais rápida do que a GeForce 6800 GT da NVIDIA, 24,39% mais rápida do que a Radeon X800 GTO da HIS, 29,66% mais rápida do que a GeForce 6600 GT da XFX, 40,15% mais rápida do que a Radeon X800 GT da HIS, 40,37% mais rápida do que a GeForce 6600 de 256 MB com overclock de fábrica da XFX, 50,49% mais rápida do que a Radeon X1600 XT da ATI, 51,99% mais rápida do que a Radeon X1600 XT da HIS, 82,14% mais rápida do que a Radeon X700 Pro da Sapphire, 88,50% mais rápida do que a GeForce 6600 da Albatron, 230,22% mais rápida do que a Radeon X600 XT da ATI e 300,87% mais rápida do que a Radeon X600 Pro da Sapphire. A placa testada obteve desempenho semelhante ao das placas GeForce 7800 GT da NVIDIA, GeForce 7800 GTX da MSI e Radeon X1800 XL da ATI. A Radeon X1900 XTX da ATI perdeu apenas para a Radeon X1800 XT da ATI, que foi 3,81% mais rápida. Na configuração 1280x1024 com recursos de aumento de qualidade de imagem, a Radeon X1900 XTX da ATI foi mais rápida do que todas as placas do teste, sendo 5,10% mais rápida do que a Radeon X1800 XT da ATI, 6,88% mais rápida do que a GeForce 7800 GTX da MSI, 9,34% mais rápida do que a GeForce 7800 GT da NVIDIA, 21,23% mais rápida do que a Radeon X1800 XL da ATI, 27,42% mais rápida do que a Radeon X850 XT P.E. da ATI, 28,28% mais rápida do que a GeForce 6800 GS da NVIDIA, 30,94% mais rápida do que a GeForce 6800 GT da NVIDIA, 70,81% mais rápida do que a GeForce 6600 GT da XFX, 80,23% mais rápida do que a Radeon X800 GTO da HIS, 99,16% mais rápida do que a GeForce 6600 de 256 MB com overclock de fábrica da XFX, 113,51% mais rápida do que a Radeon X800 GT da HIS, 127,34% mais rápida do que a Radeon X1600 XT da ATI, 130,10% mais rápida do que a Radeon X1600 XT da HIS, 175,58% mais rápida do que a Radeon X700 Pro da Sapphire, 183,83% mais rápida do que a GeForce 6600 da Albatron, 415,22% mais rápida do que a Radeon X600 XT da ATI e 532,00% mais rápida do que a Radeon X600 Pro da Sapphire. Na configuração 1600x1200 com recursos de aumento de qualidade de imagem, a Radeon X1900 XTX da ATI também foi mais rápida do que todas as placas do teste, sendo 10,64% mais rápida do que a GeForce 7800 GTX da MSI, 16,62% mais rápida do que a Radeon X1800 XT da ATI, 17,55% mais rápida do que a GeForce 7800 GT da NVIDIA, 43,97% mais rápida do que a Radeon X1800 XL da ATI, 44,68% mais rápida do que a GeForce 6800 GT da NVIDIA, 45,87% mais rápida do que a GeForce 6800 GS da NVIDIA, 46,60% mais rápida do que a Radeon X850 XT P.E. da ATI, 103,69% mais rápida do que a GeForce 6600 GT da XFX, 134,48% mais rápida do que a Radeon X800 GTO da HIS, 150,42% mais rápida do que a GeForce 6600 de 256 MB com overclock de fábrica da XFX, 189,84% mais rápida do que a Radeon X800 GT da HIS, 190,79% mais rápida do que a Radeon X1600 XT da ATI, 194,67% mais rápida do que a Radeon X1600 XT da HIS, 253,60% mais rápida do que a GeForce 6600 da Albatron, 266,80% mais rápida do que a Radeon X700 Pro da Sapphire, 662,07% mais rápida do que a Radeon X600 XT da ATI e 758,25% mais rápida do que a Radeon X600 Pro da Sapphire. O Far Cry é um jogo baseado no modelo Shader 3.0 (DirectX 9.0c), modelo de programação presente nos chips das séries 6 e 7 da NVIDIA e nos chips da série X1000 da ATI. Assim como nos fizemos nos demais programas, rodamos este jogo em três resoluções, 1024x768x32, 1280x1024x32 e 1600x1200x32. Este jogo permite vários níveis de qualidade de imagem, e fizemos nossos testes em dois níveis, low e very high. Para efetuarmos a medida de desempenho usamos o demo criado pela revista alemã PC Games Hardware (PCGH), disponível em http://www.3dcenter.org/downloads/farcry-pcgh-vga.php. Rodamos este demo quatro vezes e fizemos uma média aritmética, sendo esta média o resultado que apresentamos. Este jogo tem um detalhe importantíssimo em sua configuração de qualidade de imagem. O anti-aliasing, em vez de ser configurado numericamente (1x, 2x, 4x ou 6x) é configurado como low, medium ou high. O problema é que em chips da NVIDIA, tanto medium quanto high significa 4x, enquanto que em chips da ATI medium significa 2x e high significa 6x, tornando a comparação entre chips da ATI e da NVIDIA injusta. Por este motivo nós configuramos o antialiasing em 4x e a filtragem anisotrópica em 8x manualmente através do painel de controle do driver. Para mais detalhes de como efetuar testes de desempenho 3D com o Far Cry, leia o nosso tutorial sobre o assunto. Na configuração 1024x768 sem recursos de aumento de qualidade de imagem, a Radeon X1900 XTX da ATI foi 5,37% mais rápida do que a GeForce 7800 GTX da MSI, 6,73% mais rápida do que a GeForce 7800 GT da NVIDIA, 6,74% mais rápida do que a GeForce 6800 GS da NVIDIA, 8,48% mais rápida do que a Radeon X600 XT da ATI, 9,45% mais rápida do que a GeForce 6600 de 256 MB com overclock de fábrica da XFX, 10,42% mais rápida do que a GeForce 6600 GT da XFX, 16,52% mais rápida do que a GeForce 6600 da Albatron, 19,46% mais rápida do que a GeForce 6800 GT da NVIDIA e 28,00% mais rápida do que a Radeon X600 Pro da Sapphire. A Radeon X1900 XTX da ATI apresentou desempenho semelhante ao das seguintes placas: Radeon X800 GT da HIS, Radeon X850 XT P.E. da ATI, Radeon X800 GTO da HIS, Radeon X1800 XT da ATI, Radeon X1600 XT da HIS, Radeon X700 Pro da Sapphire, Radeon X1800 XL da ATI e Radeon X1600 XT da ATI. Na configuração 1280x1024 sem recursos de aumento de qualidade de imagem, a Radeon X1900 XTX da ATI foi 11,22% mais rápida do que a GeForce 6600 de 256 MB com overclock de fábrica da XFX, 46,96% mais rápida do que a Radeon X600 XT da ATI, 49,19% mais rápida do que a GeForce 6600 da Albatron e 79,59% mais rápida do que a Radeon X600 Pro da Sapphire. A placa testada apresentou desempenho semelhante ao das seguintes placas: GeForce 7800 GTX da MSI, GeForce 6800 GS da NVIDIA, GeForce 7800 GT da NVIDIA, GeForce 6800 GT da NVIDIA e GeForce 6600 GT da XFX. A Radeon X1900 XTX da ATI perdeu para as demais placas do teste: a Radeon X850 XT P.E. da ATI foi 9,28% mais rápida, a Radeon X800 GT da HIS foi 9,12% mais rápida, a Radeon X800 GTO da HIS foi 8,69% mais rápida, a Radeon X1800 XL da ATI foi 8,17% mais rápida, a Radeon X1800 XT da ATI foi 7,39% mais rápida, a Radeon X1600 XT da ATI foi 7,22% mais rápida, a Radeon X1600 XT da HIS foi 6,96% mais rápida e a Radeon X700 Pro da Sapphire foi 5,65% mais rápida. Na configuração 1600x1200 sem recursos de aumento de qualidade de imagem, a Radeon X1900 XTX da ATI foi 8,13% mais rápida do que a Radeon X1600 XT da ATI, 10,53% mais rápida do que a Radeon X1600 XT da HIS, 19,72% mais rápida do que a GeForce 6600 GT da XFX, 24,36% mais rápida do que a Radeon X700 Pro da Sapphire, 47,01% mais rápida do que a GeForce 6600 de 256 MB com overclock de fábrica da XFX, 106,49% mais rápida do que a GeForce 6600 da Albatron, 118,74% mais rápida do que a Radeon X600 XT da ATI e 167,86% mais rápida do que a Radeon X600 Pro da Sapphire. A placa testada apresentou desempenho semelhante ao das seguintes placas: GeForce 7800 GTX da MSI, GeForce 7800 GT da NVIDIA, GeForce 6800 GS da NVIDIA, Radeon X800 GT da HIS e GeForce 6800 GT da NVIDIA. A Radeon X1900 XTX da ATI perdeu para a Radeon X850 XT P.E. da ATI, que foi 9,74% mais rápida, para a Radeon X1800 XT da ATI, que foi 8,75% mais rápida, para a Radeon X1800 XL da ATI, que foi 8,38% mais rápida e para a Radeon X800 GTO da HIS, que foi 6,45% mais rápida do que a placa testada. Na configuração 1024x768 com recursos de aumento de qualidade de imagem, a Radeon X1900 XTX da ATI foi 10,07% mais rápida do que a Radeon X800 GTO da HIS, 26,60% mais rápida do que a Radeon X800 GT da HIS, 44,85% mais rápida do que a Radeon X1600 XT da ATI, 47,50% mais rápida do que a Radeon X1600 XT da HIS, 70,43% mais rápida do que a Radeon X700 Pro da Sapphire, 81,30% mais rápida do que a GeForce 6600 GT da XFX, 86,71% mais rápida do que a GeForce 6600 de 256 MB com overclock de fábrica da XFX, 193,20% mais rápida do que a GeForce 6600 da Albatron, 240,03% mais rápida do que a Radeon X600 Pro da Sapphire e 270,33% mais rápida do que a Radeon X600 XT da ATI. A placa testada apresentou desempenho semelhante ao da GeForce 6800 GS da NVIDIA e da GeForce 6800 GT da NVIDIA. A Radeon X1900 XTX da ATI perdeu para a Radeon X850 XT P.E. da ATI, que foi 10,39% mais rápida, para a Radeon X1800 XL da ATI, que foi 10,30% mais rápida, para a Radeon X1800 XT da ATI, que foi 9,77% mais rápida, para a GeForce 7800 GT da NVIDIA, que foi 9,25% mais rápida e para a GeForce 7800 GTX da MSI, que foi 8,62% mais rápida do que a placa testada. Na configuração 1280x1024 com recursos de aumento de qualidade de imagem, a Radeon X1900 XTX da ATI foi 27,47% mais rápida do que a GeForce 6800 GS da NVIDIA, 33,11% mais rápida do que a GeForce 6800 GT da NVIDIA, 49,76% mais rápida do que a Radeon X800 GTO da HIS, 78,48% mais rápida do que a Radeon X800 GT da HIS, 92,72% mais rápida do que a Radeon X1600 XT da ATI, 102,27% mais rápida do que a Radeon X1600 XT da HIS, 143,23% mais rápida do que a Radeon X700 Pro da Sapphire, 165,65% mais rápida do que a GeForce 6600 GT da XFX, 177,47% mais rápida do que a GeForce 6600 de 256 MB com overclock de fábrica da XFX, 355,14% mais rápida do que a GeForce 6600 da Albatron, 384,73% mais rápida do que a Radeon X600 Pro da Sapphire e 403,60% mais rápida do que a Radeon X600 XT da ATI. A placa testada apresentou desempenho semelhante ao da Radeon X1800 XL da ATI, Radeon X850 XT P.E. da ATI e GeForce 7800 GT da NVIDIA. A Radeon X1900 XTX da ATI perdeu para a Radeon X1800 XT da ATI, que foi 9,75% mais rápida e para a GeForce 7800 GTX da MSI, que foi 3,70% mais rápida. Na configuração 1600x1200 com recursos de aumento de qualidade de imagem, a Radeon X1900 XTX da ATI foi 15,60% mais rápida do que a Radeon X1800 XL da ATI, 18,11% mais rápida do que a GeForce 7800 GTX da MSI, 26,54% mais rápida do que a Radeon X850 XT P.E. da ATI, 31,08% mais rápida do que a GeForce 7800 GT da NVIDIA, 71,85% mais rápida do que a GeForce 6800 GS da NVIDIA, 100,12% mais rápida do que a GeForce 6800 GT da NVIDIA, 101,47% mais rápida do que a Radeon X800 GTO da HIS, 147,37% mais rápida do que a Radeon X800 GT da HIS, 179,97% mais rápida do que a Radeon X1600 XT da ATI, 185,68% mais rápida do que a Radeon X1600 XT da HIS, 242,93% mais rápida do que a Radeon X700 Pro da Sapphire, 251,36% mais rápida do que a GeForce 6600 GT da XFX, 298,03% mais rápida do que a GeForce 6600 de 256 MB com overclock de fábrica da XFX, 508,33% mais rápida do que a GeForce 6600 da Albatron, 753,48% mais rápida do que a Radeon X600 Pro da Sapphire e 878,89% mais rápida do que a Radeon X600 XT da ATI. A Radeon X1900 XTX da ATI perdeu apenas para a Radeon X1800 XT da ATI, que foi 4,75% mais rápida. De acordo com os resultados obtidos, podemos dizer que o Radeon X1900 XTX parece estar otimizado para jogos DirectX 9.0 e 9.0c rodando em resoluções muito altas, com ajuste de qualidade de imagem habilitado. No 3DMark2001SE, que simula jogos DirectX 8.1, ele obteve desempenho ruim, portanto este parece não ser o produto ideal para jogos mais antigos. Mas no 3DMark03 e no 3DMark05, que simulam jogos DirectX 9.0 e 9.0c, respectivamente, a placa foi mais rápida que todas as outras placas de vídeo que testamos até hoje, incluindo a Radeon X1800 XT e a GeForce 7800 GTX. Tendo em mente que comparações entre o Radeon X1900 XTX e o Radeon X1800 XT em nossos testes não são definitivas, já que nossa GeForce 7800 GTX tinha 256 MB de memória de vídeo, ao passo que as amostras da ATI chegaram com 512 MB. No 3DMark03 (DirectX 9,0) o Radeon X1900 XTX foi entre 4,61% e 8,64% mais rápido que o Radeon X1800 XT e entre 10,26% e 27,72% mais rápido que o GeForce 7800 GTX, dependendo dos ajustes de resolução e qualidade de imagem. No 3DMark05 (DirectX 9.0c) os resultados variaram de acordo com a resolução usada. O Radeon X1900 XTX alcançou desempenho parecido com o do Radeon X1800 XT em 1280x1024 e 1024x768 com ajuste de qualidade de imagem habilitado, enquanto foi derrotado pelo Radeon X1800 XT em 1024x768. Nessa resolução ele atingiu desempenho parecido com o do GeForce 7800 GTX. Mas em outras resoluções e ajustes de qualidade de imagem, o Radeon X1900 XTX foi entre 8,79% e 18,25% mais rápido que o Radeon X1800 XT e entre 10,42% e 50,02% mais rápido que o GeForce 7800 GTX. Devemos mencionar que quanto maior a resolução, maior a diferença no desempenho. No Doom 3 o Radeon X1900 XTX obteve desempenho parecido com o do Radeon X1800 XT em 1024x768 e 1280x1024, e foi vencido por uma pequena margem pelo Radeon X1800 XT em 1024x768 com ajustes de qualidade de imagem habilitados (nesta resolução ele atingiu desempenho similar ao do GeForce 7800 GTX). Em outras resoluções e ajustes de qualidade de imagem, o Radeon X1900 XTX foi entre 5,10% e 16,62% mais rápido que o Radeon X1800 XT e entre 3,87% e 10,64% mais rápido que o GeForce 7800 GTX. Far Cry foi o calcanhar de Aquiles do Radeon X1900 XTX, como você pode ver na página anterior, o que é curioso, já que se trata de um jogo DirectX 9.0c. O único bom resultado nesse jogo foi em 1600x1200 com ajustes de qualidade de imagem no máximo, onde ele foi 18,11% mais rápido que o GeForce 7800 GTX. Uma falha em nosso teste foi que nós não testamos o desempenho em resoluções acima de 1600x1200, como 1920x1200, 2048x1536 e 2560x1600. Achamos que o Radeon X1900 XTX alcançaria desempenho ainda melhor nessas resoluções, já que os melhores resultados do Radeon X1900 XTX foram alcançados em 1600x1200. Com base nesses resultados, podemos afirmar que o Radeon X1900 XTX é destinado a jogadores “pesados” que rodam jogos DirectX 9.0 e acima em resolução de pelo menos 1600x1200 com todos os ajustes de qualidade de imagem no máximo. Se você não for rodar esse jogos com essas configurações, comprar uma Radeon X1900 XTX é sem propósito, já que você pode ter desempenho quase igual com produtos mais baratos. Em nossa opinião, pagar entre US$ 590 e US$ 650 nos EUA por uma placa de vídeo é loucura até pelos jogadores mais “barra-pesada”, já que existem placas de vídeo topo-de-linha no mercado que apresentam relação custo/benefício muito melhor (Radeon X1800 XT e GeForce 7800 GTX são boas opções se você tem dinheiro para comprá-las; Radeon X1800 XL e GeForce 7800 GT são ótimas soluções para quem não é louco o suficiente para pagar mais de US$ 400 [nos EUA] por uma placa de vídeo). -

Laptop de US$ 100 Vai Funcionar na Base da Manivela?
Gabriel Torres respondeu ao tópico de Gabriel Torres em Comentários de artigos
Olá, Obrigado, eu realmente não sabia disso. Acabei de postar uma nota no blog adicionando esta informação. Mais uma vez, muito obrigado pela correção. Abraços, Gabriel Torres -
O Laptop de US$ 100 do Governo Brasileiro
Gabriel Torres respondeu ao tópico de Gabriel Torres em Comentários de artigos
Claro que são diferentes, leia com atenção a mensagem original do usuário Jose Terrabuio, as fotos são de um projeto similar, não é do mesmo projeto. Abraços, Gabriel Torres -
O Laptop de US$ 100 do Governo Brasileiro
Gabriel Torres respondeu ao tópico de Gabriel Torres em Comentários de artigos
Oi pessoal, Acabei de postar mais informações sobre esse laptop: https://www.clubedohardware.com.br/artigos/blog/63 Abraços, Gabriel. -
Laptop de US$ 100 Vai Funcionar na Base da Manivela?
Gabriel Torres postou um tópico em Comentários de artigos
Tópico para a discussão do seguinte conteúdo publicado no Clube do Hardware: Laptop de US$ 100 Vai Funcionar na Base da Manivela? "Escutei recentemente de um conhecido que viu o protótipo do tal laptop de US$ 100 proposto pelo Nicholas "Alô Mamãe, Estou Aqui" Negroponte que o bicho vai funcionar na base da manivela. É isso mesmo." Comentários são bem-vindos. Atenciosamente, Equipe Clube do Hardware https://www.clubedohardware.com.br -
 Escutei recentemente de um conhecido que viu o protótipo do tal laptop de US$ 100 proposto pelo Nicholas "Alô Mamãe, Estou Aqui" Negroponte que o bicho vai funcionar na base da manivela. É isso mesmo. O aluno vai ter que rodar a manivela para gerar energia para operar o bicho por 10 minutos, então rodar novamente a manivela e por aí vai. A ideia é que ele possa ser usado em escolas onde não exista eletricidade. Perfeito para um país como o nosso onde as escolas não têm nem quadro-negro. Atualizado em 21/02/2006: Um leitor me corrigiu dizendo que a manivela é item opcional, sendo que o bicho pode funcionar ligado na tomada ou a uma bateria, sendo que o adaptador de força dele pode ser inclusive usado como alça. Fica aqui registrada a correção. Tive uma ideia melhor, acho que vou mandar para o MIT e pode ser que eles até me candidatem a um Prêmio Nobel. Porque em vez de colocar as crianças para rodarem a manivela eles não enviam junto com o laptop uma rodinha para que os alunos coloquem um ratinho dentro para que ele fique correndo e gerando a eletricidade para o laptop? Não querem gastar dinheiro enviando uma rodinha? Não tem problema, o meu protótipo usa uma vasilha de margarina usada (e lavada, obviamente). Quanto ao ratinho, ele pode ser facilmente achado no "mercado local", se é que me entende. Minha ideia só tem um furo básico: onde os alunos vão arrumar um pedacinho de queijo para colocarem na gaiola? Afinal o governo quer comprar esses laptops para comunidades onde as pessoas não têm nem o que comer. Afinal, aprender a usar um laptop à manivela em uma sala de aula sem quadro-negro é muito mais importante do que comer, não é mesmo? Se a história da manivela é verdade ou não, eu não sei, tanto que estou postando aqui no blog. Pode ser apenas intriga da oposição. Mas se você reparar no esboço do bicho em seu site oficial (http://www.laptop.org), vai ver que ele realmente tem uma manivela gigante do lado dele Veja também: Que fim levou o laptop de US$ 100 do governo brasileiro?
Escutei recentemente de um conhecido que viu o protótipo do tal laptop de US$ 100 proposto pelo Nicholas "Alô Mamãe, Estou Aqui" Negroponte que o bicho vai funcionar na base da manivela. É isso mesmo. O aluno vai ter que rodar a manivela para gerar energia para operar o bicho por 10 minutos, então rodar novamente a manivela e por aí vai. A ideia é que ele possa ser usado em escolas onde não exista eletricidade. Perfeito para um país como o nosso onde as escolas não têm nem quadro-negro. Atualizado em 21/02/2006: Um leitor me corrigiu dizendo que a manivela é item opcional, sendo que o bicho pode funcionar ligado na tomada ou a uma bateria, sendo que o adaptador de força dele pode ser inclusive usado como alça. Fica aqui registrada a correção. Tive uma ideia melhor, acho que vou mandar para o MIT e pode ser que eles até me candidatem a um Prêmio Nobel. Porque em vez de colocar as crianças para rodarem a manivela eles não enviam junto com o laptop uma rodinha para que os alunos coloquem um ratinho dentro para que ele fique correndo e gerando a eletricidade para o laptop? Não querem gastar dinheiro enviando uma rodinha? Não tem problema, o meu protótipo usa uma vasilha de margarina usada (e lavada, obviamente). Quanto ao ratinho, ele pode ser facilmente achado no "mercado local", se é que me entende. Minha ideia só tem um furo básico: onde os alunos vão arrumar um pedacinho de queijo para colocarem na gaiola? Afinal o governo quer comprar esses laptops para comunidades onde as pessoas não têm nem o que comer. Afinal, aprender a usar um laptop à manivela em uma sala de aula sem quadro-negro é muito mais importante do que comer, não é mesmo? Se a história da manivela é verdade ou não, eu não sei, tanto que estou postando aqui no blog. Pode ser apenas intriga da oposição. Mas se você reparar no esboço do bicho em seu site oficial (http://www.laptop.org), vai ver que ele realmente tem uma manivela gigante do lado dele Veja também: Que fim levou o laptop de US$ 100 do governo brasileiro? -
Tópico para a discussão do seguinte conteúdo publicado no Clube do Hardware: Por Dentro da Conexão HDMI (High Definition Multimedia Interface) "Uma olhada aprofundada na conexão HDMI (High Definition Multimedia Interface) usada por aparelhos de DVD, HD-DVD e Blu-Ray, conversores digitais de TV a cabo/satélite e aparelhos HDTV." Comentários são bem-vindos. Atenciosamente, Equipe Clube do Hardware https://www.clubedohardware.com.br
-
Por Dentro da Conexão HDMI (High Definition Multimedia Interface)
Gabriel Torres postou um artigo em Vídeo
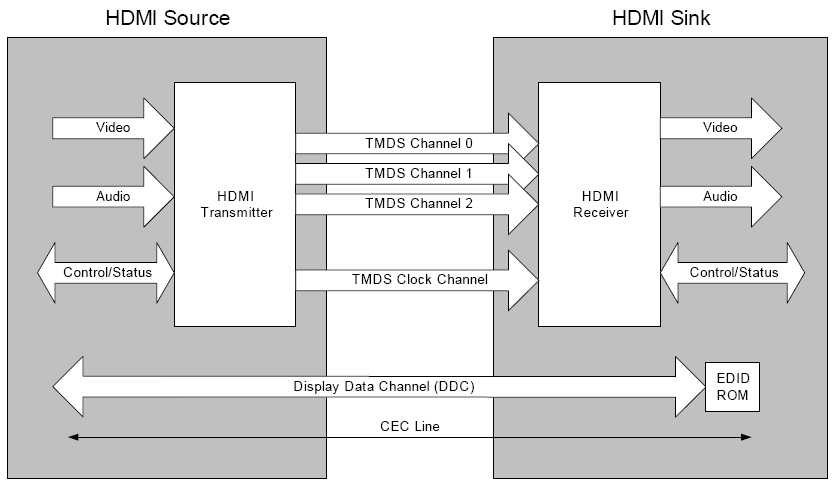 O HDMI (High-Definition Multimedia Interface) é atualmente o melhor tipo de conector de áudio e vídeo digital disponível que promete substituir todos os conectores atualmente usados em aparelhos deDVD e similares, decodificadores de TV a cabo/satélite, TVs, videoprojetores e monitores de vídeo. A ideia é em vez de usarmos vários cabos e conectores para conectar os sinais de áudio e vídeo de um aparelho de HD-DVD a uma TV, por exemplo, exista apenas um único cabo e conector fazendo todas as ligações necessárias. Este novo padrão de conexão está desenvolvido em conjunto pelas empresas Hitachi, Matsushita (Panasonic/National/Technics), Phillips, Silicon Image, Sony, Thomson (RCA) e Toshiba. A maior vantagem desse novo padrão é que a conexão tanto de áudio e quanto de vídeo são feitas digitalmente, apresentando a melhor qualidade possível de áudio e vídeo. O DVI (DVI-D, na verdade) também oferece conexão digital entre seus equipamentos e telas, mas ele não transforma suporta sinais de áudio, o que significa que você precisa de um cabo extra para a conexão de áudio; e todos os outros padrões populares – vídeo componentes e S-Video, por exemplo – são conexões analógicas. Você pode aprender mais sobre os outros tipos de conexão existentes hoje lendo nosso tutorial Conectores de Vídeo. Há três diferenças básicas entre o HDMI e o DVI-D. Primeiro, o HDMI suporta resoluções maiores do que o DVI, inclusive resoluções ainda não lançadas comercialmente (em teoria suporta o dobro da resolução mais alta usada atualmente por aparelhos de TV de alta definição); segundo, o DVI só faz conexão de vídeo, a conexão de áudio precisa ser feita através de um cabo separado, enquanto o HDMI faz a conexão tanto do vídeo quanto do áudio; terceiro, o conector HDMI é bem menor que o conector DVI. É interessante notar que o HDMI é totalmente compatível com o DVI-D, sendo possível conectar um aparelho com um conector HDMI a outro contendo um conector DVI-D, através de um cabo com um conector HDMI em uma ponta e um DVI na outra. Outra diferença importante é que o padrão DVI foi desenvolvido para ser usado por PCs, enquanto que o HDMI foi desenvolvido para ser usado por equipamentos eletrônicos tais como aparelhos de DVD, Blu-Ray e HD-DVD, videoprojetores e aparelhos HDTV. O HDMI também implementa um sistema de proteção contra cópias chamado HDCP (High-Bandwidth Digital Copy Protection), que foi desenvolvido pela Intel. Leia mais sobre o assunto em http://www.digital-cp.com. Na Figura 1 você vê o diagrama em blocos da arquitetura HDMI. Uma fonte (“source”) é qualquer dispositivo com uma saída HDMI, enquanto que um dreno (“sink”) é qualquer dispositivo com uma entrada HDMI. Figura 1: Arquitetura HDMI. A transmissão de dados usa o protocolo TMDS (Sinalização Diferencial Minimizada pela Transição, Transition Minimized Differential Signaling), criado pela empresa Silicon Image (que, por sua vez, adota o nome comercial PanelLink para este protocolo), que é o mesmo padrão usado pela conexão DVI. Este padrão codifica um dado de oito bits em um sinal de 10 bits, e os transmite usando transmissão diferencial. Leia nosso tutorial Como o Gigabit Ethernet Funciona para aprender o que é transmissão diferencial, técnica que também é conhecida como cancelamento. Os dados de áudio e vídeo são transmitidos usando os três canais TMDS de dados existentes. As informações de vídeo são transmitidas como uma série de pixels de 24 bits e são transmitidos 10 bits por período do clock de pixel (o período do clock de pixel, Tpixel, é definido como o tempo necessário para se transmitir um pixel; equivale a 10 vezes o período de transmissão de um bit, Tbit). O clock de pixel pode variar de 25 MHz a 165 MHz. Formatos que usem taxas de transmissão abaixo de 25 MHz (por exemplo, o padrão NTSC 480i [480 linhas, varredura não-entrelaçada], usa um clock de pixel de 13,5 MHz) podem usar um esquema de repetição de pixels para conseguirem ser transmitidos. Isso significa que com o HDMI é possível transmitir até 165 milhões de pixels por segundo (usando a configuração dual-link, na qual falaremos na próxima página, é possível atingir o dobro desta taxa). Esta taxa informa a resolução máxima que pode ser transmitida. Para que você entenda melhor o que é o clock de pixel e qual é a sua importância, considere a resolução 720p, que é amplamente utilizada por aparelhos HDTV. Esta resolução é na realidade de 1280x720. Multiplicando-se 1280x720 temos o número de pixels da tela. O número encontrado deve ser multiplicado pela quantidade de quadros por segundo (freqüência vertical ou taxa de atualização) para sabermos a quantidade de pixels por segundo (ou seja, a taxa de transmissão) da resolução. Supondo uma taxa de atualização de 60 Hz (720p@60Hz), temos que precisamos de um link capaz de transmitir 55.296.000 pixels por segundo ou 55,3 MHz. Como o padrão HDMI pode transferir até 165 milhões de pixels por segundo, esta conexão dá e sobra para esta resolução. Se formos calcular para a resolução mais alta disponível hoje, 1080p (1920x1080) a 60 MHz, veremos que esta precisa de uma taxa de 124,4 MHz, ou seja, o HDMI dá e sobra. Desta forma, o HDMI suporta as resoluções mais altas disponíveis hoje para aparelhos eletrônicos de consumo, além de permitir o modo dual-link, onde sua taxa dobra para 330 MHz, suportando altas resoluções ainda não usadas comercialmente. Para mais informações sobre resoluções HDTV, leia nosso tutorial Tudo sobre HDTV. Os pixels de vídeo podem ser codificados nos formatos RGB, YCbCr 4:4:4 ou YCbCr 4:2:2 a 24 bits por pixel. YCbCr é a versão digital do vídeo componente (a versão analógica do vídeo componente, que é a mais usada, é chamada YPbPr). Estes dois padrões são também conhecidos como YUV. “Y” é a informação de luminância (a imagem em preto-e-branco), Cb é a diferença entre o azul e a luminância (B-Y) e o Cr é a diferença entre o vermelho e a luminância (R-Y). Os três números representam as taxas de amostragem usadas para codificar os sinais Y, Cb e Cr, respectivamente. O valor “4” indica a taxa de 13,5 MHz, que é a taxa de amostragem usada pelos padrões NTSC, PAL e Secam. O padrão 4:4:4 indica, portanto, que os sinais estão sendo todos transmitidos na mesma taxa. Já o padrão 4:2:2 indica que o sinal Y está sendo transmitido a 13,5 MHz, mas os sinais Cb e Cr estão sendo transmitidos a 6,75 MHz. Obviamente neste modo a qualidade de imagem é inferior, embora seja bastante usado. O áudio pode ser de dois a oito canais, usando taxas de amostragem até 192 kHz. O canal DDC (Canal de Informações sobre o Vídeo, Display Data Channel) é usado para que o dispositivo de transmissão saiba qual é a configuração e/ou capacidades do dispositivo receptor. Isto é feito lendo-se o dado E-EDID (Dados Avançados Estendidos de Identificação do Vídeo, Enhanced Extended Display Identification Data) do dispositivo receptor. O canal CEC (Consumer Electronics Control) é opcional e permite o controle dos vários aparelhos audiovisuais que o usuário possua. O HDMI pode usar dois tipos de conector: tipo A, contendo 19 pinos, e tipo B, contendo 29 pinos. Este segundo é maior e permite o uso da configuração “dual link”, que dobra a taxa de transferência máxima possível. Ou seja, com o conector tipo A é possível o uso de um clock de pixel de até 165 MHz (usando a arquitetura mostrada na Figura 1) e, com o conector tipo B, é possível obter uma taxa de pixel de até 330 MHz (usando o circuito da Figura 1 duplicado). Figura 2: Conector HDMI Tipo A vs. conector DVI. O padrão TMDS limita o cabo a um comprimento máximo de cinco metros. Dispositivos transmissores com plugue do tipo A podem ser ligados a dispositivos receptores com plugue do tipo B usando um cabo com um plugue tipo A em uma ponta e um plugue tipo B na outra. Não é possível ligar um dispositivo transmissor com plugue tipo B a um dispositivo receptor com plugue tipo A. Como mencionamos anteriormente, o HDMI e o DVI são compatíveis e existem cabos conversores entre os dois padrões. Nas tabelas abaixo apresentamos a pinagem dos conectores tipo A, tipo B e a pinagem do conversor HDMI x DVI. Mas antes vamos falar rapidamente sobre algo interessante, que é o custo de se usar o padrão HDMI. Preço Um aspecto interessante do HDMI é que ele não é um padrão aberto. Fabricantes querendo adotá-lo têm que pagar taxas de royalties para a empresa HDMI Licensing, LLC: uma taxa anual de US$ 15.000 e US$ 0.15 por cada produto vendido usando o padrão HDMI. Esta taxa cai para US$ 0.05 se o fabricante usar a logomarca do HDMI no produto e em seu material promocional. Se o padrão HDCP for usado, a taxa de royalty cai para US$ 0,04 por cada unidade vendida. Além disso, se o fabricante quiser usar o sistema de proteção contra cópias HDCP, ele deve pagar uma taxa anual de US$ 15.000 mais US$ 0.005 por cada chave criptográfica, que devem ser pagas à empresa Digital Content Protection, LLC (uma subsidiária da Intel). Mais informações sobre o HDMI podem ser encontradas em http://www.hdmi.org e mais informações sobre o HDCP podem ser encontradas em http://www.digital-cp.com. Pinagem dos Conectores e Cabos Conector HDMI Tipo A Pino Sinal 1 TMDS Data2+ 2 TMDS Data2 Shield 3 TMDS Data2 4 TMDS Data1+ 5 TMDS Data1 Shield 6 TMDS Data1– 7 TMDS Data0+ 8 TMDS Data0 Shield 9 TMDS Data0– 10 TMDS Clock+ 11 TMDS Clock Shield 12 TMDS Clock– 13 CEC 14 Reservado (N.C. no dispositivo) 15 SCL 16 SDA 17 Terra DDC/CEC 18 + 5V 19 Hot Plug Detect Conector HDMI Tipo B Pino Sinal 1 TMDS Data2+ 2 TMDS Data2 Shield 3 TMDS Data2- 4 TMDS Data1+ 5 TMDS Data1 Shield 6 TMDS Data1- 7 TMDS Data0+ 8 TMDS Data0 Shield 9 TMDS Data0- 10 TMDS Clock+ 11 TMDS Clock Shield 12 TMDS Clock- 13 TMDS Data5+ 14 TMDS Data5 Shield 15 TMDS Data5- 16 TMDS Data4+ 17 TMDS Data4 Shield 18 TMDS Data4- 19 TMDS Data3+ 20 TMDS Data3 Shield 21 TMDS Data3- 22 CEC 23 Reservado (N.C. no dispositivo) 24 Reservado (N.C. no dispositivo) 25 SCL 26 SDA 27 Terra DDC/CEC 28 +5V 29 Hot Plug Detect Conector HDMI Tipo A x DVI-D Pino HDMI Sinal Fio Pino DVI-D 1 TMDS Data2+ A 2 2 TMDS Data2 Shield B 3 3 TMDS Data2- A 1 4 TMDS Data1+ A 10 5 TMDS Data1 Shield B 11 6 TMDS Data1- A 9 7 TMDS Data0+ A 18 8 TMDS Data0 Shield B 19 9 TMDS Data0- A 17 10 TMDS Clock+ A 23 11 TMDS Clock Shield B 22 12 TMDS Clock- A 24 13 CEC N.C. N.C. 14 Reservado N.C. N.C. 15 SCL C 6 16 DDC C 7 17 Terra DDC/CEC D 15 18 +5V 5V 14 19 Hot Plug Detect C 16 20 Não Conectado 4 21 Não Conectado 5 22 Não Conectado 12 23 Não Conectado 13 24 Não Conectado 20 25 Não Conectado 21 26 Não Conectado 8 Conector HDMI Tipo B x DVI-D Pino HDMI Sinal Fio Pino DVI-D 1 TMDS Data2+ A 2 2 TMDS Data2 Shield B 3 3 TMDS Data2- A 1 4 TMDS Data1+ A 10 5 TMDS Data1 Shield B 11 6 TMDS Data1- A 9 7 TMDS Data0+ A 18 8 TMDS Data0 Shield B 19 9 TMDS Data0- A 17 10 TMDS Clock+ A 23 11 TMDS Clock Shield B 22 12 TMDS Clock- A 24 13 TMDS Data5+ A 21 14 TMDS Data5 Shield B 19 15 TMDS Data5- A 20 16 TMDS Data4+ A 5 17 TMDS Data4 Shield B 3 18 TMDS Data4- A 4 19 TMDS Data3+ A 13 20 TMDS Data3 Shield B 11 21 TMDS Data3- A 12 22 CEC N.C. N.C. 23 Reservado N.C. N.C. 24 Reservado N.C. N.C. 25 SCL C 6 26 DDC C 7 27 Terra DDC/CEC D 15 28 +5V 5V 14 29 Hot Plug Detect C 16 Não Conectado N.C. 8
O HDMI (High-Definition Multimedia Interface) é atualmente o melhor tipo de conector de áudio e vídeo digital disponível que promete substituir todos os conectores atualmente usados em aparelhos deDVD e similares, decodificadores de TV a cabo/satélite, TVs, videoprojetores e monitores de vídeo. A ideia é em vez de usarmos vários cabos e conectores para conectar os sinais de áudio e vídeo de um aparelho de HD-DVD a uma TV, por exemplo, exista apenas um único cabo e conector fazendo todas as ligações necessárias. Este novo padrão de conexão está desenvolvido em conjunto pelas empresas Hitachi, Matsushita (Panasonic/National/Technics), Phillips, Silicon Image, Sony, Thomson (RCA) e Toshiba. A maior vantagem desse novo padrão é que a conexão tanto de áudio e quanto de vídeo são feitas digitalmente, apresentando a melhor qualidade possível de áudio e vídeo. O DVI (DVI-D, na verdade) também oferece conexão digital entre seus equipamentos e telas, mas ele não transforma suporta sinais de áudio, o que significa que você precisa de um cabo extra para a conexão de áudio; e todos os outros padrões populares – vídeo componentes e S-Video, por exemplo – são conexões analógicas. Você pode aprender mais sobre os outros tipos de conexão existentes hoje lendo nosso tutorial Conectores de Vídeo. Há três diferenças básicas entre o HDMI e o DVI-D. Primeiro, o HDMI suporta resoluções maiores do que o DVI, inclusive resoluções ainda não lançadas comercialmente (em teoria suporta o dobro da resolução mais alta usada atualmente por aparelhos de TV de alta definição); segundo, o DVI só faz conexão de vídeo, a conexão de áudio precisa ser feita através de um cabo separado, enquanto o HDMI faz a conexão tanto do vídeo quanto do áudio; terceiro, o conector HDMI é bem menor que o conector DVI. É interessante notar que o HDMI é totalmente compatível com o DVI-D, sendo possível conectar um aparelho com um conector HDMI a outro contendo um conector DVI-D, através de um cabo com um conector HDMI em uma ponta e um DVI na outra. Outra diferença importante é que o padrão DVI foi desenvolvido para ser usado por PCs, enquanto que o HDMI foi desenvolvido para ser usado por equipamentos eletrônicos tais como aparelhos de DVD, Blu-Ray e HD-DVD, videoprojetores e aparelhos HDTV. O HDMI também implementa um sistema de proteção contra cópias chamado HDCP (High-Bandwidth Digital Copy Protection), que foi desenvolvido pela Intel. Leia mais sobre o assunto em http://www.digital-cp.com. Na Figura 1 você vê o diagrama em blocos da arquitetura HDMI. Uma fonte (“source”) é qualquer dispositivo com uma saída HDMI, enquanto que um dreno (“sink”) é qualquer dispositivo com uma entrada HDMI. Figura 1: Arquitetura HDMI. A transmissão de dados usa o protocolo TMDS (Sinalização Diferencial Minimizada pela Transição, Transition Minimized Differential Signaling), criado pela empresa Silicon Image (que, por sua vez, adota o nome comercial PanelLink para este protocolo), que é o mesmo padrão usado pela conexão DVI. Este padrão codifica um dado de oito bits em um sinal de 10 bits, e os transmite usando transmissão diferencial. Leia nosso tutorial Como o Gigabit Ethernet Funciona para aprender o que é transmissão diferencial, técnica que também é conhecida como cancelamento. Os dados de áudio e vídeo são transmitidos usando os três canais TMDS de dados existentes. As informações de vídeo são transmitidas como uma série de pixels de 24 bits e são transmitidos 10 bits por período do clock de pixel (o período do clock de pixel, Tpixel, é definido como o tempo necessário para se transmitir um pixel; equivale a 10 vezes o período de transmissão de um bit, Tbit). O clock de pixel pode variar de 25 MHz a 165 MHz. Formatos que usem taxas de transmissão abaixo de 25 MHz (por exemplo, o padrão NTSC 480i [480 linhas, varredura não-entrelaçada], usa um clock de pixel de 13,5 MHz) podem usar um esquema de repetição de pixels para conseguirem ser transmitidos. Isso significa que com o HDMI é possível transmitir até 165 milhões de pixels por segundo (usando a configuração dual-link, na qual falaremos na próxima página, é possível atingir o dobro desta taxa). Esta taxa informa a resolução máxima que pode ser transmitida. Para que você entenda melhor o que é o clock de pixel e qual é a sua importância, considere a resolução 720p, que é amplamente utilizada por aparelhos HDTV. Esta resolução é na realidade de 1280x720. Multiplicando-se 1280x720 temos o número de pixels da tela. O número encontrado deve ser multiplicado pela quantidade de quadros por segundo (freqüência vertical ou taxa de atualização) para sabermos a quantidade de pixels por segundo (ou seja, a taxa de transmissão) da resolução. Supondo uma taxa de atualização de 60 Hz (720p@60Hz), temos que precisamos de um link capaz de transmitir 55.296.000 pixels por segundo ou 55,3 MHz. Como o padrão HDMI pode transferir até 165 milhões de pixels por segundo, esta conexão dá e sobra para esta resolução. Se formos calcular para a resolução mais alta disponível hoje, 1080p (1920x1080) a 60 MHz, veremos que esta precisa de uma taxa de 124,4 MHz, ou seja, o HDMI dá e sobra. Desta forma, o HDMI suporta as resoluções mais altas disponíveis hoje para aparelhos eletrônicos de consumo, além de permitir o modo dual-link, onde sua taxa dobra para 330 MHz, suportando altas resoluções ainda não usadas comercialmente. Para mais informações sobre resoluções HDTV, leia nosso tutorial Tudo sobre HDTV. Os pixels de vídeo podem ser codificados nos formatos RGB, YCbCr 4:4:4 ou YCbCr 4:2:2 a 24 bits por pixel. YCbCr é a versão digital do vídeo componente (a versão analógica do vídeo componente, que é a mais usada, é chamada YPbPr). Estes dois padrões são também conhecidos como YUV. “Y” é a informação de luminância (a imagem em preto-e-branco), Cb é a diferença entre o azul e a luminância (B-Y) e o Cr é a diferença entre o vermelho e a luminância (R-Y). Os três números representam as taxas de amostragem usadas para codificar os sinais Y, Cb e Cr, respectivamente. O valor “4” indica a taxa de 13,5 MHz, que é a taxa de amostragem usada pelos padrões NTSC, PAL e Secam. O padrão 4:4:4 indica, portanto, que os sinais estão sendo todos transmitidos na mesma taxa. Já o padrão 4:2:2 indica que o sinal Y está sendo transmitido a 13,5 MHz, mas os sinais Cb e Cr estão sendo transmitidos a 6,75 MHz. Obviamente neste modo a qualidade de imagem é inferior, embora seja bastante usado. O áudio pode ser de dois a oito canais, usando taxas de amostragem até 192 kHz. O canal DDC (Canal de Informações sobre o Vídeo, Display Data Channel) é usado para que o dispositivo de transmissão saiba qual é a configuração e/ou capacidades do dispositivo receptor. Isto é feito lendo-se o dado E-EDID (Dados Avançados Estendidos de Identificação do Vídeo, Enhanced Extended Display Identification Data) do dispositivo receptor. O canal CEC (Consumer Electronics Control) é opcional e permite o controle dos vários aparelhos audiovisuais que o usuário possua. O HDMI pode usar dois tipos de conector: tipo A, contendo 19 pinos, e tipo B, contendo 29 pinos. Este segundo é maior e permite o uso da configuração “dual link”, que dobra a taxa de transferência máxima possível. Ou seja, com o conector tipo A é possível o uso de um clock de pixel de até 165 MHz (usando a arquitetura mostrada na Figura 1) e, com o conector tipo B, é possível obter uma taxa de pixel de até 330 MHz (usando o circuito da Figura 1 duplicado). Figura 2: Conector HDMI Tipo A vs. conector DVI. O padrão TMDS limita o cabo a um comprimento máximo de cinco metros. Dispositivos transmissores com plugue do tipo A podem ser ligados a dispositivos receptores com plugue do tipo B usando um cabo com um plugue tipo A em uma ponta e um plugue tipo B na outra. Não é possível ligar um dispositivo transmissor com plugue tipo B a um dispositivo receptor com plugue tipo A. Como mencionamos anteriormente, o HDMI e o DVI são compatíveis e existem cabos conversores entre os dois padrões. Nas tabelas abaixo apresentamos a pinagem dos conectores tipo A, tipo B e a pinagem do conversor HDMI x DVI. Mas antes vamos falar rapidamente sobre algo interessante, que é o custo de se usar o padrão HDMI. Preço Um aspecto interessante do HDMI é que ele não é um padrão aberto. Fabricantes querendo adotá-lo têm que pagar taxas de royalties para a empresa HDMI Licensing, LLC: uma taxa anual de US$ 15.000 e US$ 0.15 por cada produto vendido usando o padrão HDMI. Esta taxa cai para US$ 0.05 se o fabricante usar a logomarca do HDMI no produto e em seu material promocional. Se o padrão HDCP for usado, a taxa de royalty cai para US$ 0,04 por cada unidade vendida. Além disso, se o fabricante quiser usar o sistema de proteção contra cópias HDCP, ele deve pagar uma taxa anual de US$ 15.000 mais US$ 0.005 por cada chave criptográfica, que devem ser pagas à empresa Digital Content Protection, LLC (uma subsidiária da Intel). Mais informações sobre o HDMI podem ser encontradas em http://www.hdmi.org e mais informações sobre o HDCP podem ser encontradas em http://www.digital-cp.com. Pinagem dos Conectores e Cabos Conector HDMI Tipo A Pino Sinal 1 TMDS Data2+ 2 TMDS Data2 Shield 3 TMDS Data2 4 TMDS Data1+ 5 TMDS Data1 Shield 6 TMDS Data1– 7 TMDS Data0+ 8 TMDS Data0 Shield 9 TMDS Data0– 10 TMDS Clock+ 11 TMDS Clock Shield 12 TMDS Clock– 13 CEC 14 Reservado (N.C. no dispositivo) 15 SCL 16 SDA 17 Terra DDC/CEC 18 + 5V 19 Hot Plug Detect Conector HDMI Tipo B Pino Sinal 1 TMDS Data2+ 2 TMDS Data2 Shield 3 TMDS Data2- 4 TMDS Data1+ 5 TMDS Data1 Shield 6 TMDS Data1- 7 TMDS Data0+ 8 TMDS Data0 Shield 9 TMDS Data0- 10 TMDS Clock+ 11 TMDS Clock Shield 12 TMDS Clock- 13 TMDS Data5+ 14 TMDS Data5 Shield 15 TMDS Data5- 16 TMDS Data4+ 17 TMDS Data4 Shield 18 TMDS Data4- 19 TMDS Data3+ 20 TMDS Data3 Shield 21 TMDS Data3- 22 CEC 23 Reservado (N.C. no dispositivo) 24 Reservado (N.C. no dispositivo) 25 SCL 26 SDA 27 Terra DDC/CEC 28 +5V 29 Hot Plug Detect Conector HDMI Tipo A x DVI-D Pino HDMI Sinal Fio Pino DVI-D 1 TMDS Data2+ A 2 2 TMDS Data2 Shield B 3 3 TMDS Data2- A 1 4 TMDS Data1+ A 10 5 TMDS Data1 Shield B 11 6 TMDS Data1- A 9 7 TMDS Data0+ A 18 8 TMDS Data0 Shield B 19 9 TMDS Data0- A 17 10 TMDS Clock+ A 23 11 TMDS Clock Shield B 22 12 TMDS Clock- A 24 13 CEC N.C. N.C. 14 Reservado N.C. N.C. 15 SCL C 6 16 DDC C 7 17 Terra DDC/CEC D 15 18 +5V 5V 14 19 Hot Plug Detect C 16 20 Não Conectado 4 21 Não Conectado 5 22 Não Conectado 12 23 Não Conectado 13 24 Não Conectado 20 25 Não Conectado 21 26 Não Conectado 8 Conector HDMI Tipo B x DVI-D Pino HDMI Sinal Fio Pino DVI-D 1 TMDS Data2+ A 2 2 TMDS Data2 Shield B 3 3 TMDS Data2- A 1 4 TMDS Data1+ A 10 5 TMDS Data1 Shield B 11 6 TMDS Data1- A 9 7 TMDS Data0+ A 18 8 TMDS Data0 Shield B 19 9 TMDS Data0- A 17 10 TMDS Clock+ A 23 11 TMDS Clock Shield B 22 12 TMDS Clock- A 24 13 TMDS Data5+ A 21 14 TMDS Data5 Shield B 19 15 TMDS Data5- A 20 16 TMDS Data4+ A 5 17 TMDS Data4 Shield B 3 18 TMDS Data4- A 4 19 TMDS Data3+ A 13 20 TMDS Data3 Shield B 11 21 TMDS Data3- A 12 22 CEC N.C. N.C. 23 Reservado N.C. N.C. 24 Reservado N.C. N.C. 25 SCL C 6 26 DDC C 7 27 Terra DDC/CEC D 15 28 +5V 5V 14 29 Hot Plug Detect C 16 Não Conectado N.C. 8 -
Tabela comparativa dos chips Radeon da AMD (desktop)
Gabriel Torres postou um tópico em Comentários de artigos
Tópico para a discussão do seguinte conteúdo publicado no Clube do Hardware: Tabela comparativa dos chips Radeon da AMD (desktop) "Uma tabela comparativa com as especificações técnicas de todos chips gráficos Radeon da AMD disponíveis no mercado para computadores de mesa." Comentários são bem-vindos. Atenciosamente, Equipe Clube do Hardware https://www.clubedohardware.com.br -
 Com mais e mais chips gráficos sendo lançados a cada dia, torna-se bastante complicado para os usuários que não acompanham o mercado de placas de vídeo saber as diferenças entre todos os chips gráficos da AMD existentes no mercado hoje. Para facilitar a compreensão e saber a diferença entre estes chips, compilamos a tabela abaixo. Para chips gráficos da AMD para computadores portáteis, veja a nossa “Tabela comparativa os chips Radeon da AMD (notebooks)”. Para chips gráficos da NVIDIA para computadores de mesa, veja a nossa “Tabela comparativa dos chips GeForce da NVIDIA (desktop)”. Em 2010 a AMD, empresa que comprou a ATI em 2006, parou de usar a marca “ATI”. GPU Memória GPU API GPU Radeon Clock Clock Boost Clock Interface Largura Banda Proc. DirectX OpenGL PCIe AIW 128 90 MHz – 90 MHz 128 bits 1,440 GB/s 4 6.0 1.2 PCI Rage 128 PRO 118 MHz – 143 MHz 64 bits 1,144 GB/s 2 6.0 1.2 AGP 4x AIW 128 PRO 120 MHz – 120 MHz 128 bits 1,920 GB/s 4 6.0 1.2 AGP 4x Rage 128 PRO Ultra 130 MHz – 130 MHz 64 bits 1,040 GB/s 2 6.0 1.2 AGP 4x Rage 128 Ultra 119 MHz – 119 MHz 64 bits 952 MB/s 2 6.0 1.2 AGP 4x Rage 128 VR 80 MHz – 125 MHz 64 bits 1 GB/s 2 6.0 1.2 AGP 4x Rage Fury 80 MHz – 120 MHz 64 bits 960 MB/s 2 6.0 1.2 AGP 4x Rage Fury MAXX† 125 MHz – 143 MHz 64 bits 1,144 GB/s 2 6.0 1.2 AGP 4x Radeon 166 MHz – 166 MHz 128 bits 2,656 GB/s 2 7.0 1.3 AGP 4x PCI 166 MHz – 166 MHz 128 bits 2,656 GB/s 2 7.0 1.3 PCI DDR 166 MHz – 332 MHz 128 bits 5,312 GB/s 2 7.0 1.3 AGP 4x DDR VIVO 183 MHz – 366 MHz 128 bits 5,856 GB/s 2 7.0 1.3 AGP 4x DDR VIVO OEM 166 MHz – 332 MHz 128 bits 5,312 GB/s 2 7.0 1.3 AGP 4x DDR VIVO SE 187 MHz – 360 MHz 128 bits 5,760 GB/s 2 7.0 1.3 AGP 4x LE 148 MHz – 296 MHz 128 bits 4,736 GB/s 2 7.0 1.3 AGP 4x VE 183 MHz – 366 MHz 64 bits 2,928 GB/s 1 7.0 1.3 AGP 4x VE PCI 183 MHz – 366 MHz 64 bits 2,928 GB/s 1 7.0 1.3 PCI AIW VE 260 MHz – 500 MHz 128 bits 8 GB/s 2 8.1 1.3 PCI 7000 183 MHz – 366 MHz 64 bits 2,928 GB/s 1 7.0 1.3 AGP 4x 7000 PCI 133 MHz – 266 MHz 64 bits 2,128 GB/s 1 7.0 1.3 PCI 7200 SDRAM 143 MHz – 143 MHz 128 bits 2,288 GB/s 2 7.0 1.3 AGP 4x 7200 DDR 166 MHz – 332 MHz 128 bits 5,312 GB/s 2 7.0 1.3 AGP 4x AIW 7200 166 MHz – 332 MHz 128 bits 5,312 GB/s 2 7.0 1.3 PCI 7500 290 MHz – 460 MHz 128 bits 7,36 GB/s 2 8.1 1.3 AGP 4x AIW 7500 260 MHz – 360 MHz 128 bits 5,76 GB/s 2 8.1 1.3 PCI 7500 LE 250 MHz – 350 MHz 128 bits 5,6 GB/s 2 8.1 1.3 AGP 4x 8500 275 MHz – 550 MHz 128 bits 8,8 GB/s 4 8.1 1.4 AGP 4x AIW 8500 230 MHz – 380 MHz 128 bits 6,08 GB/s 4 8.1 1.4 AGP 8x AIW 8500DV 230 MHz – 380 MHz 128 bits 6,08 GB/s 4 8.1 1.4 AGP 8x 8500 LE 250 MHz – 500 MHz 128 bits 8 GB/s 4 8.1 1.4 AGP 4x 8500 XT 300 MHz – 600 MHz 128 bits 9,6 GB/s 4 8.1 1.4 AGP 4x 9000 250 MHz – 400 MHz 128 bits 6,4 GB/s 4 8.1 1.4 AGP 4x 9000 LE 250 MHz – 400 MHz 128 bits 6,4 GB/s 4 8.1 1.4 AGP 4x 9000 Pro 275 MHz – 550 MHz 128 bits 8,8 GB/s 4 8.1 1.4 AGP 4x AIW 9000 Pro 275 MHz – 450 MHz 128 bits 7,2 GB/s 4 8.1 1.4 AGP 8x 9100 250 MHz – 500 MHz 128 bits 8 GB/s 4 8.1 1.4 AGP 4x 9100 PCI 250 MHz – 500 MHz 128 bits 8 GB/s 4 8.1 1.4 PCI 9200 250 MHz – 400 MHz 128 bits 6,4 GB/s 4 8.1 1.4 AGP 8x AIW 9200 250 MHz – 400 MHz 128 bits 6,4 GB/s 4 8.1 1.4 AGP 8x 9200 Pro 275 MHz – 550 MHz 128 bits 8,8 GB/s 4 8.1 1.4 AGP 8x 9200 SE 200 MHz – 333 MHz 64 bits 2,6 GB/s 4 8.1 1.4 AGP 8x AIW 9200 LE 250 MHz – 333 MHz 64 bits 2,6 GB/s 4 8.1 1.4 AGP 8x 9250 240 MHz – 400 MHz 128 bits 6,4 GB/s 4 8.1 1.4 AGP 8x 9250 SE 240 MHz – 400 MHz 64 bits 3,2 GB/s 4 8.1 1.4 AGP 8x 9500 275 MHz – 540 MHz 128 bits 8,6 GB/s 4 9.0 2.0 AGP 8x AIW 9500 277 MHz – 540 MHz 128 bits 8,6 GB/s 4 9.0 2.0 AGP 8x 9550 250 MHz – 400 MHz 128 bits 6,4 GB/s 4 9.0 2.0 AGP 8x 9550 SE 250 MHz – 400 MHz 64 bits 3,2 GB/s 4 9.0 2.0 AGP 8x 9500 Pro 275 MHz – 540 MHz 128 bits 8,6 GB/s 8 9.0 2.0 AGP 8x 9600 325 MHz – 400 MHz 128 bits 6,4 GB/s 4 9.0 2.0 AGP 8x AIW 9600 324 MHz – 392 MHz 128 bits 6,272 GB/s 4 9.0 2.0 AGP 8x 9600 Pro 400 MHz – 600 MHz 128 bits 9,6 GB/s 4 9.0 2.0 AGP 8x AIW 9600 Pro 400 MHz – 650 MHz 128 bits 10,4 GB/s 4 9.0 2.0 AGP 8x 9600 SE 325 MHz – 400 MHz 64 bits 3,2 GB/s 4 9.0 2.0 AGP 8x 9600 XT 500 MHz – 600 MHz 128 bits 9,6 GB/s 4 9.0 2.0 AGP 8x AIW 9600 XT 527 MHz – 648 MHz 128 bits 10,37 GB/s 4 9.0 2.0 AGP 8x 9700 275 MHz – 540 MHz 256 bits 17,2 GB/s 8 9.0 2.0 AGP 8x 9700 Pro 325 MHz – 620 MHz 256 bits 19,8 GB/s 8 9.0 2.0 AGP 8x AIW 9700 Pro 325 MHz – 620 MHz 256 bits 19,8 GB/s 8 9.0 2.0 AGP 8x 9800 325 MHz – 580 MHz 256 bits 18,56 GB/s 8 9.0 2.0 AGP 8x 9800 Pro 380 MHz – 680 MHz 256 bits 21,7 GB/s 8 9.0 2.0 AGP 8x AIW 9800 Pro 378 MHz – 676 MHz 256 bits 21,63 GB/s 8 9.0 2.0 AGP 8x 9800 SE 325 MHz – 500 MHz 128 bits 8 GB/s 4 9.0 2.0 AGP 8x 9800 SE 325 MHz – 500 MHz 256 bits 16 GB/s 4 9.0 2.0 AGP 8x AIW 9800 SE 378 MHz – 594 MHz 128 bits 9,504 GB/s 4 9.0 2.0 AGP 8x 9800 XT 412 MHz – 730 MHz 256 bits 23,3 GB/s 8 9.0 2.0 AGP 8x X300 SE 325 MHz – 400 MHz 64 bits 3,2 GB/s 4 9.0 2.0 1.1 X300 325 MHz – 400 MHz 128 bits 6,4 GB/s 4 9.0 2.0 1.1 X550 400 MHz – 500 MHz 64 bits 4 GB/s 4 9.0 2.0 1.1 X550 400 MHz – 500 MHz 128 bits 8 GB/s 4 9.0 2.0 1.1 AIW X600 400 MHz – 600 MHz 128 bits 9,6 GB/s 4 9.0 2.0 1.1 X600 Pro 400 MHz – 600 MHz 128 bits 9,6 GB/s 4 9.0 2.0 1.1 X600 XT 500 MHz – 730 MHz 128 bits 11,68 GB/s 4 9.0 2.0 1.1 X700 400 MHz – 600 MHz 128 bits 9,6 GB/s 8 9.0 2.0 1.1 X700 Pro 420 MHz – 864 MHz 128 bits 13,8 GB/s 8 9.0 2.0 1.1 X700 XT 475 MHz – 1,05 GHz 128 bits 16,8 GB/s 8 9.0 2.0 1.1 X800 SE * – * * * 8 9.0 2.0 1.1 X800 400 MHz – 700 MHz 256 bits 22,4 GB/s 12 9.0 2.0 1.1 AIW X800 500 MHz – 1 GHz 128 bits 16 GB/s 16 9.0b 2.0 AGP 8x AIW X800 VE 425 MHz – 800 MHz 128 bits 12,8 GB/s 8 9.0b 2.0 AGP 8x X800 XL 400 MHz – 1 GHz 256 bits 32 GB/s 16 9.0 2.0 1.1 AIW X800 XL 400 MHz – 980 MHz 256 bits 31,36 GB/s 16 9.0b 2.0 1.1 X800 GT 475 MHz – * 128 bits * 8 9.0 2.0 1.1 X800 GT 475 MHz – * 256 bits * 8 9.0 2.0 1.1 AIW X800 GT 400 MHz – 980 MHz 128 bits 15,68 GB/s 8 9.0b 2.0 1.1 X800 GTO 400 MHz – 1 GHz* 256 bits 32 GB/s 12 9.0 2.0 1.1 X800 Pro 475 MHz – 950 MHz 256 bits 30,4 GB/s 12 9.0 2.0 1.1 X800 XT 500 MHz – 1 GHz 256 bits 32 GB/s 16 9.0 2.0 1.1 AIW X800 XT 500 MHz – 1 GHz 256 bits 32 GB/s 16 9.0b 2.0 AGP 8x X800 XT PE 520 MHz – 1,12 GHz 256 bits 35,8 GB/s 16 9.0 2.0 1.1 X850 Pro 520 MHz – 1,08 GHz 256 bits 34,56 GB/s 12 9.0 2.0 1.1 X850 XT 520 MHz – 1,08 GHz 256 bits 34,56 GB/s 16 9.0 2.0 1.1 X850 PE 540 MHz – 1,18 GHz 256 bits 37,76 GB/s 16 9.0 2.0 1.1 X1050 * – * * * 4 9.0c 2.0 1.1 AIW 2006 AGP Edition 324 MHz – 392 MHz 128 bits 6,272 GB/s 4 9.0 2.0 AGP 8x AIW 2006 PCIe Edition 450 MHz – 800 MHz 128 bits 12,8 GB/s 4 9.0c 2.0 1.1 X1300 HM 450 MHz – 1 GHz 32 bits 4 GB/s 4 9.0c 2.0 1.1 X1300 HM 450 MHz – 1 GHz 64 bits 8 GB/s 4 9.0c 2.0 1.1 X1300 HM 450 MHz – 1 GHz 128 bits 16 GB/s 4 9.0c 2.0 1.1 X1300 450 MHz – 500 MHz 32 bits 2 GB/s 4 9.0c 2.0 1.1 X1300 450 MHz – 500 MHz 64 bits 4 GB/s 4 9.0c 2.0 1.1 X1300 450 MHz – 500 MHz 128 bits 8 GB/s 4 9.0c 2.0 1.1 X1300 Pro 600 MHz – 800 MHz 32 bits 3,2 GB/s 4 9.0c 2.0 1.1 X1300 Pro 600 MHz – 800 MHz 64 bits 6,4 GB/s 4 9.0c 2.0 1.1 X1300 Pro 600 MHz – 800 MHz 128 bits 12,8 GB/s 4 9.0c 2.0 1.1 X1300 XT DDR2 500 MHz – 800 MHz 128 bits 12,8 GB/s 12 9.0c 2.0 1.1 X1300 XT GDDR3 500 MHz – 1 GHz 128 bits 16 GB/s 12 9.0c 2.0 1.1 X1550 500 MHz – 666 MHz 64 bits 5,3 GB/s 4 9.0c 2.0 1.1 x16 X1550 550 MHz – 800 MHz 128 bits 12,8 GB/s 4 9.0c 2.0 1.1 x16 X1550 600 MHz – 800 MHz 128 bits 12,8 GB/s 4 9.0c 2.0 1.1 x16 X1550 AGP 600 MHz – 660 MHz 64 bits 5,28 GB/s 4 9.0c 2.0 AGP 8x X1550 PCI 452 MHz – 532 MHz 64 bits 4,3 GB/s 4 9.0c 2.0 PCI X1600 Pro 500 MHz – 780 MHz 128 bits 12,48 GB/s 12 9.0c 2.0 1.1 X1600 Pro AGP 500 MHz – 780 MHz 128 bits 12,48 GB/s 12 9.0c 2.0 AGP 8x X1600 XT 590 MHz – 1,38 GHz 128 bits 22,08 GB/s 12 9.0c 2.0 1.1 X1650 Pro 600 MHz – 1,4 GHz 128 bits 22,4 GB/s 12 9.0c 2.0 1.1 X1650 XT 575 MHz – 1,35 GHz 128 bits 21,60 GB/s 24 9.0c 2.0 1.1 X1800 GTO 500 MHz – 1 GHz 256 bits 32 GB/s 12 9.0c 2.0 1.1 X1800 XL 500 MHz – 1 GHz 256 bits 32 GB/s 16 9.0c 2.0 1.1 AIW X1800 XL 500 MHz – 1 GHz 256 bits 32 GB/s 16 9.0c 2.0 1.1 X1800 XT 625 MHz – 1,5 GHz 256 bits 48 GB/s 16 9.0c 2.0 1.1 AIW X1900 500 MHz – 954 MHz 256 bits 30,53 GB/s 48 9.0c 2.0 1.1 X1900 GT 575 MHz – 1,2 GHz 256 bits 38,4 GB/s 36 9.0c 2.0 1.1 X1900 XT 625 MHz – 1,45 GHz 256 bits 46,4 GB/s 48 9.0c 2.0 1.1 X1900 XTX 650 MHz – 1,55 GHz 256 bits 49,6 GB/s 48 9.0c 2.0 1.1 X1950 GT 500 MHz – 1,2 GHz 256 bits 38,4 GB/s 36 9.0c 2.0 1.1 X1950 Pro 575 MHz – 1,38 GHz 256 bits 44,16 GB/s 36 9.0c 2.0 1.1 X1950 XT 625 MHz – 1,8 GHz 256 bits 57,6 GB/s 48 9.0c 2.0 1.1 X1950 XTX 650 MHz – 2 GHz 256 bits 64 GB/s 48 9.0c 2.0 1.1 AIW HD 722 MHz – 1.118 MHz 128 bits 19 GB/s 120 10.1 3.3 2.0 HD 2400 Pro 525 MHz – 800 MHz 64 bits 6,4 GB/s 40 10 3.3 1.1 HD 2400 Pro AGP 525 MHz – 800 MHz 64 bits 6,4 GB/s 40 10 3.3 AGP 8x HD 2400 Pro PCI 525 MHz – 800 MHz 64 bits 6,4 GB/s 40 10 3.3 PCI HD 2400 XT 700 MHz – 1,6 GHz 64 bits 12,8 GB/s 40 10 3.3 1.1 HD 2600 Pro 600 MHz – 1 GHz 128 bits 16 GB/s 120 10 3.3 1.1 HD 2600 Pro AGP 594 MHz – 792 MHz 128 bits 12,8 GB/s 120 10 3.3 AGP 8x HD 2600 XT GDDR3 800 MHz – 1,4 GHz 128 bits 22,4 GB/s 120 10.1 3.3 1.1 HD 2600 XT GDDR4 800 MHz – 2,2 GHz 128 bits 35,2 GB/s 120 10.1 3.3 1.1 HD 2600 XT AGP DDR2 722 MHz – 810 MHz 128 bits 12,96 GB/s 120 10.1 3.3 AGP 8x HD 2600 XT AGP GDDR3 800 MHz – 1,6 GHz 128 bits 25,6 GB/s 120 10.1 3.3 AGP 8x HD 2900 GT 600 MHz – 1,6 GHz 256 bits 51,2 GB/s 240 10 3.3 1.1 HD 2900 Pro 600 MHz – 1,85 GHz 512 bits 118,4 GB/s 320 10 3.3 1.1 HD 2900 XT GDDR3 740 MHz – 1,65 GHz 512 bits 105,6 GB/s 320 10 3.3 1.1 HD 2900 XT GDDR4 740 MHz – 2 GHz 512 bits 128 GB/s 320 10 3.3 1.1 HD 3450 600 MHz – 1 GHz 64 bits 8 GB/s 40 10.1 3.3 2.0 HD 3450 AGP 600 MHz – 1 GHz 64 bits 8 GB/s 40 10.1 3.3 AGP 8x HD 3450 PCI 600 MHz – 800 MHz 64 bits 6,4 GB/s 40 10.1 3.3 PCI HD 3470 800 MHz – 1,9 GHz 64 bits 15,2 GB/s 40 10.1 3.3 2.0 HD 3650 725 MHz – 1,6 GHz 128 bits 25,6 GB/s 120 10.1 3.3 2.0 HD 3650 AGP 725 MHz – 1 GHz 128 bits 16 GB/s 120 10.1 3.3 AGP 8x HD 3690 668 MHz – 1.656 MHz 128 bits 26,5 GB/s 120 10.1 3.3 2.0 HD 3850 668 MHz – 1,66 GHz 256 bits 53,12 GB/s 320 10.1 3.3 2.0 HD 3850 AGP 668 MHz – 1.656 MHz 256 bits 53 GB/s 320 10.1 3.3 AGP 8x HD 3850 X2† 669 MHz – 1.656 MHz 256 bits 53 GB/s 320 10.1 3.3 AGP 8x HD 3870 775 MHz – 2,25 GHz 256 bits 72 GB/s 320 10.1 3.3 2.0 HD 3870 X2† 825 MHz – 1,8 GHz 256 bits 57,6 GB/s 320 10.1 3.3 2.0 HD 4350 600 MHz – 1 GHz 64 bits 8 GB/s 80 10.1 3.3 2.0 HD 4550 800 MHz – 1.6 GHz 64 bits 12,8 GB/s 80 10.1 3.3 2.0 HD 4650 600 MHz – 1 GHz 128 bits 16 GB/s 320 10.1 3.3 2.0 HD 4650 600 MHz – 1,4 GHz 128 bits 22,4 GB/s 320 10.1 3.3 2.0 HD 4650 AGP 600 MHz – 800 MHz 128 bits 12,8 GB/s 320 10.1 3.3 AGP 8x HD 4670 512 MB 750 MHz – 2 GHz 128 bits 32 GB/s 320 10.1 3.3 2.0 HD 4670 1GB 750 MHz – 1.746 MHz 128 bits 27,94 GB/s 320 10.1 3.3 2.0 HD 4670 AGP 750 MHz – 1,6 GHz 128 bits 25,6 GB/s 320 10.1 3.3 AGP 8x HD 4730 750 MHz – 1,8 GHz 128 bits 28,8 GB/s 640 10.1 3.3 2.0 HD 4770 750 MHz – 3,2 GHz 128 bits 51,2 GB/s 640 10.1 3.3 2.0 HD 4830 575 MHz – 1,8 GHz 256 bits 57,6 GB/s 640 10.1 3.3 2.0 HD 4850 625 MHz – 2 GHz 256 bits 64 GB/s 800 10.1 3.3 2.0 HD 4850 X2† 625 MHz – 2 GHz 256 bits 64 GB/s 800 10.1 3.3 2.0 HD 4870 750 MHz – 3,6 GHz 256 bits 115,2 GB/s 800 10.1 3.3 2.0 HD 4870 X2† 750 MHz – 3,6 GHz 256 bits 115,2 GB/s 800 10.1 3.3 2.0 HD 4890 850 MHz – 3,9 GHz 256 bits 124,8 GB/s 800 10.1 3.3 2.0 HD 5450 DDR2 650 MHz – 800 MHz 64 bits 6,4 GB/s 80 11 4.4 2.0 HD 5450 DDR3 650 MHz – 1,6 GHz 64 bits 12,8 GB/s 80 11 4.4 2.0 HD 5550 550 MHz – * 128 bits * 320 11 4.4 2.0 HD 5570 650 MHz – 1.8 GHz 128 bits 28,8 GB/s 400 11 4.4 2.0 HD 5670 775 MHz – 4 GHz 128 bits 64 GB/s 400 11 4.4 2.0 HD 5750 705 MHz – 4.6 GHz 128 bits 73,6 GB/s 720 11 4.4 2.0 HD 5770 850 MHz – 4,8 GHz 128 bits 76,8 GB/s 800 11 4.4 2.0 HD 5830 800 MHz – 4 GHz 256 bits 128 GB/s 1.120 11 4.4 2.0 HD 5850 725 MHz – 4 GHz 256 bits 128 GB/s 1.440 11 4.4 2.0 HD 5870 850 MHz – 4,8 GHz 256 bits 153,6 GB/s 1.600 11 4.4 2.0 HD 5970† 725 MHz – 4 GHz 256 bits 128 GB/s 1.600 11 4.4 2.0 HD 6350 650 MHz – 1,6 GHz 64 bits 12,8 GB/s 80 11 4.4 2.0 HD 6390 550 MHz – * 128 bits * 320 11 4.4 2.0 HD 6450 * – * 64 bits * 160 11 4.4 2.0 HD 6570 DDR3 650 MHz – 1,8 GHz 128 bits 28,8 GB/s 480 11 4.4 2.0 HD 6570 GDDR5 650 MHz – 4 GHz 128 bits 64 GB/s 480 11 4.4 2.0 HD 6670 800 MHz – 4 GHz 128 bits 64 GB/s 480 11 4.4 2.0 HD 6750 705 MHz – 4,6 GHz 128 bits 73,6 GB/s 720 11 4.4 2.0 HD 6770 850 MHz – 4,8 GHz 128 bits 76,8 GB/s 800 11 4.4 2.0 HD 6790 840 MHz – 4,2 GHz 256 bits 134,4 GB/s 800 11 4.4 2.0 HD 6850 775 MHz – 4 GHz 256 bits 128 GB/s 960 11 4.4 2.0 HD 6870 900 MHz – 4,2 GHz 256 bits 134,4 GB/s 1.120 11 4.4 2.0 HD 6950 800 MHz – 5 GHz 256 bits 160 GB/s 1.408 11 4.4 2.0 HD 6970 880 MHz – 5,5 GHz 256 bits 176 GB/s 1.536 11 4.4 2.0 HD 6990† 830 MHz – 5 GHz 256 bits 160 GB/s 1.536 11 4.4 2.0 HD 7730 800 MHz – 4,5 GHz 128 bits 72 GB/s 384 11.1 4.6 3.0 HD 7750 800 MHz – 4,5 GHz 128 bits 72 GB/s 512 11.1 4.6 3.0 HD 7770 1.000 MHz – 4,5 GHz 128 bits 72 GB/s 640 11.1 4.6 3.0 HD 7790 1.000 MHz – 6 GHz 128 bits 96 GB/s 896 11.1 4.6 3.0 HD 7850 860 MHz – 4,8 GHz 256 bits 153,6 GB/s 1.024 11.1 4.6 3.0 HD 7870 1.000 MHz – 4,8 GHz 256 bits 153,6 GB/s 1.280 11.1 4.6 3.0 HD 7950 800 MHz – 5 GHz 384 bits 240 GB/s 1.792 11.1 4.6 3.0 HD 7950 Boost 850 MHz 925 MHz 5 GHz 384 bits 240 GB/s 1.792 11.1 4.6 3.0 HD 7970 925 MHz – 5,5 GHz 384 bits 264 GB/s 2.048 11.1 4.6 3.0 HD 7970 GHz Edition 1.000 MHz – 6 GHz 384 bits 288 GB/s 2.048 11.1 4.6 3.0 HD 7990† 1.000 MHz – 6 GHz 384 bits 288 GB/s 2.048 11.1 4.6 3.0 HD 8350 400 MHz – 1,8 GHz 64 bits 28,8 GB/s 80 11 4.4 2.0 HD 8470 775 MHz – 3,2 GHz 64 bits 25,6 GB/s 160 11 4.4 2.0 HD 8490 875 MHz – 1,8 GHz 64 bits 14,4 GB/s 160 11 4.4 2.0 x16 HD 8570 1 GB 650 MHz – 1,6 GHz 128 bits 25,6 GB/s 480 11 4.4 2.0 x16 HD 8570 2 GB 730 MHz 780 MHz 1,8 GHz 128 bits 28,8 GB/s 320 11.1 4.6 3.0 x8 HD 8670 1.000 MHz 1.050 MHz 4,6 GHz 128 bits 73,6 GB/s 384 11.1 4.6 3.0 x8 HD 8760 1.000 MHz – 4,5 GHz 128 bits 72 GB/s 640 11.1 4.6 3.0 HD 8870 1.000 MHz – 4,8 GHz 256 bits 153,6 GB/s 1.280 11.1 4.6 3.0 HD 8950 850 MHz 925 MHz 5 GHz 384 bits 240 GB/s 1.792 11.1 4.6 3.0 HD 8970 1.000 MHz 1.050 MHz 6 GHz 384 bits 288 GB/s 2.048 11.1 4.6 3.0 R5 220 650 MHz – 1.066 MHz 64 bits 8,53 GB/s 80 11 4.4 2.0 R5 230 650 MHz – 1.066 MHz 64 bits 8,53 GB/s 160 11 4.4 2.0 R5 235 775 MHz – 1,8 GHz 64 bits 14,4 GB/s 160 11 4.4 2.0 R5 235X 875 MHz – 1,8 GHz 64 bits 14,4 GB/s 160 11 4.4 2.0 R5 240 730 MHz 780 MHz 1,8 GHz 128 bits 28,8 GB/s 320 11.1 4.6 3.0 x8 R7 240 DDR3 730 MHz 780 MHz 1,8 GHz 128 bits 28,8 GB/s 320 11.1 4.6 3.0 R7 240 GDDR5 730 MHz 780 MHz 4,6 GHz 128 bits 73,6 GB/s 320 11.1 4.6 3.0 R7 250 DDR3 1.000 MHz 1.050 MHz 1,8 GHz 128 bits 28,8 GB/s 384 11.1 4.6 3.0 x16 R7 250 GDDR5 1.000 MHz 1.050 MHz 4,6 GHz 128 bits 73,6 GB/s 384 11.1 4.6 3.0 x8 R7 250E 800 MHz – 4,5 GHz 128 bits 72 GB/s 512 11.1 4.6 3.0 R7 250X DDR3 1 GHz – * 128 bits * 640 11.1 4.6 3.0 R7 250X GDDR5 950 MHz 1.125 MHz 4,5 GHz 128 bits 72 GB/s 640 11.1 4.6 3.0 R7 250XE 860 MHz 1.125 MHz 4,5 GHz 128 bits 72 GB/s 640 11.1 4.6 3.0 R7 260 1.000 MHz – 6 GHz 128 bits 96 GB/s 768 12 4.6 3.0 R7 260X 1.100 MHz – 6,5 GHz 128 bits 104 GB/s 896 12 4.6 3.0 R7 265 900 MHz 925 MHz 5,6 GHz 256 bits 179,2 GB/s 1.024 11.1 4.6 3.0 R7 265X 900 MHz 925 MHz 5,6 GHz 256 bits 179,2 GB/s 1.280 11.1 4.6 3.0 R9 255 930 MHz – 6,5 GHz 128 bits 104 GB/s 512 11.1 4.6 3.0 R9 260 1.100 MHz – 6,5 GHz 128 bits 104 GB/s 896 12 4.6 3.0 R9 270 900 MHz 925 MHz 5,6 GHz 256 bits 179,2 GB/s 1.280 11.1 4.6 3.0 R9 270X 1.000 MHz 1.050 MHz 5,6 GHz 256 bits 179,2 GB/s 1.280 11.1 4.6 3.0 R9 280 827 MHz 933 MHz 5 GHz 384 bits 240 GB/s 1.792 11.1 4.6 3.0 R9 280X 850 MHz 1 GHz 6 GHz 384 bits 288 GB/s 2.048 11.1 4.6 3.0 R9 285 918 MHz – 5,5 GHz 256 bits 176 GB/s 1.792 12 4.6 3.0 R9 290 662 MHz 947 MHz 5 GHz 512 bits 320 GB/s 2.560 12 4.6 3.0 R9 290X 800 MHz 1.000 MHz 5 GHz 512 bits 320 GB/s 2.816 12 4.6 3.0 R9 295X2† 1.018 MHz – 5 GHz 512 bits 320 GB/s 2.816 12 4.6 3.0 R5 330 OEM 833 MHz 855 MHz 1,8 GHz 128 bits 28,8 GB/s 320 12 4.6 3.0 x8 R5 340 OEM 800 MHz 825 MHz 4,5 GHz 128 bits 72 GB/s 384 12 4.6 3.0 x8 R7 340 OEM 730 MHz 780 MHz 1,8 GHz 128 bits 28,8 GB/s 384 12 4.6 3.0 x8 R7 350 OEM 1.000 MHz 1.050 MHz 4,5 GHz 128 bits 72 GB/s 384 12 4.6 3.0 x8 R7 360 1.000 MHz 1.050 MHz 6,5 GHz 128 bits 104 GB/s 768 12 4.6 3.0 R7 370 925 MHz 975 MHz 5,6 GHz 256 bits 179,2 GB/s 1.024 12 4.6 3.0 R9 360 OEM 1 GHz 1.050 MHz 6,5 GHz 128 bits 104 GB/s 768 12 4.6 3.0 R9 370 OEM 925 MHz 975 MHz 5,6 GHz 256 bits 179,2 GB/s 1.024 12 4.6 3.0 R9 370X 980 MHz 1.030 MHz 5,6 GHz 256 bits 179,2 GB/s 1.280 12 4.6 3.0 R9 380 OEM 918 MHz – 5,5 GHz 256 bits 176 GB/s 1.792 12 4.6 3.0 R9 380 970 MHz – 5,5 GHz 256 bits 176 GB/s 1.792 12 4.6 3.0 R9 380X 970 MHz – 5,7 GHz 256 bits 182,4 GB/s 2.048 12 4.6 3.0 R9 390 1.000 MHz – 6 GHz 512 bits 384 GB/s 2.560 12 4.6 3.0 R9 390X 1.050 MHz – 6 GHz 512 bits 384 GB/s 2.816 12 4.6 3.0 Fury 1.000 MHz – 1 GHz 4.096 bits 512 GB/s 3.584 12 4.6 3.0 R9 Nano 1.000 MHz – 1 GHz 4.096 bits 512 GB/s 4.096 12 4.6 3.0 Fury X 1.050 MHz – 1 GHz 4.096 bits 512 GB/s 4.096 12 4.6 3.0 RX 460 1.090 MHz 1.200 MHz 7 GHz 128 bits 112 GB/s 896 12 4.6 3.0 RX 470 926 MHz 1.206 MHz 6,6 GHz 256 bits 211 GB/s 2.048 12 4.6 3.0 RX 480 1.120 MHz 1.266 MHz 8 GHz 256 bits 256 GB/s 2.304 12 4.6 3.0 RX 550 1.100 MHz 1.183 MHz 7 GHz 128 bits 112 GB/s 512 12 4.6 3.0 RX 560 1.175 MHz 1.275 MHz 7 GHz 128 bits 112 GB/s 1.024 12 4.6 3.0 RX 560D 1.090 MHz 1.175 MHz 6 GHz 128 bits 96 GB/s 896 12 4.6 3.0 x8 RX 570 1.168 MHz 1.244 MHz 7 GHz 256 bits 224 GB/s 2.048 12 4.6 3.0 x16 RX 580 2048SP 1,168 MHz 1.284 MHz 7 GHz 256 bits 224 GB/s 2.048 12 4.6 3.0 x16 RX 580 1.257 MHz 1.340 MHz 8 GHz 256 bits 256 GB/s 2.304 12 4.6 3.0 RX 590 1.469 MHz 1.545 MHz 8 GHz 256 bits 256 GB/s 2.304 12 4.6 3.0 RX Vega 56 1.156 MHz 1.471 MHz 1,6 GHz 2.048 bits 409,6 GB/s 3.584 12 4.6 3.0 RX Vega 64 1.247 MHz 1.546 MHz 1,89 GHz 2.048 bits 483,8 GB/s 4.096 12 4.6 3.0 RX Vega 64 Liquid 1.406 MHz 1.677 MHz 1,89 GHz 2.048 bits 483,8 GB/s 4.096 12 4.6 3.0 VII 1.400 MHz 1.750 MHz 4 GHz 4.096 bits 1.024 GB/s 3.840 12 4.6 3.0 RX 5500 1.670 MHz 1.750 MHz 14 GHz 128 bits 224 GB/s 1.408 12 4.6 4.0 RX 5500 XT 1.607 MHz 1.845 MHz 14 GHz 128 bits 224 GB/s 1.408 12 4.6 4.0 RX 5600 1.375 MHz 1.725 MHz 12 GHz 192 bits 288 GB/s 2.048 12 4.6 4.0 RX 5600 XT 1.375 MHz 1.560 MHz 12 GHz 192 bits 288 GB/s 2.304 12 4.6 4.0 RX 5700 1.465 MHz 1.725 MHz 14 GHz 256 bits 448 GB/s 2.304 12 4.6 4.0 RX 5700 XT 1.605 MHz 1.905 MHz 14 GHz 256 bits 448 GB/s 2.560 12 4.6 4.0 RX 5700 XT 50th Anniversary 1.680 MHz 1.980 MHz 14 GHz 256 bits 448 GB/s 2.560 12 4.6 4.0 RX 6400 1.923 MHz 2.321 MHz 16 GHz 64 bits 128 GB/s 768 12.2 4.6 4.0 x4 RX 6500 XT 2.200 MHz 2.815 MHz 18 GHz 64 bits 144 GB/s 1.024 12.2 4.6 4.0 x8 RX 6600 1.626 MHz 2.491 MHz 14 GHz 128 bits 224 GB/s 1.792 12.2 4.6 4.0 x8 RX 6600 XT 1.968 MHz 2.589 MHz 16 GHz 128 bits 256 GB/s 2.048 12.2 4.6 4.0 x8 RX 6650 XT 2.055 MHz 2.635 MHz 17,5 GHz 128 bits 280 GB/s 2.048 12.2 4.6 4.0 x8 RX 6700 1.941 MHz 2.450 MHz 16 GHz 160 bits 320 GB/s 2.304 12.2 4.6 4.0 x16 RX 6700 XT 2.321 MHz 2.581 MHz 16 GHz 192 bits 384 GB/s 2.560 12.2 4.6 4.0 RX 6750 XT 2.150 MHz 2.600 MHz 18 GHz 192 bits 432 GB/s 2.560 12.2 4.6 4.0 RX 6800 1.815 MHz 2.105 MHz 16 GHz 256 bits 512 GB/s 3.840 12.2 4.6 4.0 RX 6800 XT 2.015 MHz 2.250 MHz 16 GHz 256 bits 512 GB/s 4.608 12.2 4.6 4.0 RX 6900 XT 2.015 MHz 2.250 MHz 16 GHz 256 bits 512 GB/s 5.120 12.2 4.6 4.0 RX 6950 XT 1.890 MHz 2.310 MHz 18 GHz 256 bits 576 GB/s 5.120 12.2 4.6 4.0 RX 7600 1.720 MHz 2.655 MHz 18 GHz 128 bits 288 GB/s 2.048 12.2 4.6 4.0 x8 RX 7600 XT 1.980 MHz 2.755 MHz 18 GHz 128 bits 288 GB/s 2.048 12.2 4.6 4.0 x8 RX 7700 XT 1.900 MHz 2.544 MHz 18 GHz 192 bits 432 GB/s 3.456 12.2 4.6 4.0 x16 RX 7800 XT 1.800 MHz 2.430 MHz 19,5 GHz 256 bits 624 GB/s 3.840 12.2 4.6 4.0 x16 RX 7900 GRE 1.270 MHz 2.245 MHz 18 GHz 256 bits 576 GB/s 5.120 12.2 4.6 4.0 x16 RX 7900 XT 1.500 MHz 2.400 MHz 20 GHz 320 bits 800 GB/s 5.376 12.2 4.6 4.0 x16 RX 7900 XTX 1.900 MHz 2.500 MHz 20 GHz 384 bits 960 GB/s 6.144 12.2 4.6 4.0 x16 RX 9060 XT 1.700 MHz 3.130 MHz 20 GHz 128 bits 320 GB/s 2.048 12.2 4.6 5.0 x16 RX 9070 1.330 MHz 2.520 MHz 20 GHz 256 bits 640 GB/s 3.584 12.2 4.6 5.0 x16 RX 9070 XT 1.660 MHz 2.970 MHz 20 GHz 256 bits 640 GB/s 4.096 12.2 4.6 5.0 x16 * A AMD não determina um clock padrão para esta placa de vídeo; as especificações dependem do fabricante da placa. Por isso, tome cuidado na hora de comparar placas de vídeo usando esse chip. † Esta placa de vídeo tem dois chips gráficos trabalhando em paralelo (CrossFire). Os dados publicados são para apenas um dos chips. Fabricantes podem usar outros clocks de memória nos modelos da série HD 2400 e HD 2600, normalmente mais baixos e, portanto, atingindo desempenho inferior ao modelo padrão. Os clocks listados são os clocks oficiais. Na próxima página, falaremos sobre a potência máxima dissipada (TDP) e a potência mínima de fonte de alimentação recomendada para cada placa de vídeo. Abaixo nós listamos a potência mínima recomendada para a fonte de alimentação para cada placa de vídeo, de acordo com a AMD. Chips que não estão listados significa que a AMD não publica essas especificações para eles. É importante notar que todos os valores são “para a pior das hipóteses”. Em condições normais de uso um chip gráfico consumirá menos do que está publicado na tabela. O mesmo vale para a fonte de alimentação mínima, onde a AMD adiciona uma “margem de segurança”, levando em conta que a fonte é rotulada com sua potência de pico e não com a sua potência máxima em modo contínuo. Chip gráfico Consumo máx. Fonte mínima Radeon 23 W N/D Radeon PCI 23 W N/D Radeon DDR 23 W N/D Radeon VE 23 W N/D Radeon VE PCI 23 W N/D Radeon 7000 23 W N/D Radeon 7200 23 W N/D Radeon 7500 23 W N/D Radeon 7500 LE 23 W N/D Radeon 8500 23 W N/D Radeon 8500 23 W N/D Radeon 8500 23 W N/D Radeon 8500 LE 23 W N/D Radeon 8500 XT 25 W N/D Radeon 9000 28 W N/D Radeon 9000 LE 28 W N/D Radeon 9000 Pro 28 W N/D Radeon 9100 28 W N/D Radeon 9100 PCI 28 W N/D Radeon HD 2400 Pro 20 W ND Radeon HD 2600 Pro 35 W ND Radeon HD 2600 XT 45 W ND Radeon HD 3450 25 W 550 W (750 W para CrossFire) Radeon HD 3470 30 W 550 W (750 W para CrossFire) Radeon HD 3650 65 W 400 W (550 W para CrossFire) Radeon HD 3690 75 W 400 W (550 W para CrossFire) Radeon HD 3850 75 W 550 W (750 W para CrossFire) Radeon HD 3870 106 W 550 W (750 W para CrossFire) Radeon HD 4350 20 W 300 W (350 W para CrossFire Radeon HD 4550 25 W 300 W (350 W para CrossFire) Radeon HD 4650 48 W 400 W (550 W para CrossFire) Radeon HD 4670 59 W 400 W (550 W para CrossFire) Radeon HD 4830 95 W 450 W (550 W para CrossFire) Radeon HD 4850 110 W 450 W (550 W para CrossFire) Radeon HD 4870 150 W 500 W (600 W para CrossFire) Radeon HD 4890 190 W 500 W (600 W para CrossFire) Radeon HD 5450 19 W 400 W Radeon HD 5550 39 W 400 W Radeon HD 5570 39 W 400 W Radeon HD 5670 64 W 400 W (500 W para CrossFire) Radeon HD 5750 86 W 450 W (600 W para CrossFire) Radeon HD 5770 108 W 450 W (600 W para CrossFire) Radeon HD 5830 175 W 500 W (600 W para CrossFire) Radeon HD 5850 151 W 500 W (600 W para CrossFire) Radeon HD 5870 188 W 500 W (600 W para CrossFire) Radeon HD 5970 294 W 650 W (850 W para CrossFire) Radeon HD 6450 18 W 400 W (500 W para CrossFire) Radeon HD 6570 60 W 400 W (500 W para CrossFire) Radeon HD 6670 66 W 400 W (500 W para CrossFire) Radeon HD 6750 86 W 450 W (600 W para CrossFire) Radeon HD 6770 108 W 450 W (600 W para CrossFire) Radeon HD 6790 150 W 500 W (600 W para CrossFire) Radeon HD 6850 127 W 500 W Radeon HD 6870 151 W 500 W (600 W para CrossFire) Radeon HD 6950 200 W 500 W Radeon HD 6970 250 W 550 W Radeon HD 6990 375 W 750 W (1,000 W para CrossFire) Radeon HD 7730 47 W 400 W (500 W para CrossFire) Radeon HD 7750 55 W 500 W (600 W para CrossFire) Radeon HD 7770 80 W 500 W (600 W para CrossFire) Radeon HD 7790 85 W 500 W (600 W para CrossFire) Radeon HD 7850 130 W 500 W (600 W para CrossFire) Radeon HD 7870 175 W 500 W (600 W para CrossFire) Radeon HD 7950 200 W 500 W Radeon HD 7970 250 W 500 W Radeon HD 7970 GHz Edition 300 W 500 W (850 W para CrossFire) Radeon HD 7990 375 W 750 W (1.000 W para CrossFire) Radeon HD 8350 25 W N/D Radeon HD 8470 25 W 200 W Radeon HD 8490 35 W 200 W Radeon HD 8570 DDR3 50 W N/D Radeon HD 8570 GDDR3 60 W N/D Radeon HD 8670 75 W N/D Radeon HD 8760 110 W N/D Radeon HD 8870 175 W N/D Radeon HD 8950 200 W 500 W (750 W para CrossFire) Radeon HD 8970 250 W 500 W (850 W para CrossFire) Radeon R5 220 19 W N/D Radeon R5 230 19 W N/D Radeon R5 235 35 W N/D Radeon R5 235X 18 W N/D Radeon R5 240 50 W N/D Radeon R7 240 50 W N/D Radeon R7 250 65 W N/D Radeon R7 250E 55 W N/D Radeon R7 250X 80 W N/D Radeon R7 260 95 W N/D Radeon R7 260X 115 W N/D Radeon R7 265 150 W N/D Radeon R7 265X 150 W N/D Radeon R9 260 85 W N/D Radeon R9 270 175 W N/D Radeon R9 270X 180 W N/D Radeon R8 250 W N/D Radeon R9 280X 250 W N/D Radeon R9 285 190 W N/D Radeon R9 290 275 W N/D Radeon R9 290X 290 W N/D Radeon R9 295X2 500 W N/D Radeon R5 330 OEM 50 W N/D Radeon R5 340 OEM 65 W N/D Radeon R7 340 OEM 50 W N/D Radeon R7 350 OEM 65 W N/D Radeon R7 360 100 W N/D Radeon R7 370 110 W N/D Radeon R9 360 OEM 85 W N/D Radeon R9 370 OEM 150 W N/D Radeon R9 380 OEM 190 W N/D Radeon R9 380 190 W N/D Radeon R9 390 275 W N/D Radeon R9 390X 275 W N/D Radeon R9 Fury 275 W N/D Radeon R9 Nano 175 W N/D Radeon R9 Fury X 275 W N/D Radeon RX 460 75 W N/D Radeon RX 470 120 W N/D Radeon RX 480 150 W N/D Radeon RX 550 50 W 400 W Radeon RX 560 80 W 450 W Radeon RX 560D 65 W 450 W Radeon RX 570 150 W 450 W Radeon RX 580 2048SP 150 W 450 W Radeon RX 580 185 W 500 W Radeon RX 590 175 W 500 W Radeon RX Vega 56 210 W 650 W Radeon RX Vega 64 295 W 750 W Radeon RX Vega 64 Liquid 345 W 1.000 W Radeon VII 300 W 750 W Radeon RX 5500 150 W 550 W Radeon RX 5500 XT 130 W 450 W Radeon RX 5600 150 W 500 W Radeon RX 5600 XT 150 W 500 W Radeon RX 5700 180 W 600 W Radeon RX 5700 XT 235 W 600 W Radeon RX 5700 50th Anniversary 235 W 600 W Radeon RX 6400 53 W 350 W Radeon RX 6500 XT 107 W 400 W Radeon RX 6600 132 W 450 W Radeon RX 6600 XT 160 W 500 W Radeon RX 6650 XT 180 W 500 W Radeon RX 6700 175 W 600 W Radeon RX 6700 XT 230 W 550 W Radeon RX 6750 XT 250 W 650 W Radeon RX 6800 250 W 650 W Radeon RX 6800 XT 300 W 750 W Radeon RX 6900 XT 300 W 850 W Radeon RX 6950 XT 335 W 850 W Radeon RX 7600 165 W 550 W Radeon RX 7600 XT 190 W 600 W Radeon RX 7900 GRE 260 W 700 W Radeon RX 7700 XT 245 W 700 W Radeon RX 7800 XT 263 W 700 W Radeon RX 7900 XT 300 W 750 W Radeon RX 7900 XTX 355 W 800 W Radeon RX 7800 XT 263 W 700 W Radeon RX 7900 XT 300 W 750 W Radeon RX 7900 XTX 355 W 800 W Radeon RX 7800 XT 263 W 700 W Radeon RX 9060 XT 160 W 450 W Radeon RX 9070 220 W 650 W Radeon RX 9070 XT 304 W 750 W
Com mais e mais chips gráficos sendo lançados a cada dia, torna-se bastante complicado para os usuários que não acompanham o mercado de placas de vídeo saber as diferenças entre todos os chips gráficos da AMD existentes no mercado hoje. Para facilitar a compreensão e saber a diferença entre estes chips, compilamos a tabela abaixo. Para chips gráficos da AMD para computadores portáteis, veja a nossa “Tabela comparativa os chips Radeon da AMD (notebooks)”. Para chips gráficos da NVIDIA para computadores de mesa, veja a nossa “Tabela comparativa dos chips GeForce da NVIDIA (desktop)”. Em 2010 a AMD, empresa que comprou a ATI em 2006, parou de usar a marca “ATI”. GPU Memória GPU API GPU Radeon Clock Clock Boost Clock Interface Largura Banda Proc. DirectX OpenGL PCIe AIW 128 90 MHz – 90 MHz 128 bits 1,440 GB/s 4 6.0 1.2 PCI Rage 128 PRO 118 MHz – 143 MHz 64 bits 1,144 GB/s 2 6.0 1.2 AGP 4x AIW 128 PRO 120 MHz – 120 MHz 128 bits 1,920 GB/s 4 6.0 1.2 AGP 4x Rage 128 PRO Ultra 130 MHz – 130 MHz 64 bits 1,040 GB/s 2 6.0 1.2 AGP 4x Rage 128 Ultra 119 MHz – 119 MHz 64 bits 952 MB/s 2 6.0 1.2 AGP 4x Rage 128 VR 80 MHz – 125 MHz 64 bits 1 GB/s 2 6.0 1.2 AGP 4x Rage Fury 80 MHz – 120 MHz 64 bits 960 MB/s 2 6.0 1.2 AGP 4x Rage Fury MAXX† 125 MHz – 143 MHz 64 bits 1,144 GB/s 2 6.0 1.2 AGP 4x Radeon 166 MHz – 166 MHz 128 bits 2,656 GB/s 2 7.0 1.3 AGP 4x PCI 166 MHz – 166 MHz 128 bits 2,656 GB/s 2 7.0 1.3 PCI DDR 166 MHz – 332 MHz 128 bits 5,312 GB/s 2 7.0 1.3 AGP 4x DDR VIVO 183 MHz – 366 MHz 128 bits 5,856 GB/s 2 7.0 1.3 AGP 4x DDR VIVO OEM 166 MHz – 332 MHz 128 bits 5,312 GB/s 2 7.0 1.3 AGP 4x DDR VIVO SE 187 MHz – 360 MHz 128 bits 5,760 GB/s 2 7.0 1.3 AGP 4x LE 148 MHz – 296 MHz 128 bits 4,736 GB/s 2 7.0 1.3 AGP 4x VE 183 MHz – 366 MHz 64 bits 2,928 GB/s 1 7.0 1.3 AGP 4x VE PCI 183 MHz – 366 MHz 64 bits 2,928 GB/s 1 7.0 1.3 PCI AIW VE 260 MHz – 500 MHz 128 bits 8 GB/s 2 8.1 1.3 PCI 7000 183 MHz – 366 MHz 64 bits 2,928 GB/s 1 7.0 1.3 AGP 4x 7000 PCI 133 MHz – 266 MHz 64 bits 2,128 GB/s 1 7.0 1.3 PCI 7200 SDRAM 143 MHz – 143 MHz 128 bits 2,288 GB/s 2 7.0 1.3 AGP 4x 7200 DDR 166 MHz – 332 MHz 128 bits 5,312 GB/s 2 7.0 1.3 AGP 4x AIW 7200 166 MHz – 332 MHz 128 bits 5,312 GB/s 2 7.0 1.3 PCI 7500 290 MHz – 460 MHz 128 bits 7,36 GB/s 2 8.1 1.3 AGP 4x AIW 7500 260 MHz – 360 MHz 128 bits 5,76 GB/s 2 8.1 1.3 PCI 7500 LE 250 MHz – 350 MHz 128 bits 5,6 GB/s 2 8.1 1.3 AGP 4x 8500 275 MHz – 550 MHz 128 bits 8,8 GB/s 4 8.1 1.4 AGP 4x AIW 8500 230 MHz – 380 MHz 128 bits 6,08 GB/s 4 8.1 1.4 AGP 8x AIW 8500DV 230 MHz – 380 MHz 128 bits 6,08 GB/s 4 8.1 1.4 AGP 8x 8500 LE 250 MHz – 500 MHz 128 bits 8 GB/s 4 8.1 1.4 AGP 4x 8500 XT 300 MHz – 600 MHz 128 bits 9,6 GB/s 4 8.1 1.4 AGP 4x 9000 250 MHz – 400 MHz 128 bits 6,4 GB/s 4 8.1 1.4 AGP 4x 9000 LE 250 MHz – 400 MHz 128 bits 6,4 GB/s 4 8.1 1.4 AGP 4x 9000 Pro 275 MHz – 550 MHz 128 bits 8,8 GB/s 4 8.1 1.4 AGP 4x AIW 9000 Pro 275 MHz – 450 MHz 128 bits 7,2 GB/s 4 8.1 1.4 AGP 8x 9100 250 MHz – 500 MHz 128 bits 8 GB/s 4 8.1 1.4 AGP 4x 9100 PCI 250 MHz – 500 MHz 128 bits 8 GB/s 4 8.1 1.4 PCI 9200 250 MHz – 400 MHz 128 bits 6,4 GB/s 4 8.1 1.4 AGP 8x AIW 9200 250 MHz – 400 MHz 128 bits 6,4 GB/s 4 8.1 1.4 AGP 8x 9200 Pro 275 MHz – 550 MHz 128 bits 8,8 GB/s 4 8.1 1.4 AGP 8x 9200 SE 200 MHz – 333 MHz 64 bits 2,6 GB/s 4 8.1 1.4 AGP 8x AIW 9200 LE 250 MHz – 333 MHz 64 bits 2,6 GB/s 4 8.1 1.4 AGP 8x 9250 240 MHz – 400 MHz 128 bits 6,4 GB/s 4 8.1 1.4 AGP 8x 9250 SE 240 MHz – 400 MHz 64 bits 3,2 GB/s 4 8.1 1.4 AGP 8x 9500 275 MHz – 540 MHz 128 bits 8,6 GB/s 4 9.0 2.0 AGP 8x AIW 9500 277 MHz – 540 MHz 128 bits 8,6 GB/s 4 9.0 2.0 AGP 8x 9550 250 MHz – 400 MHz 128 bits 6,4 GB/s 4 9.0 2.0 AGP 8x 9550 SE 250 MHz – 400 MHz 64 bits 3,2 GB/s 4 9.0 2.0 AGP 8x 9500 Pro 275 MHz – 540 MHz 128 bits 8,6 GB/s 8 9.0 2.0 AGP 8x 9600 325 MHz – 400 MHz 128 bits 6,4 GB/s 4 9.0 2.0 AGP 8x AIW 9600 324 MHz – 392 MHz 128 bits 6,272 GB/s 4 9.0 2.0 AGP 8x 9600 Pro 400 MHz – 600 MHz 128 bits 9,6 GB/s 4 9.0 2.0 AGP 8x AIW 9600 Pro 400 MHz – 650 MHz 128 bits 10,4 GB/s 4 9.0 2.0 AGP 8x 9600 SE 325 MHz – 400 MHz 64 bits 3,2 GB/s 4 9.0 2.0 AGP 8x 9600 XT 500 MHz – 600 MHz 128 bits 9,6 GB/s 4 9.0 2.0 AGP 8x AIW 9600 XT 527 MHz – 648 MHz 128 bits 10,37 GB/s 4 9.0 2.0 AGP 8x 9700 275 MHz – 540 MHz 256 bits 17,2 GB/s 8 9.0 2.0 AGP 8x 9700 Pro 325 MHz – 620 MHz 256 bits 19,8 GB/s 8 9.0 2.0 AGP 8x AIW 9700 Pro 325 MHz – 620 MHz 256 bits 19,8 GB/s 8 9.0 2.0 AGP 8x 9800 325 MHz – 580 MHz 256 bits 18,56 GB/s 8 9.0 2.0 AGP 8x 9800 Pro 380 MHz – 680 MHz 256 bits 21,7 GB/s 8 9.0 2.0 AGP 8x AIW 9800 Pro 378 MHz – 676 MHz 256 bits 21,63 GB/s 8 9.0 2.0 AGP 8x 9800 SE 325 MHz – 500 MHz 128 bits 8 GB/s 4 9.0 2.0 AGP 8x 9800 SE 325 MHz – 500 MHz 256 bits 16 GB/s 4 9.0 2.0 AGP 8x AIW 9800 SE 378 MHz – 594 MHz 128 bits 9,504 GB/s 4 9.0 2.0 AGP 8x 9800 XT 412 MHz – 730 MHz 256 bits 23,3 GB/s 8 9.0 2.0 AGP 8x X300 SE 325 MHz – 400 MHz 64 bits 3,2 GB/s 4 9.0 2.0 1.1 X300 325 MHz – 400 MHz 128 bits 6,4 GB/s 4 9.0 2.0 1.1 X550 400 MHz – 500 MHz 64 bits 4 GB/s 4 9.0 2.0 1.1 X550 400 MHz – 500 MHz 128 bits 8 GB/s 4 9.0 2.0 1.1 AIW X600 400 MHz – 600 MHz 128 bits 9,6 GB/s 4 9.0 2.0 1.1 X600 Pro 400 MHz – 600 MHz 128 bits 9,6 GB/s 4 9.0 2.0 1.1 X600 XT 500 MHz – 730 MHz 128 bits 11,68 GB/s 4 9.0 2.0 1.1 X700 400 MHz – 600 MHz 128 bits 9,6 GB/s 8 9.0 2.0 1.1 X700 Pro 420 MHz – 864 MHz 128 bits 13,8 GB/s 8 9.0 2.0 1.1 X700 XT 475 MHz – 1,05 GHz 128 bits 16,8 GB/s 8 9.0 2.0 1.1 X800 SE * – * * * 8 9.0 2.0 1.1 X800 400 MHz – 700 MHz 256 bits 22,4 GB/s 12 9.0 2.0 1.1 AIW X800 500 MHz – 1 GHz 128 bits 16 GB/s 16 9.0b 2.0 AGP 8x AIW X800 VE 425 MHz – 800 MHz 128 bits 12,8 GB/s 8 9.0b 2.0 AGP 8x X800 XL 400 MHz – 1 GHz 256 bits 32 GB/s 16 9.0 2.0 1.1 AIW X800 XL 400 MHz – 980 MHz 256 bits 31,36 GB/s 16 9.0b 2.0 1.1 X800 GT 475 MHz – * 128 bits * 8 9.0 2.0 1.1 X800 GT 475 MHz – * 256 bits * 8 9.0 2.0 1.1 AIW X800 GT 400 MHz – 980 MHz 128 bits 15,68 GB/s 8 9.0b 2.0 1.1 X800 GTO 400 MHz – 1 GHz* 256 bits 32 GB/s 12 9.0 2.0 1.1 X800 Pro 475 MHz – 950 MHz 256 bits 30,4 GB/s 12 9.0 2.0 1.1 X800 XT 500 MHz – 1 GHz 256 bits 32 GB/s 16 9.0 2.0 1.1 AIW X800 XT 500 MHz – 1 GHz 256 bits 32 GB/s 16 9.0b 2.0 AGP 8x X800 XT PE 520 MHz – 1,12 GHz 256 bits 35,8 GB/s 16 9.0 2.0 1.1 X850 Pro 520 MHz – 1,08 GHz 256 bits 34,56 GB/s 12 9.0 2.0 1.1 X850 XT 520 MHz – 1,08 GHz 256 bits 34,56 GB/s 16 9.0 2.0 1.1 X850 PE 540 MHz – 1,18 GHz 256 bits 37,76 GB/s 16 9.0 2.0 1.1 X1050 * – * * * 4 9.0c 2.0 1.1 AIW 2006 AGP Edition 324 MHz – 392 MHz 128 bits 6,272 GB/s 4 9.0 2.0 AGP 8x AIW 2006 PCIe Edition 450 MHz – 800 MHz 128 bits 12,8 GB/s 4 9.0c 2.0 1.1 X1300 HM 450 MHz – 1 GHz 32 bits 4 GB/s 4 9.0c 2.0 1.1 X1300 HM 450 MHz – 1 GHz 64 bits 8 GB/s 4 9.0c 2.0 1.1 X1300 HM 450 MHz – 1 GHz 128 bits 16 GB/s 4 9.0c 2.0 1.1 X1300 450 MHz – 500 MHz 32 bits 2 GB/s 4 9.0c 2.0 1.1 X1300 450 MHz – 500 MHz 64 bits 4 GB/s 4 9.0c 2.0 1.1 X1300 450 MHz – 500 MHz 128 bits 8 GB/s 4 9.0c 2.0 1.1 X1300 Pro 600 MHz – 800 MHz 32 bits 3,2 GB/s 4 9.0c 2.0 1.1 X1300 Pro 600 MHz – 800 MHz 64 bits 6,4 GB/s 4 9.0c 2.0 1.1 X1300 Pro 600 MHz – 800 MHz 128 bits 12,8 GB/s 4 9.0c 2.0 1.1 X1300 XT DDR2 500 MHz – 800 MHz 128 bits 12,8 GB/s 12 9.0c 2.0 1.1 X1300 XT GDDR3 500 MHz – 1 GHz 128 bits 16 GB/s 12 9.0c 2.0 1.1 X1550 500 MHz – 666 MHz 64 bits 5,3 GB/s 4 9.0c 2.0 1.1 x16 X1550 550 MHz – 800 MHz 128 bits 12,8 GB/s 4 9.0c 2.0 1.1 x16 X1550 600 MHz – 800 MHz 128 bits 12,8 GB/s 4 9.0c 2.0 1.1 x16 X1550 AGP 600 MHz – 660 MHz 64 bits 5,28 GB/s 4 9.0c 2.0 AGP 8x X1550 PCI 452 MHz – 532 MHz 64 bits 4,3 GB/s 4 9.0c 2.0 PCI X1600 Pro 500 MHz – 780 MHz 128 bits 12,48 GB/s 12 9.0c 2.0 1.1 X1600 Pro AGP 500 MHz – 780 MHz 128 bits 12,48 GB/s 12 9.0c 2.0 AGP 8x X1600 XT 590 MHz – 1,38 GHz 128 bits 22,08 GB/s 12 9.0c 2.0 1.1 X1650 Pro 600 MHz – 1,4 GHz 128 bits 22,4 GB/s 12 9.0c 2.0 1.1 X1650 XT 575 MHz – 1,35 GHz 128 bits 21,60 GB/s 24 9.0c 2.0 1.1 X1800 GTO 500 MHz – 1 GHz 256 bits 32 GB/s 12 9.0c 2.0 1.1 X1800 XL 500 MHz – 1 GHz 256 bits 32 GB/s 16 9.0c 2.0 1.1 AIW X1800 XL 500 MHz – 1 GHz 256 bits 32 GB/s 16 9.0c 2.0 1.1 X1800 XT 625 MHz – 1,5 GHz 256 bits 48 GB/s 16 9.0c 2.0 1.1 AIW X1900 500 MHz – 954 MHz 256 bits 30,53 GB/s 48 9.0c 2.0 1.1 X1900 GT 575 MHz – 1,2 GHz 256 bits 38,4 GB/s 36 9.0c 2.0 1.1 X1900 XT 625 MHz – 1,45 GHz 256 bits 46,4 GB/s 48 9.0c 2.0 1.1 X1900 XTX 650 MHz – 1,55 GHz 256 bits 49,6 GB/s 48 9.0c 2.0 1.1 X1950 GT 500 MHz – 1,2 GHz 256 bits 38,4 GB/s 36 9.0c 2.0 1.1 X1950 Pro 575 MHz – 1,38 GHz 256 bits 44,16 GB/s 36 9.0c 2.0 1.1 X1950 XT 625 MHz – 1,8 GHz 256 bits 57,6 GB/s 48 9.0c 2.0 1.1 X1950 XTX 650 MHz – 2 GHz 256 bits 64 GB/s 48 9.0c 2.0 1.1 AIW HD 722 MHz – 1.118 MHz 128 bits 19 GB/s 120 10.1 3.3 2.0 HD 2400 Pro 525 MHz – 800 MHz 64 bits 6,4 GB/s 40 10 3.3 1.1 HD 2400 Pro AGP 525 MHz – 800 MHz 64 bits 6,4 GB/s 40 10 3.3 AGP 8x HD 2400 Pro PCI 525 MHz – 800 MHz 64 bits 6,4 GB/s 40 10 3.3 PCI HD 2400 XT 700 MHz – 1,6 GHz 64 bits 12,8 GB/s 40 10 3.3 1.1 HD 2600 Pro 600 MHz – 1 GHz 128 bits 16 GB/s 120 10 3.3 1.1 HD 2600 Pro AGP 594 MHz – 792 MHz 128 bits 12,8 GB/s 120 10 3.3 AGP 8x HD 2600 XT GDDR3 800 MHz – 1,4 GHz 128 bits 22,4 GB/s 120 10.1 3.3 1.1 HD 2600 XT GDDR4 800 MHz – 2,2 GHz 128 bits 35,2 GB/s 120 10.1 3.3 1.1 HD 2600 XT AGP DDR2 722 MHz – 810 MHz 128 bits 12,96 GB/s 120 10.1 3.3 AGP 8x HD 2600 XT AGP GDDR3 800 MHz – 1,6 GHz 128 bits 25,6 GB/s 120 10.1 3.3 AGP 8x HD 2900 GT 600 MHz – 1,6 GHz 256 bits 51,2 GB/s 240 10 3.3 1.1 HD 2900 Pro 600 MHz – 1,85 GHz 512 bits 118,4 GB/s 320 10 3.3 1.1 HD 2900 XT GDDR3 740 MHz – 1,65 GHz 512 bits 105,6 GB/s 320 10 3.3 1.1 HD 2900 XT GDDR4 740 MHz – 2 GHz 512 bits 128 GB/s 320 10 3.3 1.1 HD 3450 600 MHz – 1 GHz 64 bits 8 GB/s 40 10.1 3.3 2.0 HD 3450 AGP 600 MHz – 1 GHz 64 bits 8 GB/s 40 10.1 3.3 AGP 8x HD 3450 PCI 600 MHz – 800 MHz 64 bits 6,4 GB/s 40 10.1 3.3 PCI HD 3470 800 MHz – 1,9 GHz 64 bits 15,2 GB/s 40 10.1 3.3 2.0 HD 3650 725 MHz – 1,6 GHz 128 bits 25,6 GB/s 120 10.1 3.3 2.0 HD 3650 AGP 725 MHz – 1 GHz 128 bits 16 GB/s 120 10.1 3.3 AGP 8x HD 3690 668 MHz – 1.656 MHz 128 bits 26,5 GB/s 120 10.1 3.3 2.0 HD 3850 668 MHz – 1,66 GHz 256 bits 53,12 GB/s 320 10.1 3.3 2.0 HD 3850 AGP 668 MHz – 1.656 MHz 256 bits 53 GB/s 320 10.1 3.3 AGP 8x HD 3850 X2† 669 MHz – 1.656 MHz 256 bits 53 GB/s 320 10.1 3.3 AGP 8x HD 3870 775 MHz – 2,25 GHz 256 bits 72 GB/s 320 10.1 3.3 2.0 HD 3870 X2† 825 MHz – 1,8 GHz 256 bits 57,6 GB/s 320 10.1 3.3 2.0 HD 4350 600 MHz – 1 GHz 64 bits 8 GB/s 80 10.1 3.3 2.0 HD 4550 800 MHz – 1.6 GHz 64 bits 12,8 GB/s 80 10.1 3.3 2.0 HD 4650 600 MHz – 1 GHz 128 bits 16 GB/s 320 10.1 3.3 2.0 HD 4650 600 MHz – 1,4 GHz 128 bits 22,4 GB/s 320 10.1 3.3 2.0 HD 4650 AGP 600 MHz – 800 MHz 128 bits 12,8 GB/s 320 10.1 3.3 AGP 8x HD 4670 512 MB 750 MHz – 2 GHz 128 bits 32 GB/s 320 10.1 3.3 2.0 HD 4670 1GB 750 MHz – 1.746 MHz 128 bits 27,94 GB/s 320 10.1 3.3 2.0 HD 4670 AGP 750 MHz – 1,6 GHz 128 bits 25,6 GB/s 320 10.1 3.3 AGP 8x HD 4730 750 MHz – 1,8 GHz 128 bits 28,8 GB/s 640 10.1 3.3 2.0 HD 4770 750 MHz – 3,2 GHz 128 bits 51,2 GB/s 640 10.1 3.3 2.0 HD 4830 575 MHz – 1,8 GHz 256 bits 57,6 GB/s 640 10.1 3.3 2.0 HD 4850 625 MHz – 2 GHz 256 bits 64 GB/s 800 10.1 3.3 2.0 HD 4850 X2† 625 MHz – 2 GHz 256 bits 64 GB/s 800 10.1 3.3 2.0 HD 4870 750 MHz – 3,6 GHz 256 bits 115,2 GB/s 800 10.1 3.3 2.0 HD 4870 X2† 750 MHz – 3,6 GHz 256 bits 115,2 GB/s 800 10.1 3.3 2.0 HD 4890 850 MHz – 3,9 GHz 256 bits 124,8 GB/s 800 10.1 3.3 2.0 HD 5450 DDR2 650 MHz – 800 MHz 64 bits 6,4 GB/s 80 11 4.4 2.0 HD 5450 DDR3 650 MHz – 1,6 GHz 64 bits 12,8 GB/s 80 11 4.4 2.0 HD 5550 550 MHz – * 128 bits * 320 11 4.4 2.0 HD 5570 650 MHz – 1.8 GHz 128 bits 28,8 GB/s 400 11 4.4 2.0 HD 5670 775 MHz – 4 GHz 128 bits 64 GB/s 400 11 4.4 2.0 HD 5750 705 MHz – 4.6 GHz 128 bits 73,6 GB/s 720 11 4.4 2.0 HD 5770 850 MHz – 4,8 GHz 128 bits 76,8 GB/s 800 11 4.4 2.0 HD 5830 800 MHz – 4 GHz 256 bits 128 GB/s 1.120 11 4.4 2.0 HD 5850 725 MHz – 4 GHz 256 bits 128 GB/s 1.440 11 4.4 2.0 HD 5870 850 MHz – 4,8 GHz 256 bits 153,6 GB/s 1.600 11 4.4 2.0 HD 5970† 725 MHz – 4 GHz 256 bits 128 GB/s 1.600 11 4.4 2.0 HD 6350 650 MHz – 1,6 GHz 64 bits 12,8 GB/s 80 11 4.4 2.0 HD 6390 550 MHz – * 128 bits * 320 11 4.4 2.0 HD 6450 * – * 64 bits * 160 11 4.4 2.0 HD 6570 DDR3 650 MHz – 1,8 GHz 128 bits 28,8 GB/s 480 11 4.4 2.0 HD 6570 GDDR5 650 MHz – 4 GHz 128 bits 64 GB/s 480 11 4.4 2.0 HD 6670 800 MHz – 4 GHz 128 bits 64 GB/s 480 11 4.4 2.0 HD 6750 705 MHz – 4,6 GHz 128 bits 73,6 GB/s 720 11 4.4 2.0 HD 6770 850 MHz – 4,8 GHz 128 bits 76,8 GB/s 800 11 4.4 2.0 HD 6790 840 MHz – 4,2 GHz 256 bits 134,4 GB/s 800 11 4.4 2.0 HD 6850 775 MHz – 4 GHz 256 bits 128 GB/s 960 11 4.4 2.0 HD 6870 900 MHz – 4,2 GHz 256 bits 134,4 GB/s 1.120 11 4.4 2.0 HD 6950 800 MHz – 5 GHz 256 bits 160 GB/s 1.408 11 4.4 2.0 HD 6970 880 MHz – 5,5 GHz 256 bits 176 GB/s 1.536 11 4.4 2.0 HD 6990† 830 MHz – 5 GHz 256 bits 160 GB/s 1.536 11 4.4 2.0 HD 7730 800 MHz – 4,5 GHz 128 bits 72 GB/s 384 11.1 4.6 3.0 HD 7750 800 MHz – 4,5 GHz 128 bits 72 GB/s 512 11.1 4.6 3.0 HD 7770 1.000 MHz – 4,5 GHz 128 bits 72 GB/s 640 11.1 4.6 3.0 HD 7790 1.000 MHz – 6 GHz 128 bits 96 GB/s 896 11.1 4.6 3.0 HD 7850 860 MHz – 4,8 GHz 256 bits 153,6 GB/s 1.024 11.1 4.6 3.0 HD 7870 1.000 MHz – 4,8 GHz 256 bits 153,6 GB/s 1.280 11.1 4.6 3.0 HD 7950 800 MHz – 5 GHz 384 bits 240 GB/s 1.792 11.1 4.6 3.0 HD 7950 Boost 850 MHz 925 MHz 5 GHz 384 bits 240 GB/s 1.792 11.1 4.6 3.0 HD 7970 925 MHz – 5,5 GHz 384 bits 264 GB/s 2.048 11.1 4.6 3.0 HD 7970 GHz Edition 1.000 MHz – 6 GHz 384 bits 288 GB/s 2.048 11.1 4.6 3.0 HD 7990† 1.000 MHz – 6 GHz 384 bits 288 GB/s 2.048 11.1 4.6 3.0 HD 8350 400 MHz – 1,8 GHz 64 bits 28,8 GB/s 80 11 4.4 2.0 HD 8470 775 MHz – 3,2 GHz 64 bits 25,6 GB/s 160 11 4.4 2.0 HD 8490 875 MHz – 1,8 GHz 64 bits 14,4 GB/s 160 11 4.4 2.0 x16 HD 8570 1 GB 650 MHz – 1,6 GHz 128 bits 25,6 GB/s 480 11 4.4 2.0 x16 HD 8570 2 GB 730 MHz 780 MHz 1,8 GHz 128 bits 28,8 GB/s 320 11.1 4.6 3.0 x8 HD 8670 1.000 MHz 1.050 MHz 4,6 GHz 128 bits 73,6 GB/s 384 11.1 4.6 3.0 x8 HD 8760 1.000 MHz – 4,5 GHz 128 bits 72 GB/s 640 11.1 4.6 3.0 HD 8870 1.000 MHz – 4,8 GHz 256 bits 153,6 GB/s 1.280 11.1 4.6 3.0 HD 8950 850 MHz 925 MHz 5 GHz 384 bits 240 GB/s 1.792 11.1 4.6 3.0 HD 8970 1.000 MHz 1.050 MHz 6 GHz 384 bits 288 GB/s 2.048 11.1 4.6 3.0 R5 220 650 MHz – 1.066 MHz 64 bits 8,53 GB/s 80 11 4.4 2.0 R5 230 650 MHz – 1.066 MHz 64 bits 8,53 GB/s 160 11 4.4 2.0 R5 235 775 MHz – 1,8 GHz 64 bits 14,4 GB/s 160 11 4.4 2.0 R5 235X 875 MHz – 1,8 GHz 64 bits 14,4 GB/s 160 11 4.4 2.0 R5 240 730 MHz 780 MHz 1,8 GHz 128 bits 28,8 GB/s 320 11.1 4.6 3.0 x8 R7 240 DDR3 730 MHz 780 MHz 1,8 GHz 128 bits 28,8 GB/s 320 11.1 4.6 3.0 R7 240 GDDR5 730 MHz 780 MHz 4,6 GHz 128 bits 73,6 GB/s 320 11.1 4.6 3.0 R7 250 DDR3 1.000 MHz 1.050 MHz 1,8 GHz 128 bits 28,8 GB/s 384 11.1 4.6 3.0 x16 R7 250 GDDR5 1.000 MHz 1.050 MHz 4,6 GHz 128 bits 73,6 GB/s 384 11.1 4.6 3.0 x8 R7 250E 800 MHz – 4,5 GHz 128 bits 72 GB/s 512 11.1 4.6 3.0 R7 250X DDR3 1 GHz – * 128 bits * 640 11.1 4.6 3.0 R7 250X GDDR5 950 MHz 1.125 MHz 4,5 GHz 128 bits 72 GB/s 640 11.1 4.6 3.0 R7 250XE 860 MHz 1.125 MHz 4,5 GHz 128 bits 72 GB/s 640 11.1 4.6 3.0 R7 260 1.000 MHz – 6 GHz 128 bits 96 GB/s 768 12 4.6 3.0 R7 260X 1.100 MHz – 6,5 GHz 128 bits 104 GB/s 896 12 4.6 3.0 R7 265 900 MHz 925 MHz 5,6 GHz 256 bits 179,2 GB/s 1.024 11.1 4.6 3.0 R7 265X 900 MHz 925 MHz 5,6 GHz 256 bits 179,2 GB/s 1.280 11.1 4.6 3.0 R9 255 930 MHz – 6,5 GHz 128 bits 104 GB/s 512 11.1 4.6 3.0 R9 260 1.100 MHz – 6,5 GHz 128 bits 104 GB/s 896 12 4.6 3.0 R9 270 900 MHz 925 MHz 5,6 GHz 256 bits 179,2 GB/s 1.280 11.1 4.6 3.0 R9 270X 1.000 MHz 1.050 MHz 5,6 GHz 256 bits 179,2 GB/s 1.280 11.1 4.6 3.0 R9 280 827 MHz 933 MHz 5 GHz 384 bits 240 GB/s 1.792 11.1 4.6 3.0 R9 280X 850 MHz 1 GHz 6 GHz 384 bits 288 GB/s 2.048 11.1 4.6 3.0 R9 285 918 MHz – 5,5 GHz 256 bits 176 GB/s 1.792 12 4.6 3.0 R9 290 662 MHz 947 MHz 5 GHz 512 bits 320 GB/s 2.560 12 4.6 3.0 R9 290X 800 MHz 1.000 MHz 5 GHz 512 bits 320 GB/s 2.816 12 4.6 3.0 R9 295X2† 1.018 MHz – 5 GHz 512 bits 320 GB/s 2.816 12 4.6 3.0 R5 330 OEM 833 MHz 855 MHz 1,8 GHz 128 bits 28,8 GB/s 320 12 4.6 3.0 x8 R5 340 OEM 800 MHz 825 MHz 4,5 GHz 128 bits 72 GB/s 384 12 4.6 3.0 x8 R7 340 OEM 730 MHz 780 MHz 1,8 GHz 128 bits 28,8 GB/s 384 12 4.6 3.0 x8 R7 350 OEM 1.000 MHz 1.050 MHz 4,5 GHz 128 bits 72 GB/s 384 12 4.6 3.0 x8 R7 360 1.000 MHz 1.050 MHz 6,5 GHz 128 bits 104 GB/s 768 12 4.6 3.0 R7 370 925 MHz 975 MHz 5,6 GHz 256 bits 179,2 GB/s 1.024 12 4.6 3.0 R9 360 OEM 1 GHz 1.050 MHz 6,5 GHz 128 bits 104 GB/s 768 12 4.6 3.0 R9 370 OEM 925 MHz 975 MHz 5,6 GHz 256 bits 179,2 GB/s 1.024 12 4.6 3.0 R9 370X 980 MHz 1.030 MHz 5,6 GHz 256 bits 179,2 GB/s 1.280 12 4.6 3.0 R9 380 OEM 918 MHz – 5,5 GHz 256 bits 176 GB/s 1.792 12 4.6 3.0 R9 380 970 MHz – 5,5 GHz 256 bits 176 GB/s 1.792 12 4.6 3.0 R9 380X 970 MHz – 5,7 GHz 256 bits 182,4 GB/s 2.048 12 4.6 3.0 R9 390 1.000 MHz – 6 GHz 512 bits 384 GB/s 2.560 12 4.6 3.0 R9 390X 1.050 MHz – 6 GHz 512 bits 384 GB/s 2.816 12 4.6 3.0 Fury 1.000 MHz – 1 GHz 4.096 bits 512 GB/s 3.584 12 4.6 3.0 R9 Nano 1.000 MHz – 1 GHz 4.096 bits 512 GB/s 4.096 12 4.6 3.0 Fury X 1.050 MHz – 1 GHz 4.096 bits 512 GB/s 4.096 12 4.6 3.0 RX 460 1.090 MHz 1.200 MHz 7 GHz 128 bits 112 GB/s 896 12 4.6 3.0 RX 470 926 MHz 1.206 MHz 6,6 GHz 256 bits 211 GB/s 2.048 12 4.6 3.0 RX 480 1.120 MHz 1.266 MHz 8 GHz 256 bits 256 GB/s 2.304 12 4.6 3.0 RX 550 1.100 MHz 1.183 MHz 7 GHz 128 bits 112 GB/s 512 12 4.6 3.0 RX 560 1.175 MHz 1.275 MHz 7 GHz 128 bits 112 GB/s 1.024 12 4.6 3.0 RX 560D 1.090 MHz 1.175 MHz 6 GHz 128 bits 96 GB/s 896 12 4.6 3.0 x8 RX 570 1.168 MHz 1.244 MHz 7 GHz 256 bits 224 GB/s 2.048 12 4.6 3.0 x16 RX 580 2048SP 1,168 MHz 1.284 MHz 7 GHz 256 bits 224 GB/s 2.048 12 4.6 3.0 x16 RX 580 1.257 MHz 1.340 MHz 8 GHz 256 bits 256 GB/s 2.304 12 4.6 3.0 RX 590 1.469 MHz 1.545 MHz 8 GHz 256 bits 256 GB/s 2.304 12 4.6 3.0 RX Vega 56 1.156 MHz 1.471 MHz 1,6 GHz 2.048 bits 409,6 GB/s 3.584 12 4.6 3.0 RX Vega 64 1.247 MHz 1.546 MHz 1,89 GHz 2.048 bits 483,8 GB/s 4.096 12 4.6 3.0 RX Vega 64 Liquid 1.406 MHz 1.677 MHz 1,89 GHz 2.048 bits 483,8 GB/s 4.096 12 4.6 3.0 VII 1.400 MHz 1.750 MHz 4 GHz 4.096 bits 1.024 GB/s 3.840 12 4.6 3.0 RX 5500 1.670 MHz 1.750 MHz 14 GHz 128 bits 224 GB/s 1.408 12 4.6 4.0 RX 5500 XT 1.607 MHz 1.845 MHz 14 GHz 128 bits 224 GB/s 1.408 12 4.6 4.0 RX 5600 1.375 MHz 1.725 MHz 12 GHz 192 bits 288 GB/s 2.048 12 4.6 4.0 RX 5600 XT 1.375 MHz 1.560 MHz 12 GHz 192 bits 288 GB/s 2.304 12 4.6 4.0 RX 5700 1.465 MHz 1.725 MHz 14 GHz 256 bits 448 GB/s 2.304 12 4.6 4.0 RX 5700 XT 1.605 MHz 1.905 MHz 14 GHz 256 bits 448 GB/s 2.560 12 4.6 4.0 RX 5700 XT 50th Anniversary 1.680 MHz 1.980 MHz 14 GHz 256 bits 448 GB/s 2.560 12 4.6 4.0 RX 6400 1.923 MHz 2.321 MHz 16 GHz 64 bits 128 GB/s 768 12.2 4.6 4.0 x4 RX 6500 XT 2.200 MHz 2.815 MHz 18 GHz 64 bits 144 GB/s 1.024 12.2 4.6 4.0 x8 RX 6600 1.626 MHz 2.491 MHz 14 GHz 128 bits 224 GB/s 1.792 12.2 4.6 4.0 x8 RX 6600 XT 1.968 MHz 2.589 MHz 16 GHz 128 bits 256 GB/s 2.048 12.2 4.6 4.0 x8 RX 6650 XT 2.055 MHz 2.635 MHz 17,5 GHz 128 bits 280 GB/s 2.048 12.2 4.6 4.0 x8 RX 6700 1.941 MHz 2.450 MHz 16 GHz 160 bits 320 GB/s 2.304 12.2 4.6 4.0 x16 RX 6700 XT 2.321 MHz 2.581 MHz 16 GHz 192 bits 384 GB/s 2.560 12.2 4.6 4.0 RX 6750 XT 2.150 MHz 2.600 MHz 18 GHz 192 bits 432 GB/s 2.560 12.2 4.6 4.0 RX 6800 1.815 MHz 2.105 MHz 16 GHz 256 bits 512 GB/s 3.840 12.2 4.6 4.0 RX 6800 XT 2.015 MHz 2.250 MHz 16 GHz 256 bits 512 GB/s 4.608 12.2 4.6 4.0 RX 6900 XT 2.015 MHz 2.250 MHz 16 GHz 256 bits 512 GB/s 5.120 12.2 4.6 4.0 RX 6950 XT 1.890 MHz 2.310 MHz 18 GHz 256 bits 576 GB/s 5.120 12.2 4.6 4.0 RX 7600 1.720 MHz 2.655 MHz 18 GHz 128 bits 288 GB/s 2.048 12.2 4.6 4.0 x8 RX 7600 XT 1.980 MHz 2.755 MHz 18 GHz 128 bits 288 GB/s 2.048 12.2 4.6 4.0 x8 RX 7700 XT 1.900 MHz 2.544 MHz 18 GHz 192 bits 432 GB/s 3.456 12.2 4.6 4.0 x16 RX 7800 XT 1.800 MHz 2.430 MHz 19,5 GHz 256 bits 624 GB/s 3.840 12.2 4.6 4.0 x16 RX 7900 GRE 1.270 MHz 2.245 MHz 18 GHz 256 bits 576 GB/s 5.120 12.2 4.6 4.0 x16 RX 7900 XT 1.500 MHz 2.400 MHz 20 GHz 320 bits 800 GB/s 5.376 12.2 4.6 4.0 x16 RX 7900 XTX 1.900 MHz 2.500 MHz 20 GHz 384 bits 960 GB/s 6.144 12.2 4.6 4.0 x16 RX 9060 XT 1.700 MHz 3.130 MHz 20 GHz 128 bits 320 GB/s 2.048 12.2 4.6 5.0 x16 RX 9070 1.330 MHz 2.520 MHz 20 GHz 256 bits 640 GB/s 3.584 12.2 4.6 5.0 x16 RX 9070 XT 1.660 MHz 2.970 MHz 20 GHz 256 bits 640 GB/s 4.096 12.2 4.6 5.0 x16 * A AMD não determina um clock padrão para esta placa de vídeo; as especificações dependem do fabricante da placa. Por isso, tome cuidado na hora de comparar placas de vídeo usando esse chip. † Esta placa de vídeo tem dois chips gráficos trabalhando em paralelo (CrossFire). Os dados publicados são para apenas um dos chips. Fabricantes podem usar outros clocks de memória nos modelos da série HD 2400 e HD 2600, normalmente mais baixos e, portanto, atingindo desempenho inferior ao modelo padrão. Os clocks listados são os clocks oficiais. Na próxima página, falaremos sobre a potência máxima dissipada (TDP) e a potência mínima de fonte de alimentação recomendada para cada placa de vídeo. Abaixo nós listamos a potência mínima recomendada para a fonte de alimentação para cada placa de vídeo, de acordo com a AMD. Chips que não estão listados significa que a AMD não publica essas especificações para eles. É importante notar que todos os valores são “para a pior das hipóteses”. Em condições normais de uso um chip gráfico consumirá menos do que está publicado na tabela. O mesmo vale para a fonte de alimentação mínima, onde a AMD adiciona uma “margem de segurança”, levando em conta que a fonte é rotulada com sua potência de pico e não com a sua potência máxima em modo contínuo. Chip gráfico Consumo máx. Fonte mínima Radeon 23 W N/D Radeon PCI 23 W N/D Radeon DDR 23 W N/D Radeon VE 23 W N/D Radeon VE PCI 23 W N/D Radeon 7000 23 W N/D Radeon 7200 23 W N/D Radeon 7500 23 W N/D Radeon 7500 LE 23 W N/D Radeon 8500 23 W N/D Radeon 8500 23 W N/D Radeon 8500 23 W N/D Radeon 8500 LE 23 W N/D Radeon 8500 XT 25 W N/D Radeon 9000 28 W N/D Radeon 9000 LE 28 W N/D Radeon 9000 Pro 28 W N/D Radeon 9100 28 W N/D Radeon 9100 PCI 28 W N/D Radeon HD 2400 Pro 20 W ND Radeon HD 2600 Pro 35 W ND Radeon HD 2600 XT 45 W ND Radeon HD 3450 25 W 550 W (750 W para CrossFire) Radeon HD 3470 30 W 550 W (750 W para CrossFire) Radeon HD 3650 65 W 400 W (550 W para CrossFire) Radeon HD 3690 75 W 400 W (550 W para CrossFire) Radeon HD 3850 75 W 550 W (750 W para CrossFire) Radeon HD 3870 106 W 550 W (750 W para CrossFire) Radeon HD 4350 20 W 300 W (350 W para CrossFire Radeon HD 4550 25 W 300 W (350 W para CrossFire) Radeon HD 4650 48 W 400 W (550 W para CrossFire) Radeon HD 4670 59 W 400 W (550 W para CrossFire) Radeon HD 4830 95 W 450 W (550 W para CrossFire) Radeon HD 4850 110 W 450 W (550 W para CrossFire) Radeon HD 4870 150 W 500 W (600 W para CrossFire) Radeon HD 4890 190 W 500 W (600 W para CrossFire) Radeon HD 5450 19 W 400 W Radeon HD 5550 39 W 400 W Radeon HD 5570 39 W 400 W Radeon HD 5670 64 W 400 W (500 W para CrossFire) Radeon HD 5750 86 W 450 W (600 W para CrossFire) Radeon HD 5770 108 W 450 W (600 W para CrossFire) Radeon HD 5830 175 W 500 W (600 W para CrossFire) Radeon HD 5850 151 W 500 W (600 W para CrossFire) Radeon HD 5870 188 W 500 W (600 W para CrossFire) Radeon HD 5970 294 W 650 W (850 W para CrossFire) Radeon HD 6450 18 W 400 W (500 W para CrossFire) Radeon HD 6570 60 W 400 W (500 W para CrossFire) Radeon HD 6670 66 W 400 W (500 W para CrossFire) Radeon HD 6750 86 W 450 W (600 W para CrossFire) Radeon HD 6770 108 W 450 W (600 W para CrossFire) Radeon HD 6790 150 W 500 W (600 W para CrossFire) Radeon HD 6850 127 W 500 W Radeon HD 6870 151 W 500 W (600 W para CrossFire) Radeon HD 6950 200 W 500 W Radeon HD 6970 250 W 550 W Radeon HD 6990 375 W 750 W (1,000 W para CrossFire) Radeon HD 7730 47 W 400 W (500 W para CrossFire) Radeon HD 7750 55 W 500 W (600 W para CrossFire) Radeon HD 7770 80 W 500 W (600 W para CrossFire) Radeon HD 7790 85 W 500 W (600 W para CrossFire) Radeon HD 7850 130 W 500 W (600 W para CrossFire) Radeon HD 7870 175 W 500 W (600 W para CrossFire) Radeon HD 7950 200 W 500 W Radeon HD 7970 250 W 500 W Radeon HD 7970 GHz Edition 300 W 500 W (850 W para CrossFire) Radeon HD 7990 375 W 750 W (1.000 W para CrossFire) Radeon HD 8350 25 W N/D Radeon HD 8470 25 W 200 W Radeon HD 8490 35 W 200 W Radeon HD 8570 DDR3 50 W N/D Radeon HD 8570 GDDR3 60 W N/D Radeon HD 8670 75 W N/D Radeon HD 8760 110 W N/D Radeon HD 8870 175 W N/D Radeon HD 8950 200 W 500 W (750 W para CrossFire) Radeon HD 8970 250 W 500 W (850 W para CrossFire) Radeon R5 220 19 W N/D Radeon R5 230 19 W N/D Radeon R5 235 35 W N/D Radeon R5 235X 18 W N/D Radeon R5 240 50 W N/D Radeon R7 240 50 W N/D Radeon R7 250 65 W N/D Radeon R7 250E 55 W N/D Radeon R7 250X 80 W N/D Radeon R7 260 95 W N/D Radeon R7 260X 115 W N/D Radeon R7 265 150 W N/D Radeon R7 265X 150 W N/D Radeon R9 260 85 W N/D Radeon R9 270 175 W N/D Radeon R9 270X 180 W N/D Radeon R8 250 W N/D Radeon R9 280X 250 W N/D Radeon R9 285 190 W N/D Radeon R9 290 275 W N/D Radeon R9 290X 290 W N/D Radeon R9 295X2 500 W N/D Radeon R5 330 OEM 50 W N/D Radeon R5 340 OEM 65 W N/D Radeon R7 340 OEM 50 W N/D Radeon R7 350 OEM 65 W N/D Radeon R7 360 100 W N/D Radeon R7 370 110 W N/D Radeon R9 360 OEM 85 W N/D Radeon R9 370 OEM 150 W N/D Radeon R9 380 OEM 190 W N/D Radeon R9 380 190 W N/D Radeon R9 390 275 W N/D Radeon R9 390X 275 W N/D Radeon R9 Fury 275 W N/D Radeon R9 Nano 175 W N/D Radeon R9 Fury X 275 W N/D Radeon RX 460 75 W N/D Radeon RX 470 120 W N/D Radeon RX 480 150 W N/D Radeon RX 550 50 W 400 W Radeon RX 560 80 W 450 W Radeon RX 560D 65 W 450 W Radeon RX 570 150 W 450 W Radeon RX 580 2048SP 150 W 450 W Radeon RX 580 185 W 500 W Radeon RX 590 175 W 500 W Radeon RX Vega 56 210 W 650 W Radeon RX Vega 64 295 W 750 W Radeon RX Vega 64 Liquid 345 W 1.000 W Radeon VII 300 W 750 W Radeon RX 5500 150 W 550 W Radeon RX 5500 XT 130 W 450 W Radeon RX 5600 150 W 500 W Radeon RX 5600 XT 150 W 500 W Radeon RX 5700 180 W 600 W Radeon RX 5700 XT 235 W 600 W Radeon RX 5700 50th Anniversary 235 W 600 W Radeon RX 6400 53 W 350 W Radeon RX 6500 XT 107 W 400 W Radeon RX 6600 132 W 450 W Radeon RX 6600 XT 160 W 500 W Radeon RX 6650 XT 180 W 500 W Radeon RX 6700 175 W 600 W Radeon RX 6700 XT 230 W 550 W Radeon RX 6750 XT 250 W 650 W Radeon RX 6800 250 W 650 W Radeon RX 6800 XT 300 W 750 W Radeon RX 6900 XT 300 W 850 W Radeon RX 6950 XT 335 W 850 W Radeon RX 7600 165 W 550 W Radeon RX 7600 XT 190 W 600 W Radeon RX 7900 GRE 260 W 700 W Radeon RX 7700 XT 245 W 700 W Radeon RX 7800 XT 263 W 700 W Radeon RX 7900 XT 300 W 750 W Radeon RX 7900 XTX 355 W 800 W Radeon RX 7800 XT 263 W 700 W Radeon RX 7900 XT 300 W 750 W Radeon RX 7900 XTX 355 W 800 W Radeon RX 7800 XT 263 W 700 W Radeon RX 9060 XT 160 W 450 W Radeon RX 9070 220 W 650 W Radeon RX 9070 XT 304 W 750 W -
 Um vídeo (como arquivos do tipo AVI ou MPEG) é formado por várias imagens sendo projetadas. Cada imagem é chamada quadro e a quantidade de imagens projetadas por segundo é chamada quadros por segundo ou FPS (frames per second). Quanto mais quadros por segundo seu vídeo tiver, melhor, pois mais realista será a imagem. Vídeos normalmente trabalham com a mesma qualidade da TV, que é de 30 quadros por segundo. Uma maneira de diminuir o tamanho do vídeo é justamente diminuindo a quantidade de quadros por segundo. O tamanho do vídeo diminui, mas sua qualidade também: há “quebras de quadro”, isto é, os movimentos no vídeo ficam “truncados”, menos realistas. Para diminuir o tamanho do vídeo é usada uma técnica de compressão de imagem, que funciona removendo das imagens informações que já foram projetadas. Por exemplo, imagine um vídeo onde tenha uma pessoa falando e que esta esteja parada. No primeiro quadro a imagem é projetada completa, mas no segundo os pedaços da imagem que são idênticos ao quadro anterior são removidos. Se só a boca da pessoa é que está se mexendo, somente a área da boca será desenhada no segundo quadro. Esta técnica economiza uma quantidade enorme de espaço, já que somente o primeiro quadro precisa estar completo, os demais só têm o que é diferente do quadro anterior. Esses quadros incompletos são chamados quadros delta (delta frames). No padrão MPEG os quadros delta podem ser classificados em quadros P (de “predictive”) ou quadros B (de “bidirecionais”). Os quadros P funcionam da maneira descrita, enquanto os quadros B podem ainda ter a diferença não só para o quadro anterior, mas também a diferença para o quadro seguinte na seqüência, daí o nome “bidirecional”. O problema é que por conta desta técnica, não haveria como você usar os recursos de avanço e retrocesso do seu tocador de mídia, pois ele precisaria tocar o filme desde o início para poder construir uma imagem que esteja no meio do filme, já que no meio do filme só haverá a informação do que é diferente para o quadro anterior e não uma imagem completa. Por isso, de tempos em tempos é necessário inserir um quadro completo (como o primeiro quadro do filme) para que os recursos de avanço e retrocesso possam ser usados. Esses quadros completos são chamados quadros-chave (key frames) ou quadros I (I-frames). Quanto mais quadros-chave seu vídeo tiver, maior ele será (pois mais imagens completas, que ocupam mais espaço, serão inseridas), mas em compensação mais pontos de avanço e retrocesso existirão. Você precisa esperar o tocador chegar a um quadro-chave para que ele consiga mostrar o vídeo e quanto menos quadros-chave o vídeo tiver mais freqüente será este problema em seu vídeo. Além dessa técnica descrita, cada quadro é comprimido usando um algoritmo baseado em perda de dados – da mesma forma que ocorre com imagens no formato JPEG e áudio no formato MP3, por exemplo. Isso significa que o vídeo comprimido não tem a mesma qualidade do vídeo original.
Um vídeo (como arquivos do tipo AVI ou MPEG) é formado por várias imagens sendo projetadas. Cada imagem é chamada quadro e a quantidade de imagens projetadas por segundo é chamada quadros por segundo ou FPS (frames per second). Quanto mais quadros por segundo seu vídeo tiver, melhor, pois mais realista será a imagem. Vídeos normalmente trabalham com a mesma qualidade da TV, que é de 30 quadros por segundo. Uma maneira de diminuir o tamanho do vídeo é justamente diminuindo a quantidade de quadros por segundo. O tamanho do vídeo diminui, mas sua qualidade também: há “quebras de quadro”, isto é, os movimentos no vídeo ficam “truncados”, menos realistas. Para diminuir o tamanho do vídeo é usada uma técnica de compressão de imagem, que funciona removendo das imagens informações que já foram projetadas. Por exemplo, imagine um vídeo onde tenha uma pessoa falando e que esta esteja parada. No primeiro quadro a imagem é projetada completa, mas no segundo os pedaços da imagem que são idênticos ao quadro anterior são removidos. Se só a boca da pessoa é que está se mexendo, somente a área da boca será desenhada no segundo quadro. Esta técnica economiza uma quantidade enorme de espaço, já que somente o primeiro quadro precisa estar completo, os demais só têm o que é diferente do quadro anterior. Esses quadros incompletos são chamados quadros delta (delta frames). No padrão MPEG os quadros delta podem ser classificados em quadros P (de “predictive”) ou quadros B (de “bidirecionais”). Os quadros P funcionam da maneira descrita, enquanto os quadros B podem ainda ter a diferença não só para o quadro anterior, mas também a diferença para o quadro seguinte na seqüência, daí o nome “bidirecional”. O problema é que por conta desta técnica, não haveria como você usar os recursos de avanço e retrocesso do seu tocador de mídia, pois ele precisaria tocar o filme desde o início para poder construir uma imagem que esteja no meio do filme, já que no meio do filme só haverá a informação do que é diferente para o quadro anterior e não uma imagem completa. Por isso, de tempos em tempos é necessário inserir um quadro completo (como o primeiro quadro do filme) para que os recursos de avanço e retrocesso possam ser usados. Esses quadros completos são chamados quadros-chave (key frames) ou quadros I (I-frames). Quanto mais quadros-chave seu vídeo tiver, maior ele será (pois mais imagens completas, que ocupam mais espaço, serão inseridas), mas em compensação mais pontos de avanço e retrocesso existirão. Você precisa esperar o tocador chegar a um quadro-chave para que ele consiga mostrar o vídeo e quanto menos quadros-chave o vídeo tiver mais freqüente será este problema em seu vídeo. Além dessa técnica descrita, cada quadro é comprimido usando um algoritmo baseado em perda de dados – da mesma forma que ocorre com imagens no formato JPEG e áudio no formato MP3, por exemplo. Isso significa que o vídeo comprimido não tem a mesma qualidade do vídeo original. -
 Uma maneira muito fácil de conectar dois micros é usando um cabo USB-USB. Com este tipo de conexão você pode transferir arquivos de um computador para outro e até mesmo montar uma pequena rede, compartilhando sua conexão com a Internet com o segundo micro. Neste tutorial explicaremos como conectar dois micros usando um cabo USB-USB. A primeira coisa que você deve ter em mente é que existem vários tipos de cabo USB-USB no mercado. O cabo USB-USB usado para conectar dois micros é chamado “bridged” (ou “cabo de rede USB”), porque ele possui um pequeno circuito eletrônico no meio do cabo permitindo que os dois micros conversem entre si. Existe ainda o cabo USB A/A que, apesar de ter dois conectores USB padrão nas pontas, não possui o chip que permite a comunicação entre os micros e não pode ser usado para conectar dois computadores. Na verdade, se você usar um cabo USB A/A você pode queimar as portas USB ou até mesmo a fontes de alimentação de seus computadores. Assim, esse cabo USB A/A não tem muita utilidade. Ele é usado para conectar seu micro a periféricos como impressoras e scanners. Figura 1: Cabo de rede USB (“bridged”). Figura 2: Observe que o circuito eletrônico fica localizado no meio do cabo. O circuito eletrônico pode ser USB 1.1 (12 Mbit/s) ou USB 2.0 (480 Mbit/s). Obviamente recomendamos que você compre um cabo USB 2.0, já que ele é bem mais rápido. Só para lembrar, o padrão de redes Ethernet trabalha a 100 Mbit/s e, portanto, a taxa de transferência do cabo USB 2.0 é quase cinco vezes maior do que a de um padrão de conexão de rede. Decidimos abrir a ponte localizada no meio de nosso cabo para mostrar a você o circuito eletrônico. É devido à presença desse circuito eletrônico que este cabo é mais caro do que um simples cabo USB A/A, que não possui qualquer circuito. Figura 3: Circuito eletrônico usado em nosso cabo. Agora que você conhece o tipo de cabo que deve comprar, falaremos sobre sua instalação. Este cabo pode trabalhar em dois modos: modo link e modo rede. No modo link, o cabo funciona igual a um antigo cabo “lap link”, ou seja, ele vem com um software onde você pode selecionar os arquivos e simplesmente arrastá-los (mover ou copiar) para onde quiser. Se você deseja apenas copiar arquivos, este é o modo que recomendamos a você usar, já que sua instalação é rápida e de fácil uso. No modo rede, você criará uma pequena rede entre os dois computadores. Após a criação desta rede você pode compartilhar pastas, impressoras e sua conexão com a Internet. Este modo é recomendado se além de copiar arquivos você quiser ter acesso a uma impressora localizada em outro computador (ou qualquer outro computador na rede, se este computador estiver conectado a uma rede) ou quiser ter acesso à Internet. O processo de instalação do cabo depende do fabricante. Você terá que instalar os programas e drivers que vêm com o cabo em um CD-ROM. Este procedimento tem que ser feito em ambos computadores, com o cabo não conectado. Por isso, não instale o cabo ainda. Alguns fabricantes fornecem dois arquivos diferentes de instalação, um para o modo link e outro para o modo rede. Já outros fabricantes fornecem apenas um arquivo de instalação válido para ambos modos, selecionando o modo que deseja usar durante a instalação do programa ou dentro do programa de transferência que será instalado. Figura 4: Escolhendo o modo durante a instalação. Figura 5: Escolhendo o modo dentro do programa de transferência. Após você ter instalado os drivers correspondentes (modo link ou modo rede), você deve instalar o cabo no micro. O Windows o reconhecerá e instalará os drivers corretos. Se você instalou o programa e os drivers com o cabo conectado no micro, você deve remover o cabo e realizar o procedimento de instalação novamente. Isto fará com que o Windows o reconheça e instale seus drivers. Agora você deve repetir este processo no outro computador. Se você quiser mudar o modo de operação do seu cabo, deverá rodar o programa de instalação para o outro modo ou mudar o modo no programa de transferência, dependendo do modelo do cabo. Isto deve ser feito sem o cabo estar conectado ao micro. Após a alteração do modo, conecte o cabo e o micro o reconhecerá automaticamente. Se você executar o programa de instalação ou alterar o modo com o cabo conectado, terá que remover o cabo do micro e rodar o programa de instalação novamente de modo a fazer com que o Windows instale os drivers corretos (os drivers usados no modo link e no modo rede são diferentes). Você deve repetir este procedimento no outro micro. Agora que o cabo está instalado, vejamos como usá-lo. Como mencionamos, o modo link é o modo mais fácil e rápido para conectar dois micros usando um cabo USB para transferir arquivos. Se você quer ter acesso à Internet e/ou impressora, você deve usar o modo rede. Após a instalação do cabo como descrevemos na página anterior, você deve verificar se o cabo está instalado corretamente no Gerenciador de Dispositivos (clique com o botão direito em Meu Computador, Propriedades, Hardware, Gerenciador de Dispositivos). O cabo deve ser listado em “Controladores USB”, como você pode ver na Figura 6 (nosso cabo está listado como “Hi-Speed USB Bridge Cable”, mas seu cabo pode usar um nome ligeiramente diferente, dependendo do fabricante). Figura 6: Cabo USB-USB devidamente instalado usando no modo link. Para transferir arquivos, você deve abrir o programa de transferência que foi instalado quando você executou o arquivo de instalação. Em nosso caso este programa era chamado Pclinq2. Este programa tem que estar aberto em ambos computadores. A utilização do programa de transferência é realmente muito fácil. No lado esquerdo do programa você verá seu computador, e no lado direito você verá o computador remoto. Selecione o disco/partição e pasta/arquivos que deseja transferir e arraste e solte na localização desejada. Não poderia ser mais fácil! Figura 7: Programa de transferência. Como mencionamos, no modo rede os computadores estarão ligados em uma pequena rede e a conexão funcionará como tal. Este modo permite que você compartilhe sua conexão com a Internet, caso esteja disponível em um dos computadores. Após a instalação do cabo, como descrevemos anteriormente, você deve verificar se o cabo está instalado corretamente no Gerenciador de Dispositivos (clique com o botão direito em Meu Computador, Propriedades, Hardware, Gerenciador de Dispositivos). O cabo deve ser listado em “Adaptadores de rede”, como você pode ver na Figura 8 (nosso cabo está listado como “Hi-Speed USB-USB Network Adapter”, mas seu cabo pode usar um nome ligeiramente diferente, dependendo do fabricante). Figura 8: Cabo USB-USB devidamente instalado no modo rede. O próximo passo é configurar ambos computadores para usarem o cabo USB como uma placa de rede. Primeiro você tem que configurar o computador que tem acesso à Internet. Neste computador, abra suas Conexões de Rede (Iniciar, Configurações, Conexões de Rede). Na tela que aparecerá você verá os adaptadores de redes localizados em seu computador. Em nosso caso, “Conexão de Rede Local 3” era o adaptador de rede que conectava nosso micro à Internet (em nosso roteador banda larga) e “Conexão de Rede Local 6” era o cabo USB-USB, veja na Figura 9. Figura 9: Conexões de rede. Clique com o botão direito do mouse na placa de rede que está conectando seu micro a Internet (“Conexão de Rede Local 3”, em nosso caso), clique em Propriedades e, na janela que aparecerá, clique na guia Avançado. Feito isso, marque a opção “Permitir que outros usuários da rede se conectem pela conexão deste computador à Internet”. Dependendo da sua versão do Windows XP, haverá uma caixa chamada “Conexão de rede caseira”, onde você deve selecionar a conexão do cabo USB (“Conexão de Rede Local 6”, em nosso caso). Figura 10: Habilitando o compartilhamento de Internet. Após ter feito esta configuração, você tem que reiniciar o micro para que tudo funcione adequadamente. Tente conectar a Internet no outro computador e verifique se tudo está funcionando bem. Para compartilhar arquivos e impressoras, você deve ler nosso tutorial Como Compartilhar Pastas e Impressoras na Rede para ver como isto pode ser feito. Se você não está usando um roteador de banda larga no computador que tem a conexão com a Internet, você deve ser muito cuidadoso, já que o compartilhamento de seus arquivos pode permitir que qualquer pessoa na Internet tenha acesso a eles. Leia mais sobre isso em nosso tutorial Protegendo seu Seu Micro Contra Invasões. Neste tutorial você encontrará alguns macetes para prevenir que um hacker tenha acesso a seus arquivos. Se o computador remoto não estiver acessando a Internet, verifique se o cabo USB está configurado para obter um endereço IP automaticamente na rede. Para isso, clique no menu Iniciar, Configurações, Conexões de Rede, e então clique com o botão direito do mouse na conexão do cabo (“Conexão de Rede Local 6”, em nosso caso), selecione Propriedades e, na janela que aparecerá, dê um duplo clique em “Protocolo Internet (TCP/IP)”. As duas opções desta tela devem estar configuradas como “automaticamente”, conforme mostramos na Figura 11. Ambos computadores devem ser configurados desta maneira. Figura 11: Configuração TCP/IP tem que estar configurada como automática nos computadores.
Uma maneira muito fácil de conectar dois micros é usando um cabo USB-USB. Com este tipo de conexão você pode transferir arquivos de um computador para outro e até mesmo montar uma pequena rede, compartilhando sua conexão com a Internet com o segundo micro. Neste tutorial explicaremos como conectar dois micros usando um cabo USB-USB. A primeira coisa que você deve ter em mente é que existem vários tipos de cabo USB-USB no mercado. O cabo USB-USB usado para conectar dois micros é chamado “bridged” (ou “cabo de rede USB”), porque ele possui um pequeno circuito eletrônico no meio do cabo permitindo que os dois micros conversem entre si. Existe ainda o cabo USB A/A que, apesar de ter dois conectores USB padrão nas pontas, não possui o chip que permite a comunicação entre os micros e não pode ser usado para conectar dois computadores. Na verdade, se você usar um cabo USB A/A você pode queimar as portas USB ou até mesmo a fontes de alimentação de seus computadores. Assim, esse cabo USB A/A não tem muita utilidade. Ele é usado para conectar seu micro a periféricos como impressoras e scanners. Figura 1: Cabo de rede USB (“bridged”). Figura 2: Observe que o circuito eletrônico fica localizado no meio do cabo. O circuito eletrônico pode ser USB 1.1 (12 Mbit/s) ou USB 2.0 (480 Mbit/s). Obviamente recomendamos que você compre um cabo USB 2.0, já que ele é bem mais rápido. Só para lembrar, o padrão de redes Ethernet trabalha a 100 Mbit/s e, portanto, a taxa de transferência do cabo USB 2.0 é quase cinco vezes maior do que a de um padrão de conexão de rede. Decidimos abrir a ponte localizada no meio de nosso cabo para mostrar a você o circuito eletrônico. É devido à presença desse circuito eletrônico que este cabo é mais caro do que um simples cabo USB A/A, que não possui qualquer circuito. Figura 3: Circuito eletrônico usado em nosso cabo. Agora que você conhece o tipo de cabo que deve comprar, falaremos sobre sua instalação. Este cabo pode trabalhar em dois modos: modo link e modo rede. No modo link, o cabo funciona igual a um antigo cabo “lap link”, ou seja, ele vem com um software onde você pode selecionar os arquivos e simplesmente arrastá-los (mover ou copiar) para onde quiser. Se você deseja apenas copiar arquivos, este é o modo que recomendamos a você usar, já que sua instalação é rápida e de fácil uso. No modo rede, você criará uma pequena rede entre os dois computadores. Após a criação desta rede você pode compartilhar pastas, impressoras e sua conexão com a Internet. Este modo é recomendado se além de copiar arquivos você quiser ter acesso a uma impressora localizada em outro computador (ou qualquer outro computador na rede, se este computador estiver conectado a uma rede) ou quiser ter acesso à Internet. O processo de instalação do cabo depende do fabricante. Você terá que instalar os programas e drivers que vêm com o cabo em um CD-ROM. Este procedimento tem que ser feito em ambos computadores, com o cabo não conectado. Por isso, não instale o cabo ainda. Alguns fabricantes fornecem dois arquivos diferentes de instalação, um para o modo link e outro para o modo rede. Já outros fabricantes fornecem apenas um arquivo de instalação válido para ambos modos, selecionando o modo que deseja usar durante a instalação do programa ou dentro do programa de transferência que será instalado. Figura 4: Escolhendo o modo durante a instalação. Figura 5: Escolhendo o modo dentro do programa de transferência. Após você ter instalado os drivers correspondentes (modo link ou modo rede), você deve instalar o cabo no micro. O Windows o reconhecerá e instalará os drivers corretos. Se você instalou o programa e os drivers com o cabo conectado no micro, você deve remover o cabo e realizar o procedimento de instalação novamente. Isto fará com que o Windows o reconheça e instale seus drivers. Agora você deve repetir este processo no outro computador. Se você quiser mudar o modo de operação do seu cabo, deverá rodar o programa de instalação para o outro modo ou mudar o modo no programa de transferência, dependendo do modelo do cabo. Isto deve ser feito sem o cabo estar conectado ao micro. Após a alteração do modo, conecte o cabo e o micro o reconhecerá automaticamente. Se você executar o programa de instalação ou alterar o modo com o cabo conectado, terá que remover o cabo do micro e rodar o programa de instalação novamente de modo a fazer com que o Windows instale os drivers corretos (os drivers usados no modo link e no modo rede são diferentes). Você deve repetir este procedimento no outro micro. Agora que o cabo está instalado, vejamos como usá-lo. Como mencionamos, o modo link é o modo mais fácil e rápido para conectar dois micros usando um cabo USB para transferir arquivos. Se você quer ter acesso à Internet e/ou impressora, você deve usar o modo rede. Após a instalação do cabo como descrevemos na página anterior, você deve verificar se o cabo está instalado corretamente no Gerenciador de Dispositivos (clique com o botão direito em Meu Computador, Propriedades, Hardware, Gerenciador de Dispositivos). O cabo deve ser listado em “Controladores USB”, como você pode ver na Figura 6 (nosso cabo está listado como “Hi-Speed USB Bridge Cable”, mas seu cabo pode usar um nome ligeiramente diferente, dependendo do fabricante). Figura 6: Cabo USB-USB devidamente instalado usando no modo link. Para transferir arquivos, você deve abrir o programa de transferência que foi instalado quando você executou o arquivo de instalação. Em nosso caso este programa era chamado Pclinq2. Este programa tem que estar aberto em ambos computadores. A utilização do programa de transferência é realmente muito fácil. No lado esquerdo do programa você verá seu computador, e no lado direito você verá o computador remoto. Selecione o disco/partição e pasta/arquivos que deseja transferir e arraste e solte na localização desejada. Não poderia ser mais fácil! Figura 7: Programa de transferência. Como mencionamos, no modo rede os computadores estarão ligados em uma pequena rede e a conexão funcionará como tal. Este modo permite que você compartilhe sua conexão com a Internet, caso esteja disponível em um dos computadores. Após a instalação do cabo, como descrevemos anteriormente, você deve verificar se o cabo está instalado corretamente no Gerenciador de Dispositivos (clique com o botão direito em Meu Computador, Propriedades, Hardware, Gerenciador de Dispositivos). O cabo deve ser listado em “Adaptadores de rede”, como você pode ver na Figura 8 (nosso cabo está listado como “Hi-Speed USB-USB Network Adapter”, mas seu cabo pode usar um nome ligeiramente diferente, dependendo do fabricante). Figura 8: Cabo USB-USB devidamente instalado no modo rede. O próximo passo é configurar ambos computadores para usarem o cabo USB como uma placa de rede. Primeiro você tem que configurar o computador que tem acesso à Internet. Neste computador, abra suas Conexões de Rede (Iniciar, Configurações, Conexões de Rede). Na tela que aparecerá você verá os adaptadores de redes localizados em seu computador. Em nosso caso, “Conexão de Rede Local 3” era o adaptador de rede que conectava nosso micro à Internet (em nosso roteador banda larga) e “Conexão de Rede Local 6” era o cabo USB-USB, veja na Figura 9. Figura 9: Conexões de rede. Clique com o botão direito do mouse na placa de rede que está conectando seu micro a Internet (“Conexão de Rede Local 3”, em nosso caso), clique em Propriedades e, na janela que aparecerá, clique na guia Avançado. Feito isso, marque a opção “Permitir que outros usuários da rede se conectem pela conexão deste computador à Internet”. Dependendo da sua versão do Windows XP, haverá uma caixa chamada “Conexão de rede caseira”, onde você deve selecionar a conexão do cabo USB (“Conexão de Rede Local 6”, em nosso caso). Figura 10: Habilitando o compartilhamento de Internet. Após ter feito esta configuração, você tem que reiniciar o micro para que tudo funcione adequadamente. Tente conectar a Internet no outro computador e verifique se tudo está funcionando bem. Para compartilhar arquivos e impressoras, você deve ler nosso tutorial Como Compartilhar Pastas e Impressoras na Rede para ver como isto pode ser feito. Se você não está usando um roteador de banda larga no computador que tem a conexão com a Internet, você deve ser muito cuidadoso, já que o compartilhamento de seus arquivos pode permitir que qualquer pessoa na Internet tenha acesso a eles. Leia mais sobre isso em nosso tutorial Protegendo seu Seu Micro Contra Invasões. Neste tutorial você encontrará alguns macetes para prevenir que um hacker tenha acesso a seus arquivos. Se o computador remoto não estiver acessando a Internet, verifique se o cabo USB está configurado para obter um endereço IP automaticamente na rede. Para isso, clique no menu Iniciar, Configurações, Conexões de Rede, e então clique com o botão direito do mouse na conexão do cabo (“Conexão de Rede Local 6”, em nosso caso), selecione Propriedades e, na janela que aparecerá, dê um duplo clique em “Protocolo Internet (TCP/IP)”. As duas opções desta tela devem estar configuradas como “automaticamente”, conforme mostramos na Figura 11. Ambos computadores devem ser configurados desta maneira. Figura 11: Configuração TCP/IP tem que estar configurada como automática nos computadores. -
Como Conectar Dois Micros Usando um Cabo USB-USB
Gabriel Torres postou um tópico em Comentários de artigos
Tópico para a discussão do seguinte conteúdo publicado no Clube do Hardware: Como Conectar Dois Micros Usando um Cabo USB-USB "Aprenda como conectar dois micros usando um cabo USB-USB para transferir aquivos e compartilhar sua conexão com a Internet." Comentários são bem-vindos. Atenciosamente, Equipe Clube do Hardware https://www.clubedohardware.com.br -
 Você está a fim de usufruir todo o potencial de som que seu micro pode oferecer? Instalando caixas de som surround de 6 canais é a melhor maneira: jogar jogos e assistir filmes não será mais a mesma coisa. Neste tutorial mostraremos a você um guia passo-a-passo de como conectar caixas de som analógicas 5.1 ao seu micro. O que é o sistema 5.1? O número “5.1” significa que você tem seis caixas: duas frontais, duas traseiras, uma central (também conhecida como “canal de voz”) e um subwoofer (também conhecido como “caixa de graves”). Dessa forma, você tem cinco caixas de som similares e uma exclusiva para sons graves – o subwoofer -, daí o nome “5.1”. Existe ainda um outro sistema de som de alto desempenho disponível, chamado “7.1”, que possui mais duas caixas, central direito e central esquerdo. Atualmente praticamente todos os micros possuem áudio de 6 canais on-board, ou seja, já possuem este recurso integrado à placa-mãe, mas você terá que verificar no manual da placa-mãe se o seu micro suporta ou não este recurso. Claro que se você tem uma placa de som “off-board” é no manual dela que você terá de procurar por esta informação. Existem dois tipos de caixas de som de 6 canais: analógico e digital. Caixas de som com conexão analógica podem ser instaladas em qualquer micro e são baratas, enquanto que as caixas de som com conexão digital são geralmente caras e requerem que seu micro tenha uma saída SPDIF. Neste tutorial falaremos sobre como conectar um sistema de caixas de som de 6 canais com conexão analógica. Se o seu micro possui saída SPDIF e você quer usar conexão digital – que oferece menos ruído – leia nosso tutorial sobre o assunto. Os passos descritos neste tutorial são exatamente os mesmos, mas em vez de conectar seu micro ao receiver de home theater, você irá conectá-lo ao sistema de caixas de som digital de 6 canais. Além do baixo nível de ruído, a conexão digital tem como principal vantagem a utilização de apenas um cabo para conectar o micro às caixas de som. A conexão analógica usa três conjuntos de cabos. Na Figura 1 você pode ver nossas caixas de som surround de 6 canais que iremos conectar ao nosso micro neste tutorial. Como dissemos, essas caixas utilizam conexão analógica. Figura 1: Nosso sistema de caixas de som de 6 canais. Antes de qualquer coisa, você deve dar uma boa olhada em suas caixas de som para entendê-las melhor. Como você pode ver na Figura 1, em nosso sistema o subwoofer e o controle de volume estão em unidades separadas, o que é muito bom, já que esta é a melhor maneira de colocarmos o subwoofer sob a mesa e a unidade de controle de volume sobre a mesa, fazendo com que o controle do sistema seja mais fácil. Primeiramente, vamos dar uma olhada nas caixas de som “comuns” do sistema (ver Figura 2). Como você pode ver, não existe mistério aqui. Cada caixa possui um cabo com dois fios conectado a um conector RCA macho. Figura 2: Uma das caixas de som de nosso sistema. Agora daremos uma olhada no subwoofer, ver Figura 3. Em alguns sistemas os cabos das caixas de som são conectados ao subwoofer. Em nosso sistema, no entanto, todos os cabos devem ser conectados à unidade de controle de volume, como você pode ver na Figura 4. Em nosso sistema, três conjuntos de fios partem do subwoofer: um cabo de força para conectar o sistema à tomada elétrica, um conector de alimentação para alimentar a unidade de controle de volume e os fios de áudio do subwoofer. Figura 3: O subwoofer. Como mencionamos, em nosso sistema todos os cabos devem ser conectados à unidade de controle de volume, como mostramos na Figura 4. Figura 4: Unidade de controle de volume. Junto com o seu sistema devem vir pelo menos três conjuntos de cabos para conectar suas caixas de som ao seu micro. Estes cabos podem ser vistos na Figura 5 e eles são coloridos para ajudar na instalação: verde, azul (ou preto) e laranja (ou amarelo ou rosa). Figura 5: Cabos que vieram com nosso sistema. Junto com nosso sistema vieram também três conversores de P2 estéreo (“mini jack”) para RCA, como você pode ver na Figura 6. Estes adaptadores têm de ser usados se você quiser conectar suas caixas de som ao seu aparelho de DVD de mesa, já que aparelhos de DVD usam conectores RCA, não plugues P2 (“mini jack”). Já que estamos conectando nossas caixas de som ao micro e não ao nosso aparelho de DVD de mesa, vamos guardar estes cabos em algum lugar. Figura 6: Adaptadores caso você queira conectar suas caixas de som em seu aparelho de DVD de mesa. Você deve conectar os cabos “casando” as cores dos conectores localizados na unidade de controle de volume. Não é nada complicado. De qualquer forma, falaremos brevemente sobre o significado de cada cor abaixo. Figura 7: Conectando os cabos na unidade de controle de volume. Entrada Frontal: Verde. Entrada Traseira: Azul ou Preto. Central/Subwoofer: Laranja, amarelo ou rosa. Após conectar esses cabos, você deve também conectar todos os outros cabos, como alimentação, subwoofer e caixas de som. Isto é muito simples de fazer. Preste atenção apenas na conexão do subwoofer, já que você deve seguir a polaridade que está escrita nos conectores. No final deste processo todos os conectores na unidade de controle de volume devem ter um cabo conectado. Todos computadores possuem pelo menos três conectores de áudio: Verde: Saída de linha. Azul: Entrada de linha. Rosa: Microfone. Nos computadores com seis canais de áudio, dois conectores adicionais são requeridos: saída traseira (preto ou azul) e saída central/subwoofer (laranja ou amarelo). No entanto, nem todos os computadores possuem essas saídas. Por isso, a primeira coisa a ser feita é olhar na parte de trás do seu micro e verificar suas saídas. O micro da Figura 8 possui todos eles além de saídas digitais (como mencionamos, se você quiser usar saída digital, leia nosso tutorial sobre o assunto . Figura 8: Saídas de áudio do micro. Se o seu computador não possui essas duas saídas extras (traseira e central/subwoofer), você precisará usar os plugues da entrada de linha e do microfone. Claro que existe uma grande desvantagem em usar esta configuração: você não pode usar seu microfone ou a entrada de linha e suas caixas de som 5.1 ao mesmo tempo. E mais: se você precisar usar essas entradas – talvez você queira conectar um microfone para usar o Skype ou o MSN Messenger, por exemplo – você precisará desconectar suas caixas de som toda vez que precisar usar seu microfone ou dispositivo de captura de áudio. Realmente dá a maior trabalheira. Por esse motivo recomendamos que, caso você realmente queira usar caixas de som 5.1, você use uma placa-mãe que possua saídas traseira e central/subwoofer separadas, como a que mostramos na Figura 8. Computadores com oito canais de áudio (7.1) requer um outro tipo de plugue para a caixa de som central (este plugue é geralmente cinza). Na Figura 9 você ver o detalhe da placa-mãe com áudio on-board de oito canais. Figura 9: Placa-mãe com áudio de oito canais (7.1). A instalação dependerá se o seu micro possui saídas separadas para saídas traseiras e central/subwoofer ou não. Mostraremos ambos cenários. Micros com Saídas Traseira e Central/Subwoofer Separadas Neste caso você deve fazer a conexão da seguinte forma: Cabo frontal (verde): No conector verde (saída de linha). Cabo traseiro (azul ou preto): No conector azul (não o que fica próximo ao conector verde) ou conector preto (saída traseira). Preste atenção já que o conector azul que estamos falando não é o mesmo que entrada de linha (veja na Figura 8). Cabo central/subwoofer (laranja, amarelo ou rosa): No conector laranja ou amarelo. Mostramos isto na Figura 10. Figura 10: Como conectar as caixas de com no micro com saídas traseira e central/subwoofer separadas. Você precisará agora configurar seu micro, como explicaremos na próxima página. Micro sem Saídas Traseira e Central/Subwoofer Separadas Neste caso você deve fazer a conexão da seguinte forma: Cabo frontal (verde): No conector verde (saída de linha). Cabo traseiro (azul ou preto): No conector azul (entrada de linha). Cabo central/subwoofer (laranja, amarelo ou rosa): No conector rosa. Mostramos isto na Figura 11 (por favor esqueça que nosso micro tinha saídas separadas). Figura 11: Como conectar as caixas de som a um micro sem saídas traseira e central/subwoofer separadas. Você precisará agora configurar seu micro, como mostraremos na próxima página. Após ter feito todas as conexões físicas, você deve configurar seu micro para usar o áudio de 6 canais. Isto é feito indo nas propriedade de áudio do driver da placa de som. Normalmente quando você instala seu driver de áudio um novo ícone é criado no Painel de Controle e um pequeno ícone é exibido próximo ao relógio do Windows. Em nosso micro, que usa drivers da Realtek, o ícone no painel de controle é chamado Sound Effect Management. Dê um duplo clique nele e então clique na guia Configuração dos Altifalantes para exibir a janela mostrada na Figura 12. Nessa janela você deve selecionar “modo 6 canais para altifalantes 5.1” e marque a opção “Only SURROUND-KIT” se o seu micro possui saídas traseira e central/subwoofer separadas (que era o nosso caso). Figura 12: Configurando o micro para usar áudio de 6 canais. É isto. Agora seu micro está configurado para usar o sistema de caixas de som 5.1. Divirta-se!
Você está a fim de usufruir todo o potencial de som que seu micro pode oferecer? Instalando caixas de som surround de 6 canais é a melhor maneira: jogar jogos e assistir filmes não será mais a mesma coisa. Neste tutorial mostraremos a você um guia passo-a-passo de como conectar caixas de som analógicas 5.1 ao seu micro. O que é o sistema 5.1? O número “5.1” significa que você tem seis caixas: duas frontais, duas traseiras, uma central (também conhecida como “canal de voz”) e um subwoofer (também conhecido como “caixa de graves”). Dessa forma, você tem cinco caixas de som similares e uma exclusiva para sons graves – o subwoofer -, daí o nome “5.1”. Existe ainda um outro sistema de som de alto desempenho disponível, chamado “7.1”, que possui mais duas caixas, central direito e central esquerdo. Atualmente praticamente todos os micros possuem áudio de 6 canais on-board, ou seja, já possuem este recurso integrado à placa-mãe, mas você terá que verificar no manual da placa-mãe se o seu micro suporta ou não este recurso. Claro que se você tem uma placa de som “off-board” é no manual dela que você terá de procurar por esta informação. Existem dois tipos de caixas de som de 6 canais: analógico e digital. Caixas de som com conexão analógica podem ser instaladas em qualquer micro e são baratas, enquanto que as caixas de som com conexão digital são geralmente caras e requerem que seu micro tenha uma saída SPDIF. Neste tutorial falaremos sobre como conectar um sistema de caixas de som de 6 canais com conexão analógica. Se o seu micro possui saída SPDIF e você quer usar conexão digital – que oferece menos ruído – leia nosso tutorial sobre o assunto. Os passos descritos neste tutorial são exatamente os mesmos, mas em vez de conectar seu micro ao receiver de home theater, você irá conectá-lo ao sistema de caixas de som digital de 6 canais. Além do baixo nível de ruído, a conexão digital tem como principal vantagem a utilização de apenas um cabo para conectar o micro às caixas de som. A conexão analógica usa três conjuntos de cabos. Na Figura 1 você pode ver nossas caixas de som surround de 6 canais que iremos conectar ao nosso micro neste tutorial. Como dissemos, essas caixas utilizam conexão analógica. Figura 1: Nosso sistema de caixas de som de 6 canais. Antes de qualquer coisa, você deve dar uma boa olhada em suas caixas de som para entendê-las melhor. Como você pode ver na Figura 1, em nosso sistema o subwoofer e o controle de volume estão em unidades separadas, o que é muito bom, já que esta é a melhor maneira de colocarmos o subwoofer sob a mesa e a unidade de controle de volume sobre a mesa, fazendo com que o controle do sistema seja mais fácil. Primeiramente, vamos dar uma olhada nas caixas de som “comuns” do sistema (ver Figura 2). Como você pode ver, não existe mistério aqui. Cada caixa possui um cabo com dois fios conectado a um conector RCA macho. Figura 2: Uma das caixas de som de nosso sistema. Agora daremos uma olhada no subwoofer, ver Figura 3. Em alguns sistemas os cabos das caixas de som são conectados ao subwoofer. Em nosso sistema, no entanto, todos os cabos devem ser conectados à unidade de controle de volume, como você pode ver na Figura 4. Em nosso sistema, três conjuntos de fios partem do subwoofer: um cabo de força para conectar o sistema à tomada elétrica, um conector de alimentação para alimentar a unidade de controle de volume e os fios de áudio do subwoofer. Figura 3: O subwoofer. Como mencionamos, em nosso sistema todos os cabos devem ser conectados à unidade de controle de volume, como mostramos na Figura 4. Figura 4: Unidade de controle de volume. Junto com o seu sistema devem vir pelo menos três conjuntos de cabos para conectar suas caixas de som ao seu micro. Estes cabos podem ser vistos na Figura 5 e eles são coloridos para ajudar na instalação: verde, azul (ou preto) e laranja (ou amarelo ou rosa). Figura 5: Cabos que vieram com nosso sistema. Junto com nosso sistema vieram também três conversores de P2 estéreo (“mini jack”) para RCA, como você pode ver na Figura 6. Estes adaptadores têm de ser usados se você quiser conectar suas caixas de som ao seu aparelho de DVD de mesa, já que aparelhos de DVD usam conectores RCA, não plugues P2 (“mini jack”). Já que estamos conectando nossas caixas de som ao micro e não ao nosso aparelho de DVD de mesa, vamos guardar estes cabos em algum lugar. Figura 6: Adaptadores caso você queira conectar suas caixas de som em seu aparelho de DVD de mesa. Você deve conectar os cabos “casando” as cores dos conectores localizados na unidade de controle de volume. Não é nada complicado. De qualquer forma, falaremos brevemente sobre o significado de cada cor abaixo. Figura 7: Conectando os cabos na unidade de controle de volume. Entrada Frontal: Verde. Entrada Traseira: Azul ou Preto. Central/Subwoofer: Laranja, amarelo ou rosa. Após conectar esses cabos, você deve também conectar todos os outros cabos, como alimentação, subwoofer e caixas de som. Isto é muito simples de fazer. Preste atenção apenas na conexão do subwoofer, já que você deve seguir a polaridade que está escrita nos conectores. No final deste processo todos os conectores na unidade de controle de volume devem ter um cabo conectado. Todos computadores possuem pelo menos três conectores de áudio: Verde: Saída de linha. Azul: Entrada de linha. Rosa: Microfone. Nos computadores com seis canais de áudio, dois conectores adicionais são requeridos: saída traseira (preto ou azul) e saída central/subwoofer (laranja ou amarelo). No entanto, nem todos os computadores possuem essas saídas. Por isso, a primeira coisa a ser feita é olhar na parte de trás do seu micro e verificar suas saídas. O micro da Figura 8 possui todos eles além de saídas digitais (como mencionamos, se você quiser usar saída digital, leia nosso tutorial sobre o assunto . Figura 8: Saídas de áudio do micro. Se o seu computador não possui essas duas saídas extras (traseira e central/subwoofer), você precisará usar os plugues da entrada de linha e do microfone. Claro que existe uma grande desvantagem em usar esta configuração: você não pode usar seu microfone ou a entrada de linha e suas caixas de som 5.1 ao mesmo tempo. E mais: se você precisar usar essas entradas – talvez você queira conectar um microfone para usar o Skype ou o MSN Messenger, por exemplo – você precisará desconectar suas caixas de som toda vez que precisar usar seu microfone ou dispositivo de captura de áudio. Realmente dá a maior trabalheira. Por esse motivo recomendamos que, caso você realmente queira usar caixas de som 5.1, você use uma placa-mãe que possua saídas traseira e central/subwoofer separadas, como a que mostramos na Figura 8. Computadores com oito canais de áudio (7.1) requer um outro tipo de plugue para a caixa de som central (este plugue é geralmente cinza). Na Figura 9 você ver o detalhe da placa-mãe com áudio on-board de oito canais. Figura 9: Placa-mãe com áudio de oito canais (7.1). A instalação dependerá se o seu micro possui saídas separadas para saídas traseiras e central/subwoofer ou não. Mostraremos ambos cenários. Micros com Saídas Traseira e Central/Subwoofer Separadas Neste caso você deve fazer a conexão da seguinte forma: Cabo frontal (verde): No conector verde (saída de linha). Cabo traseiro (azul ou preto): No conector azul (não o que fica próximo ao conector verde) ou conector preto (saída traseira). Preste atenção já que o conector azul que estamos falando não é o mesmo que entrada de linha (veja na Figura 8). Cabo central/subwoofer (laranja, amarelo ou rosa): No conector laranja ou amarelo. Mostramos isto na Figura 10. Figura 10: Como conectar as caixas de com no micro com saídas traseira e central/subwoofer separadas. Você precisará agora configurar seu micro, como explicaremos na próxima página. Micro sem Saídas Traseira e Central/Subwoofer Separadas Neste caso você deve fazer a conexão da seguinte forma: Cabo frontal (verde): No conector verde (saída de linha). Cabo traseiro (azul ou preto): No conector azul (entrada de linha). Cabo central/subwoofer (laranja, amarelo ou rosa): No conector rosa. Mostramos isto na Figura 11 (por favor esqueça que nosso micro tinha saídas separadas). Figura 11: Como conectar as caixas de som a um micro sem saídas traseira e central/subwoofer separadas. Você precisará agora configurar seu micro, como mostraremos na próxima página. Após ter feito todas as conexões físicas, você deve configurar seu micro para usar o áudio de 6 canais. Isto é feito indo nas propriedade de áudio do driver da placa de som. Normalmente quando você instala seu driver de áudio um novo ícone é criado no Painel de Controle e um pequeno ícone é exibido próximo ao relógio do Windows. Em nosso micro, que usa drivers da Realtek, o ícone no painel de controle é chamado Sound Effect Management. Dê um duplo clique nele e então clique na guia Configuração dos Altifalantes para exibir a janela mostrada na Figura 12. Nessa janela você deve selecionar “modo 6 canais para altifalantes 5.1” e marque a opção “Only SURROUND-KIT” se o seu micro possui saídas traseira e central/subwoofer separadas (que era o nosso caso). Figura 12: Configurando o micro para usar áudio de 6 canais. É isto. Agora seu micro está configurado para usar o sistema de caixas de som 5.1. Divirta-se! -
Tópico para a discussão do seguinte conteúdo publicado no Clube do Hardware: Como Funciona a Tecnologia de Execução Confiável (TXT) da Intel "Tudo o que você precisa saber sobre a Tecnologia LaGrande da Intel, que é uma nova tecnologia de segurança e que estará disponível na próxima geração dos processadores da Intel (Merom, Conroe e Woodcrest)." Comentários são bem-vindos. Atenciosamente, Equipe Clube do Hardware https://www.clubedohardware.com.br
-
 A tecnologia de execução confiável (TXT, Trusted eXecution Technology), codinome LaGrande, é uma nova tecnologia de segurança que estará disponível na próxima geração dos processadores da Intel (Merom, Conroe e Woodcrest) que será lançada em 2006. Neste tutorial explicaremos suas principais características e como elas funcionam. Atualmente todos usuários estão vulneráveis a várias ameaças que comprometem a sua segurança. Não estamos falando apenas de vírus e/ou spyware, mas também de outros tipos de ameaças como de alguém roubando sua senha ou até mesmo sua identidade. Na Figura 1 você pode encontrar um resumo do porque isto acontece. Figura 1: Pontos de Vulnerabilidade do PC. O problema, como você pode ver na Figura 1, é que qualquer programa pode ter acesso a: Memória de Vídeo: qualquer programa pode criar telas “falsas” ou “ver” o que o usuário está vendo. Dispositivos de entrada: qualquer programa pode “ver” ou alterar o que o usuário está digitando. Memória: qualquer programa pode ver o que está armazenado na memória RAM, e por isso programas maliciosos podem capturar ou alterar dados dentro da memória RAM do micro. DMA: programas podem acessar a memória protegida usando o controlador de DMA. O que a tecnologia LaGrande faz é basicamente tratar dessas questões, criando uma camada de proteção baseada em hardware para cada um desses pontos fracos presentes em seu computador. A tecnologia LaGrande oferece as seguintes características: Execução Protegida: o programa pode ser executado em um modo isolado onde nenhum outro programa pode ter acesso a seu código e dados. Esta técnica é também conhecida como Separação de Domínio. Armazenamento Selado: Os dados são armazenados de forma criptografada e podem ser decriptografados apenas pelo mesmo ambiente onde foram armazenados. Entrada Protegida: Protege os dispositivos de entrada (mouse e teclado) de serem lidos ou terem seus dados alterados por programas maliciosos. A tecnologia LaGrande faz isso criptografando os comandos enviados pelo teclado e mouse e, portanto, apenas o software que tem a chave criptográfica correta pode ter acesso a esses comandos. Vídeo Protegido: Cria um caminho seguro entre aplicações rodando dentro da área de execução protegida e a memória de vídeo localizada na placa de vídeo. Com isso, nenhum outro programa pode ver ou alterar o que está sendo escrito na tela. Atestação: Uma atestação baseada em hardware de que o ambiente protegido pela Tecnologia LaGrande está seguro. Isto é oferecido por um módulo chamado TPM (Trusted Platform Module, Módulo de Plataforma Confiável). Entre outras coisas, o TPM fornece um Gerador de Números Aleatórios (RNG, Random Number Generator) e também armazena as chaves criptográficas usadas pela tecnologia LaGrande. Inicialização Protegida: Controla o carregamento do sistema operacional no ambiente de execução protegida. Figura 2: Um micro com Tecnologia LaGrande. Figura 3: Como a Tecnologia LaGrande resolve as vulnerabilidades do micro. Falaremos agora um pouco mais sobre algumas dessas características. Como explicamos, a Execução Protegida permite que programas sejam executados dentro de um ambiente protegido, onde nenhum outro programa pode ter acesso aos recursos utilizados por eles, especialmente a memória RAM – isto é, os dados sendo manipulados e gerados pelo programa. Os recursos também incluem dispositivos e processos em execução (por exemplo, o próprio programa). Figura 4: Visão geral da execução protegida. Como você pode ver na Figura 5, a execução protegida é controlada por uma nova camada chamada Gerenciador de Domínio. Para funcionar, esta camada precisa de um processador e chipset com a Tecnologia LaGrande e um TPM (Módulo de Plataforma Confiável). Figura 5: Arquitetura da execução protegida. É interessante notar que você pode rodar tanto programas protegidos quanto programas sem proteção ao mesmo tempo em um micro dotado da tecnologia LaGrande. Esta característica cria um canal confiável entre dispositivos de entrada tais como mouse e teclado e o PC. Como os dados transferidos entre os dispositivos de entrada e o PC usando esta característica são criptografados, você precisará de um novo mouse e de um novo teclado com capacidade de criptografia de modo a usufruir desta característica. Se você usar mouse e teclados convencionais esta característica não funcionará. Figura 6: O que é um canal confiável. Figura 7: Visão geral da entrada protegida. Esta característica cria um canal confiável entre programas e a placa de vídeo. Dessa forma, nenhum outro programa pode ler ou alterar dados que estejam sendo enviados para o monitor pelo programa protegido. Para funcionar, no entanto, você precisa ter uma placa de vídeo que possua esta característica. Até onde sabemos, as placas de vídeo disponíveis hoje no mercado não podem ser usadas para criar este ambiente de proteção, já que elas não possuem a Tecnologia LaGrande. Por outro lado, como a Tecnologia LaGrande precisa de uma nova geração de chipsets, ao que tudo indica a Intel lançará chipsets com vídeo “on-board” suportando esta característica. Figura 8: Visão geral do vídeo protegido. É muito cedo para sabermos se a Tecnologia LaGrande terá sucesso ou não. É uma grande ideia, sem sombra de dúvidas, mas ela requer uma série de pré-requisitos que duvidamos se o usuário médio irá utilizá-la. Para resumir, para ter um micro com a Tecnologia LaGrande 100% habilitada você precisará ter: Processador com Tecnologia LaGrande; Chipset com Tecnologia LaGrande; Dispositivos de entrada (novo mouse e novo teclado) com Tecnologia LaGrande; Placa de vídeo com Tecnologia LaGrande (nova placa de vídeo ou vídeo “on-board” com tecnologia LaGrande oferecido pela nova geração de chipsets da Intel); Dispositivo TPM na placa-mãe (isto é Gerador de Número Aleatório e memória não-volátil para o armazenamento das chaves criptográficas); Software de Gerenciamento de Domínio; Sistema operacional com Tecnologia LaGrande habilitada; E o que é mais interessante: nenhum desses estão disponíveis hoje. Portanto, teremos que aguardar o lançamento da próxima geração dos processadores da Intel (Merom, Conroe e Woodcrest) para ver o que acontece no mercado. Tenha em mente que não está claro se a Intel manterá o nome-código LaGrande ou irá usar um outro nome comercial para esta tecnologia.
A tecnologia de execução confiável (TXT, Trusted eXecution Technology), codinome LaGrande, é uma nova tecnologia de segurança que estará disponível na próxima geração dos processadores da Intel (Merom, Conroe e Woodcrest) que será lançada em 2006. Neste tutorial explicaremos suas principais características e como elas funcionam. Atualmente todos usuários estão vulneráveis a várias ameaças que comprometem a sua segurança. Não estamos falando apenas de vírus e/ou spyware, mas também de outros tipos de ameaças como de alguém roubando sua senha ou até mesmo sua identidade. Na Figura 1 você pode encontrar um resumo do porque isto acontece. Figura 1: Pontos de Vulnerabilidade do PC. O problema, como você pode ver na Figura 1, é que qualquer programa pode ter acesso a: Memória de Vídeo: qualquer programa pode criar telas “falsas” ou “ver” o que o usuário está vendo. Dispositivos de entrada: qualquer programa pode “ver” ou alterar o que o usuário está digitando. Memória: qualquer programa pode ver o que está armazenado na memória RAM, e por isso programas maliciosos podem capturar ou alterar dados dentro da memória RAM do micro. DMA: programas podem acessar a memória protegida usando o controlador de DMA. O que a tecnologia LaGrande faz é basicamente tratar dessas questões, criando uma camada de proteção baseada em hardware para cada um desses pontos fracos presentes em seu computador. A tecnologia LaGrande oferece as seguintes características: Execução Protegida: o programa pode ser executado em um modo isolado onde nenhum outro programa pode ter acesso a seu código e dados. Esta técnica é também conhecida como Separação de Domínio. Armazenamento Selado: Os dados são armazenados de forma criptografada e podem ser decriptografados apenas pelo mesmo ambiente onde foram armazenados. Entrada Protegida: Protege os dispositivos de entrada (mouse e teclado) de serem lidos ou terem seus dados alterados por programas maliciosos. A tecnologia LaGrande faz isso criptografando os comandos enviados pelo teclado e mouse e, portanto, apenas o software que tem a chave criptográfica correta pode ter acesso a esses comandos. Vídeo Protegido: Cria um caminho seguro entre aplicações rodando dentro da área de execução protegida e a memória de vídeo localizada na placa de vídeo. Com isso, nenhum outro programa pode ver ou alterar o que está sendo escrito na tela. Atestação: Uma atestação baseada em hardware de que o ambiente protegido pela Tecnologia LaGrande está seguro. Isto é oferecido por um módulo chamado TPM (Trusted Platform Module, Módulo de Plataforma Confiável). Entre outras coisas, o TPM fornece um Gerador de Números Aleatórios (RNG, Random Number Generator) e também armazena as chaves criptográficas usadas pela tecnologia LaGrande. Inicialização Protegida: Controla o carregamento do sistema operacional no ambiente de execução protegida. Figura 2: Um micro com Tecnologia LaGrande. Figura 3: Como a Tecnologia LaGrande resolve as vulnerabilidades do micro. Falaremos agora um pouco mais sobre algumas dessas características. Como explicamos, a Execução Protegida permite que programas sejam executados dentro de um ambiente protegido, onde nenhum outro programa pode ter acesso aos recursos utilizados por eles, especialmente a memória RAM – isto é, os dados sendo manipulados e gerados pelo programa. Os recursos também incluem dispositivos e processos em execução (por exemplo, o próprio programa). Figura 4: Visão geral da execução protegida. Como você pode ver na Figura 5, a execução protegida é controlada por uma nova camada chamada Gerenciador de Domínio. Para funcionar, esta camada precisa de um processador e chipset com a Tecnologia LaGrande e um TPM (Módulo de Plataforma Confiável). Figura 5: Arquitetura da execução protegida. É interessante notar que você pode rodar tanto programas protegidos quanto programas sem proteção ao mesmo tempo em um micro dotado da tecnologia LaGrande. Esta característica cria um canal confiável entre dispositivos de entrada tais como mouse e teclado e o PC. Como os dados transferidos entre os dispositivos de entrada e o PC usando esta característica são criptografados, você precisará de um novo mouse e de um novo teclado com capacidade de criptografia de modo a usufruir desta característica. Se você usar mouse e teclados convencionais esta característica não funcionará. Figura 6: O que é um canal confiável. Figura 7: Visão geral da entrada protegida. Esta característica cria um canal confiável entre programas e a placa de vídeo. Dessa forma, nenhum outro programa pode ler ou alterar dados que estejam sendo enviados para o monitor pelo programa protegido. Para funcionar, no entanto, você precisa ter uma placa de vídeo que possua esta característica. Até onde sabemos, as placas de vídeo disponíveis hoje no mercado não podem ser usadas para criar este ambiente de proteção, já que elas não possuem a Tecnologia LaGrande. Por outro lado, como a Tecnologia LaGrande precisa de uma nova geração de chipsets, ao que tudo indica a Intel lançará chipsets com vídeo “on-board” suportando esta característica. Figura 8: Visão geral do vídeo protegido. É muito cedo para sabermos se a Tecnologia LaGrande terá sucesso ou não. É uma grande ideia, sem sombra de dúvidas, mas ela requer uma série de pré-requisitos que duvidamos se o usuário médio irá utilizá-la. Para resumir, para ter um micro com a Tecnologia LaGrande 100% habilitada você precisará ter: Processador com Tecnologia LaGrande; Chipset com Tecnologia LaGrande; Dispositivos de entrada (novo mouse e novo teclado) com Tecnologia LaGrande; Placa de vídeo com Tecnologia LaGrande (nova placa de vídeo ou vídeo “on-board” com tecnologia LaGrande oferecido pela nova geração de chipsets da Intel); Dispositivo TPM na placa-mãe (isto é Gerador de Número Aleatório e memória não-volátil para o armazenamento das chaves criptográficas); Software de Gerenciamento de Domínio; Sistema operacional com Tecnologia LaGrande habilitada; E o que é mais interessante: nenhum desses estão disponíveis hoje. Portanto, teremos que aguardar o lançamento da próxima geração dos processadores da Intel (Merom, Conroe e Woodcrest) para ver o que acontece no mercado. Tenha em mente que não está claro se a Intel manterá o nome-código LaGrande ou irá usar um outro nome comercial para esta tecnologia. -
Tópico para a discussão do seguinte conteúdo publicado no Clube do Hardware: Como os Processadores Funcionam "Leia sobre como funcionam os processadores, incluindo tópicos sobre clock, memória cache, diagrama em blocos de um processador, pipeline, arquitetura superescalar, execução fora de ordem e execução especulativa." Comentários são bem-vindos. Atenciosamente, Equipe Clube do Hardware https://www.clubedohardware.com.br
-
 Apesar de cada microprocessador ter seu próprio desenho interno, todos os microprocessadores compartilham do mesmo conceito básico – o qual explicaremos neste tutorial. Daremos uma olhada dentro da arquitetura de um processador genérico, para que assim você seja capaz de entender um pouco mais sobre os produtos da Intel e da AMD, bem como as diferenças entre eles. O processador – que também é chamado de microprocessador, CPU (Central Processing Unit) ou UCP (Unidade Central de Processamento) – é o encarregado de processar informações. Como ele vai processar as informações vai depender do programa. O programa pode ser uma planilha, um processador de textos ou um jogo: para o processador isso não faz a menor diferença, já que ele não entende o que o programa está realmente fazendo. Ele apenas obedece às ordens (chamadas comandos ou instruções) contidas no programa. Essas ordens podem ser para somar dois números ou para enviar uma informação para a placa de vídeo, por exemplo. Quando você clica duas vezes em um ícone para rodar um programa, veja o que acontece: 1. O programa, que está armazenado no disco rígido, é transferido para a memória. Um programa é uma série de instruções para o processador. 2. O processador, usando um circuito chamado controlador de memória, carrega as informações do programa da memória RAM. 3. As informações, agora dentro do processador, são processadas. 4. O que acontece a seguir vai depender do programa. O processador pode continuar a carregar e executar o programa ou pode fazer alguma coisa com a informação processada, como mostrar algo na tela. Figura 1: Como a informação armazenada é transferida para o processador. No passado, o processador controlava a transferência de informações entre o disco rígido e a memória RAM. Como o disco rígido é mais lento que a memória RAM, isso deixava o sistema lento, já que o processador ficava ocupado até que todas as informações fossem transferidas do disco rígido para a memória RAM. Esse método é chamado PIO (Programmed Input/Output - Entrada/Saída Programada). Hoje em dia a transferência de informações entre o disco rígido e a memória RAM é feita sem o uso do processador, tornando, assim, o sistema mais rápido. Esse método é chamado bus mastering ou DMA (Direct Memory Access - Acesso Direto à Memória). Para simplificar nosso desenho, não colocamos o chip da ponte norte entre o disco rígido e a memória RAM na Figura 1, mas ele está lá. Caso deseje saber mais sobre esse assunto, nós já escrevemos um tutorial sobre isso. Processadores da AMD baseados nos soquetes 754, 939 e 940 (Athlon 64, Athlon 64 X2, Athlon 64 FX, Opteron e alguns modelos de Sempron) possuem controlador de memória embutido. Isso significa que para esses processadores a CPU acessa a memória RAM diretamente, sem usar o chip da ponte norte mostrado na Figura 1. Para melhor compreender o papel do chipset em um computador, nós recomendamos a leitura do nosso tutorial Tudo o Que Você Precisa Saber Sobre Chipsets. Afinal, o que vem a ser clock? Clock é um sinal usado para sincronizar coisas dentro do computador. Dê uma olhada na Figura 2, onde mostramos um típico sinal de clock: é uma onda quadrada passando de “0” a “1” a uma taxa fixa. Nessa figura você pode ver três ciclos de clock (“pulsos”) completos. O início de cada ciclo é quando o sinal de clock passa de “0” a “1”; nós marcamos isso com uma seta. O sinal de clock é medido em uma unidade chamada Hertz (Hz), que é o número de ciclos de clock por segundo. Um clock de 100 MHz significa que em um segundo existem 100 milhões de ciclos de clock. Figura 2: Sinal de clock. No computador, todas as medidas de tempo são feitas em termos de ciclos de clock. Por exemplo, uma memória RAM com latência “5” significa que vai levar cinco ciclos de clock completos para começar a transferência de dados. Dentro da CPU, todas as instruções precisam de um certo número de ciclos de clock para serem executadas. Por exemplo, uma determinada instrução pode levar sete ciclos de clock para ser completamente executada. No que diz respeito ao processador, o interessante é que ele sabe quantos ciclos de clock cada instrução vai demorar, porque ele tem uma tabela que lista essas informações. Então se há duas instruções para serem executadas e ele sabe que a primeira vai levar sete ciclos de clock para ser executada, ele vai automaticamente começar a execução da próxima instrução no 8o pulso de clock. É claro que esta é uma explicação genérica para um processador com apenas uma unidade de execução – processadores modernos possuem várias unidades de execução trabalhando em paralelo e podem executar a segunda instrução ao mesmo tempo em que a primeira, em paralelo. A isso chamamos arquitetura superescalar e falaremos mais a esse respeito mais tarde. Então o que o clock tem a ver com desempenho? Pensar que clock e desempenho são a mesma coisa é o erro mais comum acerca de processadores. Se você comparar dois processadores completamente idênticos, o que estiver rodando a uma taxa de clock mais alta será o mais rápido. Neste caso, com uma taxa de clock mais alta, o tempo entre cada ciclo de clock será menor, então as tarefas serão desempenhadas em menos tempo e o desempenho será mais alto. Mas quando você compara dois processadores diferentes, isso não é necessariamente verdadeiro. Se você pegar dois processadores com diferentes arquiteturas – por exemplo, de dois fabricantes diferentes, como Intel e AMD – o interior deles será completamente diferente. Como dissemos, cada instrução demora um certo número de ciclos de clock para ser executada. Digamos que o processador “A” demore sete ciclos de clock para executar uma determinada instrução, e que o processador “B” leve cinco ciclos de clock para executar essa mesma instrução. Se eles estiverem rodando com a mesma taxa de clock, o processador “B” será mais rápido, porque pode processar essa instrução em menos tempo. E há ainda muito mais no jogo do desempenho em processadores modernos, pois processadores têm quantidades diferentes de unidades de execução, tamanhos de cache diferentes, formas diferentes de transferência de dados dentro do processador, formas diferentes de processar instruções dentro das unidades de execução, diferentes taxas de clock com o mundo exterior, etc. Não se preocupe, pois nós falaremos sobre tudo isso neste tutorial. Como o sinal de clock do processador ficou muito alto, surgiu um problema. A placa-mãe onde o processador é instalado não podia funcionar usando o mesmo sinal de clock.Se você olhar para uma placa-mãe, verá várias trilhas ou caminhos. Essas trilhas são fios que conectam vários circuitos do computador. O problema é que, com taxas de clock mais altas, esses fios começaram a funcionar como antenas, por isso o sinal, em vez de chegar à outra extremidade do fio, simplesmente desaparecia, sendo transmitido como onda de rádio. Figura 3: Os fios na placa-mãe podem funcionar como antenas. Os fabricantes de processadores começaram a usar, então, um novo conceito, chamado multiplicação de clock, que começou com o processador 486DX2. Com esse esquema, que é usado em todos os processadores atualmente, o processador tem um clock externo, que é usado quando dados são transferidos de e para a memória RAM (usando o chip da ponte norte), e um clock interno mais alto. Para darmos um exemplo real, em um Pentium 4 de 3,4 GHz, estes “3,4 GHz” referem-se ao clock interno do processador, que é obtido quando multiplicamos por 17 seu clock externo de 200 MHz. Nós ilustramos esse exemplo na Figura 4. Figura 4: Clocks interno e externo em um Pentium 4 de 3,4 GHz. A grande diferença entre o clock interno e o clock externo em processadores modernos é uma grande barreira a ser transposta visando aumentar o desempenho do computador. Continuando com o exemplo do Pentium 4 de 3,4 GHz, ele tem que reduzir sua velocidade em 17x quando tem que ler dados da memória RAM! Durante esse processo, ele funciona como se fosse um processador de 200 MHz! Diversas técnicas são usadas para minimizar o impacto dessa diferença de clock. Um deles é o uso de memória cache dentro do processador. Outra é transferir mais de um dado por pulso de clock. Processadores tanto da AMD como da Intel usam esse recurso, mas enquanto os processadores da AMD transferem dois dados por ciclo de clock, os da Intel transferem quatro dados por ciclo de clock. Figura 5: Transferindo mais de um dado por ciclo de clock. Por causa disso, os processadores da AMD são listados como se tivessem o dobro de seus verdadeiros clocks externos. Por exemplo, um processador da AMD com clock externo de 200 MHz é listado como tendo 400 MHz. O mesmo acontece com processadores da Intel com clock externo de 200 MHz, que são listados como se tivessem clock externo de 800 MHz. A técnica de transferir dois dados por ciclo de clock é chamada DDR (Dual Data Rate), enquanto que a técnica de transferir quatro dados por ciclo de clock é chamada QDR (Quad Data Rate). Na Figura 6 você pode ver um diagrama em blocos básico de um processador moderno. São muitas as diferenças entre as arquiteturas da AMD e da Intel, e planejamos escrever artigos específicos sobre cada uma delas num futuro próximo. Acreditamos que entender o diagrama em blocos básico de um processador moderno seja o primeiro passo para entender como funcionam os processadores da Intel e da AMD e quais são as diferenças entre eles. Figura 6: Diagrama em blocos básico de um processador. A linha pontilhada na Figura 6 representa o corpo do processador, já que a memória RAM está localizada fora do processador. O caminho de dados entre a memória RAM e a CPU tem geralmente largura de 64 bits (ou de 128 bits quando é usada configuração de memória “dual channel”), rodando ao clock da memória ou ao clock externo do processador, o que for mais baixo. O número de bits usado e a taxa de clock podem ser combinados em uma unidade chamada taxa de transferência, medida em MB/s. Para calcular a taxa de transferência, a fórmula é o número de bits x clock / 8. Para um sistema usando memórias DDR400 em configuração single channel (64 bits) a taxa de transferência da memória será de 3.200 MB/s, ao passo que o mesmo sistema usando memórias dual channel (128 bits) terá taxa de transferência de memória de 6.400 MB/s. Para mais informações sobre esse assunto, leia nosso tutorial Memórias DDR Dual Channel. Todos os circuitos dentro da caixa pontilhada rodam no mesmo clock interno do processador. Dependendo do processador, algumas de suas partes internas podem até mesmo rodar a uma taxa de clock mais alta. Além disso, o caminho de dados entre as unidades do processador pode ser mais largo, isto é, transferir mais bits por ciclo de clock do que 64 ou 128. Por exemplo, o caminho de dados entre a memória cache L2 e o cache de instrução L1 em processadores modernos tem normalmente 256 bits de largura. Quanto maior o número de bits transferidos por ciclo de clock, mais rápida a transferência será feita (em outras palavras, a taxa de transferência será mais alta). Na Figura 5 usamos uma seta vermelha entre a memória RAM e a memória cache L2 e setas verdes entre todos os outros blocos para expressar as diferentes taxas de clock e largura de caminho de dados usadas. Memória cache é um tipo de memória de alto desempenho, também chamada memória estática. O tipo de memória usado na memória RAM principal do computador é chamado memória dinâmica. A memória estática consome mais energia, é mais cara e é fisicamente maior que a memória dinâmica, mas é muito mais rápida. Ela pode trabalhar no mesmo clock do processador, o que a memória dinâmica não é capaz de fazer. Já que ir ao “mundo exterior” para buscar dados faz com que o processador trabalhe a uma taxa de clock inferior, a técnica da memória cache é usada. Quando o processador carrega um dado de uma certa posição da memória, um circuito chamado controlador de memória cache (não desenhado na Figura 6 em prol da simplicidade) carrega na memória cache um bloco inteiro de dados abaixo da atual posição que o processador acabou de carregar. Como normalmente os programas rodam de maneira seqüencial, a próxima posição de memória que o processador irá requisitar será provavelmente a posição imediatamente abaixo da posição da memória que ela acabou de carregar. Como o controlador de memória cache já carregou um monte de dados abaixo da primeira posição de memória lida pelo processador, o próximo dado estará dentro da memória cache, portanto o processador não precisa “sair” para buscar os dados: eles já estão carregados na memória cache embutida no processador, os quais ela pode acessar à sua taxa de clock interna. O controlador de cache está sempre observando as posições de memória que estão sendo carregadas e carregando dados de várias posições de memória depois da posição de memória que acaba de ser lida. Para darmos um exemplo real, se o processador carregou dados armazenados no endereço 1.000, o controlador de cache carregará dados do endereço “n” após o endereço 1.000. Esse número “n” é chamado página; se um dado processador está trabalhando com páginas de 4 KB (que é um valor típico), ele carregará dados de 4.096 endereços abaixo da atual posição de memória que está sendo carregada (endereço 1.000 em nosso exemplo). A propósito, 1 KB é igual a 1.024 bytes, por isso 4 KB é igual a 4.096 e não 4.000. Na Figura 7 nós ilustramos esse exemplo. Figura 7: Como funciona o controlador de memória cache. Quanto maior a memória cache, maiores são as chances de que a informação necessária ao processador já esteja lá, então o processador precisará acessar diretamente a memória RAM com menos freqüência, e assim aumentando o desempenho do sistema (apenas lembre-se que toda vez que o processador precisa acessar a memória RAM diretamente, ele precisa diminuir sua taxa de clock para essa operação). Chamamos de “acerto” (“hit”) quando o processador carrega uma informação requisitada do cache, e de “erro” (“miss”) se a informação requisitada não está lá e o processador precise acessar a memória RAM do sistema. L1 e L2 significam “nível 1” (Level 1) e “nível 2” (“Level 2”), respectivamente, e referem-se à distância em que se encontram do núcleo do processador (unidade de execução). Uma dúvida comum é porque ter três memórias cache distintas (cache de dados L1, cache de instrução L1 e L2). Preste atenção na Figura 6 e você verá que o cache de instrução L1 funciona como “cache de entrada”, enquanto o cache de dados L1 funciona como “cache de saída”. O cache de instrução L1 – que é geralmente menor que o cache L2 – é particularmente eficiente quando o programa começa a repetir uma pequena parte dele (loop), porque as instruções requisitadas estarão mais próximas da unidade de busca. Na página de especificações de um processador o cache L1 pode ser encontrado com diferentes tipos de representação. Alguns fabricantes listam duas memórias cache L1 separadamente (algumas vezes chamando o cache de instrução de “I” e o cache de dados de “D”), alguns acrescentam a soma dos dois e escrevem “separados” – então “128 KB, separados” significa 64 KB cache de instrução e 64 KB de cache de dados –, e alguns simplesmente somam os dois e você tem que adivinhar que o número é o total e que você deve dividi-lo por dois para saber a capacidade de cada cache. A exceção, entretanto, fica com os processadores Pentium 4 e os Celeron mais novos, baseados nos soquetes 478 e 775. Os processadores Pentium 4 (e processadores Celeron soquetes 478 e 775) não possuem cache de instrução L1. Em vez disso eles possuem cache de rastreamento de execução, que é um cache localizado entre a unidade de decodificação e a unidade de execução. Portanto, o cache de instrução L1 está lá, mas com nome e lugar diferentes. Estamos falando isso porque esse é um erro muito comum, pensar que processadores Pentium 4 não possuem cache de instrução L1. Então, quando comparam o Pentium 4 com outros processadores, alguns podem achar que seu cache L1 é muito menor, porque estão contando apenas o cache de dados L1 de 8 KB. O cache de rastreamento de execução dos processadores Pentium 4 e Celeron é de 150 KB e deve ser levado em conta, é claro. Como dissemos várias vezes, um dos principais problemas para o processador é ter muitos erros de cache, porque a unidade de busca tem que acessar diretamente a memória RAM lenta, e assim deixar o sistema lento. Normalmente o uso da memória cache evita bem isso, mas existe uma situação típica em que o controlador de cache falha: desvios condicionais. Se no meio do programa houver uma instrução chamada JMP (“jump” ou “vá para”) mandando o programa para uma posição de memória completamente diferente, essa nova posição não será carregada na memória cache L2, fazendo com que a unidade de busca vá buscar aquela posição diretamente na memória RAM. Para resolver essa questão, o controlador de cache de processadores modernos analisa o bloco de memória carregado e sempre que encontrar uma instrução JMP lá carregará o bloco de memória para aquela posição na memória cache L2 antes que o processador alcance aquela instrução JMP. Figura 8: Situação de desvio incondicional. Isso é bastante fácil de implementar, o problema é que quando o programa apresenta um desvio condicional, isto é, o endereço para onde o programa deve se dirigir depende de uma condição até então desconhecida. Por exemplo, se a =< b salta para o endereço 1, ou se a > b salta para o endereço 2. Nós ilustramos esse exemplo na Figura 9. Isso resultaria em um erro de cache, porque os valores de a e b são desconhecidos e o controlador de cache estaria procurando apenas por instruções do tipo JMP. A solução: o controlador de cache carrega ambas as condições na memória cache.Mais tarde, quando o processador processar a instrução de desvio condicional, ele simplesmente descartará aquela que não foi escolhida. É melhor carregar a memória cache com dados desnecessários do que acessar diretamente a memória RAM. Figura 9: Situação de desvio condicional. A unidade de busca é encarregada de carregar as instruções da memória. Primeiro ela vai verificar se a instrução requisitada pelo processador está no cache de instrução L1. Caso não esteja, ela vai para a memória cache L2. Se a instrução também não estiver lá, então ela tem que carregar diretamente da lenta memória RAM do sistema. Quando você liga seu computador todos os caches estão vazios, é claro, mas na medida em que o computador começa a carregar o sistema operacional, o processador começa a processar as primeiras instruções carregadas do disco rígido, fazendo com que o controlador de cache comece a carregar os caches e começar o espetáculo. Depois que a unidade de busca pegou a instrução requisitada pelo processador para ser processada, ela a envia para a unidade de decodificação. A unidade de decodificação irá então verificar o que aquela instrução específica faz. Ela faz isso através de consulta à memória ROM que existe dentro do processador, chamada microcódigo. Cada instrução que um determinado processador compreende possui seu próprio microcódigo. O microcódigo vai “ensinar” ao processador o que fazer. É como um guia passo-a-passo para cada instrução. Se a instrução carregada é, por exemplo, somar a+b, seu microcódigo dirá à unidade de decodificação que são necessários dois parâmetros, a e b. A unidade de decodificação vai então requisitar que a unidade de busca pegue a informação presente nas duas posições de memória seguintes, que seja compatível com os valores para a e b. Depois que a unidade de decodificação “traduziu” a instrução e coletou todas as informações necessárias para executar a instrução, ela irá passar todas as informações e o “guia passo-a-passo” sobre como executar aquela instrução para a unidade de execução. A unidade de execução irá então finalmente executar a instrução. Em processadores modernos você encontrará mais de uma unidade de execução trabalhando em paralelo. Isso é feito para aumentar o desempenho do processador. Por exemplo, um processador com seis unidades de execução é capaz de executar seis instruções em paralelo, então, na teoria, ele pode alcançar o mesmo desempenho que seis processadores dotados de apenas uma unidade de execução. Esse tipo de arquitetura é chamado de arquitetura superescalar. Normalmente processadores modernos não possuem diversas unidades de execução idênticas; eles têm unidades de execução especializadas em um tipo de instruções. O melhor exemplo é a unidade de ponto flutuante (FPU, Float Point Unit, também chamada “co-processador matemático”), que é encarregada de executar instruções matemáticas complexas. Geralmente entre a unidade de decodificação e a unidade de execução existe uma unidade (chamada unidade de despacho ou agendamento) encarregada de enviar a instrução para a unidade de execução correta, isto é, caso a instrução seja uma instrução matemática, ela a enviará para a unidade de ponto flutuante e não para uma unidade de execução “genérica”. A propósito, unidades de execução “genéricas” são chamadas ALU (Arithmetic and Logic Unit) ou ULA (Unidade Lógica e Aritmética). Finalmente, quando o processamento termina, o resultado é enviado para o cache de dados L1. Continuando com nosso exemplo de soma a+b, o resultado será enviado para o cache de dados L1. Esse resultado pode ser então enviado de volta para a memória RAM ou para outro lugar, como a placa de vídeo, por exemplo. Mas isso vai depender da próxima instrução que será processada em seguida (a instrução seguinte pode ser “imprima o resultado na tela”). Outra função interessante que todos os microprocessadores possuem há muito tempo é chamada de “pipeline”, que é a capacidade de ter várias instruções diferentes em vários estágios do processador ao mesmo tempo. Depois que a unidade de busca enviou a instrução para a unidade de decodificação, ela ficará ociosa, certo? Então, em vez de ficar fazendo nada, que tal mandar a unidade de busca pegar a próxima instrução? Quando a primeira instrução for para a unidade de execução, a unidade de busca pode enviar a segunda instrução para a unidade de decodificação e pegar a terceira instrução, e por aí vai. Em um processador moderno com um pipeline de 11 estágios (estágio é outro nome para cada unidade do processador), ele provavelmente terá 11 instruções dentro dele ao mesmo tempo quase o tempo todo. Na verdade, visto que todos os processadores modernos possuem arquitetura superescalar, o número de instruções simultâneas dentro do processador será até maior. Além disso, em um processador de 11 estágios, uma instrução terá que passar por 11 unidades para que seja completamente executada. Quanto maior o número de estágios, mais tempo uma instrução vai demorar para que seja totalmente executada. Por outro lado, tenha em mente que, por causa desse conceito, várias instruções podem estar rodando ao mesmo tempo dentro do processador. A primeira instrução carregada pelo processador pode demorar 11 passos para sair dele, mas uma vez que estiver fora, a segunda instrução sairá logo depois (e não outros 11 passos depois). Existem muitos outros truques usados pelos processadores modernos para aumentar o desempenho. Nós explicaremos dois deles, execução fora de ordem (OOO, out-of-order execution) e execução especulativa. Lembra que dissemos que processadores modernos possuem diversas unidades de execução trabalhando em paralelo? Nós também dissemos que existem tipos diferentes de unidades de execução, como a ALU (Unidade Lógica Aritmética), que é uma unidade de execução genérica, e a FPU (Unidade de Ponto Flutuante), que é uma unidade de execução matemática. Apenas como exemplo genérico para entendermos o problema, digamos que um determinado processador possua seis unidades de execução, quatro “genéricas” e duas de ponto flutuante. Digamos também que o programa tenha o seguinte fluxo de instruções em um dado momento. 1. instrução genérica 2. instrução genérica 3. instrução genérica 4. instrução genérica 5. instrução genérica 6. instrução genérica 7. instrução matemática 8. instrução genérica 9. instrução genérica 10. instrução matemática O que vai acontecer? A unidade de despacho/agendamento enviará as primeiras quatro instruções às quatro ALUs mas, na quinta instrução, o processador precisará esperar que uma de suas ALUs fique livre para continuar o processamento, já que todas as suas quatro unidades de execução genéricas estarão ocupadas. Isso não é bom, porque ainda teremos duas unidades matemáticas (FPUs) disponíveis, e elas estarão ociosas. Portanto, um processador com mecanismo de execução fora de ordem (todos os processadores modernos têm essa função) vai analisar a próxima instrução e ver se ela pode ser enviada a uma das unidades ociosas. Em nosso exemplo isso não é possível, porque a sexta instrução também precisa de uma ALU para ser processada. O mecanismo de execução fora de ordem continua sua busca e descobre que a sétima instrução é uma instrução matemática que pode ser executada em uma das FPUs disponíveis. Como a outra FPU continuará disponível, ele vai vasculhar o programa em busca de oura instrução matemática. Em nosso exemplo, ele vai passar pelas instruções oito e nove e carregará a décima instrução. Em nosso exemplo, as unidades de execução estarão processando, ao mesmo tempo, a primeira, a segunda, a terceira, a quarta, a sétima e a décima instruções. O nome fora de ordem vem do fato de que o processador não precisa esperar; ele pode puxar uma instrução do fundo do programa e processá-la antes que instruções acima dela sejam processadas. É claro que a execução fora de ordem não pode ficar indefinidamente procurando por uma instrução se não puder encontrar imediatamente uma para ser executada em paralelo. A execução fora de ordem de todos os processadores tem um limite de profundidade até onde podem ir procurar por instruções (um valor típico seria 512). Vamos supor que uma dessas instruções genéricas é um desvio condicional. O que a execução fora de ordem vai fazer? Se o processador implementar uma função chamada execução especulativa (todos os processadores modernos fazem isso), ele executará ambos os desvios. Considere o exemplo abaixo: 1. instrução genérica 2. instrução genérica 3. se a=<b vá para instrução 15 4. instrução genérica 5. instrução genérica 6. instrução genérica 7. instrução matemática 8. instrução genérica 9. instrução genérica 10. instrução matemática … 15. instrução matemática 16. instrução genérica … Quando o mecanismo da execução fora de ordem analisar este programa, ele vai puxar a instrução 15 para uma das FPUs, já que ele vai precisar de uma instrução matemática para preencher uma das FPUs que estariam ociosas. Então, em um dado momento, podemos ter ambos os desvios sendo processados ao mesmo tempo. Se quando o processador terminar de processar a terceira instrução a for maior que a b, então o processador irá simplesmente descartar o processamento da instrução 15. Você pode achar que isso é perda de tempo, mas na verdade não é. Não custa nada ao processador executar aquela instrução específica, porque a FPU estaria ociosa de qualquer maneira. Por outro lado, se a=<b o processador terá um aumento no desempenho, já que quando a instrução 3 pedir a instrução 15 ela já terá sido processada, indo direto para a instrução 16 ou até mais longe, se a instrução 16 também já tiver sido processada em paralelo pelo mecanismo de execução fora de ordem. É claro que tudo que explicamos neste tutorial é uma simplificação para fazer com que esse tema tão técnico fique um pouco mais fácil de ser entendido.
Apesar de cada microprocessador ter seu próprio desenho interno, todos os microprocessadores compartilham do mesmo conceito básico – o qual explicaremos neste tutorial. Daremos uma olhada dentro da arquitetura de um processador genérico, para que assim você seja capaz de entender um pouco mais sobre os produtos da Intel e da AMD, bem como as diferenças entre eles. O processador – que também é chamado de microprocessador, CPU (Central Processing Unit) ou UCP (Unidade Central de Processamento) – é o encarregado de processar informações. Como ele vai processar as informações vai depender do programa. O programa pode ser uma planilha, um processador de textos ou um jogo: para o processador isso não faz a menor diferença, já que ele não entende o que o programa está realmente fazendo. Ele apenas obedece às ordens (chamadas comandos ou instruções) contidas no programa. Essas ordens podem ser para somar dois números ou para enviar uma informação para a placa de vídeo, por exemplo. Quando você clica duas vezes em um ícone para rodar um programa, veja o que acontece: 1. O programa, que está armazenado no disco rígido, é transferido para a memória. Um programa é uma série de instruções para o processador. 2. O processador, usando um circuito chamado controlador de memória, carrega as informações do programa da memória RAM. 3. As informações, agora dentro do processador, são processadas. 4. O que acontece a seguir vai depender do programa. O processador pode continuar a carregar e executar o programa ou pode fazer alguma coisa com a informação processada, como mostrar algo na tela. Figura 1: Como a informação armazenada é transferida para o processador. No passado, o processador controlava a transferência de informações entre o disco rígido e a memória RAM. Como o disco rígido é mais lento que a memória RAM, isso deixava o sistema lento, já que o processador ficava ocupado até que todas as informações fossem transferidas do disco rígido para a memória RAM. Esse método é chamado PIO (Programmed Input/Output - Entrada/Saída Programada). Hoje em dia a transferência de informações entre o disco rígido e a memória RAM é feita sem o uso do processador, tornando, assim, o sistema mais rápido. Esse método é chamado bus mastering ou DMA (Direct Memory Access - Acesso Direto à Memória). Para simplificar nosso desenho, não colocamos o chip da ponte norte entre o disco rígido e a memória RAM na Figura 1, mas ele está lá. Caso deseje saber mais sobre esse assunto, nós já escrevemos um tutorial sobre isso. Processadores da AMD baseados nos soquetes 754, 939 e 940 (Athlon 64, Athlon 64 X2, Athlon 64 FX, Opteron e alguns modelos de Sempron) possuem controlador de memória embutido. Isso significa que para esses processadores a CPU acessa a memória RAM diretamente, sem usar o chip da ponte norte mostrado na Figura 1. Para melhor compreender o papel do chipset em um computador, nós recomendamos a leitura do nosso tutorial Tudo o Que Você Precisa Saber Sobre Chipsets. Afinal, o que vem a ser clock? Clock é um sinal usado para sincronizar coisas dentro do computador. Dê uma olhada na Figura 2, onde mostramos um típico sinal de clock: é uma onda quadrada passando de “0” a “1” a uma taxa fixa. Nessa figura você pode ver três ciclos de clock (“pulsos”) completos. O início de cada ciclo é quando o sinal de clock passa de “0” a “1”; nós marcamos isso com uma seta. O sinal de clock é medido em uma unidade chamada Hertz (Hz), que é o número de ciclos de clock por segundo. Um clock de 100 MHz significa que em um segundo existem 100 milhões de ciclos de clock. Figura 2: Sinal de clock. No computador, todas as medidas de tempo são feitas em termos de ciclos de clock. Por exemplo, uma memória RAM com latência “5” significa que vai levar cinco ciclos de clock completos para começar a transferência de dados. Dentro da CPU, todas as instruções precisam de um certo número de ciclos de clock para serem executadas. Por exemplo, uma determinada instrução pode levar sete ciclos de clock para ser completamente executada. No que diz respeito ao processador, o interessante é que ele sabe quantos ciclos de clock cada instrução vai demorar, porque ele tem uma tabela que lista essas informações. Então se há duas instruções para serem executadas e ele sabe que a primeira vai levar sete ciclos de clock para ser executada, ele vai automaticamente começar a execução da próxima instrução no 8o pulso de clock. É claro que esta é uma explicação genérica para um processador com apenas uma unidade de execução – processadores modernos possuem várias unidades de execução trabalhando em paralelo e podem executar a segunda instrução ao mesmo tempo em que a primeira, em paralelo. A isso chamamos arquitetura superescalar e falaremos mais a esse respeito mais tarde. Então o que o clock tem a ver com desempenho? Pensar que clock e desempenho são a mesma coisa é o erro mais comum acerca de processadores. Se você comparar dois processadores completamente idênticos, o que estiver rodando a uma taxa de clock mais alta será o mais rápido. Neste caso, com uma taxa de clock mais alta, o tempo entre cada ciclo de clock será menor, então as tarefas serão desempenhadas em menos tempo e o desempenho será mais alto. Mas quando você compara dois processadores diferentes, isso não é necessariamente verdadeiro. Se você pegar dois processadores com diferentes arquiteturas – por exemplo, de dois fabricantes diferentes, como Intel e AMD – o interior deles será completamente diferente. Como dissemos, cada instrução demora um certo número de ciclos de clock para ser executada. Digamos que o processador “A” demore sete ciclos de clock para executar uma determinada instrução, e que o processador “B” leve cinco ciclos de clock para executar essa mesma instrução. Se eles estiverem rodando com a mesma taxa de clock, o processador “B” será mais rápido, porque pode processar essa instrução em menos tempo. E há ainda muito mais no jogo do desempenho em processadores modernos, pois processadores têm quantidades diferentes de unidades de execução, tamanhos de cache diferentes, formas diferentes de transferência de dados dentro do processador, formas diferentes de processar instruções dentro das unidades de execução, diferentes taxas de clock com o mundo exterior, etc. Não se preocupe, pois nós falaremos sobre tudo isso neste tutorial. Como o sinal de clock do processador ficou muito alto, surgiu um problema. A placa-mãe onde o processador é instalado não podia funcionar usando o mesmo sinal de clock.Se você olhar para uma placa-mãe, verá várias trilhas ou caminhos. Essas trilhas são fios que conectam vários circuitos do computador. O problema é que, com taxas de clock mais altas, esses fios começaram a funcionar como antenas, por isso o sinal, em vez de chegar à outra extremidade do fio, simplesmente desaparecia, sendo transmitido como onda de rádio. Figura 3: Os fios na placa-mãe podem funcionar como antenas. Os fabricantes de processadores começaram a usar, então, um novo conceito, chamado multiplicação de clock, que começou com o processador 486DX2. Com esse esquema, que é usado em todos os processadores atualmente, o processador tem um clock externo, que é usado quando dados são transferidos de e para a memória RAM (usando o chip da ponte norte), e um clock interno mais alto. Para darmos um exemplo real, em um Pentium 4 de 3,4 GHz, estes “3,4 GHz” referem-se ao clock interno do processador, que é obtido quando multiplicamos por 17 seu clock externo de 200 MHz. Nós ilustramos esse exemplo na Figura 4. Figura 4: Clocks interno e externo em um Pentium 4 de 3,4 GHz. A grande diferença entre o clock interno e o clock externo em processadores modernos é uma grande barreira a ser transposta visando aumentar o desempenho do computador. Continuando com o exemplo do Pentium 4 de 3,4 GHz, ele tem que reduzir sua velocidade em 17x quando tem que ler dados da memória RAM! Durante esse processo, ele funciona como se fosse um processador de 200 MHz! Diversas técnicas são usadas para minimizar o impacto dessa diferença de clock. Um deles é o uso de memória cache dentro do processador. Outra é transferir mais de um dado por pulso de clock. Processadores tanto da AMD como da Intel usam esse recurso, mas enquanto os processadores da AMD transferem dois dados por ciclo de clock, os da Intel transferem quatro dados por ciclo de clock. Figura 5: Transferindo mais de um dado por ciclo de clock. Por causa disso, os processadores da AMD são listados como se tivessem o dobro de seus verdadeiros clocks externos. Por exemplo, um processador da AMD com clock externo de 200 MHz é listado como tendo 400 MHz. O mesmo acontece com processadores da Intel com clock externo de 200 MHz, que são listados como se tivessem clock externo de 800 MHz. A técnica de transferir dois dados por ciclo de clock é chamada DDR (Dual Data Rate), enquanto que a técnica de transferir quatro dados por ciclo de clock é chamada QDR (Quad Data Rate). Na Figura 6 você pode ver um diagrama em blocos básico de um processador moderno. São muitas as diferenças entre as arquiteturas da AMD e da Intel, e planejamos escrever artigos específicos sobre cada uma delas num futuro próximo. Acreditamos que entender o diagrama em blocos básico de um processador moderno seja o primeiro passo para entender como funcionam os processadores da Intel e da AMD e quais são as diferenças entre eles. Figura 6: Diagrama em blocos básico de um processador. A linha pontilhada na Figura 6 representa o corpo do processador, já que a memória RAM está localizada fora do processador. O caminho de dados entre a memória RAM e a CPU tem geralmente largura de 64 bits (ou de 128 bits quando é usada configuração de memória “dual channel”), rodando ao clock da memória ou ao clock externo do processador, o que for mais baixo. O número de bits usado e a taxa de clock podem ser combinados em uma unidade chamada taxa de transferência, medida em MB/s. Para calcular a taxa de transferência, a fórmula é o número de bits x clock / 8. Para um sistema usando memórias DDR400 em configuração single channel (64 bits) a taxa de transferência da memória será de 3.200 MB/s, ao passo que o mesmo sistema usando memórias dual channel (128 bits) terá taxa de transferência de memória de 6.400 MB/s. Para mais informações sobre esse assunto, leia nosso tutorial Memórias DDR Dual Channel. Todos os circuitos dentro da caixa pontilhada rodam no mesmo clock interno do processador. Dependendo do processador, algumas de suas partes internas podem até mesmo rodar a uma taxa de clock mais alta. Além disso, o caminho de dados entre as unidades do processador pode ser mais largo, isto é, transferir mais bits por ciclo de clock do que 64 ou 128. Por exemplo, o caminho de dados entre a memória cache L2 e o cache de instrução L1 em processadores modernos tem normalmente 256 bits de largura. Quanto maior o número de bits transferidos por ciclo de clock, mais rápida a transferência será feita (em outras palavras, a taxa de transferência será mais alta). Na Figura 5 usamos uma seta vermelha entre a memória RAM e a memória cache L2 e setas verdes entre todos os outros blocos para expressar as diferentes taxas de clock e largura de caminho de dados usadas. Memória cache é um tipo de memória de alto desempenho, também chamada memória estática. O tipo de memória usado na memória RAM principal do computador é chamado memória dinâmica. A memória estática consome mais energia, é mais cara e é fisicamente maior que a memória dinâmica, mas é muito mais rápida. Ela pode trabalhar no mesmo clock do processador, o que a memória dinâmica não é capaz de fazer. Já que ir ao “mundo exterior” para buscar dados faz com que o processador trabalhe a uma taxa de clock inferior, a técnica da memória cache é usada. Quando o processador carrega um dado de uma certa posição da memória, um circuito chamado controlador de memória cache (não desenhado na Figura 6 em prol da simplicidade) carrega na memória cache um bloco inteiro de dados abaixo da atual posição que o processador acabou de carregar. Como normalmente os programas rodam de maneira seqüencial, a próxima posição de memória que o processador irá requisitar será provavelmente a posição imediatamente abaixo da posição da memória que ela acabou de carregar. Como o controlador de memória cache já carregou um monte de dados abaixo da primeira posição de memória lida pelo processador, o próximo dado estará dentro da memória cache, portanto o processador não precisa “sair” para buscar os dados: eles já estão carregados na memória cache embutida no processador, os quais ela pode acessar à sua taxa de clock interna. O controlador de cache está sempre observando as posições de memória que estão sendo carregadas e carregando dados de várias posições de memória depois da posição de memória que acaba de ser lida. Para darmos um exemplo real, se o processador carregou dados armazenados no endereço 1.000, o controlador de cache carregará dados do endereço “n” após o endereço 1.000. Esse número “n” é chamado página; se um dado processador está trabalhando com páginas de 4 KB (que é um valor típico), ele carregará dados de 4.096 endereços abaixo da atual posição de memória que está sendo carregada (endereço 1.000 em nosso exemplo). A propósito, 1 KB é igual a 1.024 bytes, por isso 4 KB é igual a 4.096 e não 4.000. Na Figura 7 nós ilustramos esse exemplo. Figura 7: Como funciona o controlador de memória cache. Quanto maior a memória cache, maiores são as chances de que a informação necessária ao processador já esteja lá, então o processador precisará acessar diretamente a memória RAM com menos freqüência, e assim aumentando o desempenho do sistema (apenas lembre-se que toda vez que o processador precisa acessar a memória RAM diretamente, ele precisa diminuir sua taxa de clock para essa operação). Chamamos de “acerto” (“hit”) quando o processador carrega uma informação requisitada do cache, e de “erro” (“miss”) se a informação requisitada não está lá e o processador precise acessar a memória RAM do sistema. L1 e L2 significam “nível 1” (Level 1) e “nível 2” (“Level 2”), respectivamente, e referem-se à distância em que se encontram do núcleo do processador (unidade de execução). Uma dúvida comum é porque ter três memórias cache distintas (cache de dados L1, cache de instrução L1 e L2). Preste atenção na Figura 6 e você verá que o cache de instrução L1 funciona como “cache de entrada”, enquanto o cache de dados L1 funciona como “cache de saída”. O cache de instrução L1 – que é geralmente menor que o cache L2 – é particularmente eficiente quando o programa começa a repetir uma pequena parte dele (loop), porque as instruções requisitadas estarão mais próximas da unidade de busca. Na página de especificações de um processador o cache L1 pode ser encontrado com diferentes tipos de representação. Alguns fabricantes listam duas memórias cache L1 separadamente (algumas vezes chamando o cache de instrução de “I” e o cache de dados de “D”), alguns acrescentam a soma dos dois e escrevem “separados” – então “128 KB, separados” significa 64 KB cache de instrução e 64 KB de cache de dados –, e alguns simplesmente somam os dois e você tem que adivinhar que o número é o total e que você deve dividi-lo por dois para saber a capacidade de cada cache. A exceção, entretanto, fica com os processadores Pentium 4 e os Celeron mais novos, baseados nos soquetes 478 e 775. Os processadores Pentium 4 (e processadores Celeron soquetes 478 e 775) não possuem cache de instrução L1. Em vez disso eles possuem cache de rastreamento de execução, que é um cache localizado entre a unidade de decodificação e a unidade de execução. Portanto, o cache de instrução L1 está lá, mas com nome e lugar diferentes. Estamos falando isso porque esse é um erro muito comum, pensar que processadores Pentium 4 não possuem cache de instrução L1. Então, quando comparam o Pentium 4 com outros processadores, alguns podem achar que seu cache L1 é muito menor, porque estão contando apenas o cache de dados L1 de 8 KB. O cache de rastreamento de execução dos processadores Pentium 4 e Celeron é de 150 KB e deve ser levado em conta, é claro. Como dissemos várias vezes, um dos principais problemas para o processador é ter muitos erros de cache, porque a unidade de busca tem que acessar diretamente a memória RAM lenta, e assim deixar o sistema lento. Normalmente o uso da memória cache evita bem isso, mas existe uma situação típica em que o controlador de cache falha: desvios condicionais. Se no meio do programa houver uma instrução chamada JMP (“jump” ou “vá para”) mandando o programa para uma posição de memória completamente diferente, essa nova posição não será carregada na memória cache L2, fazendo com que a unidade de busca vá buscar aquela posição diretamente na memória RAM. Para resolver essa questão, o controlador de cache de processadores modernos analisa o bloco de memória carregado e sempre que encontrar uma instrução JMP lá carregará o bloco de memória para aquela posição na memória cache L2 antes que o processador alcance aquela instrução JMP. Figura 8: Situação de desvio incondicional. Isso é bastante fácil de implementar, o problema é que quando o programa apresenta um desvio condicional, isto é, o endereço para onde o programa deve se dirigir depende de uma condição até então desconhecida. Por exemplo, se a =< b salta para o endereço 1, ou se a > b salta para o endereço 2. Nós ilustramos esse exemplo na Figura 9. Isso resultaria em um erro de cache, porque os valores de a e b são desconhecidos e o controlador de cache estaria procurando apenas por instruções do tipo JMP. A solução: o controlador de cache carrega ambas as condições na memória cache.Mais tarde, quando o processador processar a instrução de desvio condicional, ele simplesmente descartará aquela que não foi escolhida. É melhor carregar a memória cache com dados desnecessários do que acessar diretamente a memória RAM. Figura 9: Situação de desvio condicional. A unidade de busca é encarregada de carregar as instruções da memória. Primeiro ela vai verificar se a instrução requisitada pelo processador está no cache de instrução L1. Caso não esteja, ela vai para a memória cache L2. Se a instrução também não estiver lá, então ela tem que carregar diretamente da lenta memória RAM do sistema. Quando você liga seu computador todos os caches estão vazios, é claro, mas na medida em que o computador começa a carregar o sistema operacional, o processador começa a processar as primeiras instruções carregadas do disco rígido, fazendo com que o controlador de cache comece a carregar os caches e começar o espetáculo. Depois que a unidade de busca pegou a instrução requisitada pelo processador para ser processada, ela a envia para a unidade de decodificação. A unidade de decodificação irá então verificar o que aquela instrução específica faz. Ela faz isso através de consulta à memória ROM que existe dentro do processador, chamada microcódigo. Cada instrução que um determinado processador compreende possui seu próprio microcódigo. O microcódigo vai “ensinar” ao processador o que fazer. É como um guia passo-a-passo para cada instrução. Se a instrução carregada é, por exemplo, somar a+b, seu microcódigo dirá à unidade de decodificação que são necessários dois parâmetros, a e b. A unidade de decodificação vai então requisitar que a unidade de busca pegue a informação presente nas duas posições de memória seguintes, que seja compatível com os valores para a e b. Depois que a unidade de decodificação “traduziu” a instrução e coletou todas as informações necessárias para executar a instrução, ela irá passar todas as informações e o “guia passo-a-passo” sobre como executar aquela instrução para a unidade de execução. A unidade de execução irá então finalmente executar a instrução. Em processadores modernos você encontrará mais de uma unidade de execução trabalhando em paralelo. Isso é feito para aumentar o desempenho do processador. Por exemplo, um processador com seis unidades de execução é capaz de executar seis instruções em paralelo, então, na teoria, ele pode alcançar o mesmo desempenho que seis processadores dotados de apenas uma unidade de execução. Esse tipo de arquitetura é chamado de arquitetura superescalar. Normalmente processadores modernos não possuem diversas unidades de execução idênticas; eles têm unidades de execução especializadas em um tipo de instruções. O melhor exemplo é a unidade de ponto flutuante (FPU, Float Point Unit, também chamada “co-processador matemático”), que é encarregada de executar instruções matemáticas complexas. Geralmente entre a unidade de decodificação e a unidade de execução existe uma unidade (chamada unidade de despacho ou agendamento) encarregada de enviar a instrução para a unidade de execução correta, isto é, caso a instrução seja uma instrução matemática, ela a enviará para a unidade de ponto flutuante e não para uma unidade de execução “genérica”. A propósito, unidades de execução “genéricas” são chamadas ALU (Arithmetic and Logic Unit) ou ULA (Unidade Lógica e Aritmética). Finalmente, quando o processamento termina, o resultado é enviado para o cache de dados L1. Continuando com nosso exemplo de soma a+b, o resultado será enviado para o cache de dados L1. Esse resultado pode ser então enviado de volta para a memória RAM ou para outro lugar, como a placa de vídeo, por exemplo. Mas isso vai depender da próxima instrução que será processada em seguida (a instrução seguinte pode ser “imprima o resultado na tela”). Outra função interessante que todos os microprocessadores possuem há muito tempo é chamada de “pipeline”, que é a capacidade de ter várias instruções diferentes em vários estágios do processador ao mesmo tempo. Depois que a unidade de busca enviou a instrução para a unidade de decodificação, ela ficará ociosa, certo? Então, em vez de ficar fazendo nada, que tal mandar a unidade de busca pegar a próxima instrução? Quando a primeira instrução for para a unidade de execução, a unidade de busca pode enviar a segunda instrução para a unidade de decodificação e pegar a terceira instrução, e por aí vai. Em um processador moderno com um pipeline de 11 estágios (estágio é outro nome para cada unidade do processador), ele provavelmente terá 11 instruções dentro dele ao mesmo tempo quase o tempo todo. Na verdade, visto que todos os processadores modernos possuem arquitetura superescalar, o número de instruções simultâneas dentro do processador será até maior. Além disso, em um processador de 11 estágios, uma instrução terá que passar por 11 unidades para que seja completamente executada. Quanto maior o número de estágios, mais tempo uma instrução vai demorar para que seja totalmente executada. Por outro lado, tenha em mente que, por causa desse conceito, várias instruções podem estar rodando ao mesmo tempo dentro do processador. A primeira instrução carregada pelo processador pode demorar 11 passos para sair dele, mas uma vez que estiver fora, a segunda instrução sairá logo depois (e não outros 11 passos depois). Existem muitos outros truques usados pelos processadores modernos para aumentar o desempenho. Nós explicaremos dois deles, execução fora de ordem (OOO, out-of-order execution) e execução especulativa. Lembra que dissemos que processadores modernos possuem diversas unidades de execução trabalhando em paralelo? Nós também dissemos que existem tipos diferentes de unidades de execução, como a ALU (Unidade Lógica Aritmética), que é uma unidade de execução genérica, e a FPU (Unidade de Ponto Flutuante), que é uma unidade de execução matemática. Apenas como exemplo genérico para entendermos o problema, digamos que um determinado processador possua seis unidades de execução, quatro “genéricas” e duas de ponto flutuante. Digamos também que o programa tenha o seguinte fluxo de instruções em um dado momento. 1. instrução genérica 2. instrução genérica 3. instrução genérica 4. instrução genérica 5. instrução genérica 6. instrução genérica 7. instrução matemática 8. instrução genérica 9. instrução genérica 10. instrução matemática O que vai acontecer? A unidade de despacho/agendamento enviará as primeiras quatro instruções às quatro ALUs mas, na quinta instrução, o processador precisará esperar que uma de suas ALUs fique livre para continuar o processamento, já que todas as suas quatro unidades de execução genéricas estarão ocupadas. Isso não é bom, porque ainda teremos duas unidades matemáticas (FPUs) disponíveis, e elas estarão ociosas. Portanto, um processador com mecanismo de execução fora de ordem (todos os processadores modernos têm essa função) vai analisar a próxima instrução e ver se ela pode ser enviada a uma das unidades ociosas. Em nosso exemplo isso não é possível, porque a sexta instrução também precisa de uma ALU para ser processada. O mecanismo de execução fora de ordem continua sua busca e descobre que a sétima instrução é uma instrução matemática que pode ser executada em uma das FPUs disponíveis. Como a outra FPU continuará disponível, ele vai vasculhar o programa em busca de oura instrução matemática. Em nosso exemplo, ele vai passar pelas instruções oito e nove e carregará a décima instrução. Em nosso exemplo, as unidades de execução estarão processando, ao mesmo tempo, a primeira, a segunda, a terceira, a quarta, a sétima e a décima instruções. O nome fora de ordem vem do fato de que o processador não precisa esperar; ele pode puxar uma instrução do fundo do programa e processá-la antes que instruções acima dela sejam processadas. É claro que a execução fora de ordem não pode ficar indefinidamente procurando por uma instrução se não puder encontrar imediatamente uma para ser executada em paralelo. A execução fora de ordem de todos os processadores tem um limite de profundidade até onde podem ir procurar por instruções (um valor típico seria 512). Vamos supor que uma dessas instruções genéricas é um desvio condicional. O que a execução fora de ordem vai fazer? Se o processador implementar uma função chamada execução especulativa (todos os processadores modernos fazem isso), ele executará ambos os desvios. Considere o exemplo abaixo: 1. instrução genérica 2. instrução genérica 3. se a=<b vá para instrução 15 4. instrução genérica 5. instrução genérica 6. instrução genérica 7. instrução matemática 8. instrução genérica 9. instrução genérica 10. instrução matemática … 15. instrução matemática 16. instrução genérica … Quando o mecanismo da execução fora de ordem analisar este programa, ele vai puxar a instrução 15 para uma das FPUs, já que ele vai precisar de uma instrução matemática para preencher uma das FPUs que estariam ociosas. Então, em um dado momento, podemos ter ambos os desvios sendo processados ao mesmo tempo. Se quando o processador terminar de processar a terceira instrução a for maior que a b, então o processador irá simplesmente descartar o processamento da instrução 15. Você pode achar que isso é perda de tempo, mas na verdade não é. Não custa nada ao processador executar aquela instrução específica, porque a FPU estaria ociosa de qualquer maneira. Por outro lado, se a=<b o processador terá um aumento no desempenho, já que quando a instrução 3 pedir a instrução 15 ela já terá sido processada, indo direto para a instrução 16 ou até mais longe, se a instrução 16 também já tiver sido processada em paralelo pelo mecanismo de execução fora de ordem. É claro que tudo que explicamos neste tutorial é uma simplificação para fazer com que esse tema tão técnico fique um pouco mais fácil de ser entendido. -
Tópico para a discussão do seguinte conteúdo publicado no Clube do Hardware: Tudo o Que Você Precisa Saber Sobre a Tecnologia de Virtualização da Intel "Aprenda sobre a Tecnologia de Virtualização da Intel, como funciona e como saber se o seu processador é capaz de suportá-la." Comentários são bem-vindos. Atenciosamente, Equipe Clube do Hardware https://www.clubedohardware.com.br
-
 Vários processadores da Intel vem com Tecnologia de Virtualização (VT). Previamente conhecido como Vanderpool, esta tecnologia permite que um processador funcione como vários computadores independentes, permitindo que vários sistemas operacionais possam ser executados ao mesmo tempo em uma mesma máquina. Neste tutorial explicaremos tudo o que você precisa saber sobre esta tecnologia. A Tecnologia de Virtualização da Intel está disponível em duas versões: VT-x para processadores x86 e VT-i para processadores Itanium (IA-64). Neste tutorial vamos cobrir os detalhes da tecnologia VT-x. A Tecnologia de Virtualização não é novidade. Existem alguns programas no mercado que permitem virtualização e muito provavelmente o VMware é o mais famoso deles (clique aqui para uma lista completa de programas de virtualização disponíveis no mercado). Com esta técnica, você pode “particionar” um único computador para que ele funcione como se fosse computadores independentes, permitindo ao micro rodar vários sistemas operacionais ao mesmo tempo. Os sistemas operacionais podem ser diferentes (por exemplo, você pode rodar Windows em um computador virtual e Linux em outro). Você pode confundir virtualização com multitarefa, com tecnologia de múltiplos núcleos ou com a tecnologia Hyper-Threading. Na multitarefa, existe um único sistema operacional e vários programas trabalhando em paralelo. Já na virtualização, você pode ter vários sistemas operacionais trabalhando em paralelo, cada um com vários programas em execução. Cada sistema operacional roda em um “processador virtual” ou “máquina virtual”, ou seja, cada um dos sistemas operacionais “acredita” que está sendo executado em um computador independente. A tecnologia multi-núcleo permite que um único processador tenha mais de um processador físico dentro dele. Por exemplo, um computador com um processador de dois núcleos funciona como se fosse um computador com dois processadores instalados, trabalhando em um modo chamado multiprocessamento simétrico (SMP, Symmetrical MultiProcessing). Apesar de os processadores multi-núcleo conterem mais de um processador, eles não podem ser usados separadamente. O sistema operacional é executado pelo primeiro núcleo do processador e os demais núcleos deverão ser usados pelo mesmo sistema operacional. Assim, para nossas explicações, não há diferença entre um processador com apenas um núcleo e um com vários núcleos. A tecnologia Hyper-Threading simula um processador adicional por núcleo de processamento. Por exemplo, um processador de dois núcleos com tecnologia Hyper-Threading é visto pelo sistema operacional como se fosse um processador de quatro núcleos. No entanto, estes processadores adicionais não podem executar sistemas operacionais distintos, então para o sistema operacional, a tecnologia Hyper-Threading tem o mesmo efeito que a tecnologia multi-núcleo. Os diagramas abaixo mostram as diferenças entre as tecnologias citadas acima. Figura 1: Multitarefa Figura 2: Multi-núcleo ou Hyper-Threading Figura 3: Virtualização Se você prestar atenção, a Tecnologia de Virtualização usa a mesma ideia do modo Virtual 8086 (V86), que está disponível desde os processadores 386. Com o modo V86 você pode criar várias máquinas virtuais 8086 para rodar programas baseados no DOS em paralelo, cada uma delas “acreditando” que está sendo executada por computadores completamente independentes. Com a tecnologia VT você pode criar várias máquinas virtuais “completas” para rodar sistemas operacionais em paralelo. Mas se existem programas como o VMware que habilitam a virtualização, porque implementar esta tecnologia dentro do processador? A vantagem é que o processador com Tecnologia de Virtualização possui algumas novas instruções para controlar a virtualização. Com essas instruções, o controle do software (chamado VMM, Virtual Machine Monitor) pode ser mais simples, o que resulta em um maior desempenho se comparado a soluções baseadas apenas em software. Quando o processador suporta Tecnologia de Virtualização, a virtualização é chamada “baseada em hardware”. Processadores com Tecnologia de Virtualização possuem um conjunto de instruções extra chamado Virtual Machine Extensions (Extensões de Máquina Virtual) ou VMX. O VMX traz 10 novas instruções específicas de virtualização para o processador: VMPTRLD, VMPTRST, VMCLEAR, VMREAD, VMWRITE, VMCALL, VMLAUNCH, VMRESUME, VMXOFF e VMXON. Existem dois modos de execução dentro da virtualização: root e não-root. Normalmente apenas o software de controle da virtualização, chamado Virtual Machine Monitor (VMM), roda no modo root, enquanto que os sistemas operacionais trabalhando no topo das máquinas virtuais rodam no modo não-root. Programas sendo executados no topo das máquinas virtuais são também chamados “programas convidados”. Para entrar no modo de virtualização, o programa deve executar a instrução VMXON e então chamar o software VMM. Feito isso, o software VMM pode entrar em cada máquina virtual usando a instrução VMLAUNCH, e sair delas usando a instrução VMRESUME. Se a VMM quiser parar todas as máquinas virtuais e sair do modo de virtualização, ela executa a instrução VMXOFF. Figura 4: Operação da Tecnologia de Virtualização Cada convidado mostrado na Figura 4 pode ser um sistema operacional diferente, rodando o seu próprio software (ou até mesmo vários programas ao mesmo tempo como mostramos na Figura 3). Processadores mais recentes apresentam uma extensão chamada EPT (Extended Page Tables ou Tabelas de Página Estendidas), que permite que cada convidado tenha sua própria tabela de página, de modo a monitorar quais endereços de memória que o convidado está acessando correspondem a quais endereços de memória no sistema de memória do computador. Sem esta extensão, o VMM tem de sair da máquina virtual para executar esta tarefa, o que reduz seu desempenho. Portanto, a extensão EPT aumenta o desempenho da virtualização. Apesar de a Tecnologia de Virtualização da Intel ter sido lançada em 2005, nem todos processadores da Intel trazem esta tecnologia. A maneira mais fácil de verificar se o seu processador suporta esta tecnologia é rodando o “Utilitário para Indentificação do Processador Intel”, que está disponível em português. Depois de baixar e instalar este programa, abra o programa e clique na guia “Tecnologias da CPU”. Na tela que aparecerá, você verá, em “Tecnologia de Virtualização Intel(R)”, se o seu processador suporta esta tecnologia ou não. Além disso, você pode verificar se seu processador suporta ou não a extensão EPT, em “IntelVT-x com tabelas estendidas de página”. Ver Figura 5. Figura 5: Detectando suporte para a Tecnologia de Virtualização da Intel
Vários processadores da Intel vem com Tecnologia de Virtualização (VT). Previamente conhecido como Vanderpool, esta tecnologia permite que um processador funcione como vários computadores independentes, permitindo que vários sistemas operacionais possam ser executados ao mesmo tempo em uma mesma máquina. Neste tutorial explicaremos tudo o que você precisa saber sobre esta tecnologia. A Tecnologia de Virtualização da Intel está disponível em duas versões: VT-x para processadores x86 e VT-i para processadores Itanium (IA-64). Neste tutorial vamos cobrir os detalhes da tecnologia VT-x. A Tecnologia de Virtualização não é novidade. Existem alguns programas no mercado que permitem virtualização e muito provavelmente o VMware é o mais famoso deles (clique aqui para uma lista completa de programas de virtualização disponíveis no mercado). Com esta técnica, você pode “particionar” um único computador para que ele funcione como se fosse computadores independentes, permitindo ao micro rodar vários sistemas operacionais ao mesmo tempo. Os sistemas operacionais podem ser diferentes (por exemplo, você pode rodar Windows em um computador virtual e Linux em outro). Você pode confundir virtualização com multitarefa, com tecnologia de múltiplos núcleos ou com a tecnologia Hyper-Threading. Na multitarefa, existe um único sistema operacional e vários programas trabalhando em paralelo. Já na virtualização, você pode ter vários sistemas operacionais trabalhando em paralelo, cada um com vários programas em execução. Cada sistema operacional roda em um “processador virtual” ou “máquina virtual”, ou seja, cada um dos sistemas operacionais “acredita” que está sendo executado em um computador independente. A tecnologia multi-núcleo permite que um único processador tenha mais de um processador físico dentro dele. Por exemplo, um computador com um processador de dois núcleos funciona como se fosse um computador com dois processadores instalados, trabalhando em um modo chamado multiprocessamento simétrico (SMP, Symmetrical MultiProcessing). Apesar de os processadores multi-núcleo conterem mais de um processador, eles não podem ser usados separadamente. O sistema operacional é executado pelo primeiro núcleo do processador e os demais núcleos deverão ser usados pelo mesmo sistema operacional. Assim, para nossas explicações, não há diferença entre um processador com apenas um núcleo e um com vários núcleos. A tecnologia Hyper-Threading simula um processador adicional por núcleo de processamento. Por exemplo, um processador de dois núcleos com tecnologia Hyper-Threading é visto pelo sistema operacional como se fosse um processador de quatro núcleos. No entanto, estes processadores adicionais não podem executar sistemas operacionais distintos, então para o sistema operacional, a tecnologia Hyper-Threading tem o mesmo efeito que a tecnologia multi-núcleo. Os diagramas abaixo mostram as diferenças entre as tecnologias citadas acima. Figura 1: Multitarefa Figura 2: Multi-núcleo ou Hyper-Threading Figura 3: Virtualização Se você prestar atenção, a Tecnologia de Virtualização usa a mesma ideia do modo Virtual 8086 (V86), que está disponível desde os processadores 386. Com o modo V86 você pode criar várias máquinas virtuais 8086 para rodar programas baseados no DOS em paralelo, cada uma delas “acreditando” que está sendo executada por computadores completamente independentes. Com a tecnologia VT você pode criar várias máquinas virtuais “completas” para rodar sistemas operacionais em paralelo. Mas se existem programas como o VMware que habilitam a virtualização, porque implementar esta tecnologia dentro do processador? A vantagem é que o processador com Tecnologia de Virtualização possui algumas novas instruções para controlar a virtualização. Com essas instruções, o controle do software (chamado VMM, Virtual Machine Monitor) pode ser mais simples, o que resulta em um maior desempenho se comparado a soluções baseadas apenas em software. Quando o processador suporta Tecnologia de Virtualização, a virtualização é chamada “baseada em hardware”. Processadores com Tecnologia de Virtualização possuem um conjunto de instruções extra chamado Virtual Machine Extensions (Extensões de Máquina Virtual) ou VMX. O VMX traz 10 novas instruções específicas de virtualização para o processador: VMPTRLD, VMPTRST, VMCLEAR, VMREAD, VMWRITE, VMCALL, VMLAUNCH, VMRESUME, VMXOFF e VMXON. Existem dois modos de execução dentro da virtualização: root e não-root. Normalmente apenas o software de controle da virtualização, chamado Virtual Machine Monitor (VMM), roda no modo root, enquanto que os sistemas operacionais trabalhando no topo das máquinas virtuais rodam no modo não-root. Programas sendo executados no topo das máquinas virtuais são também chamados “programas convidados”. Para entrar no modo de virtualização, o programa deve executar a instrução VMXON e então chamar o software VMM. Feito isso, o software VMM pode entrar em cada máquina virtual usando a instrução VMLAUNCH, e sair delas usando a instrução VMRESUME. Se a VMM quiser parar todas as máquinas virtuais e sair do modo de virtualização, ela executa a instrução VMXOFF. Figura 4: Operação da Tecnologia de Virtualização Cada convidado mostrado na Figura 4 pode ser um sistema operacional diferente, rodando o seu próprio software (ou até mesmo vários programas ao mesmo tempo como mostramos na Figura 3). Processadores mais recentes apresentam uma extensão chamada EPT (Extended Page Tables ou Tabelas de Página Estendidas), que permite que cada convidado tenha sua própria tabela de página, de modo a monitorar quais endereços de memória que o convidado está acessando correspondem a quais endereços de memória no sistema de memória do computador. Sem esta extensão, o VMM tem de sair da máquina virtual para executar esta tarefa, o que reduz seu desempenho. Portanto, a extensão EPT aumenta o desempenho da virtualização. Apesar de a Tecnologia de Virtualização da Intel ter sido lançada em 2005, nem todos processadores da Intel trazem esta tecnologia. A maneira mais fácil de verificar se o seu processador suporta esta tecnologia é rodando o “Utilitário para Indentificação do Processador Intel”, que está disponível em português. Depois de baixar e instalar este programa, abra o programa e clique na guia “Tecnologias da CPU”. Na tela que aparecerá, você verá, em “Tecnologia de Virtualização Intel(R)”, se o seu processador suporta esta tecnologia ou não. Além disso, você pode verificar se seu processador suporta ou não a extensão EPT, em “IntelVT-x com tabelas estendidas de página”. Ver Figura 5. Figura 5: Detectando suporte para a Tecnologia de Virtualização da Intel -
Como Funciona a Tecnologia Intel EM64T
Gabriel Torres respondeu ao tópico de Gabriel Torres em Comentários de artigos
Agradeço enormemente pela informação/correção. Estou atualizando o tutorial agora mesmo. Além disso, descobri que os processadores Celeron D das séries 3x1 e 3x6 também têm esta tecnologia. Abraços, Gabriel Torres -
Tópico para a discussão do seguinte conteúdo publicado no Clube do Hardware: Como Funciona a Tecnologia Intel EM64T "Tudo o que você precisa saber sobre a tecnologia de 64 bits EM64T da Intel, disponível nos processadores Pentium 4 6xx e Pentium D." Comentários são bem-vindos. Atenciosamente, Equipe Clube do Hardware https://www.clubedohardware.com.br
-
 A Intel lançou a sua “tecnologia de 64 bits” de modo a competir com a tecnologia de 64 bits da AMD. Esta tecnologia, oficialmente chamada EM64T (Extended Memory 64 Technology), já está presente em vários processadores Pentium 4, como todos os da série 6xx e os da série 5x1 (541, 551, 561, 571, etc). Além disso, os processadores Celeron D da série 3x1 e 3x6 (331, 336, 341, 346, etc) também possuem esta tecnologia, indicando a tendência de todos os processadores da Intel lançados daqui para a frente incorporarem esta nova tecnologia. Neste tutorial explicaremos o que é esta tecnologia e como ela funciona. Se você quiser comparar a implementação da Intel com a da AMD, leia nosso artigo Arquitetura de 64 bits da AMD (x86-64). Processadores com esta tecnologia possuem um novo modo de operação chamado IA32E, que tem dois sub-modos: Modo de Compatibilidade: Permite que sistemas operacionais de 64 bits rodem programas de 32 bits e 16 bits sem a necessidade de serem recompilados. O sistema operacional pode ter programas de 64 bits (no modo 64 bits), 32 bits e 16 bits (ambos no modo de compatibilidade) sendo executados ao mesmo tempo. No entanto, programas de 32 bits serão executados como se estivessem rondando em um processador de 32 bits, ou seja, acessarão no máximo 4 GB de memória RAM. A mesma idéia é válida para programas de 16 bits, que continuarão acessando no máximo 1 MB de memória RAM. Modo de 64 bits: Permite que sistemas operacionais e programas de 64 bits utilizem o novo espaço de endereçamento de 64 bits oferecido por esta tecnologia. Como você pode ver acima, a tecnologia EM64T pode ser usada apenas por sistemas operacionais de 64 bits, como o Windows 64. Sistemas operacionais de 32 bits, como o Windows XP, continuarão rodando no modo IA32, ou seja, usando o espaço de endereçamento de 32 bits e podendo acessar a no máximo 4 GB de memória RAM. Atualmente, o Windows não pode tirar vantagem da tecnologia EM64T por ainda ser um sistema operacional de 32 bits. No modo 64 bits (IA32E), o processador ganha novas funcionalidades: Espaço de endereçamento de 64 bits, isto é, aplicações podem endereçar até 16 EB (exabytes) de memória RAM (2^64 bytes); no entanto, atualmente processadores Celeron D, Pentium 4 e Xeon com suporte a tecnologia EM64T possuem apenas 36 linhas de endereçamento, o que significa que eles podem acessar “apenas” 64 GB de memória RAM (2^36). Processadores Xeon DP com tecnologia EM64T possuem 40 linhas de endereçamento, o que significa que eles podem acessar até 1 TB (terabyte) de memória RAM (2^40). Essas limitações podem ser alteradas no futuro e a Intel poderá lançar processadores capazes de acessar até 16 EB de memória RAM. Oito registradores adicionais: No modo de 64 bits, o processador possui um total de 16 registradores de 64 bits. Estes novos registradores são chamados R8 a R15. É interessante notar que a Intel decidiu usar a mesma nomenclatura criada pela AMD em sua implementação de 64 bits, ou seja, o uso da letra “R” para indicar os registradores de 64 bits. Na Figura 1 você pode ver como o registrador de 64 bits RAX funciona. Figura 1: Esquema de um registrador na tecnologia EM64T. Oito registradores adicionais para instruções SIMD (MMX, SSE, SSE2, SSE3): o processador possui um total de 16 registradores MMX de 64 bits no modo 64 bits. Os registradores chamados XMM continuam sendo de 128 bits, no entanto o número de registradores XMM foi dobrado de oito para 16. Estes registradores são usados pelas operações de ponto flutuante SSE. Todos registradores e ponteiros de instruções são de 64 bits. Os registradores da unidade de ponto flutuante continuam sendo de 80 bits. Os registradores de 64 bits continuam usando o mesmo esquema de divisão que permite que ele seja usado por operações de até oito bits (ver Figura 1). Por exemplo, o registrador de oito bits AL é, na realidade, os oito bits menos significativos do registrador RAX. Este esquema é chamado, em inglês, de “uniform byte-register addressing”. Mecanismo rápido de priorização de interrupção. Um novo ponteiro de instruções de 64 bits, chamado RIP, que substitui o ponteiro de instruções de 32 bits, chamado EIP. Um novo modo de endereçamento relativo para o ponteiro de instruções, chamado RIP-relative addressing (endereçamento relativo ao ponteiro de instruções). A tecnologia EM64T é voltada para sistemas operacionais de 64 bits. Ponto. Se você quer comprar um Pentium 4 ou Celeron D com tecnologia de 64 bits para quando o Windows 64 e programas nativos de 64 bits chegarem ao mercado, vá em frente. Mas tenha em mente que você não será capaz de usar características exclusivas da tecnologia EM64T ao menos que você execute um sistema operacional e programas de 64 bits. Se você tem um Pentium 4 ou Celeron D de 64 bits e o Windows 64, programas de 32 bits rodarão sem problemas, apesar de funcionarem no modo de compatibilidade, o que significa que eles “enxergarão” o processador como sendo de 32 bits. Se você utiliza aplicações “pesadas” e está pensando em migrar para a plataforma de 64 bits para ter acesso a mais de 4 GB de memória RAM, tenha em mente que você precisará de versões de 64 bits dos seus programas, ou eles continuarão acessando apenas 4 GB de memória RAM, não resolvendo assim o seu problema. Também tenha em mente que o barramento de endereços externo dos processadores baseados na tecnologia EM64T não é de 64 bits e, portanto, nenhum processador da Intel usando esta tecnologia pode acessar 16 EB (exabytes) de memória RAM (2^64), como você pode pensar. A quantidade máxima de memória RAM que um processador pode acessar no modo de 64 bits depende da sua implementação. As versões de 64 bits dos processadores Celeron D, Pentium 4 e Xeon podem acessar a até 64 GB de memória RAM enquanto que o processador Xeon DP pode acessar a até 1 TB de memória. Mais uma vez tenha em mente que no modo de 32 bits ou no modo de compatibilidade de 64 bits o processador pode acessar apenas 4 GB de memória, mesmo que ele seja um “processador de 64 bits”.
A Intel lançou a sua “tecnologia de 64 bits” de modo a competir com a tecnologia de 64 bits da AMD. Esta tecnologia, oficialmente chamada EM64T (Extended Memory 64 Technology), já está presente em vários processadores Pentium 4, como todos os da série 6xx e os da série 5x1 (541, 551, 561, 571, etc). Além disso, os processadores Celeron D da série 3x1 e 3x6 (331, 336, 341, 346, etc) também possuem esta tecnologia, indicando a tendência de todos os processadores da Intel lançados daqui para a frente incorporarem esta nova tecnologia. Neste tutorial explicaremos o que é esta tecnologia e como ela funciona. Se você quiser comparar a implementação da Intel com a da AMD, leia nosso artigo Arquitetura de 64 bits da AMD (x86-64). Processadores com esta tecnologia possuem um novo modo de operação chamado IA32E, que tem dois sub-modos: Modo de Compatibilidade: Permite que sistemas operacionais de 64 bits rodem programas de 32 bits e 16 bits sem a necessidade de serem recompilados. O sistema operacional pode ter programas de 64 bits (no modo 64 bits), 32 bits e 16 bits (ambos no modo de compatibilidade) sendo executados ao mesmo tempo. No entanto, programas de 32 bits serão executados como se estivessem rondando em um processador de 32 bits, ou seja, acessarão no máximo 4 GB de memória RAM. A mesma idéia é válida para programas de 16 bits, que continuarão acessando no máximo 1 MB de memória RAM. Modo de 64 bits: Permite que sistemas operacionais e programas de 64 bits utilizem o novo espaço de endereçamento de 64 bits oferecido por esta tecnologia. Como você pode ver acima, a tecnologia EM64T pode ser usada apenas por sistemas operacionais de 64 bits, como o Windows 64. Sistemas operacionais de 32 bits, como o Windows XP, continuarão rodando no modo IA32, ou seja, usando o espaço de endereçamento de 32 bits e podendo acessar a no máximo 4 GB de memória RAM. Atualmente, o Windows não pode tirar vantagem da tecnologia EM64T por ainda ser um sistema operacional de 32 bits. No modo 64 bits (IA32E), o processador ganha novas funcionalidades: Espaço de endereçamento de 64 bits, isto é, aplicações podem endereçar até 16 EB (exabytes) de memória RAM (2^64 bytes); no entanto, atualmente processadores Celeron D, Pentium 4 e Xeon com suporte a tecnologia EM64T possuem apenas 36 linhas de endereçamento, o que significa que eles podem acessar “apenas” 64 GB de memória RAM (2^36). Processadores Xeon DP com tecnologia EM64T possuem 40 linhas de endereçamento, o que significa que eles podem acessar até 1 TB (terabyte) de memória RAM (2^40). Essas limitações podem ser alteradas no futuro e a Intel poderá lançar processadores capazes de acessar até 16 EB de memória RAM. Oito registradores adicionais: No modo de 64 bits, o processador possui um total de 16 registradores de 64 bits. Estes novos registradores são chamados R8 a R15. É interessante notar que a Intel decidiu usar a mesma nomenclatura criada pela AMD em sua implementação de 64 bits, ou seja, o uso da letra “R” para indicar os registradores de 64 bits. Na Figura 1 você pode ver como o registrador de 64 bits RAX funciona. Figura 1: Esquema de um registrador na tecnologia EM64T. Oito registradores adicionais para instruções SIMD (MMX, SSE, SSE2, SSE3): o processador possui um total de 16 registradores MMX de 64 bits no modo 64 bits. Os registradores chamados XMM continuam sendo de 128 bits, no entanto o número de registradores XMM foi dobrado de oito para 16. Estes registradores são usados pelas operações de ponto flutuante SSE. Todos registradores e ponteiros de instruções são de 64 bits. Os registradores da unidade de ponto flutuante continuam sendo de 80 bits. Os registradores de 64 bits continuam usando o mesmo esquema de divisão que permite que ele seja usado por operações de até oito bits (ver Figura 1). Por exemplo, o registrador de oito bits AL é, na realidade, os oito bits menos significativos do registrador RAX. Este esquema é chamado, em inglês, de “uniform byte-register addressing”. Mecanismo rápido de priorização de interrupção. Um novo ponteiro de instruções de 64 bits, chamado RIP, que substitui o ponteiro de instruções de 32 bits, chamado EIP. Um novo modo de endereçamento relativo para o ponteiro de instruções, chamado RIP-relative addressing (endereçamento relativo ao ponteiro de instruções). A tecnologia EM64T é voltada para sistemas operacionais de 64 bits. Ponto. Se você quer comprar um Pentium 4 ou Celeron D com tecnologia de 64 bits para quando o Windows 64 e programas nativos de 64 bits chegarem ao mercado, vá em frente. Mas tenha em mente que você não será capaz de usar características exclusivas da tecnologia EM64T ao menos que você execute um sistema operacional e programas de 64 bits. Se você tem um Pentium 4 ou Celeron D de 64 bits e o Windows 64, programas de 32 bits rodarão sem problemas, apesar de funcionarem no modo de compatibilidade, o que significa que eles “enxergarão” o processador como sendo de 32 bits. Se você utiliza aplicações “pesadas” e está pensando em migrar para a plataforma de 64 bits para ter acesso a mais de 4 GB de memória RAM, tenha em mente que você precisará de versões de 64 bits dos seus programas, ou eles continuarão acessando apenas 4 GB de memória RAM, não resolvendo assim o seu problema. Também tenha em mente que o barramento de endereços externo dos processadores baseados na tecnologia EM64T não é de 64 bits e, portanto, nenhum processador da Intel usando esta tecnologia pode acessar 16 EB (exabytes) de memória RAM (2^64), como você pode pensar. A quantidade máxima de memória RAM que um processador pode acessar no modo de 64 bits depende da sua implementação. As versões de 64 bits dos processadores Celeron D, Pentium 4 e Xeon podem acessar a até 64 GB de memória RAM enquanto que o processador Xeon DP pode acessar a até 1 TB de memória. Mais uma vez tenha em mente que no modo de 32 bits ou no modo de compatibilidade de 64 bits o processador pode acessar apenas 4 GB de memória, mesmo que ele seja um “processador de 64 bits”. -
Como Conectar Seu PC ao Seu Aparelho de Som ou Home Theater
Gabriel Torres respondeu ao tópico de Gabriel Torres em Comentários de artigos
liverig: O tutorial de upgrade de BIOS: https://www.clubedohardware.com.br/artigos/692 slpk: Aparentemente sua placa-mãe usa um conector fora de padrão, mas se você reparar bem sua fibra óptica é normal com um adaptador para ser instalado na sua placa. O mais provável é que a outra ponta do cabo, que liga a placa ao receiver, seja no padrão correto, então acredito que você não precisa se preocupar. Abraços, Gabriel.



Sobre o Clube do Hardware
No ar desde 1996, o Clube do Hardware é uma das maiores, mais antigas e mais respeitadas comunidades sobre tecnologia do Brasil. Leia mais
Direitos autorais
Não permitimos a cópia ou reprodução do conteúdo do nosso site, fórum, newsletters e redes sociais, mesmo citando-se a fonte. Leia mais
